1. 用队列实现栈
描述 
思路
栈是一种 后进先出(last in - first out, LIFO)的数据结构,栈内元素从顶端压入(push),从顶端弹出(pop)。一般我们用数组或者链表来实现栈,但是这篇文章会来介绍如何用队列来实现栈。队列是一种与栈相反的 先进先出(first in - first out, FIFO)的数据结构,队列中元素只能从 后端(rear)入队(push),然后从 前端(front)端出队(pop)。为了满足栈的特性,我们需要维护两个队列 q1 和 q2。同时,我们用一个额外的变量来保存栈顶元素。
压入(push)
新元素永远从 q1 的后端入队,同时 q1 的后端也是栈的 栈顶(top)元素。
弹出(pop)
我们需要把栈顶元素弹出,就是 q1 中最后入队的元素。
考虑到队列是一种 FIFO 的数据结构,最后入队的元素应该在最后被出队。因此我们需要维护另外一个队列 q2,这个队列用作临时存储 q1 中出队的元素。q2 中最后入队的元素将作为新的栈顶元素。接着将 q1 中最后剩下的元素出队。我们通过把 q1 和 q2 互相交换的方式来避免把 q2 中的元素往 q1 中拷贝。
解法**
class MyStack {private Queue<Integer> q1;private Queue<Integer> q2;private int top;/** Initialize your data structure here. */public MyStack() {q1 = new LinkedList<>();q2 = new LinkedList<>();}/** Push element x onto stack. */public void push(int x) {q1.add(x);top = x;}/** Removes the element on top of the stack and returns that element. */public int pop() {while (q1.size() > 1) {top = q1.remove();q2.add(top);}int res = q1.remove();Queue<Integer> temp = q1;q1 = q2;q2 = temp;return res;}/** Get the top element. */public int top() {return top;}/** Returns whether the stack is empty. */public boolean empty() {return q1.isEmpty() && q2.isEmpty();}}/*** Your MyStack object will be instantiated and called as such:* MyStack obj = new MyStack();* obj.push(x);* int param_2 = obj.pop();* int param_3 = obj.top();* boolean param_4 = obj.empty();*/
class MyStack:def __init__(self):"""Initialize your data structure here."""self.q1 = []self.q2 = []def push(self, x: int) -> None:"""Push element x onto stack."""self.q1.append(x);def pop(self) -> int:"""Removes the element on top of the stack and returns that element."""if len(self.q1) == 0:return Nonewhile len(self.q1) != 1:self.q2.append(self.q1.pop(0))self.q1, self.q2 = self.q2, self.q1return self.q2.pop()def top(self) -> int:"""Get the top element."""return self.q1[-1]def empty(self) -> bool:"""Returns whether the stack is empty."""return not self.q1 and not self.q2# Your MyStack object will be instantiated and called as such:# obj = MyStack()# obj.push(x)# param_2 = obj.pop()# param_3 = obj.top()# param_4 = obj.empty()
注意:python这里用pop(0)模拟队列的出队操作。如果用deque作为队列,改为q1.popleft()即可。
2. 栈实现队列
描述
思路
使用两个栈 入队 - O(1),出队 - 摊还复杂度 O(1)
入队(push)
新元素总是压入 s1 的栈顶,同时我们会把 s1 中压入的第一个元素赋值给作为队首元素的 front 变量。
出队(pop)
根据栈 LIFO 的特性,s1 中第一个压入的元素在栈底。为了弹出 s1 的栈底元素,我们得把 s1 中所有的元素全部弹出,再把它们压入到另一个栈 s2 中,这个操作会让元素的入栈顺序反转过来。通过这样的方式,s1 中栈底元素就变成了 s2 的栈顶元素,这样就可以直接从 s2 将它弹出了。一旦 s2 变空了,我们只需把 s1 中的元素再一次转移到 s2 就可以了。
解法
class MyQueue {private Stack<Integer> s1;private Stack<Integer> s2;private int front;/** Initialize your data structure here. */public MyQueue() {s1 = new Stack<>();s2 = new Stack<>();}/** Push element x to the back of queue. */public void push(int x) {if (s1.empty())front = x;s1.push(x);}/** Removes the element from in front of queue and returns that element. */public int pop() {if (s2.isEmpty()) {while (!s1.isEmpty())s2.push(s1.pop());}return s2.pop();}/** Get the front element. */public int peek() {if (!s2.isEmpty()) {return s2.peek();}return front;}/** Returns whether the queue is empty. */public boolean empty() {return s1.isEmpty() && s2.isEmpty();}}/*** Your MyQueue object will be instantiated and called as such:* MyQueue obj = new MyQueue();* obj.push(x);* int param_2 = obj.pop();* int param_3 = obj.peek();* boolean param_4 = obj.empty();*/
class MyQueue:def __init__(self):"""Initialize your data structure here."""self.s1 = []self.s2 = []def push(self, x: int) -> None:"""Push element x to the back of queue."""self.s1.append(x)def pop(self) -> int:"""Removes the element from in front of queue and returns that element."""if not self.s2:while self.s1:self.s2.append(self.s1.pop())return self.s2.pop()def peek(self) -> int:"""Get the front element."""if self.s2:return self.s2[-1]return self.s1[0]def empty(self) -> bool:"""Returns whether the queue is empty."""return not self.s1 and not self.s2# Your MyQueue object will be instantiated and called as such:# obj = MyQueue()# obj.push(x)# param_2 = obj.pop()# param_3 = obj.peek()# param_4 = obj.empty()
4. 包含min函数的栈
描述 
思路
在代码实现的时候有两种方式:
1、辅助栈和数据栈同步
特点:编码简单,不用考虑一些边界情况,就有一点不好:辅助栈可能会存一些“不必要”的元素。
2、辅助栈和数据栈不同步
特点:由“辅助栈和数据栈同步”的思想,我们知道,当数据栈进来的数越来越大的时候,我们要在辅助栈顶放置和当前辅助栈顶一样的元素,这样做有点“浪费”。基于这一点,我们做一些“优化”,但是在编码上就要注意一些边界条件。
(1)辅助栈为空的时候,必须放入新进来的数;
(2)新来的数小于或者等于辅助栈栈顶元素的时候,才放入,特别注意这里“等于”要考虑进去,因为出栈的时候,连续的、相等的并且是最小值的元素要同步出栈;
(3)出栈的时候,辅助栈的栈顶元素等于数据栈的栈顶元素,才出栈。
解法
方法一:辅助栈和数据栈同步
import java.util.Stack;public class MinStack {// 数据栈private Stack<Integer> data;// 辅助栈private Stack<Integer> helper;/*** initialize your data structure here.*/public MinStack() {data = new Stack<>();helper = new Stack<>();}// 思路 1:数据栈和辅助栈在任何时候都同步public void push(int x) {// 数据栈和辅助栈一定会增加元素data.add(x);if (helper.isEmpty() || helper.peek() >= x) {helper.add(x);} else {helper.add(helper.peek());}}public void pop() {// 两个栈都得 popif (!data.isEmpty()) {helper.pop();data.pop();}}public int top() {if(!data.isEmpty()){return data.peek();}throw new RuntimeException("栈中元素为空,此操作非法");}public int getMin() {if(!helper.isEmpty()){return helper.peek();}throw new RuntimeException("栈中元素为空,此操作非法");}}
class MinStack:
# 辅助栈和数据栈同步
# 思路简单不容易出错
def __init__(self):
# 数据栈
self.data = []
# 辅助栈
self.helper = []
def push(self, x):
self.data.append(x)
if len(self.helper) == 0 or x <= self.helper[-1]:
self.helper.append(x)
else:
self.helper.append(self.helper[-1])
def pop(self):
if self.data:
self.helper.pop()
return self.data.pop()
def top(self):
if self.data:
return self.data[-1]
def getMin(self):
if self.helper:
return self.helper[-1]
方法二:辅助栈和数据栈不同步
import java.util.Stack;
public class MinStack {
// 数据栈
private Stack<Integer> data;
// 辅助栈
private Stack<Integer> helper;
/**
* initialize your data structure here.
*/
public MinStack() {
data = new Stack<>();
helper = new Stack<>();
}
// 思路 2:辅助栈和数据栈不同步
// 关键 1:辅助栈的元素空的时候,必须放入新进来的数
// 关键 2:新来的数小于或者等于辅助栈栈顶元素的时候,才放入(特别注意这里等于要考虑进去)
// 关键 3:出栈的时候,辅助栈的栈顶元素等于数据栈的栈顶元素,才出栈,即"出栈保持同步"就可以了
public void push(int x) {
// 辅助栈在必要的时候才增加
data.add(x);
// 关键 1 和 关键 2
if (helper.isEmpty() || helper.peek() >= x) {
helper.add(x);
}
}
public void pop() {
// 关键 3:data 一定得 pop()
if (!data.isEmpty()) {
// 注意:声明成 int 类型,这里完成了自动拆箱,从 Integer 转成了 int,因此下面的比较可以使用 "==" 运算符
// 参考资料:https://www.cnblogs.com/GuoYaxiang/p/6931264.html
// 如果把 top 变量声明成 Integer 类型,下面的比较就得使用 equals 方法
int top = data.pop();
if(top == helper.peek()){
helper.pop();
}
}
}
public int top() {
if(!data.isEmpty()){
return data.peek();
}
throw new RuntimeException("栈中元素为空,此操作非法");
}
public int getMin() {
if(!helper.isEmpty()){
return helper.peek();
}
throw new RuntimeException("栈中元素为空,此操作非法");
}
}
class MinStack:
# 辅助栈和数据栈不同步
# 关键 1:辅助栈的元素空的时候,必须放入新进来的数
# 关键 2:新来的数小于或者等于辅助栈栈顶元素的时候,才放入(特别注意这里等于要考虑进去)
# 关键 3:出栈的时候,辅助栈的栈顶元素等于数据栈的栈顶元素,才出栈,即"出栈保持同步"就可以了
def __init__(self):
# 数据栈
self.data = []
# 辅助栈
self.helper = []
def push(self, x):
self.data.append(x)
# 关键 1 和关键 2
if len(self.helper) == 0 or x <= self.helper[-1]:
self.helper.append(x)
def pop(self):
# 关键 3:【注意】不论怎么样,数据栈都要 pop 出元素
top = self.data.pop()
if self.helper and top == self.helper[-1]:
self.helper.pop()
return top
def top(self):
if self.data:
return self.data[-1]
def getMin(self):
if self.helper:
return self.helper[-1]
# Your MinStack object will be instantiated and called as such:
# obj = MinStack()
# obj.push(x)
# obj.pop()
# param_3 = obj.top()
# param_4 = obj.min()
5. 合法的出栈序列
描述 
思路
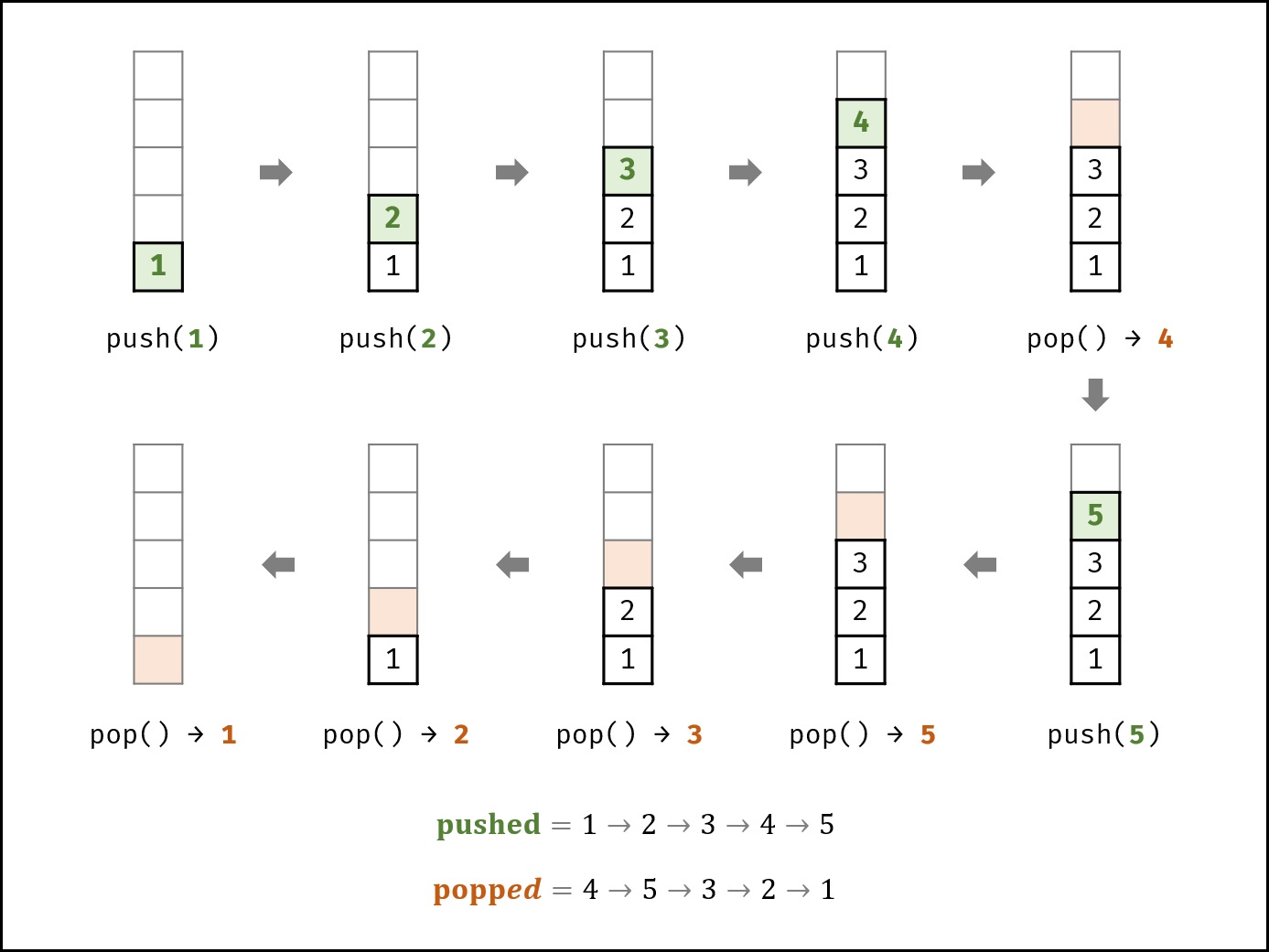
如下图所示,给定一个压入序列 pushed 和弹出序列 popped,则压入 / 弹出操作的顺序(即排列)是 唯一确定 的。
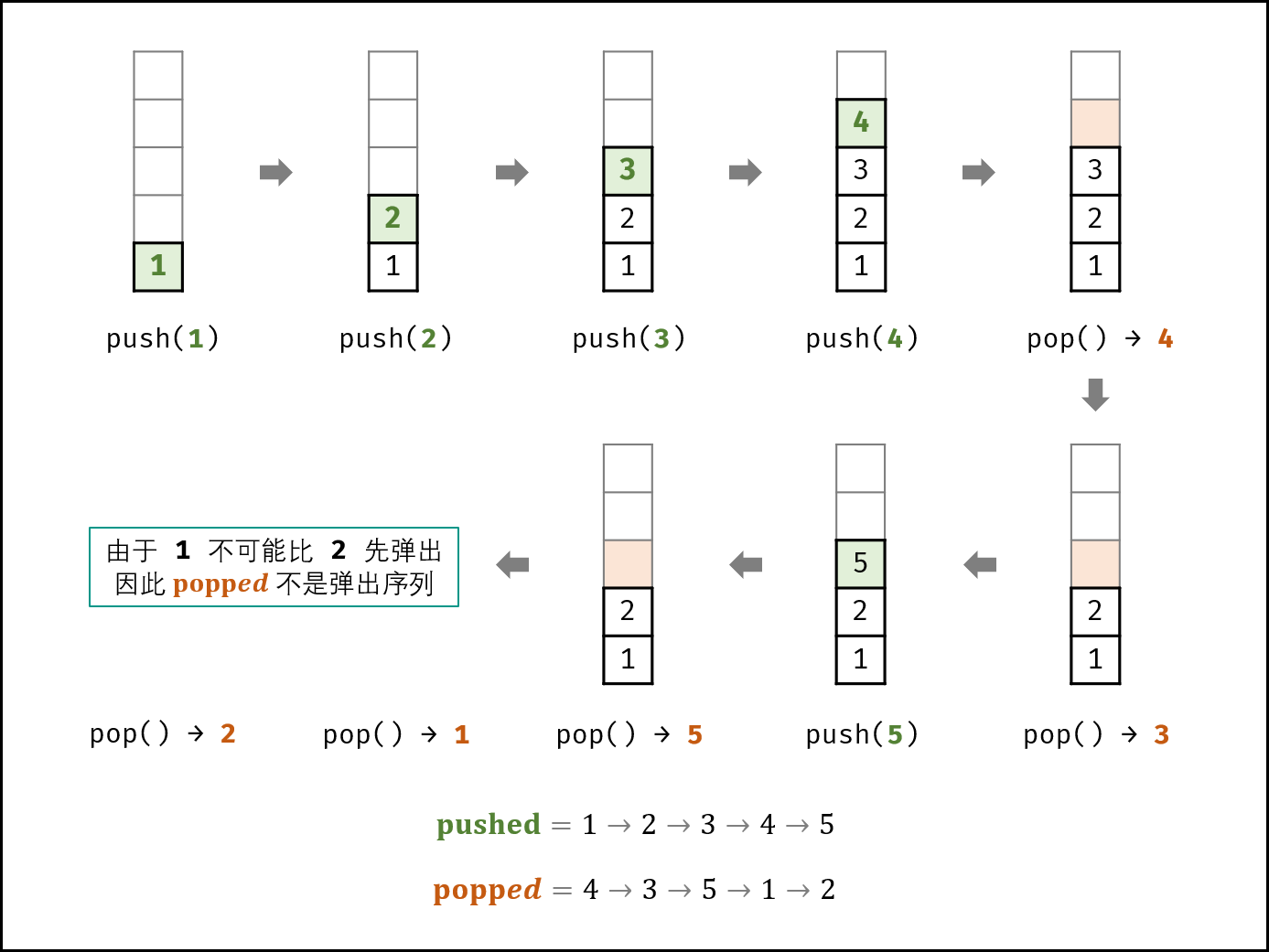
如下图所示,栈的数据操作具有 先入后出 的特性,因此某些弹出序列是无法实现的。
考虑借用一个辅助栈 stackstack ,模拟 压入 / 弹出操作的排列。根据是否模拟成功,即可得到结果。
入栈操作: 按照压栈序列的顺序执行。
出栈操作: 每次入栈后,循环判断 “栈顶元素 == 弹出序列的当前元素” 是否成立,将符合弹出序列顺序的栈顶元素全部弹出。
算法流程:
- 初始化: 辅助栈 stackstack ,弹出序列的索引 ii ;
- 遍历压栈序列: 各元素记为 numnum ;
- 元素 numnum 入栈;
- 循环出栈:若 stackstack 的栈顶元素 == 弹出序列元素 popped[i]popped[i] ,则执行出栈与 i++i++ ;
- 返回值: 若 stackstack 为空,则此弹出序列合法。
注意:我们在进行出栈操作时,记得判断栈是否为空
代码
class Solution:
def validateStackSequences(self, pushed: List[int], popped: List[int]) -> bool:
stack, i = [], 0
for num in pushed:
stack.append(num) # num 入栈
while stack and stack[-1] == popped[i]: # 循环判断与出栈
stack.pop()
i += 1
return not stack
class Solution {
public boolean validateStackSequences(int[] pushed, int[] popped) {
Stack<Integer> stack = new Stack<>();
int i = 0;
for(int num : pushed) {
stack.push(num); // num 入栈
while(!stack.isEmpty() && stack.peek() == popped[i]) { // 循环判断与出栈
stack.pop();
i++;
}
}
return stack.isEmpty();
}
}
复杂度分析:
时间复杂度 O(N) : 其中 N为列表 pushed 的长度;每个元素最多入栈与出栈一次,即最多共 2N 次出入栈操作。
空间复杂度 O(N) : 辅助栈 stack 最多同时存储 N 个元素。
6. 有效的括号
描述 
本文中看到的算法可用于处理编译器正在编译的程序中的所有括号,并检查是否所有括号都已配对。这将检查给定的括号字符串是否有效,是一个重要的编程问题。
思路
如果每当我们在表达式中遇到一对匹配的括号时,我们只是从表达式中删除它,会发生什么?
算法
- 初始化栈 S。
- 一次处理表达式的每个括号。
- 如果遇到开括号,我们只需将其推到栈上即可。这意味着我们将稍后处理它,让我们简单地转到前面的 子表达式。
- 如果我们遇到一个闭括号,那么我们检查栈顶的元素。如果栈顶的元素是一个 相同类型的 左括号,那么我们将它从栈中弹出并继续处理。否则,这意味着表达式无效。
- 如果到最后我们剩下的栈中仍然有元素,那么这意味着表达式无效。
代码
def isValid(self, s: str) -> bool:
"""
:type s: str
:rtype: bool
"""
# 栈用来保存开括号
stack = []
# 括号对
mapping = {")": "(", "}": "{", "]": "["}
# 遍历每个括号
for char in s:
# 如果是闭括号
if char in mapping:
# 如果栈不为空,弹出栈顶元素,否则用一个 # 号代替
top_element = stack.pop() if stack else '#'
# 如果栈顶元素不匹配,或者栈为空,则返回False
if mapping[char] != top_element:
return False
else:
# 开括号直接入栈
stack.append(char)
# 最后如果栈为空,说明是有效的
# 因为当括号为 ((() 时,最后栈可能不为空, 但它是无效的
return not stack
class Solution {
private HashMap<Character, Character> mappings;
public Solution() {
this.mappings = new HashMap<Character, Character>();
this.mappings.put(')', '(');
this.mappings.put('}', '{');
this.mappings.put(']', '[');
}
public boolean isValid(String s) {
Stack<Character> stack = new Stack<Character>();
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (this.mappings.containsKey(c)) {
char topElement = stack.empty() ? '#' : stack.pop();
if (topElement != this.mappings.get(c)) {
return false;
}
} else {
stack.push(c);
}
}
return stack.isEmpty();
}
}
注意:JAVA官方推荐我们使用Deque来实现栈,不推荐使用Stack。Deque同样支持push和pop操作。
Deque<Character> stack = new ArrayDeque<>();
复杂度分析
时间复杂度:O(n),因为我们一次只遍历给定的字符串中的一个字符并在栈上进行 O(1) 的推入和弹出操作。
空间复杂度:O(n),当我们将所有的开括号都推到栈上时以及在最糟糕的情况下,我们最终要把所有括号推到栈上。例如 ((((((((((。
7. 每日温度
描述 
思路
可以维护一个存储下标的单调栈,从栈底到栈顶的下标对应的温度列表中的温度依次递减。如果一个下标在单调栈里,则表示尚未找到下一次温度更高的下标。
正向遍历温度列表。对于温度列表中的每个元素 T[i],如果栈为空,则直接将 i 进栈,如果栈不为空,则比较栈顶元素 prevIndex 对应的温度 T[prevIndex] 和当前温度 T[i],如果 T[i] > T[prevIndex],则将 prevIndex 移除,并将 prevIndex 对应的等待天数赋为 i - prevIndex,重复上述操作直到栈为空或者栈顶元素对应的温度小于等于当前温度,然后将 i 进栈。
为什么可以在弹栈的时候更新 ans[prevIndex] 呢?因为在这种情况下,即将进栈的 i 对应的 T[i] 一定是 T[prevIndex] 右边第一个比它大的元素,试想如果 prevIndex 和 i 有比它大的元素,假设下标为 j,那么 prevIndex 一定会在下标 j 的那一轮被弹掉。
代码
class Solution:
def dailyTemperatures(self, T: List[int]) -> List[int]:
length = len(T)
res = [0]*length
stack = []
for i in range(length):
curent_temp = T[i]
while stack and curent_temp > T[stack[-1]]:
pre_index = stack.pop()
res[pre_index] = i - pre_index
stack.append(i)
return res
class Solution {
public int[] dailyTemperatures(int[] T) {
int length = T.length;
int[] ans = new int[length];
Deque<Integer> stack = new LinkedList<Integer>();
for (int i = 0; i < length; i++) {
int temperature = T[i];
while (!stack.isEmpty() && temperature > T[stack.peek()]) {
int prevIndex = stack.pop();
ans[prevIndex] = i - prevIndex;
}
stack.push(i);
}
return ans;
}
}
注意:很多时候,我们要判断栈是否为空,再进行弹出操作。
8. 接雨水
描述
思路
方法一、暴力解法
直接按问题描述进行。对于数组中的每个元素,我们找出下雨后水能达到的最高位置,等于两边最大高度的较小值减去当前高度的值。
算法
- 初始化 ans=0
- 从左向右扫描数组:
- 初始化 max_left=0 和 max_right=0
- 从当前元素向左扫描并更新:
max_left=max(max_left,height[j])
- 从当前元素向右扫描并更新:
max_right=max(max_right,height[j])
- min(max_left,max_right)−height[i] 累加到 }ans
复杂性分析class Solution { public int trap(int[] height) { int ans = 0; int len = height.length; for (int i = 0; i < len; i++) { int left_max = 0, right_max = 0; for (int j = i; j >= 0; j--) { left_max = Math.max(left_max, height[j]); } for (int k = i; k < len; k++) { right_max = Math.max(right_max, height[k]); } ans += Math.min(left_max, right_max) - height[i]; } return ans; } }
- 时间复杂度: O(n^2)。数组中的每个元素都需要向左向右扫描。
- 空间复杂度 O(1) 的额外空间。
方法二、动态编程
算法
- 找到数组中从下标 i 到最左端最高的条形块高度 left_max。
- 找到数组中从下标 i 到最右端最高的条形块高度 right_max。
- 扫描数组 height 并更新答案:
- 累加 min(max_left[i],max_right[i])−height[i] 到 ans 上
代码
int trap(vector<int>& height)
{
if(height == null)
return 0;
int ans = 0;
int size = height.size();
vector<int> left_max(size), right_max(size);
left_max[0] = height[0];
for (int i = 1; i < size; i++) {
left_max[i] = max(height[i], left_max[i - 1]);
}
right_max[size - 1] = height[size - 1];
for (int i = size - 2; i >= 0; i--) {
right_max[i] = max(height[i], right_max[i + 1]);
}
for (int i = 1; i < size - 1; i++) {
ans += min(left_max[i], right_max[i]) - height[i];
}
return ans;
}
class Solution {
public int trap(int[] height) {
int ans = 0;
int size = height.length;
if (size == 0) {
return 0;
}
int[] left_max = new int[size + 1];
int[] right_max = new int[size + 1];
left_max[0] = height[0];
for (int i = 1; i < size - 1; i++) {
left_max[i] = Math.max(left_max[i-1], height[i]);
}
right_max[size - 1] = height[size - 1];
for (int j = size - 2; j >= 0; j--) {
right_max[j] = Math.max(right_max[j+1], height[j]);
}
for (int k = 0; k < size - 1; k++) {
ans += Math.min(right_max[k], left_max[k]) - height[k];
}
return ans;
}
}
方法三、栈
思路
我们可以不用像方法 2 那样存储最大高度,而是用栈来跟踪可能储水的最长的条形块。使用栈就可以在一次遍历内完成计算。
我们在遍历数组时维护一个栈。如果当前的条形块小于或等于栈顶的条形块,我们将条形块的索引入栈,意思是当前的条形块被栈中的前一个条形块界定。如果我们发现一个条形块长于栈顶,我们可以确定栈顶的条形块被当前条形块和栈的前一个条形块界定,因此我们可以弹出栈顶元素并且累加答案到 ans 。
算法
- 使用栈来存储条形块的索引下标。
- 遍历数组:
- 当栈非空且 height[current]>height[st.top()]
- 意味着栈中元素可以被弹出。弹出栈顶元素 top。
- 计算当前元素和栈顶元素的距离,准备进行填充操作
- 当栈非空且 height[current]>height[st.top()]
distance=current−st.top()−1
- 找出界定高度
bounded_height=min(height[current],height[st.top()])−height[top]
- 往答案中累加积水量
ans+=distance×bounded_height
- 将当前索引下标入栈
- 将 current 移动到下个位置
class Solution: def trap(self, height: List[int]) -> int: sta = [] n = len(height) if n < 3: return 0 res = 0 for i in range(n): while sta and height[i] > height[sta[-1]]: top = sta.pop() if not sta: break min_height = min(height[i], height[sta[-1]]) - height[top] distance = i - sta[-1] - 1 res += distance * min_height sta.append(i) return resclass Solution { public int trap(int[] height) { int size = height.length; if (size < 3) return 0; Deque<Integer> sta = new ArrayDeque<>(); int ans = 0; for (int i = 0; i < size; i++) { while (!sta.isEmpty() && height[i] > height[sta.peek()]) { int top = sta.pop(); if (sta.isEmpty()) break; int distance = i - sta.peek() - 1; int bounded_height = Math.min(height[i], height[sta.peek()]) - height[top]; ans += distance * bounded_height; } sta.push(i); } return ans; } }9. 下一个更大元素 I
描述
思路
我们可以忽略数组 nums1,先对将 nums2 中的每一个元素,求出其下一个更大的元素。随后对于将这些答案放入哈希映射(HashMap)中,再遍历数组 nums1,并直接找出答案。对于 nums2,我们可以使用单调栈来解决这个问题。
我们首先把第一个元素 nums2[1] 放入栈,随后对于第二个元素 nums2[2],如果 nums2[2] > nums2[1],那么我们就找到了 nums2[1] 的下一个更大元素 nums2[2],此时就可以把 nums2[1] 出栈并把 nums2[2] 入栈;如果 nums2[2] <= nums2[1],我们就仅把 nums2[2] 入栈。对于第三个元素 nums2[3],此时栈中有若干个元素,那么所有比 nums2[3] 小的元素都找到了下一个更大元素(即 nums2[3]),因此可以出栈,在这之后,我们将 nums2[3] 入栈,以此类推。
可以发现,我们维护了一个单调栈,栈中的元素从栈顶到栈底是单调不降的。当我们遇到一个新的元素 nums2[i] 时,我们判断栈顶元素是否小于 nums2[i],如果是,那么栈顶元素的下一个更大元素即为 nums2[i],我们将栈顶元素出栈。重复这一操作,直到栈为空或者栈顶元素大于 nums2[i]。此时我们将 nums2[i] 入栈,保持栈的单调性,并对接下来的 nums2[i + 1], nums2[i + 2] … 执行同样的操作。
解法
- 根据nums2初始化哈希表,key为其中的元素,value为-1;
- 遍历nums2,当前元素为current;
- 如果栈不为空,并且current大于栈顶元素,弹出栈顶元素item,并将
- 重复上面操作,直至current小于等于栈顶元素,将current入栈。
- 其他情况,将current入栈即可。
- 如果栈不为空,并且current大于栈顶元素,弹出栈顶元素item,并将
- 遍历nums1,对每个元素,获取哈希表中值即为所求。
代码
class Solution:
def nextGreaterElement(self, nums1: List[int], nums2: List[int]) -> List[int]:
length = len(nums2)
d = {item:-1 for item in nums2}
res = []
stack = []
for item in nums2:
while stack and item > stack[-1]:
d[stack.pop()] = item
stack.append(item)
for item in nums1:
res.append(d[item])
return res
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
Deque<Integer> sta = new ArrayDeque<>();
HashMap<Integer, Integer> map = new HashMap<>();
int[] res = new int[nums1.length];
for (int i = 0; i < nums2.length; i++) {
while (!sta.isEmpty() && nums2[i] > sta.peek()) {
map.put(sta.pop(), nums2[i]);
}
sta.push(nums2[i]);
}
while (!sta.isEmpty()) {
map.put(sta.pop(), -1);
}
for (int i = 0; i < res.length; i++) {
res[i] = map.get(nums1[i]);
}
return res;
}
}
复杂度分析
时间复杂度:O(N + M),分别为nums2和nums1的长度。
空间复杂度:O(N),用了栈和哈希表。
10.下一个更大元素 II
描述
解题思路
我们可以依然可以使用单调栈来解决这个问题。
我们首先把第一个元素 A[1] 放入栈,随后对于第二个元素 A[2],如果 A[2] > A[1],那么我们就找到了 A[1] 的下一个更大元素 A[2],此时就可以把 A[1] 出栈并把 A[2] 入栈;如果 A[2] <= A[1],我们就仅把 A[2] 入栈。对于第三个元素 A[3],此时栈中有若干个元素,那么所有比 A[3] 小的元素都找到了下一个更大元素(即 A[3]),因此可以出栈,在这之后,我们将 A[3] 入栈,以此类推。
由于这道题的数组是循环数组,因此我们需要将每个元素都入栈两次。这样可能会有元素出栈过一次,即得到了超过一个“下一个更大元素”,我们只需要保留第一个出栈的结果即可。
具体做法就是遍历次数变为2倍,每次将变量 i 对数组长度取余即可。
代码
class Solution {
public int[] nextGreaterElements(int[] nums) {
int size = nums.length;
int[] res = new int[size];
Deque<Integer> sta = new ArrayDeque<>();
for (int i = size * 2 - 1; i >= 0; i--) {
while (!sta.isEmpty() && nums[sta.peek()] <= nums[i % size]) {
sta.pop();
}
res[i % size] = sta.isEmpty() ? -1 : nums[sta.peek()];
sta.push(i % size);
}
return res;
}
}
class Solution:
def nextGreaterElements(self, nums: List[int]) -> List[int]:
size = len(nums)
res = [-1] * size
sta = []
for i in range(2*size - 1, -1, -1):
while sta and nums[sta[-1]] <= nums[i % size]:
sta.pop()
res[i % size] = nums[sta[-1]] if sta else -1
sta.append(i % size)
return res
注意:这里是采用从右往左遍历,其原理是一致,请读者仔细体会。下面是从左往右遍历的代码。
class Solution {
public int[] nextGreaterElements(int[] nums) {
int[] res = new int[nums.length];
Arrays.fill(res, -1);
Stack<Integer> stack = new Stack<>(); // 存储的是索引index
// 由于是循环数组,对于末位元素,要往后循环考虑到其前一位数也就是倒数第二个数
for(int i = 0; i < 2 * nums.length; i++) {
// 对于当前元素,弹出栈中小于当前元素的元素,这些被弹出的元素的"下一个更大元素"就是当前元素
// 一个元素只有入栈后再被弹出,才能得到该元素的"下一个更大元素",否则无"下一个更大元素",res[i]默认为-1
// 例如,对于最大的元素,其一直留在栈中无法被弹出,因此其"下一个更大元素"默认为-1
while(!stack.empty() && nums[stack.peek()] < nums[i % nums.length])
res[stack.pop()] = nums[i % nums.length];
stack.push(i % nums.length);
}
return res;
}
}
复杂度分析
- 时间复杂度:O(N)。
- 空间复杂度:O(N))。
11. 移掉K位数字
描述
解题思路
对于两个相同长度的数字序列,最左边不同的数字决定了这两个数字的大小,例如,对于 A = 1axxx,B = 1bxxx,如果 a > b 则 A > B。
知道了这个以后,我们可以想到,在删除数字时应该从左向右迭代。
确定了迭代的顺序以后,就必须制定如何消除数字的标准,以便获得最小值。
让我们从一个简单的例子开始。给定一个数字序列,例如 425,如果要求我们只删除一个数字,那么从左到右,我们有 4、2 和 5 三个选择。我们将每一个数字和它的左邻居进行比较。从 2 开始,小于它的左邻居 4。则我们应该去掉数字 4。如果不这么做,则随后无论做什么,都不会得到最小数。
我们可以总结上述删除一个数字的规则,如下:
给定一个数字序列 [D1, D2, D3, … , Dn],如果D2 小于其左邻居,则我们应该删除 D1。
算法
我们会注意到,在某些情况下,规则对任意数字都不适用,即单调递增序列。在这种情况下,我们只需要删除末尾的数字来获得最小数。
我们可以利用栈来实现上述算法,存储当前迭代数字之前的数字。
- 对于每个数字,如果该数字小于栈顶部,即该数字的左邻居,则弹出堆栈,即删除左邻居。否则,我们把数字推到栈上。
- 我们重复上述步骤(1),直到任何条件不再适用,例如堆栈为空(不再保留数字)。或者我们已经删除了 k 位数字。
代码
class Solution:
def removeKdigits(self, num: str, k: int) -> str:
sta = []
for digit in num:
while k and sta and sta[-1] > digit:
sta.pop()
k -= 1
sta.append(digit)
if (k > 0):
sta = sta[:-k]
return "".join(sta).lstrip("0") or "0"
class Solution {
public String removeKdigits(String num, int k) {
LinkedList<Character> stack = new LinkedList<Character>();
for(char digit : num.toCharArray()) {
while(stack.size() > 0 && k > 0 && stack.peekLast() > digit) {
stack.removeLast();
k -= 1;
}
stack.addLast(digit);
}
/* remove the remaining digits from the tail. */
for(int i=0; i<k; ++i) {
stack.removeLast();
}
// build the final string, while removing the leading zeros.
StringBuilder ret = new StringBuilder();
boolean leadingZero = true;
for(char digit: stack) {
if(leadingZero && digit == '0') continue;
leadingZero = false;
ret.append(digit);
}
/* return the final string */
if (ret.length() == 0) return "0";
return ret.toString();
}
}
复杂度分析
时间复杂度:O(N)。尽管存在嵌套循环,但内部循环最多只能运行 kk次。由于 0
12. 去除重复字母
描述
思路
首先要知道什么叫 “字典序”。字符串之间比较跟数字之间比较是不太一样的。字符串比较是从头往后一个字符一个字符比较的。哪个字符串大取决于两个字符串中 第一个对应不相等的字符 。根据这个规则,任意一个以 a 开头的字符串都大于任意一个以 b 开头的字符串。
综上所述,解题过程中我们将 最小的字符尽可能的放在前面 。下面将给出两种 O(N)复杂度的解法:
- 方法一:题目要求最终返回的字符串必须包含所有出现过的字母,同时得让字符串的字典序最小。因此,对于最终返回的字符串,最左侧的字符是在能保证其他字符至少能出现一次情况下的最小字符。
- 方法二:在遍历字符串的过程中,如果字符 i 大于字符i+1,在字符 i 不是最后一次出现的情况下,删除字符 i。
方法一:贪心 - 一个字符一个字符处理
算法
每次递归中,在保证其他字符至少出现一次的情况下,确定最小左侧字符。之后再将未处理的后缀字符串继续递归。
代码
from collections import Counter
class Solution:
def removeDuplicateLetters(self, s: str) -> str:
# find pos - the index of the leftmost letter in our solution
# we create a counter and end the iteration once the suffix doesn't have each unique character
# pos will be the index of the smallest character we encounter before the iteration ends
c = Counter(s)
pos = 0
for i in range(len(s)):
if s[i] < s[pos]: pos = i
c[s[i]] -=1
if c[s[i]] == 0: break
# our answer is the leftmost letter plus the recursive call on the remainder of the string
# note we have to get rid of further occurrences of s[pos] to ensure that there are no duplicates
return s[pos] + self.removeDuplicateLetters(s[pos:].replace(s[pos], "")) if s else ''
public class Solution {
public String removeDuplicateLetters(String s) {
// find pos - the index of the leftmost letter in our solution
// we create a counter and end the iteration once the suffix doesn't have each unique character
// pos will be the index of the smallest character we encounter before the iteration ends
int[] cnt = new int[26];
int pos = 0;
for (int i = 0; i < s.length(); i++) cnt[s.charAt(i) - 'a']++;
for (int i = 0; i < s.length(); i++) {
if (s.charAt(i) < s.charAt(pos)) pos = i;
if (--cnt[s.charAt(i) - 'a'] == 0) break;
}
// our answer is the leftmost letter plus the recursive call on the remainder of the string
// note that we have to get rid of further occurrences of s[pos] to ensure that there are no duplicates
return s.length() == 0 ? "" : s.charAt(pos) + removeDuplicateLetters(s.substring(pos + 1).replaceAll("" + s.charAt(pos), ""));
}
}
复杂度分析
时间复杂度:O(N)。 每次递归调用占用 O(N) 时间。递归调用的次数受常数限制(只有26个字母),最终复杂度为 O(N)∗C=O(N)。
空间复杂度:O(N),每次给字符串切片都会创建一个新的字符串(字符串不可变),切片的数量受常数限制,最终复杂度为 O(N)∗C=O(N)。
方法二:贪心 - 用栈
算法
用栈来存储最终返回的字符串,并维持字符串的最小字典序。每遇到一个字符,如果这个字符不存在于栈中,就需要将该字符压入栈中。可以用一个set记录在栈中的元素。在压入之前,需要先将之后还会出现,并且字典序比当前字符小的栈顶字符移除,然后再将当前字符压入。
代码
class Solution {
public String removeDuplicateLetters(String s) {
Deque<Character> sta = new ArrayDeque<>();
Set<Character> set = new HashSet<>();
Map<Character, Integer> lastIndexMap = new HashMap<>();
for (int i = 0; i < s.length(); i++) {
lastIndexMap.put(s.charAt(i), i);
}
for (int i = 0; i < s.length(); i++) {
if (!set.contains(s.charAt(i))) {
while (!sta.isEmpty() && s.charAt(i) < sta.peek() && lastIndexMap.get(sta.peek()) > i) {
set.remove(sta.pop());
}
sta.push(s.charAt(i));
set.add(s.charAt(i));
}
}
StringBuilder res = new StringBuilder(sta.size());
for (Character c : sta) {
res.append(c);
}
return res.reverse().toString();
}
}
class Solution:
def removeDuplicateLetters(self, s: str) -> str:
sta = []
seen = set()
last_index = {item : index for index, item in enumerate(s)}
for i in range(len(s)):
if s[i] not in seen:
while sta and sta[-1] > s[i] and last_index[sta[-1]] > i:
seen.remove(sta.pop())
sta.append(s[i])
seen.add(s[i])
return "".join(sta)
/**
* @param {string} s
* @return {string}
*/
var removeDuplicateLetters = function(s) {
let sta = [];
let seen = new Set();
let last_index = new Map();
for(let i = 0; i < s.length; i++) {
last_index.set(s[i], i);
}
for (let i = 0; i < s.length; i++) {
if (!seen.has(s[i])) {
while (sta.length > 0 && sta[sta.length - 1] > s[i] && last_index.get(sta[sta.length - 1]) > i) {
seen.delete(sta.pop());
}
sta.push(s[i]);
seen.add(s[i]);
}
}
return sta.join("");
};
注意: 栈顶元素弹出时,要将set中的元素也对应删掉。
13. 拼接最大数
描述
思路
通常字符串和数字的最大最小问题,且输入是无序状态的数组,一般都会用到栈。
假设我们从 nums1 中取了 k1 个,从 num2 中取了 k2 个,其中 k1 + k2 = k。而 k1 和 k2 这 两个子问题我们是会解决的。由于这两个子问题是相互独立的,因此我们只需要分别求解,然后将结果合并即可。
假如 k1 和 k2 个数字,已经取出来了。那么剩下要做的就是将这个长度分别为 k1 和 k2 的数字,合并成一个长度为 k 的数组合并成一个最大的数组。
以题目的 nums1 = [3, 4, 6, 5] nums2 = [9, 1, 2, 5, 8, 3] k = 5 为例。 假如我们从 num1 中取出 1 个数字,那么就要从 nums2 中取出 4 个数字。
我们计算出应该取 nums1 的 [6],并取 nums2 的 [9,5,8,3]。 如何将 [6] 和 [9,5,8,3],使得数字尽可能大,并且保持相对位置不变呢?
实际上这个过程有点类似归并排序中的治,而上面我们分别计算 num1 和 num2 的最大数的过程类似归并排序中的分。
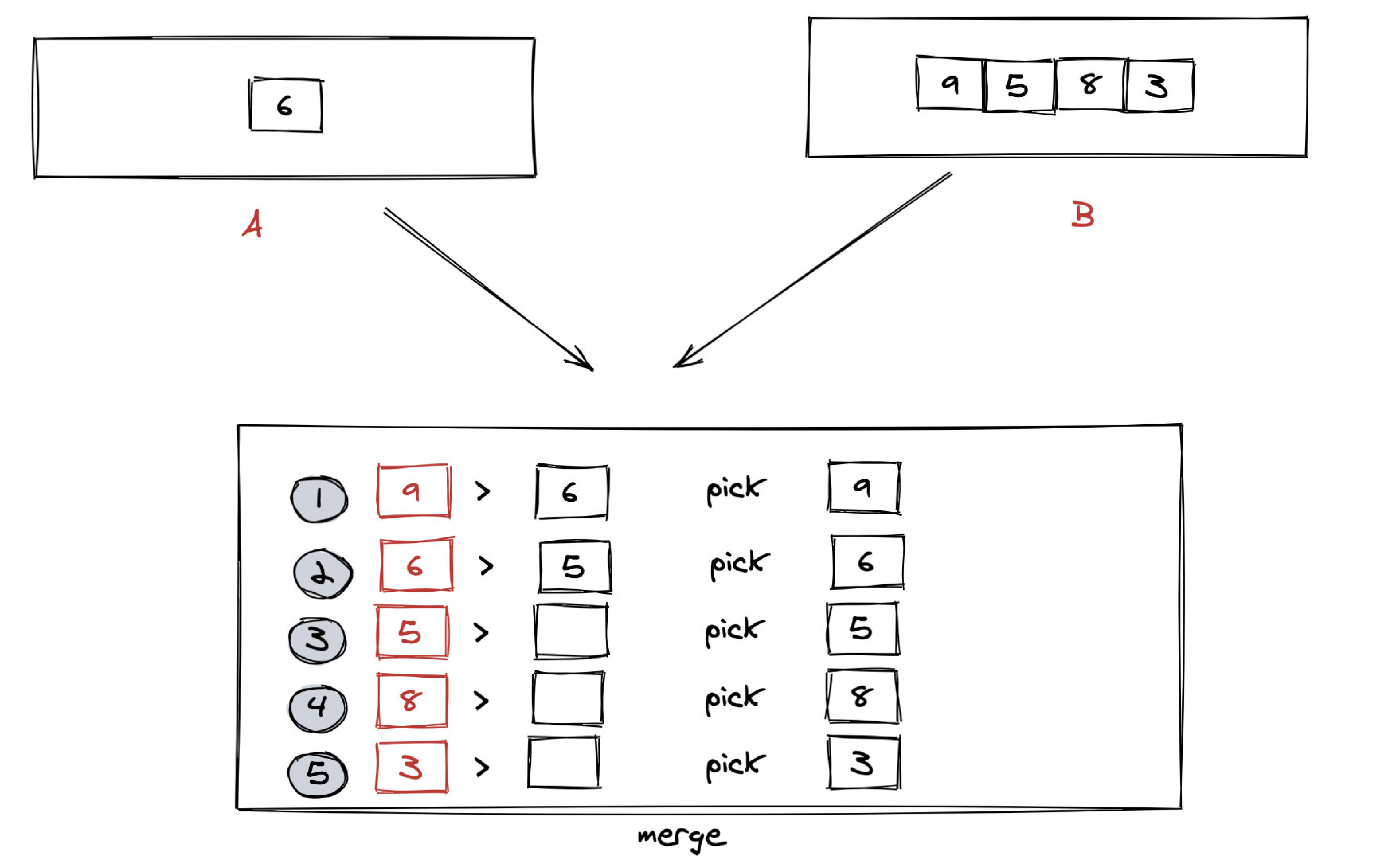
以合并 [6] 和 [9,5,8,3] 为例,图解过程如下:
具体算法:
从 nums1 中 取 min(i, len(nums1))min(i,len(nums1)) 个数形成新的数组 A(取的逻辑同第11题),其中 i 等于 0,1,2, … k。
从 nums2 中 对应取 min(j, len(nums2))min(j,len(nums2)) 个数形成新的数组 B(取的逻辑同第11题),其中 j 等于 k - i。
将 A 和 B 按照上面的 merge 方法合并
上面我们暴力了 k 种组合情况,我们只需要将 k 种情况取出最大值即可。
代码
class Solution:
def maxNumber(self, nums1: List[int], nums2: List[int], k: int) -> List[int]:
def pick_max(nums, k):
"""
删掉len - k 个数字后,组成的最大数字
"""
# 单调栈
sta = []
# 需要丢弃的数量, 最终要保证剩下的数字组成的数字较大
drop = len(nums) - k
for num in nums:
while drop and sta and sta[-1] < num:
sta.pop()
drop -= 1
sta.append(num)
# 如果是降序的话,for循环结束,一个元素都不会删除
return sta[:k]
def merge(A, B):
"""
两个数组合并
"""
ans = []
# 这里是or,要让两个数组都遍历完
while A or B:
bigArr = A if A > B else B
ans.append(bigArr.pop(0))
return ans
res = []
for i in range(k + 1):
if i <= len(nums1) and k - i <= len(nums2):
res = max(res, merge(pick_max(nums1, i), pick_max(nums2, k-i)))
return res
14. 不同字符的最小子序列
描述 
思路
单调栈,用一个set记录栈中出现的元素,遍历字符串,当栈顶元素大于当前字符串时候,且未来还会出现该字符串的时候,出栈。
否则入栈,将当前元素加入set中,最后栈中的元素即为最小且无重复字符的字符串。
代码
Python代码:
class Solution:
def smallestSubsequence(self, text: str) -> str:
last_index = {}
for idx, c in enumerate(text):
last_index[c] = idx
sta = []
seen = set()
for i, c in enumerate(text):
if c in seen:
continue
while sta and sta[-1] > c and last_index[sta[-1]] > i:
seen.remove(sta.pop())
sta.append(c)
seen.add(c)
return "".join(sta)
Java代码:
class Solution {
public String smallestSubsequence(String text) {
Map<Character, Integer> lastIndex = new HashMap<>();
Set<Character> seen = new HashSet<>();
for(int i = 0; i < text.length(); i++) {
lastIndex.put(text.charAt(i), i);
}
Deque<Character> sta = new ArrayDeque<>();
for (int i = 0; i < text.length(); i++) {
char c = text.charAt(i);
if (seen.contains(c)) {
continue;
}
while (!sta.isEmpty() && sta.peekLast() > c && lastIndex.get(sta.peekLast()) > i) {
seen.remove(sta.pollLast());
}
sta.addLast(c);
seen.add(c);
}
StringBuilder res = new StringBuilder();
for (Character c : sta) {
res.append(c);
}
return res.toString();
}
}
15. 最短无序连续子数组
描述 
思路
单调栈,我们从头遍历 nums 数组,如果遇到的数字大小一直是升序的,我们就不断把对应的下标压入栈中,这么做的目的是因为这些元素在目前都是处于正确的位置上。一旦我们遇到前面的数比后面的数大,也就是 nums[j] 比栈顶元素小,我们可以知道 nums[j] 一定不在正确的位置上。
为了找到 nums[j] 的正确位置,我们不断将栈顶元素弹出,直到栈顶元素比 nums[j] 小,我们假设栈顶元素对应的下标为 k ,那么我们知道 nums[j] 的正确位置下标应该是 k+1 。
我们重复这一过程并遍历完整个数组,这样我们可以找到最小的 k, 它也是无序子数组的左边界。
类似的,我们逆序遍历一遍 nums 数组来找到无序子数组的右边界。这一次我们将降序的元素压入栈中,如果遇到一个升序的元素,我们像上面所述的方法一样不断将栈顶元素弹出,直到找到一个更大的元素,以此找到无序子数组的右边界。
代码
Java代码:
class Solution {
public int findUnsortedSubarray(int[] nums) {
Deque<Integer> sta = new ArrayDeque<>();
int l = nums.length;
int r = 0;
for (int i = 0; i < nums.length; i++) {
while (!sta.isEmpty() && nums[sta.peek()] > nums[i]) {
l = Math.min(l, sta.pop());
}
sta.push(i);
}
sta.clear();
for (int i = nums.length - 1; i >= 0; i--) {
while (!sta.isEmpty() && nums[sta.peek()] < nums[i]) {
r = Math.max(r, sta.pop());
}
sta.push(i);
}
return r - l > 0? r - l + 1 : 0;
}
}
Python代码:
class Solution:
def findUnsortedSubarray(self, nums: List[int]) -> int:
n = len(nums)
sta = []
left = n
right = 0
for i in range(n):
while sta and nums[sta[-1]] > nums[i]:
left = min(left, sta.pop())
sta.append(i)
sta = []
for i in range(n-1, -1, -1):
while sta and nums[sta[-1]] < nums[i]:
right = max(right, sta.pop())
sta.append(i)
return right - left + 1 if right - left > 0 else 0
18. 逆波兰表达式求值
描述
逆波兰表达式: 逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
平常使用的算式则是一种中缀表达式,如 ( 1 + 2 ) ( 3 + 4 ) 。 该算式的逆波兰表达式写法为 ( ( 1 2 + ) ( 3 4 + ) ) 。
逆波兰表达式主要有以下两个优点: 去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + 也可以依据次序计算出正确结果。 *适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中。
思路
上面已经提到了,适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中。
算法流程
- 遍历token数组
- 如果是数字直接入栈,如果是操作符,将栈顶的两个元素弹出,计算的结果再入栈
- 最后栈应该只有一个元素,返回即为结果。
代码
class Solution {
public int evalRPN(String[] tokens) {
Deque<Integer> numStack = new ArrayDeque<>();
Integer op1, op2;
for (String s : tokens) {
switch (s) {
case "+":
op2 = numStack.pop();
op1 = numStack.pop();
numStack.push(op1 + op2);
break;
case "-":
op2 = numStack.pop();
op1 = numStack.pop();
numStack.push(op1 - op2);
break;
case "*":
op2 = numStack.pop();
op1 = numStack.pop();
numStack.push(op1 * op2);
break;
case "/":
op2 = numStack.pop();
op1 = numStack.pop();
numStack.push(op1 / op2);
break;
default:
numStack.push(Integer.valueOf(s));
break;
}
}
return numStack.pop();
}
}
1.数组最大长度为tokens.length / 2 + 1 2.switch代替if-else,效率优化 3.Integer.parseInt代替Integer.valueOf,减少自动拆箱装箱操作
class Solution:
def evalRPN(self, tokens: List[str]) -> int:
sta = []
for s in tokens:
if s == "+":
op1 = int(sta.pop())
op2 = int(sta.pop())
sta.append(op2 + op1)
elif s == "-":
op1 = int(sta.pop())
op2 = int(sta.pop())
sta.append(op2 - op1)
elif s == "*":
op1 = int(sta.pop())
op2 = int(sta.pop())
sta.append(op2 * op1)
elif s == "/":
op1 = int(sta.pop())
op2 = int(sta.pop())
sta.append(op2 / op1)
else:
sta.append(int(s))
return int(sta.pop())
python中 eval 函数可以直接计算字符串表达式的值
print(eval("1*2")) # 2
19. 基本计算器
描述
思路
解决这个问题需要理解以下内容:
- 输入始终包含有效的字符串。
- 加减法规则。
- 括号中的优先含义。
- 空格不影响输入表达式的计算。
因为表达式中包含括号,我们可以使用栈来查找每个子表达式的值。本质上,我们需要延迟处理主表达式,直到完成对括号种的中间子表达式的求值,我们使用栈来解决它。
我们将表达式的元素一个接一个的添加到栈上,直到我们遇到一个右括号 )。然后逐个弹出栈中的元素,在运行时对子表达式进行求值,直到遇到左括号 ( 为止。
我们需要理解 + 和 - 的区别。+ 遵循结合律。例如 A+B+CA+B+C,等价为 (A+B)+C = A+(B+C)(A+B)+C=A+(B+C)。然后 - 不遵循这个一规则,这是该方法中所有问题的根本原因。
如果我们使用栈并从左到右读取表达式的元素,则最终我们会从右到左计算表达式。就会出现 (A-B)-C(A−B)−C 等于 (C-B)-A(C−B)−A 的情况,这是不正确的。减法即不遵循结合律也不遵循交换律。
这个问题很容易解决,我们通过反转字符串,然后再按需添加到栈中,我们将字符串从右到左放入栈中,并从左到右正确的计算表达式。
方法一:栈和反转字符串
算法
- 按逆序迭代字符串。
- 操作数可以由多个字符组成,字符串 “123” 表示数字 123,它可以被构造为:123 >> 120 + 3 >> 100 + 20 + 3。如果我们读取的字符是一个数字,则我们要将读取的数字乘以 10 的幂并将当前数字相加,形成操作数。因为我们是按逆序处理字符串。
- 操作数由多个字符组成,一旦我们遇到的字符不是数字,则我们将操作数添加到栈上。
- 当我们遇到最括号 (,这意味这遇到了一个子表达式结束。由于我们是逆序,所以开括号成了表达式的结尾。则需要从栈中弹出操作数和运算发来计算表达式,直到弹出相应的右括号。子表达式的最终结果最终添加到栈上。
- 将非数字字符添加到栈上。
- 这个做直到我们得到最终的结果。可能我们没有更多的字符要处理,但是栈仍然是非空的。当主表达式没有用括号括起来时,就会发生这种情况。因此,在完成对整个表达式求值之后,我们将检查栈是否非空。如果是的话,我们将栈中的元素作为最终表达式处理,并像遇到左括号时那样对其求值。我们还可以用一组括号覆盖原表达式,以此避免额外调用。
代码
def evaluate_expr(self, stack):
res = stack.pop() if stack else 0
# Evaluate the expression till we get corresponding ')'
while stack and stack[-1] != ')':
sign = stack.pop()
if sign == '+':
res += stack.pop()
else:
res -= stack.pop()
return res
def calculate(self, s: str) -> int:
stack = []
n, operand = 0, 0
for i in range(len(s) - 1, -1, -1):
ch = s[i]
if ch.isdigit():
# Forming the operand - in reverse order.
operand = (10**n * int(ch)) + operand
n += 1
elif ch != " ":
if n:
# Save the operand on the stack
# As we encounter some non-digit.
stack.append(operand)
n, operand = 0, 0
if ch == '(':
res = self.evaluate_expr(stack)
stack.pop()
# Append the evaluated result to the stack.
# This result could be of a sub-expression within the parenthesis.
stack.append(res)
# For other non-digits just push onto the stack.
else:
stack.append(ch)
# Push the last operand to stack, if any.
if n:
stack.append(operand)
# Evaluate any left overs in the stack.
return self.evaluate_expr(stack)
class Solution {
public int evaluateExpr(Stack<Object> stack) {
int res = 0;
if (!stack.empty()) {
res = (int) stack.pop();
}
// Evaluate the expression till we get corresponding ')'
while (!stack.empty() && !((char) stack.peek() == ')')) {
char sign = (char) stack.pop();
if (sign == '+') {
res += (int) stack.pop();
} else {
res -= (int) stack.pop();
}
}
return res;
}
public int calculate(String s) {
int operand = 0;
int n = 0;
Stack<Object> stack = new Stack<Object>();
for (int i = s.length() - 1; i >= 0; i--) {
char ch = s.charAt(i);
if (Character.isDigit(ch)) {
// Forming the operand - in reverse order.
operand = (int) Math.pow(10, n) * (int) (ch - '0') + operand;
n += 1;
} else if (ch != ' ') {
if (n != 0) {
// Save the operand on the stack
// As we encounter some non-digit.
stack.push(operand);
n = 0;
operand = 0;
}
if (ch == '(') {
int res = evaluateExpr(stack);
stack.pop();
// Append the evaluated result to the stack.
// This result could be of a sub-expression within the parenthesis.
stack.push(res);
} else {
// For other non-digits just push onto the stack.
stack.push(ch);
}
}
}
//Push the last operand to stack, if any.
if (n != 0) {
stack.push(operand);
}
// Evaluate any left overs in the stack.
return evaluateExpr(stack);
}
}
方法二:栈和不反转字符串
解决 - 结合律的问题的一个分厂简单的方法就是使将 - 运算符看作右侧操作数的大小。一旦我们将 - 看作操作数的大小,则表达式将只剩下一个操作符。就是 + 运算符,而 + 是遵循结合律的。
例如,A-B-CA−B−C 等于 A + (-B) + (-C)A+(−B)+(−C)。
重写以后的表达式将遵循结合律,所以我们从左或从右计算表达式都是正确的。
我们需要注意的是给定的表达式会很复杂,即会有嵌套在其他表达式的表达式。即 (A - (B - C)),我们需要 B-C 外面的 - 号与 B-C 关联起来,而不是仅仅与 B 关联起来。
我们可以通过遵循前面的基本练习并将符号与其右侧的表达式关联来解决此问题。然而,我们将采用的方法有一个小的转折,因为我们将在运行中评估大多数表达式。这减少了推送和弹出操作的数量。
算法:
- 正序迭代字符串。
- 操作数可以由多个字符组成,字符串 “123” 表示数字 123,它可以被构造为:123 >> 120 + 3 >> 100 + 20 + 3。如果我们读取的字符是一个数字,则我们要将先前形成的操作数乘以 10 并于读取的数字相加,形成操作数。
- 每当我们遇到 + 或 - 运算符时,我们首先将表达式求值到左边,然后将正负符号保存到下一次求值。
- 如果字符是左括号 (,我们将迄今为止计算的结果和符号添加到栈上,然后重新开始进行计算,就像计算一个新的表达式一样。
如果字符是右括号 ),则首先计算左侧的表达式。则产生的结果就是刚刚结束的子表达式的结果。如果栈顶部有符号,则将此结果与符号相乘。 ```python class Solution: def calculate(self, s: str) -> int:
sta = [] operand = 0 res = 0 sign = 1 for ch in s: if ch.isdigit(): # 如果是数字就连续处理 operand = (operand * 10) + int(ch) if ch == '+': # 计算 + 号左边的值 res += sign * operand # 保存最近遇到的加号 sign = 1 # 重置操作数 operand = 0 if ch == '-': res += sign * operand sign = -1 operand = 0 if ch == '(': # 先将 res 入栈,再将 符号 入栈,方便后面计算 sta.append(res) sta.append(sign) # 重置res 和 sign 就像开始新的表达式, 此时operand已经为0 无需重置 res = 0 sign = 1 if ch == ')': res += sign * operand # 这个时候先看看栈顶的符号,eg. -(2 + 5) or + (3 - 2) res *= sta.pop() res += sta.pop() operand = 0 return res + sign * operand
```java
class Solution {
public int calculate(String s) {
Stack<Integer> stack = new Stack<Integer>();
int operand = 0;
int result = 0; // For the on-going result
int sign = 1; // 1 means positive, -1 means negative
for (int i = 0; i < s.length(); i++) {
char ch = s.charAt(i);
if (Character.isDigit(ch)) {
// Forming operand, since it could be more than one digit
operand = 10 * operand + (int) (ch - '0');
} else if (ch == '+') {
// Evaluate the expression to the left,
// with result, sign, operand
result += sign * operand;
// Save the recently encountered '+' sign
sign = 1;
// Reset operand
operand = 0;
} else if (ch == '-') {
result += sign * operand;
sign = -1;
operand = 0;
} else if (ch == '(') {
// Push the result and sign on to the stack, for later
// We push the result first, then sign
stack.push(result);
stack.push(sign);
// Reset operand and result, as if new evaluation begins for the new sub-expression
sign = 1;
result = 0;
} else if (ch == ')') {
// Evaluate the expression to the left
// with result, sign and operand
result += sign * operand;
// ')' marks end of expression within a set of parenthesis
// Its result is multiplied with sign on top of stack
// as stack.pop() is the sign before the parenthesis
result *= stack.pop();
// Then add to the next operand on the top.
// as stack.pop() is the result calculated before this parenthesis
// (operand on stack) + (sign on stack * (result from parenthesis))
result += stack.pop();
// Reset the operand
operand = 0;
}
}
return result + (sign * operand);
}
}

若有收获,就点个赞吧
0 人点赞
