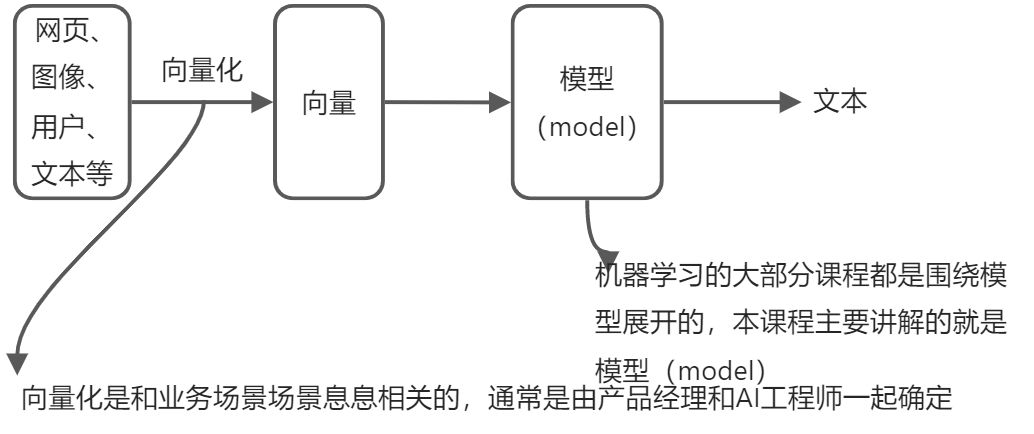
第1章 线性回归(模型1)
1.1 前置知识
1.1.1 为什么需要线性回归
1.1.2 什么是线性回归
1.1.3 什么是线性回归方程
1.2 线性回归模型
1.2.1 需求
假设有这样一个需求: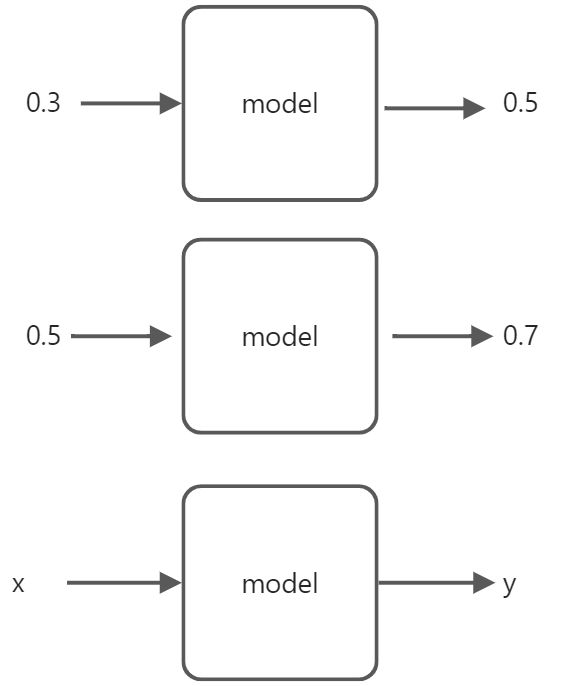
假如输入为 x 通过模型(model)后得到了y。有时候我们可能得到了这样一组数据,如下图:
左边是 x ,右边是 y,通过什么样的公式根据 x 然后得到 y。
1.2.2 模型 y = wx + b
要解决上面的需求,得到一个这样的公式(y = wx + b)。这个公式在坐标系里面就是一条直线。w:表示倾斜度,b:表示直线在 y 轴上位置。
1.2.3 线性回归
由于表示的是一条直线,所以我们称为线性回归(回归:拟合,模拟的意思)。也就是说根据已知数 x 和 y 把 w 和 b 给算出来,就叫做回归。
假如在坐标系中有很多点,如下图:
我们要找到一条直线,该直线要尽可能多的通过坐标系中的点。直线通过的点数越多拟合程度就越高。
1.2.4 多点可能产生误差
只有通过不断调整w和b来实现。那具体如何调整呢?
首先,假设坐标系中只有一个点(2,3)那么将会有无数多条直线通过该点,也就是说w和b有无数多个。
若坐标系中有两个点如(2,3)和(3,6),那么w和b就只有一个。
若坐标系中有三个点如(2,3)、(3,6)和(1,7),点(1,7)不在直线上,所以产生了误差,离线越远误差越大。
1.2.5 MSE
用MSE公式来表示误差,如下图:
MSE每个字母代表的意思如下图:
1.2.6 使MSE最小
要减小误差,只能通过不断的改变w和b,如下图:
当mse最小时,误差自然就最小了。我们可以将公式写成下图这样:

1.2.7 导数



1.2.8 随机初始化w(初始值是机器自动给出的)



1.2.9 梯度下降法


1.3 多元线性回归
在此之前 y = wx + b,只有一个x,现实生活中可能 x 不止一个,比如我们要预测房价,就需要多个x,x1,x2,x3,x4,……。分别代表当地收入,人口密度,人口结构,受教育程度等,y 是我们需要的房价。这就需要多元的线性回归,也就是 x 是多个,y 只有一个。
1.3.1 w对y的影响

1.3.2 将非线性回归模型转化为线性回归模型


1.3.3 多元线性回归与特勒公式

1.4 线性回归的优点
1.4.1 优点1:抗噪声
1.4.2 优点2:抗冗余
1.5 总结
1.6 面试题
测试集的误差一定大于训练集吗?
不一定,因为测试集是随机选的,有可能刚好选到训练集上面的数据。
但是,在真实环境中,测试集的mse一般大于训练集的mse。
测试集的mse和训练集的mes谁大谁小?
2中所指的图,如下:
解决办法:有两个
1、增大训练集,这样测试集就有很大机会选中训练集的数据。
2、增加训练集数据的多样性。尽量从已经取得的数据中选取数据,不是从集中的一小部分取数据。
第2章 逻辑回归
2.1 线性回归与逻辑回归的区别
区别1:线性回归是得到一个y,逻辑回归是得到一个类别。
区别2:线性回归:知道坐标的一部分,通过预测另一个。
逻辑回归:知道完整的坐标,计算和直线的相对位置。
2.2 分类
2.2.1 多分类(两种以上的分类)
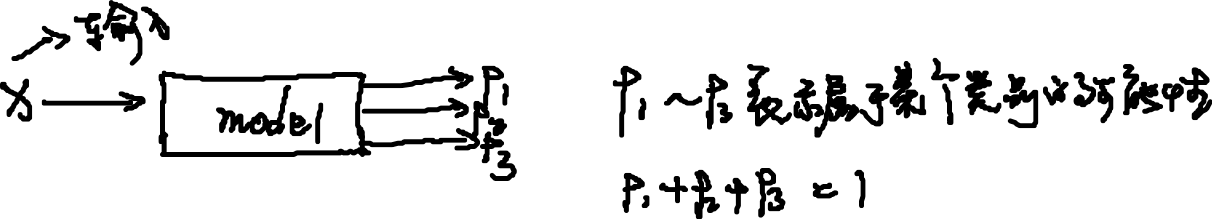
2.2.2 二分类
为了简化问题,我们先从二分类讲起,首先需要明白的是:没有一分类,假如输入x—->model—->p,若 x 是一张猫的图片,那么得到的 p 要么是猫 ,要么不是猫,是猫用1表示,那么就隐含了一个分类不是猫用(1-p)表示。
2.3 实现二分类的模型


2.3.1 f 值域(0,1)

2.3.2 d 与 f 的关系

2.3.3 求导
2.3.4 倒数曲线

2.4 逻辑回归中机器学习到底学什么

2.5 KL距离(两个概率之间的距离)
2.5.1 什么是KL距离
2.5.2 两个例子

2.5.3 KL距离公式

2.5.4 KL距离的性质

2.5.5 计算预测概率与真实概率之间的距离



2.6 机器学习的流程
第一步:先随机出一个w,计算模型输出;
第二步:计算模型输出与真实数值的差,得到损失函数(mse,kl距离);
第三步:不停地调整w让损失函数变小。
2.5.6.1 对LK距离公式进行求导 
2.5.6.2 梯度下降法

2.7 逻辑回归只能做二分类吗
逻辑回归可以做n分类,但是通常不这么干,原因如下:
工程上如何解决:
2.8 线性不可分

2.9 上采样与下采样
2.10 分类模型的评价方式(3种方式)
标注的信息(也称为正确答案)有两种情况:
1、P(y = 1);
2、N(y = 0);
模型预测出来的也有两种情况:
1、P’(y>0.5)
2、N’(y<0.5)
将标注信息与预测信息综合起来,就有四种情况,如下图:
以上四种情况中,只有两种情况(TP和TN)的预测结果与真实结果是一致的。
2.10.1 方式1:正确率(acc)

2.10.1.1 正确率(acc)的缺点

2.10.2 方式2:准确率和召回率
为了解决正确率中由于样本数量极度不均衡,正确率被大样本一方拔高的情况,引入了准确率和召回率。
准确率和召回率不是一个整体指标,他们是针对某一类(P类或N类)的预测情况进行评价的。
准确率越高,说明模型的误判少,比如推荐系统,每日给用户的推荐要尽可能的精确。
召回率越高,说明模型的漏判少,比如过滤政治反动言论、黄色暴力等文章的模型,就重视召回率,宁可误判也不要漏判。
准确率和召回率是相互矛盾的。

2.10.2.1 准确率和召回率的缺点
准确率和召回率跟阈值有关,阈值的变化会影响预测结果,进而引起指标的变化,而阈值的选择依赖于产品形态。所以准确率和召回率不是完全客观的。
2.10.3 方式3:AUC(ROC曲线下面的面积)
2.10.3.1 ROC曲线
基本的符号表示: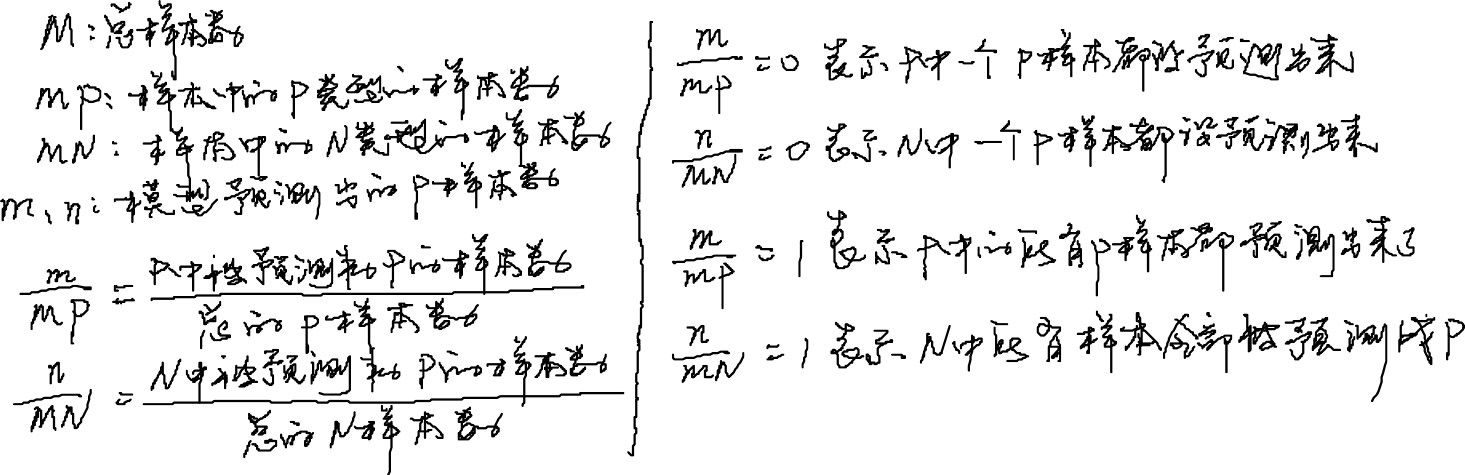
什么是ROC曲线:
ROC曲线就是一条以n/MN(范围[0~1])为横轴,m/MP(范围[0~1])为纵轴,形成的坐标用(a,b)表示,每个阈值(θ)都对应了一个唯一的坐标,遍历所有阈值(θ)所形成的一条曲线。

2.10.3.2 案例

2.10.3.3 AUC的取值范围
?面试题(3级)
面试题1、KL距离问题(二)~KL距离问题(五)
面试题2、逻辑回归中为什么不用MES,68、69
第6章 无监督学习
6.1 为什么需要无监督学习

6.2 什么是无监督学习

6.4 K-Means算法(根据质点不断将点进行分类的算法)的基本原理
6.4.1 K-Means算法的步骤

6.4.1.1 什么时候循环结束

6.4.1.2 μ 如何计算(样本到某个质点的距离)
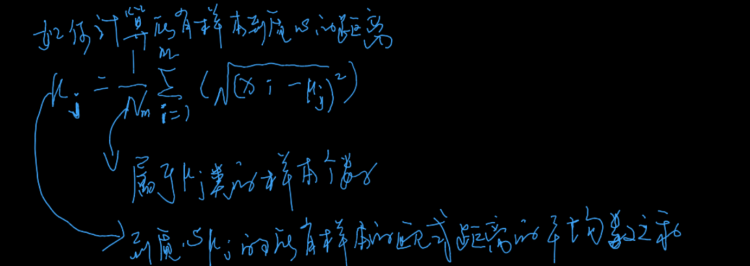
6.4.1.3 loss 公式

6.4.1.4 关于质点

6.4.3 质心是如何受样本影响的

6.5 聚类存在什么问题
6.5.1 问题1:对初始点敏感
随机初始化的时候往往会极大的影响分类,如下图:
怎么办呢?
最好的办法就是,多随机几次,每次都求出一个loss,最终选loss最小的那个即可。但是,会带来新的问题:当样本量很大的时候就非常耗时耗资源。
6.5.2 问题2:被异常点影响
如果一个样本远离了其他所有样本,那么他就是异常点。有两种办法可以避免:
方法1、分类前先将其去除;
方法2、每次聚类的时候将距离质心很远的那个点去掉。
6.5.3 问题3:某些场合缺乏物理意义
比如男表示为0,女表示为1,那么聚类以后得到的可能是一个小数,这就缺乏了物理意义。这个问题没法解决。
6.5.4 问题4:数值问题

6.6 如何寻找合适的K

6.7 K-means算法无法解决的问题

6.8 聚类效果的评价
6.8.1 评价的工具
6.8.2 评价的角度
6.8.2.1 角度1:从同一个类的角度评价
计算同一个类的两种不同信息熵:
1、同一个真实类别中,所包含的预测类别的情况;
这种情况K设置过大
2、同一个预测类别中,所包含的真实类别的情况。
这种情况K设置过小
6.8.2.2 角度2:从不同类角度进行评价
第7章 深度神经网络
7.1 深度学习与传统机器学习的关系
人工智能 = 传统机器学习 + 深度学习
深度学习其实是由传统机器学习的BP模型发展而来的,也就是说深度学习其实是机器学习的延伸。
7.2 为什么需要深度学习
深度学习其实是从逻辑回归中来的,机器学习中最大的难点是特征。一个好的特征有以下几个特点:
1、区分度高;
2、特征的数量多;
3、能进行各类特征的组合。
特征的组合是重点,也是难点。在FM模型中,能自动组合二阶特征。但有时候我们需要组合更高阶的特征,比如,3阶、4阶乃至更高阶。很多时候具体需要多少阶我们自己都不胜了解。
能否搞一个类似于FM模型,能自动组合特征的框架,具体组合方式以及阶次由模型自动学习。像这样的模型就是深度学习。
7.3 什么是深度学习
7.4 深度学习的基本原理

7.4.1 常见写法

7.4.2 从 n 维向量到 m 维向量的变换
7.4.2.1 没有意义的变换

7.4.2.2 有意义的变换

若有收获,就点个赞吧
0 人点赞
