参考
kafka参考:Apache Kafka SQL 连接器
kafka表配置: Kafka | Apache Flink
Upsert Kafka SQL 连接器配置:upsert-kafka
kafka-clients驱动下载: kafka-clients
安装Docker
请参考安装docker
安装Flink
安装Kafka
系统环境
- win 10
- docker Desktop
- sql server 2019
- kafka 2.8.1
-
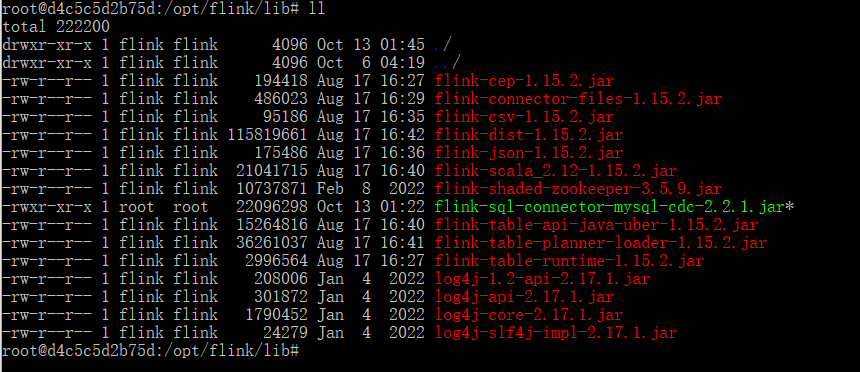
Flink CDC的lib依赖
下载下面列出的依赖包,下载地址
- flink-connector-kafka-1.15.2.jar
- kafka-clients-2.8.1.jar (不能少这个,一定要下载,且版本与安装的kafka 版本对应上)
- flink-connector-jdbc
需要自己选择对应的版本下载,如flink的版本为1.15.2,就下载flink-connector-jdbc-1.15.2.jar,将下载的数据库连接驱动包的jar放到 flink的lib目录下:
任务管理器容器
docker cp D:/data/flink/lib/flink-sql-connector-sqlserver-cdc-2.2.1.jar flink-docker-taskmanager-1:/opt/flink/lib/flink-sql-connector-sqlserver-cdc-2.2.1.jar
docker cp D:/data/flink/lib/flink-connector-kafka-1.15.2.jar flink-docker-taskmanager-1:/opt/flink/lib/flink-connector-kafka-1.15.2.jar
docker cp D:/data/flink/lib/kafka-clients-2.8.1.jar flink-docker-taskmanager-1:/opt/flink/lib/kafka-clients-2.8.1.jar
docker cp D:/data/flink/lib/flink-connector-jdbc-1.15.2.jar flink-docker-taskmanager-1:/opt/flink/lib/flink-connector-jdbc-1.15.2.jar
作业管理器容器
docker cp D:/data/flink/lib/flink-sql-connector-sqlserver-cdc-2.2.1.jar flink-docker-jobmanager-1:/opt/flink/lib/flink-sql-connector-sqlserver-cdc-2.2.1.jar
docker cp D:/data/flink/lib/flink-connector-kafka-1.15.2.jar flink-docker-jobmanager-1:/opt/flink/lib/flink-connector-kafka-1.15.2.jar
docker cp D:/data/flink/lib/kafka-clients-2.8.1.jar flink-docker-jobmanager-1:/opt/flink/lib/kafka-clients-2.8.1.jar
docker cp D:/data/flink/lib/flink-connector-jdbc-1.15.2.jar flink-docker-jobmanager-1:/opt/flink/lib/flink-connector-jdbc-1.15.2.jar
到任务管理器容器查看是否拷贝成功
cd D:\data\flink\flink-docker
docker-compose exec taskmanager /bin/bash
cd ./lib/ll
Sql Server同步Kafka示例
Sql Server源数据sql准备
创建数据库es_test,并创建V_Blood_BOutItem表
CREATE TABLE [dbo].[V_Blood_BOutItem]([id] [int] NOT NULL,[deptno] [int] NOT NULL,[deptname] [varchar](65) NULL,[bloodno] [varchar](20) NULL,[bloodname] [varchar](65) NULL,[boutcount] [float] NULL,[bloodunitname] [varchar](65) NULL,[bodate] [datetime] NULL,CONSTRAINT [PK_V_Blood_BOutItem] PRIMARY KEY CLUSTERED([id] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]) ON [PRIMARY]GO
开启数据库CDC
SELECT is_cdc_enabled,CASE WHEN is_cdc_enabled=0 THEN 'CDC功能禁用' ELSE 'CDC功能启用' END 描述 FROM sys.databases WHERE name='es_test'
exec sys.sp_cdc_enable_db
EXEC sys.sp_cdc_disable_db
开启表CDC
SELECT name, physical_name FROM sys.master_files WHERE database_id = DB_ID('es_test');
-- 为该库添加名为CDC1的文件组ALTER DATABASE es_test ADD FILEGROUP CDC1;ALTER DATABASE es_testADD FILE(NAME= 'cdctest1_cdc',FILENAME = 'D:\DATA2019\cdctest1_cdc.ndf')TO FILEGROUP CDC1;
--操作开启表CDCIF EXISTS(SELECT 1 FROM sys.tables WHERE name='V_Blood_BOutItem' AND is_tracked_by_cdc = 0)BEGINEXEC sys.sp_cdc_enable_table@source_schema = 'dbo', -- source_schema@source_name = 'V_Blood_BOutItem', -- table_name@capture_instance = 'test_instance', -- capture_instance@supports_net_changes = 1, -- supports_net_changes@role_name = NULL, -- role_name@index_name = NULL, -- index_name@captured_column_list = NULL, -- captured_column_list@filegroup_name = 'CDC1' -- filegroup_nameEND; -- 开启表级别CDC
select name, is_tracked_by_cdc from sys.tables where object_id = OBJECT_ID('V_Blood_BOutItem')
Kafka准备
启动 Flink 集群
cd D:\data\flink\flink-docker
进入到作业管理器容器
docker-compose exec jobmanager /bin/bash
./bin/start-cluster.sh
Flink SQL CLI创建job
需要先开启Flink 集群,首先,开启 checkpoint,每隔3秒做一次 checkpoint
cd D:\data\flink\flink-docker
进入到作业管理器容器
docker-compose exec jobmanager /bin/bash
使用下面的命令启动 Flink SQL CLI
./bin/sql-client.sh
开启 checkpoint,每隔3秒做一次 checkpoint
SET execution.checkpointing.interval = 3s;
使用 Flink DDL 创建表
CREATE TABLE sourceboutitem (id INT NOT NULL,deptno INT NULL,deptname STRING,bloodno INT NULL,bloodname STRING,boutcount FLOAT,bloodunitname STRING,bodate STRING,primary key (id) not enforced) WITH ('connector' = 'sqlserver-cdc','hostname' = '192.168.3.40','port' = '1433','username' = 'sa','password' = 'longfuchu','database-name' = 'es_test','schema-name' = 'dbo','table-name' = 'V_Blood_BOutItem');
select * from sourceboutitem;
以上是将192.168.3.40服务器上的sql server数据库的es_test的表V_Blood_BOutItem同步到sourceboutitem上;
CREATE TABLE sinkboutitem (id INT,deptno INT,deptname STRING,bloodno STRING,bloodname STRING,boutcount FLOAT,bloodunitname STRING,PRIMARY KEY (id) NOT ENFORCED) WITH ('connector' = 'kafka','topic' = 'sinkboutitem','properties.bootstrap.servers' = 'kafka1:9091,kafka2:9092,kafka3:9093','properties.group.id' = 'sinkboutitem','scan.startup.mode' = 'earliest-offset','key.format' = 'json','key.json.ignore-parse-errors' = 'true','key.fields' = 'id','value.format' = 'debezium-json');
:::warning scan.startup.mode 配置项决定了 Kafka consumer 的启动模式。有效值为:
group-offsets:从 Zookeeper/Kafka 中某个指定的消费组已提交的偏移量开始。earliest-offset:从可能的最早偏移量开始。latest-offset:从最末尾偏移量开始。timestamp:从用户为每个 partition 指定的时间戳开始。specific-offsets:从用户为每个 partition 指定的偏移量开始。 ::: 检查验证
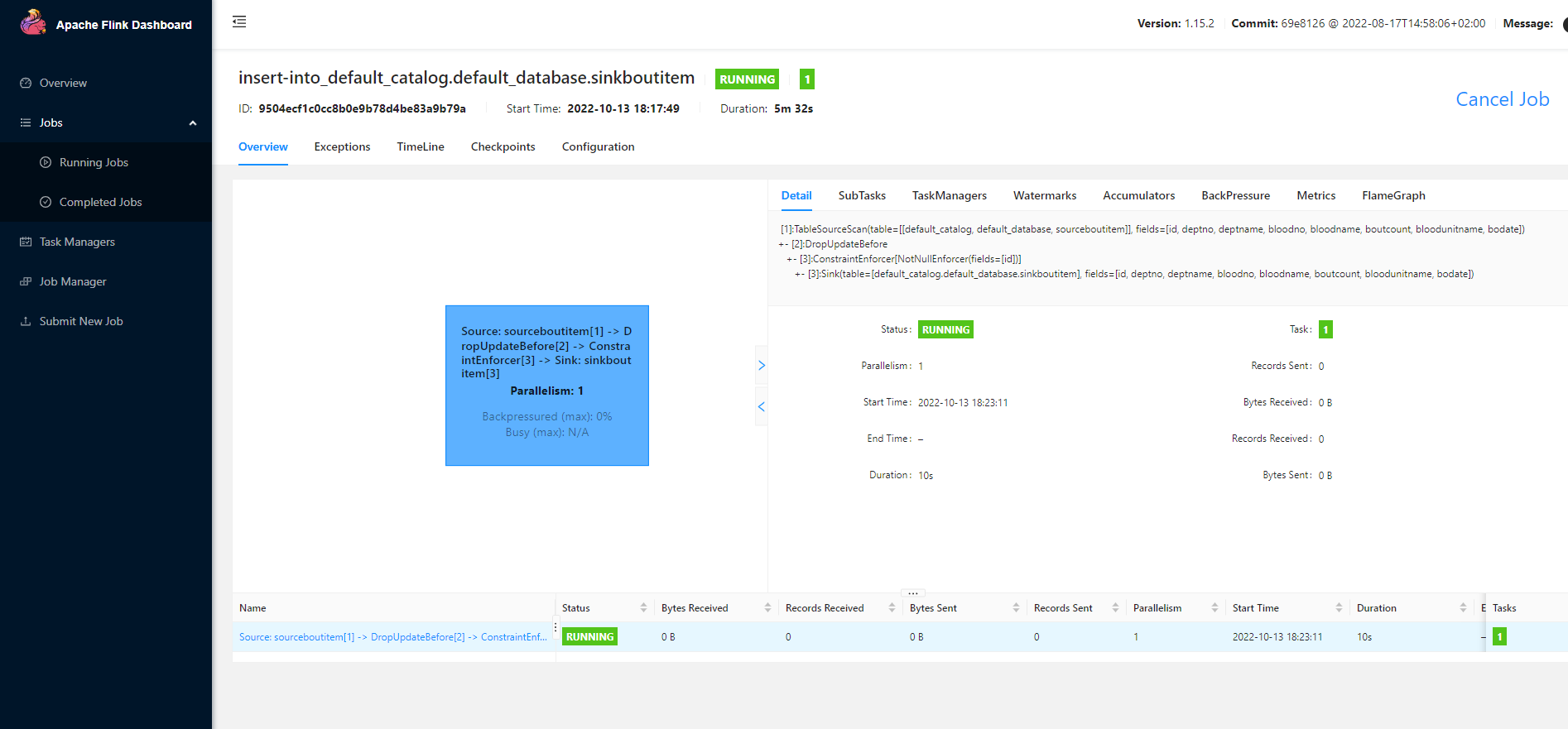
以上是将Kafka与flink cdc的sinkflinktest表映射;开始同步select * from sinkboutitem;
注意:以上操作,如果同步出现异常信息,请检查sql server连接配置及端口号是否被防火墙拦截,或者与Flink数据类型映射是否正确!打开http://localhost:8081/查看,因为是测试,我只是执行任务一小段时间后就结束任务了,同步到EDS数据库的记录数为insert into sinkboutitem select * from sourceboutitem;

若有收获,就点个赞吧
0 人点赞
