MapReduce工作原理
大数据的并行化计算
一个大数据若可以分为具有同样计算过程的数据块,并且这些数据块之间不存在数据依赖关系,则提高处理速度的最好办法就是并行计算
并行计算案例
例如:假设有一个巨大的2维数据需要处理(比如求每个元素的开立方),其中对每个元素的处理是相同的,并且数据元素间不存在数据依赖关系,可以考虑不同的划分方法将其划分为子数组,由一组处理器并行处理
并行计算案例一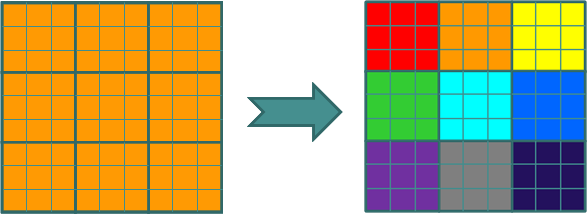
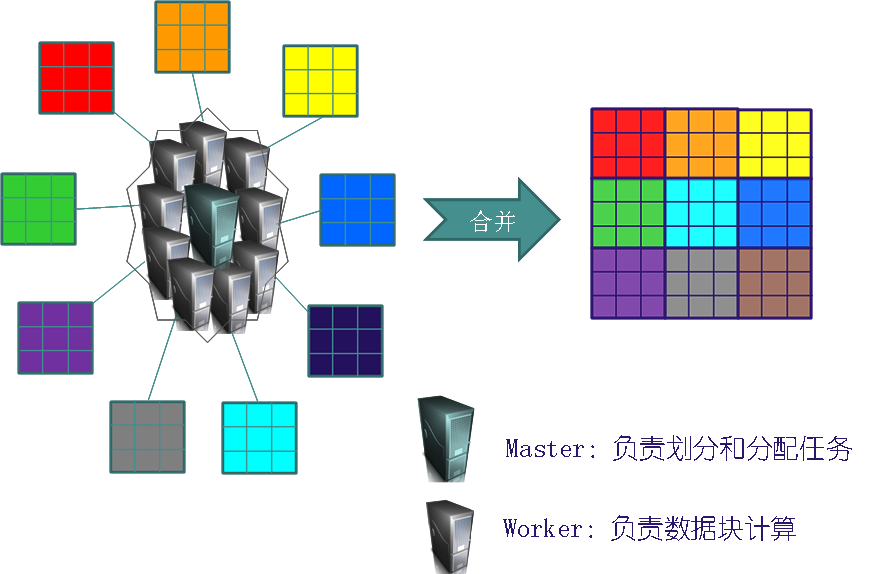
并行计算案例二
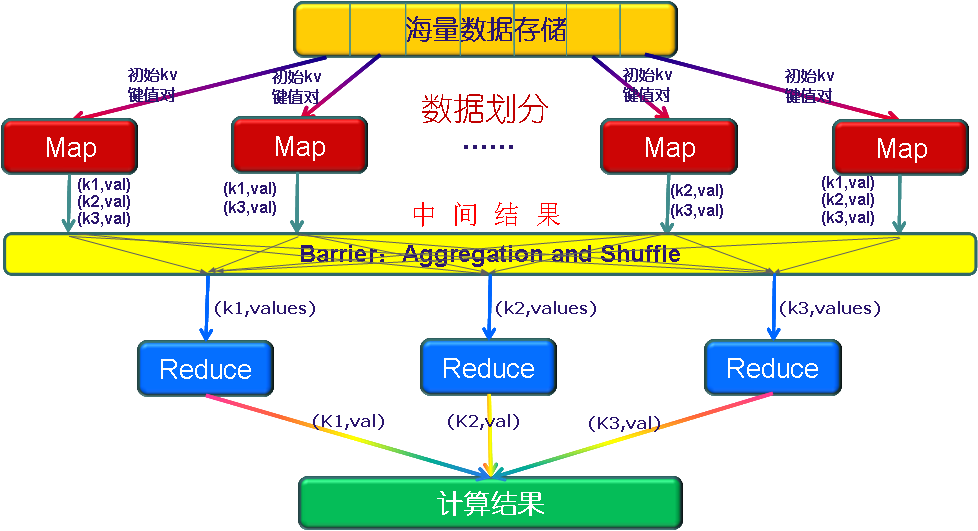
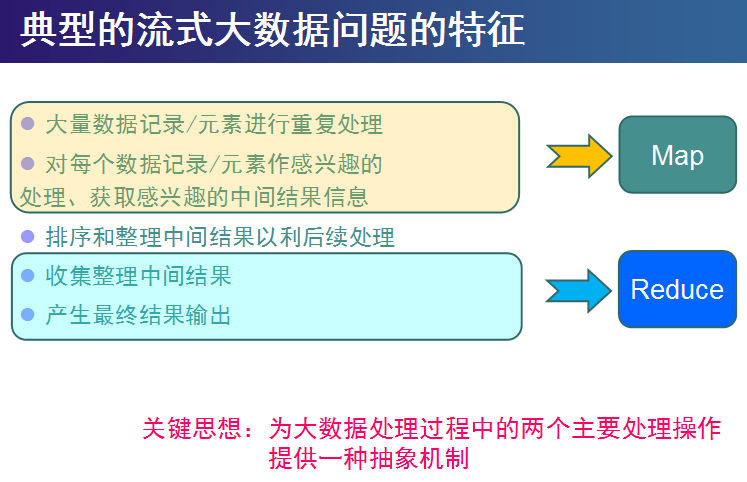
MapReduce编程规范
MapReduce的开发有八个阶段,其中Map阶段分为2个步骤,Shuffle阶段4个步骤,Reduce阶段分为2个步骤
Map的2个阶段
- 设置inputFormat类,将数据切分为k1和v1,输入到第二步
自定义map逻辑,将第一步的结果转换为另外的k2和v2,对结果进行输出
Shuffle(洗牌)的4个阶段
对输出的k2和v2进行分区
- 对不同分区的数据按照相同的key排序
- (可选)对分组过的数据初步规约,降低数据的网络拷贝
-
Reduce的2个阶段
对多个map任务结果进行排序以及合并,编写reduce函数实现自己的逻辑,对输入的key-value进行处理,转为新的key-value(k3和v3)
- 设置outputFaormat处理并保存reduce输出的key-value数据
案例
比如存在一个a.text,里面记录了一些各个单词,通过TextInputFormat组件读每一行数据(无需我们操作,组件自动完成) ,形成一个kv键值对数据,k为每个数据的偏移量,v为我们要记录的每行数据。(完成了第一步骤)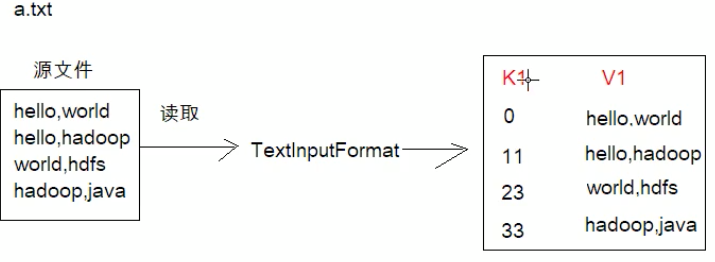
上述已经拿到k1和v1,现在要自定义有个Mapper类重写map方法,在map方法中将k1和v1转为k2和v2,至于转成什么样的,需要根据我们的业务逻辑。我们假设要统计源文件各个单词出现的次数。将v1读取到的数字按照“逗号”分割,将读取到的每个值变成k2 v2的形式,k2的值即为单词,v2可以理解为固定的值1。(完成了第二步骤)。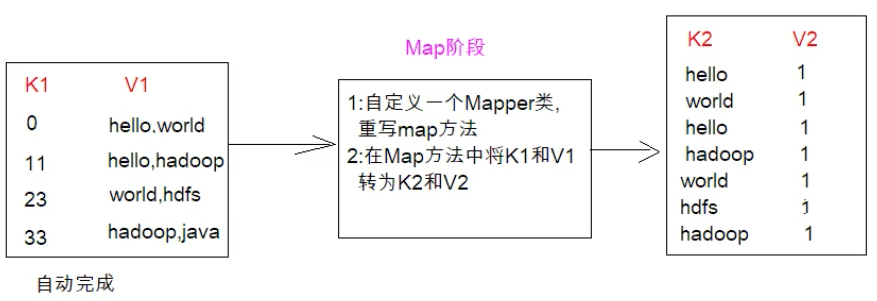
现在到了我们的shuffle阶段,它会陆续的进行分区、排序、规约、分组(java8 stream语法很多类似名词)。最终它会形成新的k2 v2,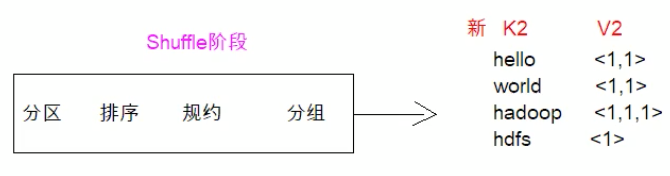
到了reduce阶段,肯定是要形成一个k3和v3,格式肯定是单词作为键值,出现次数肯定是出现的次数了,然后通过OutPutFormat的子类TextOutPutFormat,它会将我们的结果保存成文件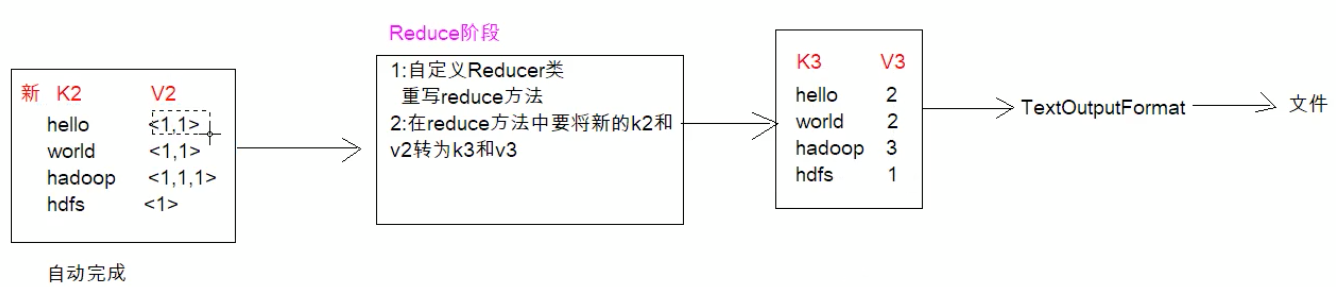

若有收获,就点个赞吧
0 人点赞
