安装完成,如果环境是Python3,则需要修改datax/bin下面的三个python文件。![]()
GitHub
https://github.com/alibaba/DataX
https://github.com/alibaba/DataX/blob/master/introduction.md
https://github.com/alibaba/DataX/blob/master/userGuid.md
系统要求
- Linux
- JDK(1.8以上,推荐1.8)
- Python(2或3都可以)
- Apache Maven 3.x (Compile DataX)
相关安装
python安装
windows10安装python详细过程
python 3.X版本在win10安装成功后,还是直接使用python,不需要python3JDK安装
请参考Jdk 8 安装与配置
https://www.oracle.com/java/technologies/downloads/archive/
版本说明
Linux x86 RPM Package //适用于32bit的centos、rethat(linux)操作系统
Linux x64 RPM Package //适用于64bit的centos、rethat(linux)操作系统
Linux x86 Compressed Archive //适用于32bit的Linux操作系统
Linux x64 Compressed Archive //适用于64bit的Linux操作系统DataX安装
直接下载DataX工具包:DataX下载地址将下载的压缩包解压即可。,
可参考 userGuid.md下载解压
直接下载DataX工具包:DataX下载地址,将下载的压缩包解压即可。,
我解压的存放目录在D:\DataX\DataX,
隐藏文件
需要删除隐藏文件 (重要),以._开头的文件都删除.测试安装
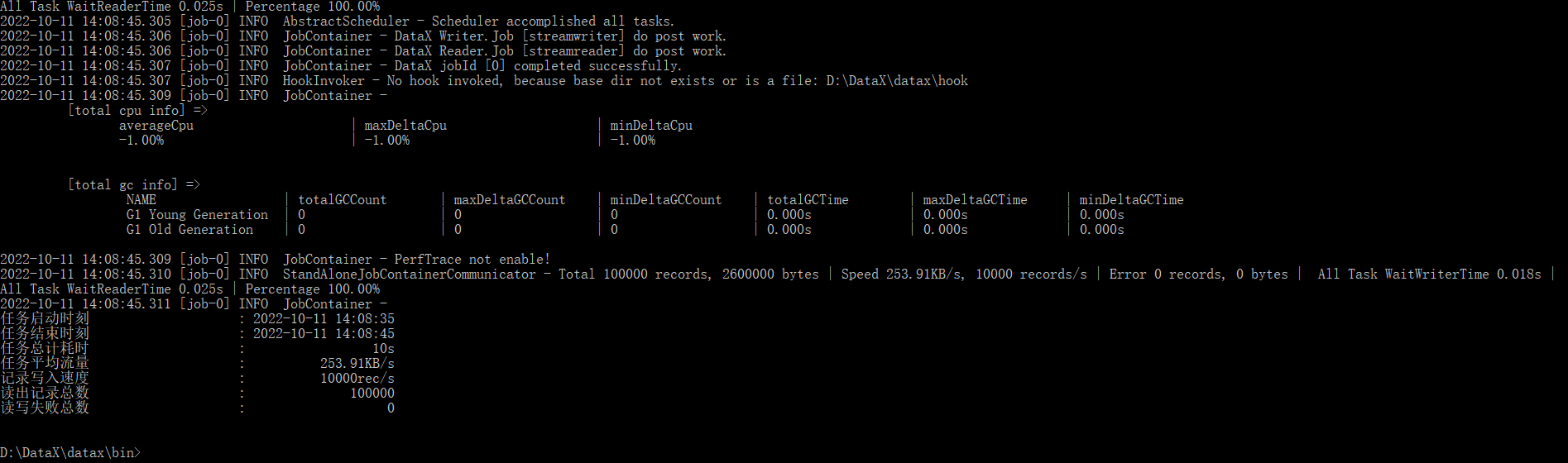
cd D:/DataX/datax/bin
python D:/DataX/datax/bin/datax.py D:/DataX/datax/job/job.json
修改python文件
安装完成,如果环境是Python3,则需要修改datax/bin下面的三个python文件。
修改的文件 ```python!/usr/bin/env python
-- coding:utf-8 --
import sys import os import signal import subprocess import time import re import socket import json from optparse import OptionParser from optparse import OptionGroup from string import Template import codecs import platform
def isWindows(): return platform.system() == ‘Windows’
DATAXHOME = os.path.dirname(os.path.dirname(os.path.abspath(_file)))
DATAX_VERSION = ‘DATAX-OPENSOURCE-3.0’ if isWindows(): codecs.register(lambda name: name == ‘cp65001’ and codecs.lookup(‘utf-8’) or None) CLASS_PATH = (“%s/lib/“) % (DATAX_HOME) else: CLASS_PATH = (“%s/lib/:.”) % (DATAX_HOME) LOGBACK_FILE = (“%s/conf/logback.xml”) % (DATAX_HOME) DEFAULT_JVM = “-Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=%s/log” % (DATAX_HOME) DEFAULT_PROPERTY_CONF = “-Dfile.encoding=UTF-8 -Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener -Djava.security.egd=file:///dev/urandom -Ddatax.home=%s -Dlogback.configurationFile=%s” % ( DATAX_HOME, LOGBACK_FILE) ENGINE_COMMAND = “java -server ${jvm} %s -classpath %s ${params} com.alibaba.datax.core.Engine -mode ${mode} -jobid ${jobid} -job ${job}” % ( DEFAULT_PROPERTY_CONF, CLASS_PATH) REMOTE_DEBUG_CONFIG = “-Xdebug -Xrunjdwp:transport=dt_socket,server=y,address=9999”
RET_STATE = { “KILL”: 143, “FAIL”: -1, “OK”: 0, “RUN”: 1, “RETRY”: 2 }
def getLocalIp(): try: return socket.gethostbyname(socket.getfqdn(socket.gethostname())) except: return “Unknown”
def suicide(signum, e): global child_process print >> sys.stderr, “[Error] DataX receive unexpected signal %d, starts to suicide.” % (signum)
if child_process:child_process.send_signal(signal.SIGQUIT)time.sleep(1)child_process.kill()print >> sys.stderr, "DataX Process was killed ! you did ?"sys.exit(RET_STATE["KILL"])
def register_signal(): if not isWindows(): global child_process signal.signal(2, suicide) signal.signal(3, suicide) signal.signal(15, suicide)
def getOptionParser(): usage = “usage: %prog [options] job-url-or-path” parser = OptionParser(usage=usage)
prodEnvOptionGroup = OptionGroup(parser, "Product Env Options","Normal user use these options to set jvm parameters, job runtime mode etc. ""Make sure these options can be used in Product Env.")prodEnvOptionGroup.add_option("-j", "--jvm", metavar="<jvm parameters>", dest="jvmParameters", action="store",default=DEFAULT_JVM, help="Set jvm parameters if necessary.")prodEnvOptionGroup.add_option("--jobid", metavar="<job unique id>", dest="jobid", action="store", default="-1",help="Set job unique id when running by Distribute/Local Mode.")prodEnvOptionGroup.add_option("-m", "--mode", metavar="<job runtime mode>",action="store", default="standalone",help="Set job runtime mode such as: standalone, local, distribute. ""Default mode is standalone.")prodEnvOptionGroup.add_option("-p", "--params", metavar="<parameter used in job config>",action="store", dest="params",help='Set job parameter, eg: the source tableName you want to set it by command, ''then you can use like this: -p"-DtableName=your-table-name", ''if you have mutiple parameters: -p"-DtableName=your-table-name -DcolumnName=your-column-name".''Note: you should config in you job tableName with ${tableName}.')prodEnvOptionGroup.add_option("-r", "--reader", metavar="<parameter used in view job config[reader] template>",action="store", dest="reader",type="string",help='View job config[reader] template, eg: mysqlreader,streamreader')prodEnvOptionGroup.add_option("-w", "--writer", metavar="<parameter used in view job config[writer] template>",action="store", dest="writer",type="string",help='View job config[writer] template, eg: mysqlwriter,streamwriter')parser.add_option_group(prodEnvOptionGroup)devEnvOptionGroup = OptionGroup(parser, "Develop/Debug Options","Developer use these options to trace more details of DataX.")devEnvOptionGroup.add_option("-d", "--debug", dest="remoteDebug", action="store_true",help="Set to remote debug mode.")devEnvOptionGroup.add_option("--loglevel", metavar="<log level>", dest="loglevel", action="store",default="info", help="Set log level such as: debug, info, all etc.")parser.add_option_group(devEnvOptionGroup)return parser
def generateJobConfigTemplate(reader, writer): readerRef = “Please refer to the %s document:\n https://github.com/alibaba/DataX/blob/master/%s/doc/%s.md \n” % (reader,reader,reader) writerRef = “Please refer to the %s document:\n https://github.com/alibaba/DataX/blob/master/%s/doc/%s.md \n “ % (writer,writer,writer) print (readerRef) print (writerRef) jobGuid = ‘Please save the following configuration as a json file and use\n python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json \nto run the job.\n’ print (jobGuid) jobTemplate={ “job”: { “setting”: { “speed”: { “channel”: “” } }, “content”: [ { “reader”: {}, “writer”: {} } ] } } readerTemplatePath = “%s/plugin/reader/%s/plugin_job_template.json” % (DATAX_HOME,reader) writerTemplatePath = “%s/plugin/writer/%s/plugin_job_template.json” % (DATAX_HOME,writer) try: readerPar = readPluginTemplate(readerTemplatePath); except Exception as e: print (“Read reader[%s] template error: can\’t find file %s” % (reader,readerTemplatePath)) try: writerPar = readPluginTemplate(writerTemplatePath); except Exception as e: print (“Read writer[%s] template error: : can\’t find file %s” % (writer,writerTemplatePath)) jobTemplate[‘job’][‘content’][0][‘reader’] = readerPar; jobTemplate[‘job’][‘content’][0][‘writer’] = writerPar; print (json.dumps(jobTemplate, indent=4, sort_keys=True))
def readPluginTemplate(plugin): with open(plugin, ‘r’) as f: return json.load(f)
def isUrl(path): if not path: return False
assert (isinstance(path, str))m = re.match(r"^http[s]?://\S+\w*", path.lower())if m:return Trueelse:return False
def buildStartCommand(options, args): commandMap = {} tempJVMCommand = DEFAULT_JVM if options.jvmParameters: tempJVMCommand = tempJVMCommand + “ “ + options.jvmParameters
if options.remoteDebug:tempJVMCommand = tempJVMCommand + " " + REMOTE_DEBUG_CONFIGprint ('local ip: ', getLocalIp())if options.loglevel:tempJVMCommand = tempJVMCommand + " " + ("-Dloglevel=%s" % (options.loglevel))if options.mode:commandMap["mode"] = options.mode# jobResource 鍙兘鏄?URL锛屼篃鍙兘鏄湰鍦版枃浠惰矾寰勶紙鐩稿,缁濆锛? jobResource = args[0]if not isUrl(jobResource):jobResource = os.path.abspath(jobResource)if jobResource.lower().startswith("file://"):jobResource = jobResource[len("file://"):]jobParams = ("-Dlog.file.name=%s") % (jobResource[-20:].replace('/', '_').replace('.', '_'))if options.params:jobParams = jobParams + " " + options.paramsif options.jobid:commandMap["jobid"] = options.jobidcommandMap["jvm"] = tempJVMCommandcommandMap["params"] = jobParamscommandMap["job"] = jobResourcereturn Template(ENGINE_COMMAND).substitute(**commandMap)
def printCopyright(): print (‘’’ DataX (%s), From Alibaba ! Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
‘’’ % DATAX_VERSION) sys.stdout.flush()
if name == “main“: printCopyright() parser = getOptionParser() options, args = parser.parse_args(sys.argv[1:]) if options.reader is not None and options.writer is not None: generateJobConfigTemplate(options.reader,options.writer) sys.exit(RET_STATE[‘OK’]) if len(args) != 1: parser.print_help() sys.exit(RET_STATE[‘FAIL’])
startCommand = buildStartCommand(options, args)# print startCommandchild_process = subprocess.Popen(startCommand, shell=True)register_signal()(stdout, stderr) = child_process.communicate()sys.exit(child_process.returncode)
```python#! /usr/bin/env python# vim: set expandtab tabstop=4 shiftwidth=4 foldmethod=marker nu:import reimport sysimport timeREG_SQL_WAKE = re.compile(r'Begin\s+to\s+read\s+record\s+by\s+Sql', re.IGNORECASE)REG_SQL_DONE = re.compile(r'Finished\s+read\s+record\s+by\s+Sql', re.IGNORECASE)REG_SQL_PATH = re.compile(r'from\s+(\w+)(\s+where|\s*$)', re.IGNORECASE)REG_SQL_JDBC = re.compile(r'jdbcUrl:\s*\[(.+?)\]', re.IGNORECASE)REG_SQL_UUID = re.compile(r'(\d+\-)+reader')REG_COMMIT_UUID = re.compile(r'(\d+\-)+writer')REG_COMMIT_WAKE = re.compile(r'begin\s+to\s+commit\s+blocks', re.IGNORECASE)REG_COMMIT_DONE = re.compile(r'commit\s+blocks\s+ok', re.IGNORECASE)# {{{ function parse_timestamp() #def parse_timestamp(line):try:ts = int(time.mktime(time.strptime(line[0:19], '%Y-%m-%d %H:%M:%S')))except:ts = 0return ts# }}} ## {{{ function parse_query_host() #def parse_query_host(line):ori = REG_SQL_JDBC.search(line)if (not ori):return ''ori = ori.group(1).split('?')[0]off = ori.find('@')if (off > -1):ori = ori[off+1:len(ori)]else:off = ori.find('//')if (off > -1):ori = ori[off+2:len(ori)]return ori.lower()# }}} ## {{{ function parse_query_table() #def parse_query_table(line):ori = REG_SQL_PATH.search(line)return (ori and ori.group(1).lower()) or ''# }}} ## {{{ function parse_reader_task() #def parse_task(fname):global LAST_SQL_UUIDglobal LAST_COMMIT_UUIDglobal DATAX_JOBDICTglobal DATAX_JOBDICT_COMMITglobal UNIXTIMELAST_SQL_UUID = ''DATAX_JOBDICT = {}LAST_COMMIT_UUID = ''DATAX_JOBDICT_COMMIT = {}UNIXTIME = int(time.time())with open(fname, 'r') as f:for line in f.readlines():line = line.strip()if (LAST_SQL_UUID and (LAST_SQL_UUID in DATAX_JOBDICT)):DATAX_JOBDICT[LAST_SQL_UUID]['host'] = parse_query_host(line)LAST_SQL_UUID = ''if line.find('CommonRdbmsReader$Task') > 0:parse_read_task(line)elif line.find('commit blocks') > 0:parse_write_task(line)else:continue# }}} ## {{{ function parse_read_task() #def parse_read_task(line):ser = REG_SQL_UUID.search(line)if not ser:returnLAST_SQL_UUID = ser.group()if REG_SQL_WAKE.search(line):DATAX_JOBDICT[LAST_SQL_UUID] = {'stat' : 'R','wake' : parse_timestamp(line),'done' : UNIXTIME,'host' : parse_query_host(line),'path' : parse_query_table(line)}elif ((LAST_SQL_UUID in DATAX_JOBDICT) and REG_SQL_DONE.search(line)):DATAX_JOBDICT[LAST_SQL_UUID]['stat'] = 'D'DATAX_JOBDICT[LAST_SQL_UUID]['done'] = parse_timestamp(line)# }}} ## {{{ function parse_write_task() #def parse_write_task(line):ser = REG_COMMIT_UUID.search(line)if not ser:returnLAST_COMMIT_UUID = ser.group()if REG_COMMIT_WAKE.search(line):DATAX_JOBDICT_COMMIT[LAST_COMMIT_UUID] = {'stat' : 'R','wake' : parse_timestamp(line),'done' : UNIXTIME,}elif ((LAST_COMMIT_UUID in DATAX_JOBDICT_COMMIT) and REG_COMMIT_DONE.search(line)):DATAX_JOBDICT_COMMIT[LAST_COMMIT_UUID]['stat'] = 'D'DATAX_JOBDICT_COMMIT[LAST_COMMIT_UUID]['done'] = parse_timestamp(line)# }}} ## {{{ function result_analyse() #def result_analyse():def compare(a, b):return b['cost'] - a['cost']tasklist = []hostsmap = {}statvars = {'sum' : 0, 'cnt' : 0, 'svr' : 0, 'max' : 0, 'min' : int(time.time())}tasklist_commit = []statvars_commit = {'sum' : 0, 'cnt' : 0}for idx in DATAX_JOBDICT:item = DATAX_JOBDICT[idx]item['uuid'] = idx;item['cost'] = item['done'] - item['wake']tasklist.append(item);if (not (item['host'] in hostsmap)):hostsmap[item['host']] = 1statvars['svr'] += 1if (item['cost'] > -1 and item['cost'] < 864000):statvars['sum'] += item['cost']statvars['cnt'] += 1statvars['max'] = max(statvars['max'], item['done'])statvars['min'] = min(statvars['min'], item['wake'])for idx in DATAX_JOBDICT_COMMIT:itemc = DATAX_JOBDICT_COMMIT[idx]itemc['uuid'] = idxitemc['cost'] = itemc['done'] - itemc['wake']tasklist_commit.append(itemc)if (itemc['cost'] > -1 and itemc['cost'] < 864000):statvars_commit['sum'] += itemc['cost']statvars_commit['cnt'] += 1ttl = (statvars['max'] - statvars['min']) or 1idx = float(statvars['cnt']) / (statvars['sum'] or ttl)tasklist.sort(compare)for item in tasklist:print '%s\t%s.%s\t%s\t%s\t% 4d\t% 2.1f%%\t% .2f' %(item['stat'], item['host'], item['path'],time.strftime('%H:%M:%S', time.localtime(item['wake'])),(('D' == item['stat']) and time.strftime('%H:%M:%S', time.localtime(item['done']))) or '--',item['cost'], 100 * item['cost'] / ttl, idx * item['cost'])if (not len(tasklist) or not statvars['cnt']):returnprint '\n--- DataX Profiling Statistics ---'print '%d task(s) on %d server(s), Total elapsed %d second(s), %.2f second(s) per task in average' %(statvars['cnt'],statvars['svr'], statvars['sum'], float(statvars['sum']) / statvars['cnt'])print 'Actually cost %d second(s) (%s - %s), task concurrency: %.2f, tilt index: %.2f' %(ttl,time.strftime('%H:%M:%S', time.localtime(statvars['min'])),time.strftime('%H:%M:%S', time.localtime(statvars['max'])),float(statvars['sum']) / ttl, idx * tasklist[0]['cost'])idx_commit = float(statvars_commit['cnt']) / (statvars_commit['sum'] or ttl)tasklist_commit.sort(compare)print '%d task(s) done odps comit, Total elapsed %d second(s), %.2f second(s) per task in average, tilt index: %.2f' % (statvars_commit['cnt'],statvars_commit['sum'], float(statvars_commit['sum']) / statvars_commit['cnt'],idx_commit * tasklist_commit[0]['cost'])# }}} #if (len(sys.argv) < 2):print "Usage: %s filename" %(sys.argv[0])quit(1)else:parse_task(sys.argv[1])result_analyse()
#!/usr/bin/env python# -*- coding:utf-8 -*-"""Life's short, Python more."""import reimport osimport sysimport jsonimport uuidimport signalimport timeimport subprocessfrom optparse import OptionParserreload(sys)sys.setdefaultencoding('utf8')##begin cli & help logicdef getOptionParser():usage = getUsage()parser = OptionParser(usage = usage)#rdbms reader and writerparser.add_option('-r', '--reader', action='store', dest='reader', help='trace datasource read performance with specified !json! string')parser.add_option('-w', '--writer', action='store', dest='writer', help='trace datasource write performance with specified !json! string')parser.add_option('-c', '--channel', action='store', dest='channel', default='1', help='the number of concurrent sync thread, the default is 1')parser.add_option('-f', '--file', action='store', help='existing datax configuration file, include reader and writer params')parser.add_option('-t', '--type', action='store', default='reader', help='trace which side\'s performance, cooperate with -f --file params, need to be reader or writer')parser.add_option('-d', '--delete', action='store', default='true', help='delete temporary files, the default value is true')#parser.add_option('-h', '--help', action='store', default='true', help='print usage information')return parserdef getUsage():return '''The following params are available for -r --reader:[these params is for rdbms reader, used to trace rdbms read performance, it's like datax's key]*datasourceType: datasource type, may be mysql|drds|oracle|ads|sqlserver|postgresql|db2 etc...*jdbcUrl: datasource jdbc connection string, mysql as a example: jdbc:mysql://ip:port/database*username: username for datasource*password: password for datasource*table: table name for read datacolumn: column to be read, the default value is ['*']splitPk: the splitPk column of rdbms tablewhere: limit the scope of the performance data setfetchSize: how many rows to be fetched at each communicate[these params is for stream reader, used to trace rdbms write performance]reader-sliceRecordCount: how man test data to mock(each channel), the default value is 10000reader-column : stream reader while generate test data(type supports: string|long|date|double|bool|bytes; support constant value and random function)锛宒emo: [{"type":"string","value":"abc"},{"type":"string","random":"10,20"}]The following params are available for -w --writer:[these params is for rdbms writer, used to trace rdbms write performance, it's like datax's key]datasourceType: datasource type, may be mysql|drds|oracle|ads|sqlserver|postgresql|db2|ads etc...*jdbcUrl: datasource jdbc connection string, mysql as a example: jdbc:mysql://ip:port/database*username: username for datasource*password: password for datasource*table: table name for write datacolumn: column to be writed, the default value is ['*']batchSize: how many rows to be storeed at each communicate, the default value is 512preSql: prepare sql to be executed before write data, the default value is ''postSql: post sql to be executed end of write data, the default value is ''url: required for ads, pattern is ip:portschme: required for ads, ads database name[these params is for stream writer, used to trace rdbms read performance]writer-print: true means print data read from source datasource, the default value is falseThe following params are available global control:-c --channel: the number of concurrent tasks, the default value is 1-f --file: existing completely dataX configuration file path-t --type: test read or write performance for a datasource, couble be reader or writer, in collaboration with -f --file-h --help: print help messagesome demo:perftrace.py --channel=10 --reader='{"jdbcUrl":"jdbc:mysql://127.0.0.1:3306/database", "username":"", "password":"", "table": "", "where":"", "splitPk":"", "writer-print":"false"}'perftrace.py --channel=10 --writer='{"jdbcUrl":"jdbc:mysql://127.0.0.1:3306/database", "username":"", "password":"", "table": "", "reader-sliceRecordCount": "10000", "reader-column": [{"type":"string","value":"abc"},{"type":"string","random":"10,20"}]}'perftrace.py --file=/tmp/datax.job.json --type=reader --reader='{"writer-print": "false"}'perftrace.py --file=/tmp/datax.job.json --type=writer --writer='{"reader-sliceRecordCount": "10000", "reader-column": [{"type":"string","value":"abc"},{"type":"string","random":"10,20"}]}'some example jdbc url pattern, may help:jdbc:oracle:thin:@ip:port:databasejdbc:mysql://ip:port/databasejdbc:sqlserver://ip:port;DatabaseName=databasejdbc:postgresql://ip:port/databasewarn: ads url pattern is ip:portwarn: test write performance will write data into your table, you can use a temporary table just for test.'''def printCopyright():DATAX_VERSION = 'UNKNOWN_DATAX_VERSION'print '''DataX Util Tools (%s), From Alibaba !Copyright (C) 2010-2016, Alibaba Group. All Rights Reserved.''' % DATAX_VERSIONsys.stdout.flush()def yesNoChoice():yes = set(['yes','y', 'ye', ''])no = set(['no','n'])choice = raw_input().lower()if choice in yes:return Trueelif choice in no:return Falseelse:sys.stdout.write("Please respond with 'yes' or 'no'")##end cli & help logic##begin process logicdef suicide(signum, e):global childProcessprint >> sys.stderr, "[Error] Receive unexpected signal %d, starts to suicide." % (signum)if childProcess:childProcess.send_signal(signal.SIGQUIT)time.sleep(1)childProcess.kill()print >> sys.stderr, "DataX Process was killed ! you did ?"sys.exit(-1)def registerSignal():global childProcesssignal.signal(2, suicide)signal.signal(3, suicide)signal.signal(15, suicide)def fork(command, isShell=False):global childProcesschildProcess = subprocess.Popen(command, shell = isShell)registerSignal()(stdout, stderr) = childProcess.communicate()#闃诲鐩村埌瀛愯繘绋嬬粨鏉? childProcess.wait()return childProcess.returncode##end process logic##begin datax json generate logic#warn: if not '': -> true; if not None: -> truedef notNone(obj, context):if not obj:raise Exception("Configuration property [%s] could not be blank!" % (context))def attributeNotNone(obj, attributes):for key in attributes:notNone(obj.get(key), key)def isBlank(value):if value is None or len(value.strip()) == 0:return Truereturn Falsedef parsePluginName(jdbcUrl, pluginType):import re#warn: drdsname = 'pluginName'mysqlRegex = re.compile('jdbc:(mysql)://.*')if (mysqlRegex.match(jdbcUrl)):name = 'mysql'postgresqlRegex = re.compile('jdbc:(postgresql)://.*')if (postgresqlRegex.match(jdbcUrl)):name = 'postgresql'oracleRegex = re.compile('jdbc:(oracle):.*')if (oracleRegex.match(jdbcUrl)):name = 'oracle'sqlserverRegex = re.compile('jdbc:(sqlserver)://.*')if (sqlserverRegex.match(jdbcUrl)):name = 'sqlserver'db2Regex = re.compile('jdbc:(db2)://.*')if (db2Regex.match(jdbcUrl)):name = 'db2'return "%s%s" % (name, pluginType)def renderDataXJson(paramsDict, readerOrWriter = 'reader', channel = 1):dataxTemplate = {"job": {"setting": {"speed": {"channel": 1}},"content": [{"reader": {"name": "","parameter": {"username": "","password": "","sliceRecordCount": "10000","column": ["*"],"connection": [{"table": [],"jdbcUrl": []}]}},"writer": {"name": "","parameter": {"print": "false","connection": [{"table": [],"jdbcUrl": ''}]}}}]}}dataxTemplate['job']['setting']['speed']['channel'] = channeldataxTemplateContent = dataxTemplate['job']['content'][0]pluginName = ''if paramsDict.get('datasourceType'):pluginName = '%s%s' % (paramsDict['datasourceType'], readerOrWriter)elif paramsDict.get('jdbcUrl'):pluginName = parsePluginName(paramsDict['jdbcUrl'], readerOrWriter)elif paramsDict.get('url'):pluginName = 'adswriter'theOtherSide = 'writer' if readerOrWriter == 'reader' else 'reader'dataxPluginParamsContent = dataxTemplateContent.get(readerOrWriter).get('parameter')dataxPluginParamsContent.update(paramsDict)dataxPluginParamsContentOtherSide = dataxTemplateContent.get(theOtherSide).get('parameter')if readerOrWriter == 'reader':dataxTemplateContent.get('reader')['name'] = pluginNamedataxTemplateContent.get('writer')['name'] = 'streamwriter'if paramsDict.get('writer-print'):dataxPluginParamsContentOtherSide['print'] = paramsDict['writer-print']del dataxPluginParamsContent['writer-print']del dataxPluginParamsContentOtherSide['connection']if readerOrWriter == 'writer':dataxTemplateContent.get('reader')['name'] = 'streamreader'dataxTemplateContent.get('writer')['name'] = pluginNameif paramsDict.get('reader-column'):dataxPluginParamsContentOtherSide['column'] = paramsDict['reader-column']del dataxPluginParamsContent['reader-column']if paramsDict.get('reader-sliceRecordCount'):dataxPluginParamsContentOtherSide['sliceRecordCount'] = paramsDict['reader-sliceRecordCount']del dataxPluginParamsContent['reader-sliceRecordCount']del dataxPluginParamsContentOtherSide['connection']if paramsDict.get('jdbcUrl'):if readerOrWriter == 'reader':dataxPluginParamsContent['connection'][0]['jdbcUrl'].append(paramsDict['jdbcUrl'])else:dataxPluginParamsContent['connection'][0]['jdbcUrl'] = paramsDict['jdbcUrl']if paramsDict.get('table'):dataxPluginParamsContent['connection'][0]['table'].append(paramsDict['table'])traceJobJson = json.dumps(dataxTemplate, indent = 4)return traceJobJsondef isUrl(path):if not path:return Falseif not isinstance(path, str):raise Exception('Configuration file path required for the string, you configure is:%s' % path)m = re.match(r"^http[s]?://\S+\w*", path.lower())if m:return Trueelse:return Falsedef readJobJsonFromLocal(jobConfigPath):jobConfigContent = NonejobConfigPath = os.path.abspath(jobConfigPath)file = open(jobConfigPath)try:jobConfigContent = file.read()finally:file.close()if not jobConfigContent:raise Exception("Your job configuration file read the result is empty, please check the configuration is legal, path: [%s]\nconfiguration:\n%s" % (jobConfigPath, str(jobConfigContent)))return jobConfigContentdef readJobJsonFromRemote(jobConfigPath):import urllibconn = urllib.urlopen(jobConfigPath)jobJson = conn.read()return jobJsondef parseJson(strConfig, context):try:return json.loads(strConfig)except Exception, e:import tracebacktraceback.print_exc()sys.stdout.flush()print >> sys.stderr, '%s %s need in line with json syntax' % (context, strConfig)sys.exit(-1)def convert(options, args):traceJobJson = ''if options.file:if isUrl(options.file):traceJobJson = readJobJsonFromRemote(options.file)else:traceJobJson = readJobJsonFromLocal(options.file)traceJobDict = parseJson(traceJobJson, '%s content' % options.file)attributeNotNone(traceJobDict, ['job'])attributeNotNone(traceJobDict['job'], ['content'])attributeNotNone(traceJobDict['job']['content'][0], ['reader', 'writer'])attributeNotNone(traceJobDict['job']['content'][0]['reader'], ['name', 'parameter'])attributeNotNone(traceJobDict['job']['content'][0]['writer'], ['name', 'parameter'])if options.type == 'reader':traceJobDict['job']['content'][0]['writer']['name'] = 'streamwriter'if options.reader:traceReaderDict = parseJson(options.reader, 'reader config')if traceReaderDict.get('writer-print') is not None:traceJobDict['job']['content'][0]['writer']['parameter']['print'] = traceReaderDict.get('writer-print')else:traceJobDict['job']['content'][0]['writer']['parameter']['print'] = 'false'else:traceJobDict['job']['content'][0]['writer']['parameter']['print'] = 'false'elif options.type == 'writer':traceJobDict['job']['content'][0]['reader']['name'] = 'streamreader'if options.writer:traceWriterDict = parseJson(options.writer, 'writer config')if traceWriterDict.get('reader-column'):traceJobDict['job']['content'][0]['reader']['parameter']['column'] = traceWriterDict['reader-column']if traceWriterDict.get('reader-sliceRecordCount'):traceJobDict['job']['content'][0]['reader']['parameter']['sliceRecordCount'] = traceWriterDict['reader-sliceRecordCount']else:columnSize = len(traceJobDict['job']['content'][0]['writer']['parameter']['column'])streamReaderColumn = []for i in range(columnSize):streamReaderColumn.append({"type": "long", "random": "2,10"})traceJobDict['job']['content'][0]['reader']['parameter']['column'] = streamReaderColumntraceJobDict['job']['content'][0]['reader']['parameter']['sliceRecordCount'] = 10000else:pass#do nothingreturn json.dumps(traceJobDict, indent = 4)elif options.reader:traceReaderDict = parseJson(options.reader, 'reader config')return renderDataXJson(traceReaderDict, 'reader', options.channel)elif options.writer:traceWriterDict = parseJson(options.writer, 'writer config')return renderDataXJson(traceWriterDict, 'writer', options.channel)else:print getUsage()sys.exit(-1)#dataxParams = {}#for opt, value in options.__dict__.items():# dataxParams[opt] = value##end datax json generate logicif __name__ == "__main__":printCopyright()parser = getOptionParser()options, args = parser.parse_args(sys.argv[1:])#print options, argsdataxTraceJobJson = convert(options, args)#鐢盡AC鍦板潃銆佸綋鍓嶆椂闂存埑銆侀殢鏈烘暟鐢熸垚,鍙互淇濊瘉鍏ㄧ悆鑼冨洿鍐呯殑鍞竴鎬? dataxJobPath = os.path.join(os.getcwd(), "perftrace-" + str(uuid.uuid1()))jobConfigOk = Trueif os.path.exists(dataxJobPath):print "file already exists, truncate and rewrite it? %s" % dataxJobPathif yesNoChoice():jobConfigOk = Trueelse:print "exit failed, because of file conflict"sys.exit(-1)fileWriter = open(dataxJobPath, 'w')fileWriter.write(dataxTraceJobJson)fileWriter.close()print "trace environments:"print "dataxJobPath: %s" % dataxJobPathdataxHomePath = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))print "dataxHomePath: %s" % dataxHomePathdataxCommand = "%s %s" % (os.path.join(dataxHomePath, "bin", "datax.py"), dataxJobPath)print "dataxCommand: %s" % dataxCommandreturncode = fork(dataxCommand, True)if options.delete == 'true':os.remove(dataxJobPath)sys.exit(returncode)
cmd中文显示乱码处理
在cmd中输入CHCP 65001,就是将编码方式调整为UTF-8
CHCP 65001
DataX 基本使用
查看模板
python D:/DataX/datax/bin/datax.py -r streamreader -w streamwriter
输出
{"job": {"content": [{"reader": {"name": "streamreader","parameter": {"column": [],"sliceRecordCount": ""}},"writer": {"name": "streamwriter","parameter": {"encoding": "","print": true}}}],"setting": {"speed": {"channel": ""}}}}
run test job
根据模板编写 json 文件
cd D:\DataX\datax\job
在该目录下,新建文件test.json
{"job": {"content": [{"reader": {"name": "streamreader","parameter": {"column": [{"type": "string","value": "Hello."},{"type": "string","value": "河北彭于晏"},],"sliceRecordCount": "3"}},"writer": {"name": "streamwriter","parameter": {"encoding": "utf-8","print": true}}}],"setting": {"speed": {"channel": "2"}}}}
,验证test.json
python D:/DataX/datax/bin/datax.py D:/DataX/datax/job/test.json
输出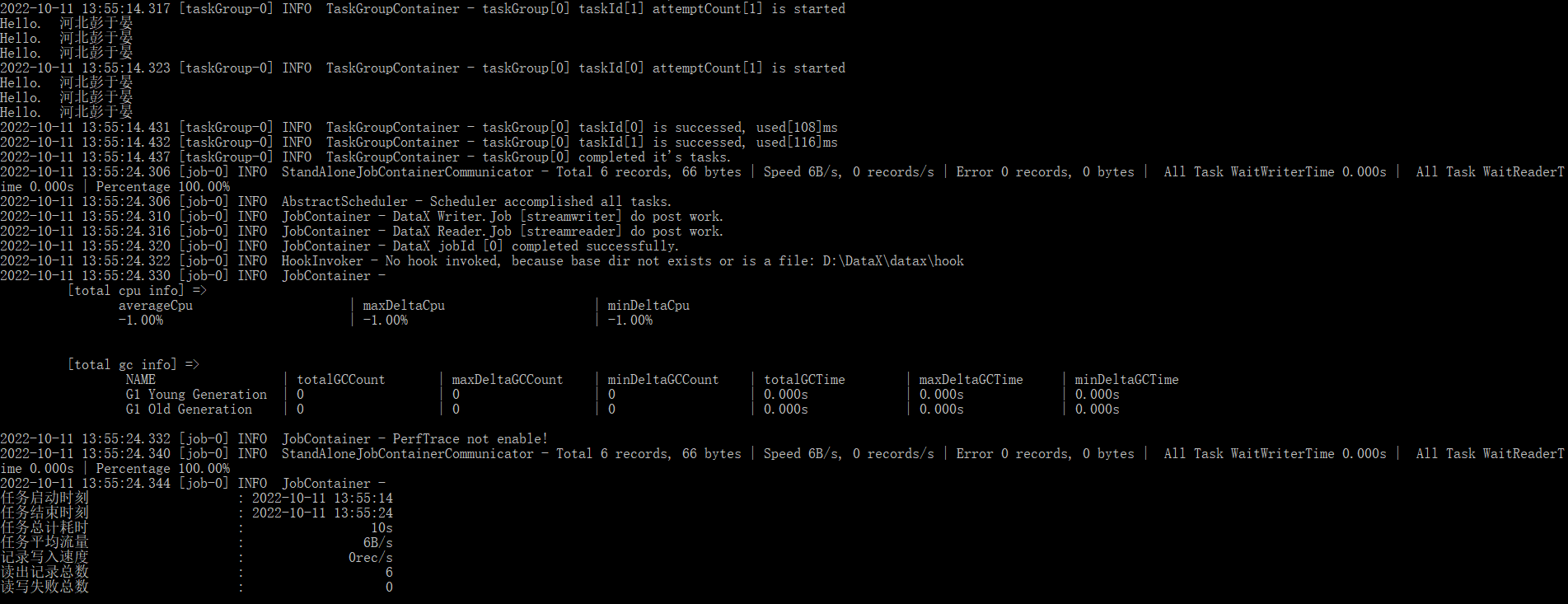

若有收获,就点个赞吧
0 人点赞
