zset数据结构
zset的编码有ziplist和skiplist两种。
底层分别使用ziplist(压缩链表)或skiplist(跳表)实现。当数据比较少的时候用ziplist编码结构存储。
同时满足以下两个条件采用ziplist存储:
- 有序集合保存的元素数量小于默认值128个
有序集合保存的所有元素的长度小于默认值64字节
不能满足上面两个条件的使用 skiplist 编码。以上两个条件也可以通过Redis配置文件zset-max-ziplist-entries 选项和 zset-max-ziplist-value 进行修改。
对于一个 REDIS_ENCODING_ZIPLIST 编码的 Zset, 只要满足以上任一条件, 则转为REDIS_ENCODING_SKIPLIST 编码。
zset操作命令
/**向名称为key的zset中添加元素member,score用于排序。* 如果该元素已经存在,则根据score更新该元素的顺序。*/zadd(key, score, member)// 删除名称为key的zset中的元素memberzrem(key, member)zincrby(key, increment, member):如果在名称为key的zset中已经存在元素member,则该元素的score增加increment;否则向集合中添加该元素,其score的值为incrementzrank(key, member):返回名称为key的zset(元素已按score从小到大排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”zrevrank(key, member):返回名称为key的zset(元素已按score从大到小排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”zrange(key, start, end):返回名称为key的zset(元素已按score从小到大排序)中的index从start到end的所有元素zrevrange(key, start, end):返回名称为key的zset(元素已按score从大到小排序)中的index从start到end的所有元素zrangebyscore(key, min, max):返回名称为key的zset中score >= min且score <= max的所有元素zcard(key):返回名称为key的zset的基数zscore(key, element):返回名称为key的zset中元素element的scorezremrangebyrank(key, min, max):删除名称为key的zset中rank >= min且rank <= max的所有元素zremrangebyscore(key, min, max):删除名称为key的zset中score >= min且score <= max的所有元素
ziplist
ziplist 编码的 Zset 使用紧挨在一起的压缩列表节点来保存,第一个节点保存 member,第二个保存 score。ziplist 内的集合元素按 score 从小到大排序,其实质是一个双向链表。虽然元素是按 score 有序排序的, 但对 ziplist 的节点指针只能线性地移动,所以在 REDIS_ENCODING_ZIPLIST 编码的 Zset 中, 查找某个给定元素的复杂度为 O(N)。
- ziplist是为节省内存空间而生的。
- ziplist是一个为Redis专门提供的底层数据结构之一,本身可以有序也可以无序。当作为list和hash的底层实现时,节点之间没有顺序;当作为zset的底层实现时,节点之间会按照大小顺序排列。
2.添加测试数据
ZADD price 8.5 apple 5.0 banana 6.0 cherry
在redis中从小到大排列

- 从以上的布局中,我们可以看到ziplist内存数据结构,由如下5部分构成:

各个部分在内存上是前后相邻的并连续的,每一部分作用如下:
zlbytes: 存储一个无符号整数,固定四个字节长度(32bit),用于存储压缩列表所占用的字节(也包括
zltail: 存储一个无符号整数,固定四个字节长度(32bit),表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。
zllen: 压缩列表包含的节点个数,固定两个字节长度(16bit), 表示ziplist中数据项(entry)的个数。由于zllen字段只有16bit,所以可以表达的最大值为2^16-1。
注意点:如果ziplist中数据项个数超过了16bit能表达的最大值,ziplist仍然可以表示。ziplist是如何做到的?
如果
entry,表示真正存放数据的数据项,长度不定。一个数据项(entry)也有它自己的内部结构。
zlend, ziplist最后1个字节,值固定等于255,其是一个结束标记。
skiplist
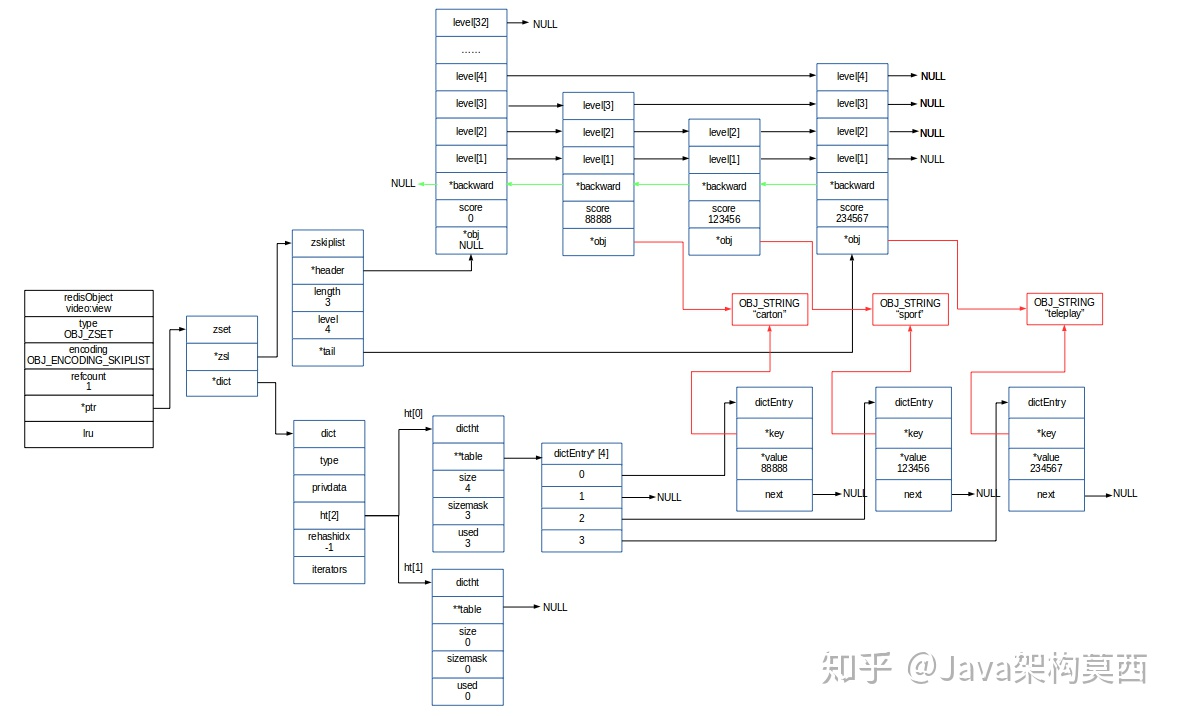
skiplist 编码的 Zset 底层为一个被称为 zset 的结构体,这个结构体中包含一个字典和一个跳跃表。
typedef struct zset{// 字典 键为成员,值为分值// 用于支持O(1) 复杂度的按成员取分值操作dict *dict;// 跳跃表 按分值排序成员// 用于支持平均复杂度为O(logN)的按分值定位成员操作以及范围操作zskiplist *zsl;} zset;
字典的键保存元素的值,字典的值则保存元素的分值;而zkiplist作为跳跃表,节点的 object 属性保存元素的成员,跳跃表节点的 score 属性保存元素的分值。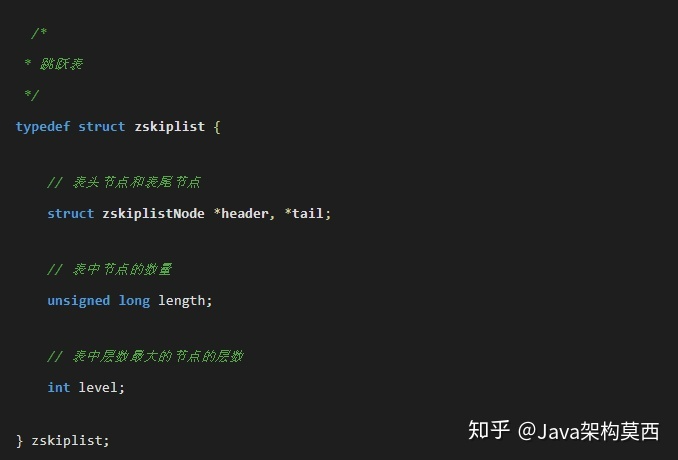
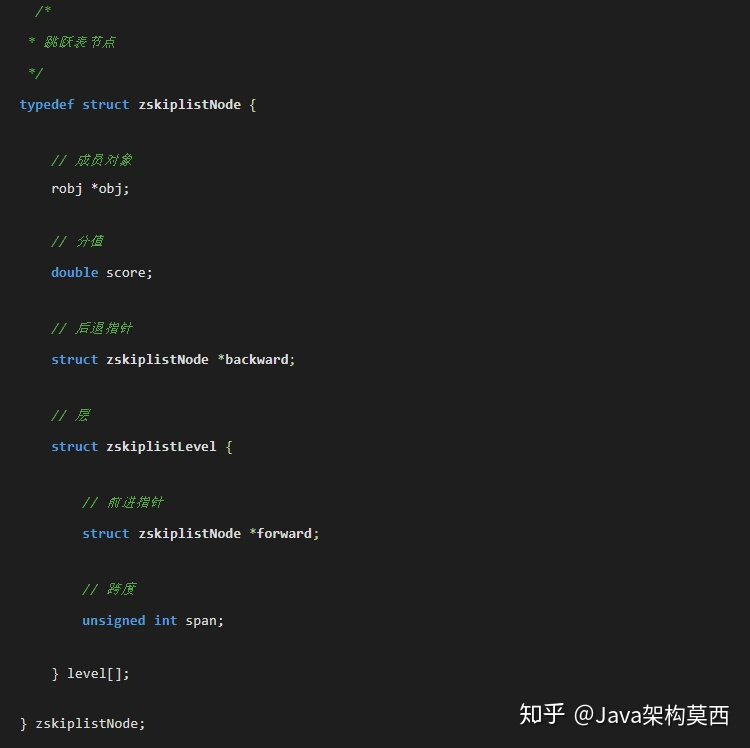
zskiplistNode中的robj指针指向具体元素,注意这个指针和dict中key指针指向同一个元素,其中backward后退指针便于回溯。
跳跃表按 score 从小到大保存所有集合元素,查找时间复杂度为平均 O(logN),最坏 O(N) 。字典则保存着从 member 到 score 的映射,这样就可以用 O(1)的复杂度来查找 member 对应的 score 值。虽然同时使用两种结构,但它们会通过指针来共享相同元素的 member 和 score,因此不会浪费额外的内存。
说明:其实有序集合单独使用字典或跳跃表其中一种数据结构都可以实现,但是这里使用两种数据结构组合起来,原因是假如我们单独使用 字典,虽然能以 O(1) 的时间复杂度查找成员的分值,但是因为字典是以无序的方式来保存集合元素,所以每次进行范围操作的时候都要进行排序;假如我们单独使用跳跃表来实现,虽然能执行范围操作,但是查找操作有 O(1)的复杂度变为了O(logN)。因此Redis使用了两种数据结构来共同实现有序集合。
详解
跳表(skip List)是一种随机化的数据结构, 插入、删除、查找的复杂度均为O(logN)。简单说来跳表也是链表的一种,只不过它在链表的基础上增加了跳跃功能,正是这个跳跃的功能,使得在查找元素时,跳表能够提供O(logN)的时间复杂度。
先来看一个有序链表,如下图(最左侧的灰色节点表示一个空的头结点):
在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:
这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是7, 19, 26)。现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数据大的节点时,再回到原来的链表中进行查找。比如,我们想查找23,查找的路径是沿着下图中标红的指针所指向的方向进行的:
23首先和7比较,再和19比较,比它们都大,继续向后比较。
但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。
23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它的插入位置应该在22和26之间。
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。
利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:
在这个新的三层链表结构上,如果我们还是查找23,那么沿着最上层链表首先要比较的是19,发现23比19大,接下来我们就知道只需要到19的后面去继续查找,从而一下子跳过了19前面的所有节点。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度。
skiplist正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。
但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)。删除数据也有同样的问题。
skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)。比如,一个节点随机出的层数是3,那么就把它链入到第1层到第3层这三层链表中。为了表达清楚,下图展示了如何通过一步步的插入操作从而形成一个skiplist的过程: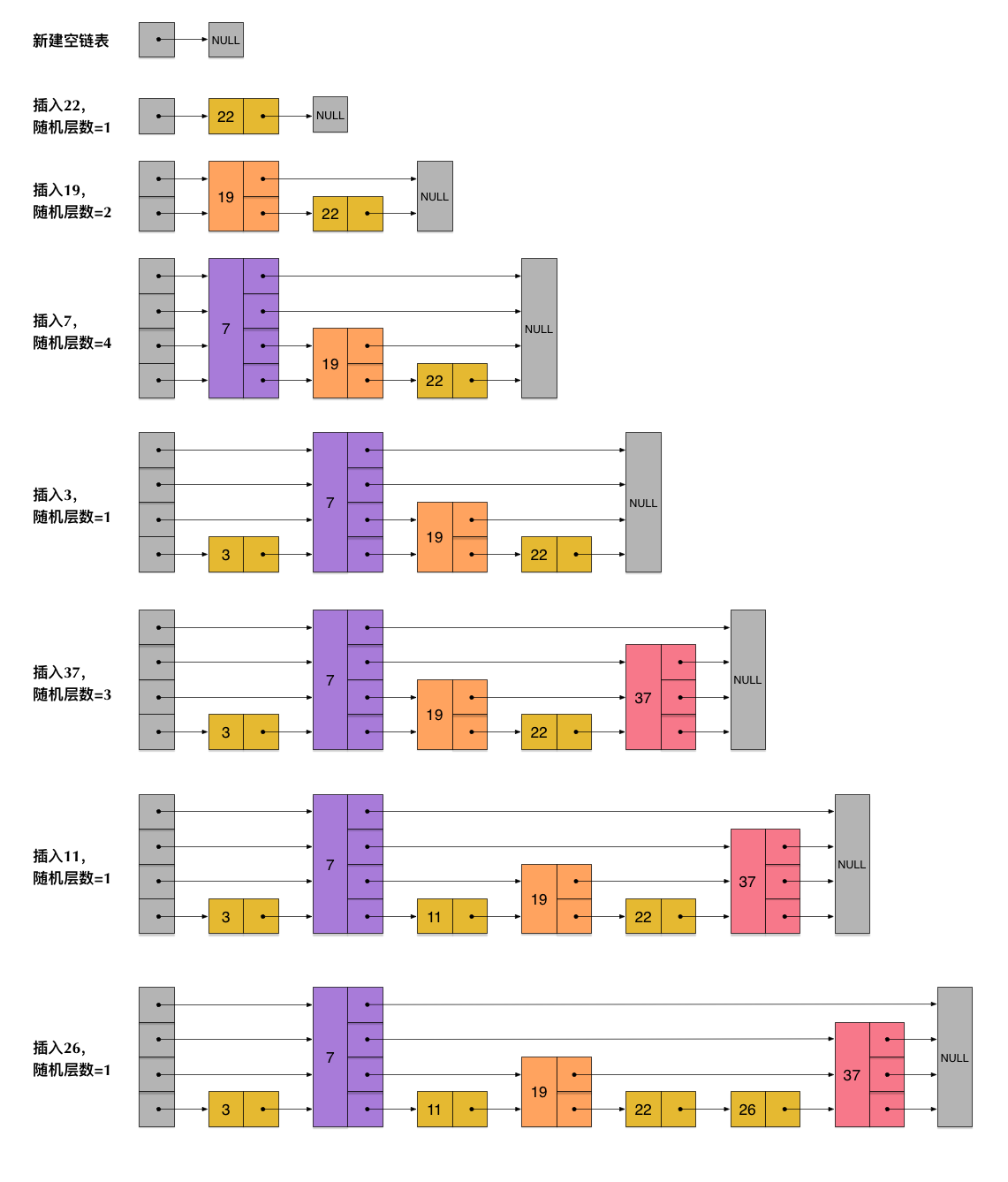
从上面skiplist的创建和插入过程可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是skiplist的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。这在后面我们还会提到。
skiplist,指的就是除了最下面第1层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针故意跳过了一些节点(而且越高层的链表跳过的节点越多)。这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置。在这个过程中,我们跳过了一些节点,从而也就加快了查找速度。
刚刚创建的这个skiplist总共包含4层链表,现在假设我们在它里面依然查找23,下图给出了查找路径: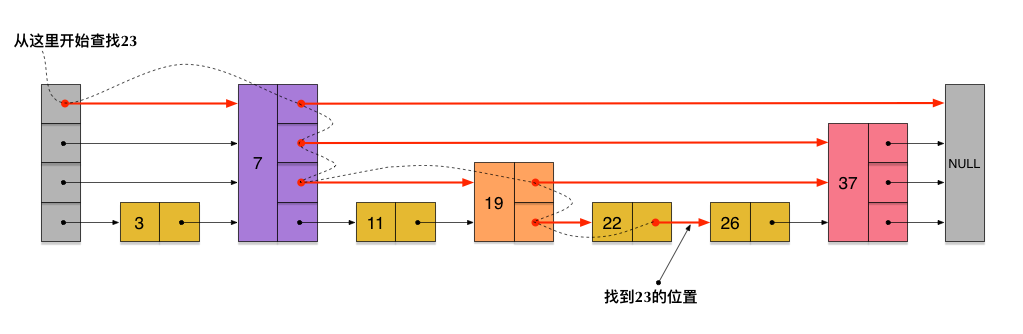
需要注意的是,前面演示的各个节点的插入过程,实际上在插入之前也要先经历一个类似的查找过程,在确定插入位置后,再完成插入操作。
实际应用中的skiplist每个节点应该包含key和value两部分。前面的描述中我们没有具体区分key和value,但实际上列表中是按照key(score)进行排序的,查找过程也是根据key在比较。
执行插入操作时计算随机数的过程,是一个很关键的过程,它对skiplist的统计特性有着很重要的影响。这并不是一个普通的服从均匀分布的随机数,它的计算过程如下:
首先,每个节点肯定都有第1层指针(每个节点都在第1层链表里)。
如果一个节点有第i层(i>=1)指针(即节点已经在第1层到第i层链表中),那么它有第(i+1)层指针的概率为p。
节点最大的层数不允许超过一个最大值,记为MaxLevel。
这个计算随机层数的伪码如下所示:
randomLevel()level := 1// random()返回一个[0...1)的随机数while random() < p and level < MaxLevel dolevel := level + 1return level
randomLevel()的伪码中包含两个参数,一个是p,一个是MaxLevel。在Redis的skiplist实现中,这两个参数的取值为:
p = 1/4MaxLevel = 32
Redis中的skiplist实现
skiplist的数据结构定义:
#define ZSKIPLIST_MAXLEVEL 32#define ZSKIPLIST_P 0.25typedef struct zskiplistNode {robj *obj;double score;struct zskiplistNode *backward;struct zskiplistLevel {struct zskiplistNode *forward;unsigned int span;} level[];} zskiplistNode;typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length;int level;} zskiplist;
简单分析一下几个查询命令:
- zrevrank由数据查询它对应的排名,这在前面介绍的skiplist中并不支持。
- zscore由数据查询它对应的分数,这也不是skiplist所支持的。
- zrevrange根据一个排名范围,查询排名在这个范围内的数据。这在前面介绍的skiplist中也不支持。
- zrevrangebyscore根据分数区间查询数据集合,是一个skiplist所支持的典型的范围查找(score相当于key,数据相当于value)。
实际上,Redis中sorted set的实现是这样的:
- 当数据较少时,sorted set是由一个ziplist来实现的。
- 当数据多的时候,sorted set是由一个dict + 一个skiplist来实现的。简单来讲,dict用来查询数据到分数的对应关系,而skiplist用来根据分数查询数据(可能是范围查找)。
看一下sorted set与skiplist的关系,:
- zscore的查询,不是由skiplist来提供的,而是由那个dict来提供的。
- 为了支持排名(rank),Redis里对skiplist做了扩展,使得根据排名能够快速查到数据,或者根据分数查到数据之后,也同时很容易获得排名。而且,根据排名的查找,时间复杂度也为O(log n)。
- zrevrange的查询,是根据排名查数据,由扩展后的skiplist来提供。
- zrevrank是先在dict中由数据查到分数,再拿分数到skiplist中去查找,查到后也同时获得了排名。
总结起来,Redis中的skiplist跟前面介绍的经典的skiplist相比,有如下不同:
- 分数(score)允许重复,即skiplist的key允许重复。这在最开始介绍的经典skiplist中是不允许的。
- 在比较时,不仅比较分数(相当于skiplist的key),还比较数据本身。在Redis的skiplist实现中,数据本身的内容唯一标识这份数据,而不是由key来唯一标识。另外,当多个元素分数相同的时候,还需要根据数据内容来进字典排序。
- 第1层链表不是一个单向链表,而是一个双向链表。这是为了方便以倒序方式获取一个范围内的元素。
- 在skiplist中可以很方便地计算出每个元素的排名(rank)。
redis中的zset为什么不使用红黑树而使用跳跃表
1、跳表的实现更加简单,不用旋转节点,相对效率更高。
2、跳表在范围查询的时候的效率是高于红黑树的,因为跳表是从上层往下层查找的,上层的区域范围更广,可以快速定位到查询的范围。
3、平衡树的插入和删除操作可能引发子树的调整、逻辑复杂,而跳表只需要维护相邻节点即可。
4、查找单个key,跳表和平衡树时间复杂度都是O(logN)。
[
](https://blog.csdn.net/qq_24950043/article/details/118305731)
首先,在做范围查询的时候,平衡树的操作要比跳跃表复杂。因为平衡树,在查询到最小值的时候,还需要采用中序遍历去查询最大值。 而skipList只需要在找到最小值后,对第一层的链表(也就是最底层的链表)进行若干次遍历即可。
平衡树的删除和插入,需要对子树进行相应的调整,操作复杂。而skiplist只需要修改相邻的节点即可。
在做查询操作的时候,skiplist和平衡树都是O(logN)的时间复杂度。
从整体上来看,skiplist算法实现的难度要低于平衡树。
3. 跳跃表的实现
3.1 跳跃表的查询
跳跃表就像是上图一样的一个多层的链表,如果查询46的话。其步骤是:
(1)查询L4层,查询55,需要查询1次
(2)查询L3层,查询–>21–>55,需要查询2次
(3)查询L2层,查询–>37–>55,需要查询2次
(4)查询L1层,查询–>46,查询1次,找到结果
跳跃表就好像每两个元素抽取一个元素放到上一层,这样一次叠加,就形成了多层的链表。上一层的元素个数是下一层元素个数的1/2,所以查询的时候就类似二分查找。
这种方法类似于二分查找的方法,所以跳跃表的查找的时间复杂度为O(logN)
跳跃表每个节点包含两个指针,一个指向同一链表中的下一个元素(next),一个指向下面一层的元素(down)。
3.2 插入
我们往跳表中插入数据的时候,可以选择同时将这个数据插入到第几层中,比如随机函数生成了值 K,那我们就将这个结点添加到第一层到第 K 层这 K 级索引中。
随机的K是如何产生的:
通过随机数来产生,第一层肯定需要添加元素,所以K的初始值为1。后面的,如果随机数为1,就是K加一,随机数为0,就退出。这样每一层插入该元素的概率为(1/2)^ n。这样就很大程度上保证了后一层元素的总数量是前一层元素的2倍。
int random_level(){K = 1;while (random(0,1))K++;return K;}
3.3 删除
在各个层中找到包含 x 的节点,使用标准的 delete from list 方法删除该节点。直接删除元素,然后调整一下删除元素后的指针即可。跟普通的链表删除操作完全一样。
跳跃表插入和删除的时间复杂度都是O(logN)

若有收获,就点个赞吧
0 人点赞
