第一章.项目需求一:日活统计
1.创建子模块(gmall-realtime)
该模块为实时处理模块,主要负责对采集到的数据进行实时处理
一.pom.xml
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId></dependency><!-- 使用java连接redis --><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version></dependency><dependency><artifactId>gmall-common</artifactId><groupId>org.example</groupId><version>1.0-SNAPSHOT</version></dependency><dependency><groupId>org.apache.phoenix</groupId><artifactId>phoenix-spark</artifactId><version>5.0.0-HBase-2.0</version><exclusions><exclusion><groupId>org.glassfish</groupId><artifactId>javax.el</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId></dependency><dependency><groupId>commons-httpclient</groupId><artifactId>commons-httpclient</artifactId><version>3.1</version></dependency></dependencies><build><plugins><!-- 该插件用于将Scala代码编译成class文件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.0</version><executions><execution><!-- 声明绑定到maven的compile阶段 --><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins></build>
二.配置文件
- config.properties
# Kafka配置kafka.broker.list=hadoop102:9092,hadoop103:9092,hadoop104:9092# Redis配置redis.host=hadoop102redis.port=6379
- log4j.properties
#定义了名为atguigu.MyConsole的一个ConsoleAppender 向控制台输出日志,红色打印,log4j.appender.atguigu.MyConsole=org.apache.log4j.ConsoleAppenderlog4j.appender.atguigu.MyConsole.target=System.errlog4j.appender.atguigu.MyConsole.layout=org.apache.log4j.PatternLayout# 年-月-日 时:分:秒 10个占位符 日志级别 (全类名:方法名) - 消息 换行log4j.appender.atguigu.MyConsole.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %10p (%c:%M) - %m%n#代表指定哪个类的logger使用什么级别和appender进行日志输出 全类名可能需要修改log4j.rootLogger=error,atguigu.MyConsole
三.工具类
- 消费kafka中的数据
- 利用Redis过滤当日已经计入的日活设备
- 把每批次新增的当日的日活信息保存在Hbase中
- 从HBase中查询出数据,发布成数据接口,通过可视化工程调用
- PropertiesUtil.scala
package com.atguigu.realtime.utilsimport java.io.InputStreamReaderimport java.util.Properties// 加载类路径的一个properties文件,只需要调用load方法,自动将properties文件读取,封装一个Properties返回object PropertiesUtil {def load(propertieName:String): Properties ={val prop=new Properties()prop.load(new InputStreamReader(Thread.currentThread().getContextClassLoader.getResourceAsStream(propertieName) , "UTF-8"))prop}}
- MyKafkaUtil.scala
package com.atguigu.realtime.utilsimport java.util.Propertiesimport org.apache.kafka.clients.consumer.ConsumerRecordimport org.apache.kafka.common.TopicPartitionimport org.apache.kafka.common.serialization.StringDeserializerimport org.apache.spark.streaming.StreamingContextimport org.apache.spark.streaming.dstream.InputDStreamimport org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}object MyKafkaUtil {// 读取配置文件中的信息private val properties: Properties = PropertiesUtil.load("config.properties")// kafka集群地址val broker_list: String = properties.getProperty("kafka.broker.list")def getKafkaStream(topics: Array[String], ssc: StreamingContext, groupId:String, saveOffsetToMysql:Boolean = false ,offsetsMap: Map[TopicPartition, Long] =null , ifAutoCommit:String ="false" ): InputDStream[ConsumerRecord[String, String]] = {//kafka消费者配置val kafkaParam = Map("bootstrap.servers" -> broker_list,"key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> groupId,"auto.offset.reset" -> "earliest","enable.auto.commit" -> ifAutoCommit)var ds: InputDStream[ConsumerRecord[String, String]] =null;if (saveOffsetToMysql){ds = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topics, kafkaParam,offsetsMap))}else{ds = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topics, kafkaParam))}ds}}
- RedisUtil
package com.atguigu.realtime.utilsimport java.util.Propertiesimport redis.clients.jedis.{Jedis}object RedisUtil {val config: Properties = PropertiesUtil.load("config.properties")val host: String = config.getProperty("redis.host")val port: String = config.getProperty("redis.port")def getJedisClient():Jedis={new Jedis(host,port.toInt)}}
四.DAU实现
- 流程图

- 设计redis的key,value | key | value | | —- | —- | | 当前批次日期(logDate) | 设备号(mid) |
- Phoenix建表
create table gmall2021_startuplog(ar varchar,ba varchar,ch varchar,is_new Integer,md varchar,mid varchar,os varchar,uid BIGINT,vc varchar,entry varchar,loading_time Integer,open_ad_id Integer,open_ad_ms Integer,open_ad_skip_ms Integer,logDate varchar,logHour varchar,ts BIGINTCONSTRAINT dau_pk PRIMARY KEY (mid, logDate));
- 为了便于对数据进行解析,需要将数据封装为样例类(StartUpLog,StartLogoInfo)
package com.atguigu.realtime.beanscase class StartUpLog(//commonvar ar:String,var ba:String,var ch:String,var is_new:Int,var md:String,var mid:String,var os:String,var uid:Long,var vc:String,// startvar entry:String,var loading_time:Int,var open_ad_id:Int,var open_ad_ms:Int,var open_ad_skip_ms:Int,//kafka里面没有,为了统计最终结果,额外设置的字段,需要从ts转换得到var logDate:String,var logHour:String,var ts:Long){def mergeStartInfo(startInfo:StartLogInfo):Unit={if (startInfo != null){this.entry = startInfo.entrythis.loading_time = startInfo.loading_timethis.open_ad_id = startInfo.open_ad_idthis.open_ad_ms = startInfo.open_ad_msthis.open_ad_skip_ms = startInfo.open_ad_skip_ms}}}// 封装了 启动日志中 start:{}部分的属性,目的是为了方便展平case class StartLogInfo(entry:String,loading_time:Int,open_ad_id:Int,open_ad_ms:Int,open_ad_skip_ms:Int)
- 将每个需求实现的公共部分封装为一个抽象类(BaseApp)
package com.atguigu.realtime.appimport org.apache.spark.streaming.StreamingContext//该类是所有实时App程序继承的父类abstract class BaseApp {//抽象属性(只声明未赋值),让子类实现的var appName:Stringvar batchDuration:Intvar ssc:StreamingContext = nulldef runApp(op: =>Unit){try{//一堆代码opssc.start()ssc.awaitTermination()}catch{case e:Exception =>e.printStackTrace()throw new RuntimeException("运行失败")}}}
- 日活统计程序(DAUApp)
package com.atguigu.realtime.appimport com.alibaba.fastjson.JSONimport com.atguigu.constants.MyConstantsimport com.atguigu.realtime.beans.{StartLogInfo, StartUpLog}import com.atguigu.realtime.utils.{MyKafkaUtil, RedisUtil}import org.apache.hadoop.hbase.HBaseConfigurationimport org.apache.kafka.clients.consumer.ConsumerRecordimport org.apache.spark.SparkConfimport org.apache.spark.rdd.RDDimport org.apache.spark.streaming.kafka010.{CanCommitOffsets, HasOffsetRanges}import org.apache.spark.streaming.{Seconds, StreamingContext}import java.time.{Instant, LocalDateTime, ZoneId}import java.time.format.DateTimeFormatterimport scala.Seq//导入Phoenix提供的静态方法import org.apache.phoenix.spark._/*** 精确一次性: at least once(offsets维护到kafka) + hbase(幂等性输出)*/object DAUApp extends BaseApp {override var appName: String = "DAUApp"override var batchDuration: Int = 10val groupId = "gmallrealtime"/*** 将rdd封装为样例类* @param rdd* @return*/def parseRecordToBean(rdd: RDD[ConsumerRecord[String, String]]):RDD[StartUpLog] = {rdd.map(record => {//将record.value()封装为json对象val jSONObject = JSON.parseObject(record.value())//封装common部分压平的结果val startUpLog = JSON.parseObject(jSONObject.getString("common"), classOf[StartUpLog])//封装start部分并合并val startLogInfo = JSON.parseObject(jSONObject.getString("start"), classOf[StartLogInfo])startUpLog.mergeStartInfo(startLogInfo)//合并tsstartUpLog.ts = jSONObject.getLong("ts")//获取当前日志的日期和小时val formatter1 = DateTimeFormatter.ofPattern("yyyy-MM-dd")val formatter2 = DateTimeFormatter.ofPattern("HH")val time = LocalDateTime.ofInstant(Instant.ofEpochMilli(startUpLog.ts), ZoneId.of("Asia/Shanghai"))startUpLog.logDate = time.format(formatter1)startUpLog.logHour = time.format(formatter2)startUpLog})}/*** 同批次去重(根据当前批次的日期和设备号去重)* @param rdd* @return*/def removeDuplicateLogsInCommonBatch(rdd: RDD[StartUpLog]):RDD[StartUpLog] = {val rdd1 = rdd.map(log => {((log.logDate, log.mid), log)})val rdd2 = rdd1.groupByKey()//只对value进行运算,可以使用mapValuesval rdd3 = rdd2.mapValues({_.toList.sortBy(_.ts).take(1)})val rdd4 = rdd3.map(date => {((date._1, date._2.head))})rdd4.values}/*** 跨批次过滤* @param rdd* @return*/def removeDuplicateLogsInDiffBatch(rdd: RDD[StartUpLog]):RDD[StartUpLog] = {//连接数据库,都是以分区为单位获取连接rdd.mapPartitions(partition=>{//获取连接val jedis = RedisUtil.getJedisClient()//判断这条日志的mid和logdate是否在set集合中已经存在val filterdPartition = partition.filter(log => !jedis.sismember("DAU:" + log.logDate, log.mid))//关闭jedis.close()//返回处理后的分区filterdPartition})}def main(args: Array[String]): Unit = {ssc = new StreamingContext(new SparkConf().setMaster("local[4]").setAppName(appName),Seconds(batchDuration))runApp{//1.获取初始dsval ds = MyKafkaUtil.getKafkaStream(Array(MyConstants.STARTUP_LOG),ssc,groupId)ds.foreachRDD(rdd => {//真正从kafka消费到数据后,再执行以下运算,防止job每次数据提交,但是并无数据计算!if (!rdd.isEmpty()){//2.获取偏移量val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges//3.封装为样例类val rdd1 = parseRecordToBean(rdd)println("当前这批数据消费到:" + rdd1.count())//4.同批次去重val rdd2 = removeDuplicateLogsInCommonBatch(rdd1)println("同批次去重后: " + rdd2.count())//5.跨批次过滤val rdd3 = removeDuplicateLogsInDiffBatch(rdd2)rdd3.cache()println("跨批次过滤后: " + rdd3.count())//6.写入hbaserdd3.saveToPhoenix("GMALL2021_STARTUPLOG",Seq("AR", "BA", "CH", "IS_NEW", "MD", "MID", "OS", "UID", "VC", "ENTRY", "LOADING_TIME","OPEN_AD_ID","OPEN_AD_MS","OPEN_AD_SKIP_MS","LOGDATE","LOGHOUR","TS"),HBaseConfiguration.create(),Some("hadoop102:2181"))//7.将写入hbase完成的mid,logdate 记录到redisrdd3.foreachPartition(partition=>{val jedis = RedisUtil.getJedisClient()partition.foreach(log=>{jedis.sadd("DAU:"+log.logDate,log.mid)//设置key的过期时间,设置24小时过期jedis.expire("DAU:"+log.logDate,60*60*24)})jedis.close()})//8.提交偏移量ds.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)}})}}}
- 将数据写入数据库并测试
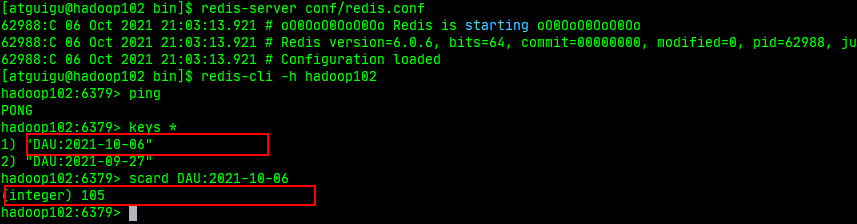
分别启动gmall-logger,nginx,zookeeper,kafka,hadoop,hbase,redis,phoenix
生产数据到kafka()

启动APP

分别在redis和Phoenix客户端验证

2.创建子模块(gmall-publisher)
该模块为日活数据查询接口,是一个springboot工程,主要负责对实时处理后的数据进行查询
一.pom.xml
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><artifactId>spark-gmall</artifactId><groupId>org.example</groupId><version>1.0-SNAPSHOT</version></parent><artifactId>gmall-publisher</artifactId><version>0.0.1-SNAPSHOT</version><name>gmall-publisher</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.0</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><artifactId>gmall-common</artifactId><groupId>org.example</groupId><version>1.0-SNAPSHOT</version></dependency><dependency><groupId>org.apache.phoenix</groupId><artifactId>phoenix-core</artifactId><version>5.0.0-HBase-2.0</version><exclusions><exclusion><groupId>org.glassfish</groupId><artifactId>javax.el</artifactId></exclusion></exclusions></dependency><!-- google提供的java开发的工具包,在很多框架中,都引入了guava--><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>20.0</version></dependency><!--java.lang.NoSuchMethodError: org.apache.hadoop.security.authentication.util.KerberosUtil.hasKerberosKeyTab--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.2</version></dependency><!-- 异构(不同架构 mysql hbase)数据源的切换 --><dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>2.4.2</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>1.5.10.RELEASE</version><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>
二.配置文件
- application.properties
#绑定8070端口,没写项目名 ,使用http://主机名:8070/server.port=8070#默认使用springboot提供的logger,记录级别为errorlogging.level.root=error#mybatismybatis.mapperLocations=classpath:mybatis/*.xmlmybatis.configuration.map-underscore-to-camel-case=true
- application.yml
spring:datasource:dynamic:primary: hbase #设置默认的数据源或者数据源组,默认值即为masterstrict: false #严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源datasource:hbase:url: jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181username:password:driver-class-name: org.apache.phoenix.jdbc.PhoenixDrivermysql:url: jdbc:mysql://hadoop103:3306/sparkproductusername: rootpassword: "321074"driver-class-name: com.mysql.jdbc.Driver
三.业务代码实现
- pojo层(DAUPerHour)
package com.example.gmallpublisher.pojo;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@NoArgsConstructor@AllArgsConstructor@Datapublic class DAUPerHour {private String hour;private Integer dau;}
- mapper层(DAUMapper)
package com.example.gmallpublisher.mapper;import com.baomidou.dynamic.datasource.annotation.DS;import com.example.gmallpublisher.pojo.DAUPerHour;import org.springframework.stereotype.Repository;import java.util.List;@Repository@DS("hbase")public interface DAUMapper {//查询单日日活Integer getDAUByDate(String date);//查询当日新增的设备数Integer getNewMidCountByDate(String date);//查询当日分时的设备数List<DAUPerHour> getDAUPerHourData(String date);}
- DAUMapper.xml
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><!--namespace=绑定一个对应的Dao/Mapper接口--><mapper namespace="com.example.gmallpublisher.mapper.DAUMapper"><!--查询当日日活--><select id="getDAUByDate" resultType="int">selectcount(*)from GMALL2021_STARTUPLOGwhere logdate = #{logdate}</select><!-- 查询当日新增的设备数--><select id="getNewMidCountByDate" resultType="int">select count(*)from(select midfrom GMALL2021_STARTUPLOGwhere logdate = #{logdate}) t1left join(select midfrom GMALL2021_STARTUPLOGwhere logdate < #{logdate}) t2on t1.mid = t2.midwhere t2.mid is null</select><!-- 查询当日分时的设备数 --><select id="getDAUPerHourData" resultType="com.example.gmallpublisher.pojo.DAUPerHour">selectloghour hour,count(*) daufrom GMALL2021_STARTUPLOGwhere logdate = #{logdate}group by loghour</select></mapper>
- service层(PublisherService,PublisherServiceImpl)
package com.example.gmallpublisher.service;import com.example.gmallpublisher.pojo.DAUPerHour;import com.example.gmallpublisher.pojo.GMVPerHour;import java.util.List;public interface PublisherService {//查询单日日活Integer getDAUByDate(String date);//查询当日新增的设备数Integer getNewMidCountByDate(String date);//查询当日分时的设备数List<DAUPerHour> getDAUPerHourData(String date);}
package com.example.gmallpublisher.service;import com.example.gmallpublisher.mapper.DAUMapper;import com.example.gmallpublisher.mapper.GMVMapper;import com.example.gmallpublisher.pojo.DAUPerHour;import com.example.gmallpublisher.pojo.GMVPerHour;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import java.util.List;@Servicepublic class PublisherServiceImpl implements PublisherService {@Autowiredprivate DAUMapper dauMapper;@Overridepublic Integer getDAUByDate(String date) {System.out.println("遵循的业务步骤");return dauMapper.getDAUByDate(date);}@Overridepublic Integer getNewMidCountByDate(String date) {System.out.println("遵循的业务步骤");return dauMapper.getNewMidCountByDate(date);}@Overridepublic List<DAUPerHour> getDAUPerHourData(String date) {System.out.println("遵循业务步骤");return dauMapper.getDAUPerHourData(date);}}
- controller层
package com.example.gmallpublisher.controller;import com.alibaba.fastjson.JSONObject;import com.example.gmallpublisher.pojo.DAUPerHour;import com.example.gmallpublisher.pojo.GMVPerHour;import com.example.gmallpublisher.service.PublisherService;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;import java.time.LocalDate;import java.util.ArrayList;import java.util.List;@RestControllerpublic class PublisherController {@Autowiredprivate PublisherService publisherService;/*** [* {"id":"dau","name":"当日日活数","value":1200},* {"id":"new_mid","name":"新增设备数","value":233}** ]* @param date* @return*/@RequestMapping(value="/realtime-total")public Object handle1(String date){//获取当日日活Integer dauByDate = publisherService.getDAUByDate(date);//获取当日新增设备数Integer newMidCountByDate = publisherService.getNewMidCountByDate(date);ArrayList<JSONObject> result = new ArrayList<>();JSONObject jsonObject1 = new JSONObject();JSONObject jsonObject2 = new JSONObject();/*JSONObject jsonObject3 = new JSONObject();*/jsonObject1.put("id","dau");jsonObject1.put("name","当日日活数");jsonObject1.put("value",dauByDate);jsonObject2.put("id","new_mid");jsonObject2.put("name","新增设备数");jsonObject2.put("value",newMidCountByDate);result.add(jsonObject1);result.add(jsonObject2);/*result.add(jsonObject3);*/return result;}/**** {"yesterday":{"11":383,"12":123,"17":88,"19":200},"today":{"12":38,"13":1233,"17":123,"19":688 }}** @param date* @return*/@RequestMapping(value="realtime-hours")public Object handle2(String id,String date){JSONObject result = new JSONObject();//根据今天的日期计算昨天的日期String yestodayDate = LocalDate.parse(date).minusDays(1).toString();if("dau".equals(id)){List<DAUPerHour> todayData = publisherService.getDAUPerHourData(date);List<DAUPerHour> yestodayData = publisherService.getDAUPerHourData(yestodayDate);result.put("yesterday",parseDAUDate(yestodayData));result.put("today",parseDAUDate(todayData));}return result;}public JSONObject parseDAUDate(List<DAUPerHour> data){JSONObject result = new JSONObject();for (DAUPerHour dauPerHour : data) {result.put(dauPerHour.getHour(),dauPerHour.getDau());}return result;}}
- 主程序
package com.example.gmallpublisher;import org.mybatis.spring.annotation.MapperScan;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication@MapperScan(basePackages = "com.example.gmallpublisher.mapper")public class GmallPublisherApplication {public static void main(String[] args) {SpringApplication.run(GmallPublisherApplication.class, args);}}
- index.html
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>首页</title></head><body><a href=" http://localhost:8070/realtime-total?date=2021-10-07">请求今天DAU</a> <br><a href=" http://localhost:8070/realtime-hours?id=dau&date=2021-10-07">请求今天和昨天分时DAU</a><br/></body></html>
四.运行程序
浏览器访问: http://localhost:8070/index.html

- 请求今天DAU

- 请求今天和昨天分时DAU

第二章.项目需求二:交易额统计
数据处理流程图

1.业务采集数据
交易额统计需要采集业务数据,业务数据一般存储在关系型数据库mysql中,此时可以使用Canal来实时采集业务数据到kafka
Canal的工作原理:将自己伪装成Slave(从数据库),假装从Master(主数据库)复制数据
一.MySql的准备
- 使用存储过程模拟数据
call `init_data`('2021-10-06',10,3,FALSE);call `init_data`('2021-10-07',10,3,FALSE);
- 开启Binlog
MYSQL需要让主机把写操作记录到日志中,故需要开启binlog
在安装mysql的主机(hadoop103)上编辑配置文件(/etc/my.cnf),在[mysqld]下面添加
log-bin=mysql-binserver-id=3binlog_format=rowbinlog-do-db=sparkproduct
修改完之后重启mysql
sudo systemctl restart mysqld
二.安装Canal
- 下载Canal
下载地址: https://github.com/alibaba/canal/releases
- 将压缩包上传到Linux上并解压
注意: 解压前自己要先创建一个目录来存放解压后的Canal数据
- 修改canal.properties(全局配置文件)
vim conf/canal.propertiescanal.ip = hadoop103
- 修改instance.properties (实例配置文件)
vim conf/example/instance.propertiescanal.instance.mysql.slaveId=0# position infocanal.instance.master.address=hadoop103:3306canal.instance.master.journal.name=mysql-bin.000001canal.instance.master.position=154
- 在mysql中执行以下语句(赋权限)
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal';FLUSH PRIVILEGES;
- 启动canal
[atguigu@hadoop103 canal]$ bin/startup.sh
2.创建子模块(gmall-canalclient)
该模块为canal客户端,订阅canalServer拉取到的数据
一.pom.xml
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>spark-gmall</artifactId><groupId>org.example</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>gmall-canalclient</artifactId><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><artifactId>gmall-common</artifactId><groupId>org.example</groupId><version>1.0-SNAPSHOT</version></dependency><!--canal client--><dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>1.1.2</version></dependency><!--kafka : 需要使用生产者写入kafka--><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></dependency></dependencies></project>
二.生产者(MyProducer.java)
package com.atguigu.client;import org.apache.kafka.clients.producer.KafkaProducer;import org.apache.kafka.clients.producer.Producer;import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;public class MyProducer {private static Producer producer;static{producer= getProducer();}//获取一个生产者public static Producer getProducer(){Properties properties = new Properties();//集群地址 key,value的序列化器properties.put("bootstrap.servers","hadoop102:9092,hadoop103:9092,hadoop104:9092");properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");return new KafkaProducer<String,String>(properties);}public static void sendData(String topic,String value){producer.send(new ProducerRecord(topic,value));}}
三.canal客户端(CanalClient.java)
package com.atguigu.client;import com.alibaba.fastjson.JSONObject;import com.alibaba.otter.canal.client.CanalConnector;import com.alibaba.otter.canal.client.CanalConnectors;import com.alibaba.otter.canal.protocol.CanalEntry;import com.alibaba.otter.canal.protocol.Message;import com.atguigu.constants.MyConstants;import com.google.protobuf.ByteString;import com.google.protobuf.InvalidProtocolBufferException;import java.net.InetSocketAddress;import java.util.List;//canalclient连接服务端public class CanalClient {public static void main(String[] args) throws InterruptedException, InvalidProtocolBufferException {//1.创建一个客户端对象CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("hadoop103", 11111), "example", null, null);//2.连接connector.connect();//3.发请求connector.subscribe("sparkproduct.order_info");//4.拉数据while(true){Message message = connector.get(100);//判断是否拉取到了数据if(message.getId() == -1){System.out.println("歇会再去");Thread.sleep(5000);continue;}//解析数据(message->拉取一次,多条SQL,造成的写操作变化)//List<CanalEntry.Entry> entrys:->保存的就是多条SQL引起的变化List<CanalEntry.Entry> entries = message.getEntries();for (CanalEntry.Entry entry : entries) {//Entry:一个SQL引起的变化//只要insert语句if(entry.getEntryType().equals(CanalEntry.EntryType.ROWDATA)){//ByteStrinng storeValue_存的是一条SQL引起的数据变化,,不能直接使用,必须反序列化ByteString storeValue = entry.getStoreValue();parseDate(storeValue);}}}//}private static void parseDate(ByteString storeValue) throws InvalidProtocolBufferException {//反序列化CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);//只要insertif (rowChange.getEventType().equals(CanalEntry.EventType.INSERT)){List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();//将每一行的所有数据封装为json字符串for (CanalEntry.RowData rowData : rowDatasList) {JSONObject jsonObject = new JSONObject();//获取insert之后的列的信息//Column:可以获取列之前的值以及之后的值,以及列名List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();for (CanalEntry.Column column : afterColumnsList) {jsonObject.put(column.getName(),column.getValue());}//System.out.println(jsonObject.toJSONString());//生产到kafkaMyProducer.sendData(MyConstants.GMALL_ORDER_INFO,jsonObject.toJSONString());}}}}
四.运行程序,去kafka客户端查看

3.编辑子模块(gmall-realtime)
实时处理从canal客户端发送到kafka的数据
一.pom.xml
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.30</version></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch-hadoop</artifactId><version>6.6.0</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.0.5</version></dependency>
二.配置文件(db.properties)
#Mysqljdbc.datasource.size=20jdbc.url=jdbc:mysql://hadoop103:3306/sparkproduct?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=truejdbc.user=rootjdbc.password=321074jdbc.driver.name=com.mysql.jdbc.Driver
三.工具类(JDBCUtil.java)
package com.atguigu.realtime.utilsimport java.sql.{Connection, PreparedStatement, ResultSet}import java.util.Propertiesimport com.alibaba.druid.pool.DruidDataSourceFactoryimport javax.sql.DataSourceobject JDBCUtil {private val properties: Properties = PropertiesUtil.load("db.properties")// 创建连接池对象var dataSource:DataSource = init()// 连接池的初始化def init():DataSource = {val paramMap = new java.util.HashMap[String, String]()paramMap.put("driverClassName", properties.getProperty("jdbc.driver.name"))paramMap.put("url", properties.getProperty("jdbc.url"))paramMap.put("username", properties.getProperty("jdbc.user"))paramMap.put("password", properties.getProperty("jdbc.password"))paramMap.put("maxActive", properties.getProperty("jdbc.datasource.size"))// 使用Druid连接池对象DruidDataSourceFactory.createDataSource(paramMap)}// 从连接池中获取连接对象def getConnection(): Connection = {dataSource.getConnection}def main(args: Array[String]): Unit = {println(getConnection())}}
四.GMV实现
- 创建两张表分别存储GMV和偏移量
CREATE TABLE `gmvstats` (`date` VARCHAR(10) NOT NULL,`hour` VARCHAR(10) NOT NULL,`gmv` DECIMAL(20,2) DEFAULT NULL,PRIMARY KEY (`date`,`hour`)) ENGINE=INNODB DEFAULT CHARSET=utf8;
CREATE TABLE `offsets` (`group_id` VARCHAR(200) NOT NULL,`topic` VARCHAR(200) NOT NULL,`partition` INT(5) NOT NULL,`offset` BIGINT(10) ,PRIMARY KEY (`group_id`,`topic`,`partition`)) ENGINE=INNODB DEFAULT CHARSET=utf8;
- 样例类
package com.atguigu.realtime.beanscase class OrderInfo(id: String,province_id: String,consignee: String,order_comment: String,var consignee_tel: String,order_status: String,payment_way: String,user_id: String,img_url: String,total_amount: Double,expire_time: String,delivery_address: String,create_time: String,operate_time: String,tracking_no: String,parent_order_id: String,out_trade_no: String,trade_body: String,// 方便分时和每日统计,额外添加的字段var create_date: String,var create_hour: String)
- 交易额统计程序(GMVApp)
package com.atguigu.realtime.appimport com.alibaba.fastjson.JSONimport com.atguigu.constants.MyConstantsimport com.atguigu.realtime.app.DAUApp.{appName, batchDuration, groupId, ssc}import com.atguigu.realtime.beans.OrderInfoimport com.atguigu.realtime.utils.{JDBCUtil, MyKafkaUtil}import org.apache.kafka.clients.consumer.ConsumerRecordimport org.apache.kafka.common.TopicPartitionimport org.apache.spark.SparkConfimport org.apache.spark.rdd.RDDimport org.apache.spark.streaming.kafka010.{HasOffsetRanges, OffsetRange}import org.apache.spark.streaming.{Seconds, StreamingContext}import java.sql.{Connection, PreparedStatement}import java.time.LocalDateTimeimport java.time.format.DateTimeFormatterimport scala.collection.mutable/***** 计算每天,所有订单的GMV数据。* 每天的总GMV* 每天每个时段的GMV** 结果: K(时间的说明)-V(GMV)** 聚合类的运算: 采取 at least once + 事务(聚合的结果 + 偏移量) 维护到mysql!***/object GMVApp extends BaseApp {override var appName: String = "GMVApp"override var batchDuration: Int = 10val groupId="gmallrealtime"/*** 查询上一次消费的offset* @param groupId* @param topicName* @return*/def selectLatestOffsetsFromDB(groupId: String, topicName: String) = {val offsets = mutable.Map[TopicPartition, Long]()var connection:Connection = nullvar ps:PreparedStatement = nulltry {connection = JDBCUtil.getConnection()val sql ="""|select * from `offsets` where `groupid` = ? and `topic` = ?|""".stripMarginps = connection.prepareStatement(sql)ps.setString(1,groupId)ps.setString(2,topicName)val resultSet = ps.executeQuery()while(resultSet.next()){val topicPartition = new TopicPartition(resultSet.getString("topic"), resultSet.getInt("partitionid"))val offset = resultSet.getLong("offset")offsets.put(topicPartition,offset)}} catch {case e:Exception =>{e.printStackTrace()throw new RuntimeException("查询偏移量失败")}} finally {if(ps != null){ps.close()}if (connection != null){connection.close()}}offsets.toMap}/*** 将Rdd封装为样例类* @param rdd* @return*/def parseRecordToOrderInfo(rdd: RDD[ConsumerRecord[String, String]]):RDD[OrderInfo] = {rdd.map(record=>{val orderInfo = JSON.parseObject(record.value(), classOf[OrderInfo])//"create_time": "2021-09-28 21:12:40",val formatter1 = DateTimeFormatter.ofPattern("yyyy-MM-dd")val formatter2 = DateTimeFormatter.ofPattern("HH")val formatter3 = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")// 先将 "2021-09-28 21:12:40" 转换为 LocalDateTime对象val localDateTime = LocalDateTime.parse(orderInfo.create_time, formatter3)orderInfo.create_date=localDateTime.format(formatter1)orderInfo.create_hour=localDateTime.format(formatter2)orderInfo})}/*** 在一个事务中,将结果和偏移量写出到mysql数据库中* @param results* @param offsetRanges*/def writeDataAndOffsetInCommonBatch(results: Array[((String, String), Double)], offsetRanges: Array[OffsetRange]): Unit = {var connection:Connection = nullvar ps1:PreparedStatement = nullvar ps2:PreparedStatement = nulltry {connection = JDBCUtil.getConnection()//关闭事务的自动提交connection.setAutoCommit(false)//先判断当前的是有状态计算,还是无状态计算//有状态计算val sql1 ="""|insert into gmvstats values(?,?,?)|on duplicate key update gmv = gmv + values(gmv)|""".stripMarginval sql2 ="""|insert into offsets values(?,?,?,?)|on duplicate key update offset = values(offset)|""".stripMarginps1 = connection.prepareStatement(sql1)ps2 = connection.prepareStatement(sql2)for (((date, hour), gmv)<- results) {ps1.setString(1,date)ps1.setString(2,hour)ps1.setDouble(3,gmv)//攒起来ps1.addBatch}//批量提交val dataResults = ps1.executeBatch()for (offsetRange <- offsetRanges) {ps2.setString(1,groupId)ps2.setString(2,offsetRange.topic)ps2.setInt(3,offsetRange.partition)ps2.setLong(4,offsetRange.untilOffset)//遍历一次,写一个分区的信息,一个offsetRange代表一个主题的一个分区ps2.addBatch()}val offsetResult = ps2.executeBatch()//提交事务connection.commit()println("写入数据" + dataResults.size)println("写入偏移量" + offsetResult.size)} catch {case e:Exception =>{connection.rollback()e.printStackTrace()throw new RuntimeException("写入结果和偏移量失败")}} finally {if(ps1 != null){ps1.close()}if(ps2 != null){ps2.close()}if (connection != null){connection.close()}}}def main(args: Array[String]): Unit = {ssc = new StreamingContext(new SparkConf().setMaster("local[4]").setAppName(appName),Seconds(batchDuration))runApp{//1.查询上次消费的offsets的位置val offsets = selectLatestOffsetsFromDB(groupId, MyConstants.GMALL_ORDER_INFO)//2,根据上次消费的位置,获取dsval ds = MyKafkaUtil.getKafkaStream(Array(MyConstants.GMALL_ORDER_INFO),ssc,groupId,true,offsets)//3.获取初始ds的偏移量信息ds.foreachRDD(rdd=>{if(!rdd.isEmpty()){val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges//4.封装为样例类val rdd1 = parseRecordToOrderInfo(rdd)//5.计算GMVval rdd2 = rdd1.map(orderInfo => ((orderInfo.create_date, orderInfo.create_hour), orderInfo.total_amount)).reduceByKey(_ + _)//6.将结果拉取到driver端和偏移量在一个事务中写入mysqlval result = rdd2.collect()writeDataAndOffsetInCommonBatch(result,offsetRanges)}})}}}
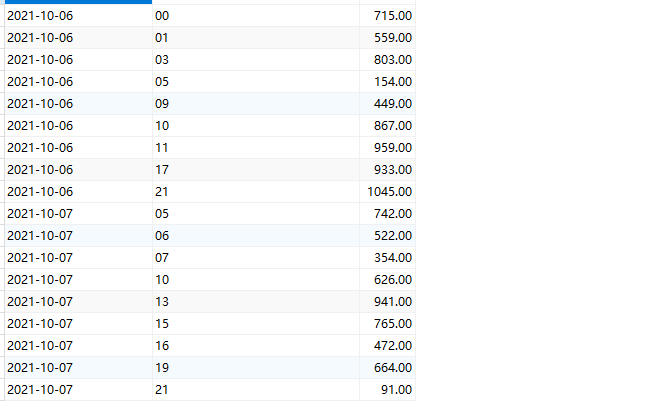
- 启动APP,并去mysql客户端查看

4.编辑子模块(gmall-publisher)
一.业务代码实现
- pojo层(GMVPerHour.java)
package com.example.gmallpublisher.pojo;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@NoArgsConstructor@AllArgsConstructor@Datapublic class GMVPerHour {private String item;private Integer gmv;}
- mapper层(GMVMapper)
package com.example.gmallpublisher.mapper;import com.baomidou.dynamic.datasource.annotation.DS;import com.example.gmallpublisher.pojo.GMVPerHour;import org.springframework.stereotype.Repository;import java.util.List;@Repository@DS("mysql")public interface GMVMapper {//查询当天累计的GMVDouble getGMVByDate(String date);//查询当天分时GMVList<GMVPerHour> getGMVPerHourDate(String date);}
- GMVMapper.xml
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><!--namespace=绑定一个对应的Dao/Mapper接口--><mapper namespace="com.example.gmallpublisher.mapper.GMVMapper"><!--查询当日累计的GMV--><select id="getGMVByDate" resultType="double">selectsum(gmv)from gmvstatswhere `date` = #{logdate}</select><!-- 查询分时GMV--><select id="getGMVPerHourDate" resultType="com.example.gmallpublisher.pojo.GMVPerHour">select`hour` item,sum(gmv) gmvfrom gmvstatswhere `date`= #{logdate}group by `hour`</select></mapper>
- service层(PublisherService,PublisherServiceImpl)
package com.example.gmallpublisher.service;import com.example.gmallpublisher.pojo.DAUPerHour;import com.example.gmallpublisher.pojo.GMVPerHour;import java.util.List;public interface PublisherService {//查询单日日活Integer getDAUByDate(String date);//查询当日新增的设备数Integer getNewMidCountByDate(String date);//查询当日分时的设备数List<DAUPerHour> getDAUPerHourData(String date);//查询当天累计的GMVDouble getGMVByDate(String date);//查询当天分时GMVList<GMVPerHour> getGMVPerHourDate(String date);}
package com.example.gmallpublisher.service;import com.example.gmallpublisher.mapper.DAUMapper;import com.example.gmallpublisher.mapper.GMVMapper;import com.example.gmallpublisher.pojo.DAUPerHour;import com.example.gmallpublisher.pojo.GMVPerHour;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import java.util.List;@Servicepublic class PublisherServiceImpl implements PublisherService {@Autowiredprivate DAUMapper dauMapper;@Autowiredprivate GMVMapper gmvMapper;@Overridepublic Integer getDAUByDate(String date) {System.out.println("遵循的业务步骤");return dauMapper.getDAUByDate(date);}@Overridepublic Integer getNewMidCountByDate(String date) {System.out.println("遵循的业务步骤");return dauMapper.getNewMidCountByDate(date);}@Overridepublic List<DAUPerHour> getDAUPerHourData(String date) {System.out.println("遵循业务步骤");return dauMapper.getDAUPerHourData(date);}@Overridepublic Double getGMVByDate(String date) {System.out.println("遵循业务步骤");return gmvMapper.getGMVByDate(date);}@Overridepublic List<GMVPerHour> getGMVPerHourDate(String date) {System.out.println("遵循业务步骤");return gmvMapper.getGMVPerHourDate(date);}}
- controller层
package com.example.gmallpublisher.controller;import com.alibaba.fastjson.JSONObject;import com.example.gmallpublisher.pojo.DAUPerHour;import com.example.gmallpublisher.pojo.GMVPerHour;import com.example.gmallpublisher.service.PublisherService;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;import java.time.LocalDate;import java.util.ArrayList;import java.util.List;@RestControllerpublic class PublisherController {@Autowiredprivate PublisherService publisherService;/*** [* {"id":"dau","name":"当日日活数","value":1200},* {"id":"new_mid","name":"新增设备数","value":233}* {"id":"order_amount","name":"当日交易额","value":1000.2 }* ]* @param date* @return*/@RequestMapping(value="/realtime-total")public Object handle1(String date){//获取当日日活Integer dauByDate = publisherService.getDAUByDate(date);//获取当日新增设备数Integer newMidCountByDate = publisherService.getNewMidCountByDate(date);//获取当天累计的交易额Double gmvByDate = publisherService.getGMVByDate(date);ArrayList<JSONObject> result = new ArrayList<>();JSONObject jsonObject1 = new JSONObject();JSONObject jsonObject2 = new JSONObject();JSONObject jsonObject3 = new JSONObject();jsonObject1.put("id","dau");jsonObject1.put("name","当日日活数");jsonObject1.put("value",dauByDate);jsonObject2.put("id","new_mid");jsonObject2.put("name","新增设备数");jsonObject2.put("value",newMidCountByDate);jsonObject3.put("id","order_amount");jsonObject3.put("name","当日交易额");jsonObject3.put("value",gmvByDate);result.add(jsonObject1);result.add(jsonObject2);result.add(jsonObject3);return result;}/**** {"yesterday":{"11":383,"12":123,"17":88,"19":200},"today":{"12":38,"13":1233,"17":123,"19":688 }}** @param date* @return*/@RequestMapping(value="realtime-hours")public Object handle2(String id,String date){JSONObject result = new JSONObject();//根据今天的日期计算昨天的日期String yestodayDate = LocalDate.parse(date).minusDays(1).toString();if("dau".equals(id)){List<DAUPerHour> todayData = publisherService.getDAUPerHourData(date);List<DAUPerHour> yestodayData = publisherService.getDAUPerHourData(yestodayDate);result.put("yesterday",parseDAUDate(yestodayData));result.put("today",parseDAUDate(todayData));}if ("order_amount".equals(id)){List<GMVPerHour> todayData = publisherService.getGMVPerHourDate(date);List<GMVPerHour> yestodayData = publisherService.getGMVPerHourDate(yestodayDate);result.put("yesterday",parseGMVData(yestodayData));result.put("today",parseGMVData(todayData));}return result;}private Object parseGMVData(List<GMVPerHour> data) {JSONObject result = new JSONObject();for (GMVPerHour gmvPerHour : data) {result.put(gmvPerHour.getItem(),gmvPerHour.getGmv());}return result;}public JSONObject parseDAUDate(List<DAUPerHour> data){JSONObject result = new JSONObject();for (DAUPerHour dauPerHour : data) {result.put(dauPerHour.getHour(),dauPerHour.getDau());}return result;}}
- 主程序
package com.example.gmallpublisher;import org.mybatis.spring.annotation.MapperScan;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication@MapperScan(basePackages = "com.example.gmallpublisher.mapper")public class GmallPublisherApplication {public static void main(String[] args) {SpringApplication.run(GmallPublisherApplication.class, args);}}
- index.html
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>首页</title></head><body><a href=" http://localhost:8070/realtime-total?date=2021-10-07">请求今天DAU和GMV</a> <br><a href=" http://localhost:8070/realtime-hours?id=dau&date=2021-10-07">请求今天和昨天分时DAU</a><br/><a href=" http://localhost:8070/realtime-hours?id=order_amount&date=2021-10-07">请求今天和昨天分时GMV</a></body></html>
二.运行程序
浏览器访问: http://localhost:8070/index.html

- 请求今天DAU和GMV

- 请求今天和昨天分时DAU

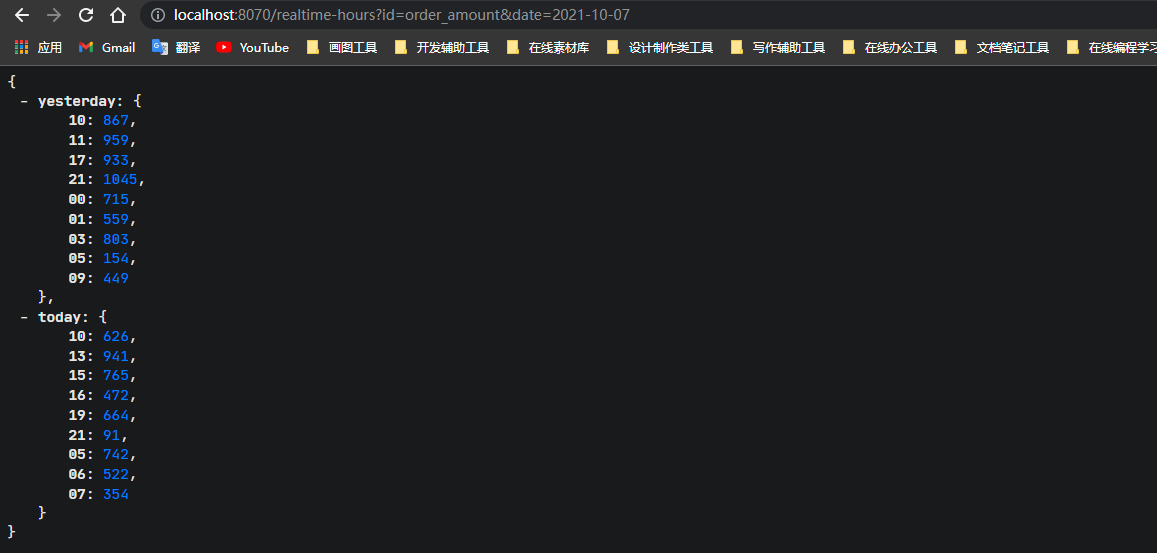
- 请求今天和昨天分时GMV

若有收获,就点个赞吧
0 人点赞
