第一章.项目需求三:购物券风险预警
1.需求分析
一.简介
实时预警,是一种经常出现在实时计算中的业务类型,根据日志数据中系统报错异常,或者用户行为异常的检测,产生对应预警日志,预警日志通过图形化界面的展示,可以提醒监控方,需要及时核查问题,并采取应对措施
二.需求说明
需求:同一设备,五分钟内使用2个及以上不同账号登录且都增加了收货地址,达到以上要求则产生一条预警日志,并且同一设备,每分钟只记录一次预警
三.数据处理流程图

2.编辑子模块(gmall-realtime)
一.pom.xml
<dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch-hadoop</artifactId><version>6.6.0</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.0.5</version></dependency>
二.样例类
package com.atguigu.realtime.beansimport scala.collection.mutableimport scala.collection.mutable.ListBuffer/*** Created by Smexy on 2021/9/30*/// 对应 actions[{action},... ]case class Action(action_id:String,item:String,item_type:String,ts:Long)// 对应common部分case class CommonInfo(ar:String,ba:String,ch:String,is_new:Int,md:String,mid:String,os:String,uid:Long,vc:String)// 对应Kafka中的一条数据case class ActionsLog(actions: List[Action],ts:Long,common:CommonInfo)//预警日志case class AlertInfo(id:String,// 这个设备过去5分组,登录过的用户uids:mutable.Set[String],// 这个设备过去5分组,登录过的用户 如果收藏了商品,请将收藏商品的id记录下来itemIds:mutable.Set[String],// 这个设备过去5分组,登录过的用户所产生的所有行为events:ListBuffer[String],// 预警日志的tsts:Long)
三.ES相关(创建index)
PUT _template/gmall_coupon_alert_template{"index_patterns": ["gmall_coupon_alert*"],"settings": {"number_of_shards": 3},"aliases" : {"{index}-query": {},"gmall_coupon_alert-query":{}},"mappings": {"_doc":{"properties":{"mid":{"type":"keyword"},"uids":{"type":"keyword"},"itemIds":{"type":"keyword"},"events":{"type":"keyword"},"ts":{"type":"date"}}}}}
四.Alert实现
package com.atguigu.realtime.appimport com.alibaba.fastjson.{JSON, JSONObject}import com.atguigu.constants.MyConstantsimport com.atguigu.realtime.beans.{Action, ActionsLog, AlertInfo, CommonInfo}import com.atguigu.realtime.utils.MyKafkaUtilimport org.apache.spark.SparkConfimport org.apache.spark.streaming.kafka010.{CanCommitOffsets, HasOffsetRanges, OffsetRange}import org.apache.spark.streaming.{Minutes, Seconds, StreamingContext}import java.time.{Instant, LocalDate, LocalDateTime, ZoneId}import java.time.format.DateTimeFormatterimport scala.collection.mutableimport scala.util.control.Breaks/*** at least once + ES(幂等输出,偏移量维护在kafka)*/object AlertApp extends BaseApp {override var appName: String = "AlertApp"override var batchDuration: Int = 10val groupId = "gmallrealtime"def main(args: Array[String]): Unit = {//将ES的配置写入confval conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName(appName)conf.set("es.index.auto.create", "true")conf.set("es.nodes", "hadoop102")conf.set("es.port", "9200")ssc = new StreamingContext(conf,Seconds(batchDuration))runApp{//1.获取初始DSval ds = MyKafkaUtil.getKafkaStream(Array(MyConstants.ACTIONS_LOG), ssc, groupId)var offsetRanges:Array[OffsetRange] = null//2.获取偏移量信息val ds1 = ds.transform(rdd => {offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges//3.封装样例类rdd.map(record => {//获取actionsval jSONObject:JSONObject = JSON.parseObject(record.value())/*** 导入静态方法,封装了scala集合和java集合的转换方法* scala集合转java集合 scala集合.asJava* java集合转scala集合 java集合.asScala*/import collection.JavaConverters._//将util.list转为scala的listval actions: List[Action] = JSON.parseArray(jSONObject.getString("actions"), classOf[Action]).asScala.toList//获取commonval common = JSON.parseObject(jSONObject.getString("common"), classOf[CommonInfo])ActionsLog(actions, jSONObject.getLong("ts"), common)})})//4.开窗5分钟,按照(mid,uid)分组val ds2 = ds1.window(Minutes(5)).map(log => {((log.common.mid, log.common.uid), log)}).groupByKey()//5.根据需求,计算每个用户是否进行收货地址修改val ds3 = ds2.map {case ((mid, uid), actionLogs) => {//假设不需要预警var ifNeedAlert: Boolean = false//判断是否有需要预警的嫌疑Breaks.breakable {actionLogs.foreach(actionLogs => {actionLogs.actions.foreach(action => {if (action.action_id == "trade_add_address") {ifNeedAlert = true//不需要往下遍历,跳出循环Breaks.break}})})}//如果需要预警,返回这个人此期间产生的Logsif(ifNeedAlert){(mid,actionLogs)}else{(null,null)}}}//6.过滤(null,null)val ds4 = ds3.filter(_._1 != null)//7.继续将同一个设备,有嫌疑的用户及日志,分到同一组val ds5 = ds4.groupByKey()//8.过去5分钟,修改收货地址用户超过2个及以上的设备才需要预警val ds6 = ds5.filter(_._2.size >= 2)//9.压平val ds7 = ds6.mapValues(_.flatten)//10.生成预警信息val ds8 = ds7.map {case (mid, actionsLogs) => {var uids = mutable.Set[String]()var itemIds = mutable.Set[String]()var events = mutable.ListBuffer[String]()actionsLogs.foreach(actionsLog => {uids.add(actionsLog.common.uid.toString)actionsLog.actions.foreach(action => {if (action.action_id == "favor_add") {itemIds.add(action.item)}events.append(action.action_id)})})// id = mid_yyyy-MM-dd HH:mmval formatter1: DateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm")val ts: Long = System.currentTimeMillis()val time: LocalDateTime = LocalDateTime.ofInstant(Instant.ofEpochMilli(ts), ZoneId.of("Asia/Shanghai"))var id = mid + "_" + time.format(formatter1)AlertInfo(id, uids, itemIds, events, ts)}}ds8.cache()ds8.print(100)//为了使用ESRdd的静态方法import org.elasticsearch.spark._//11.写到ESds8.foreachRDD(rdd=>{rdd.saveToEs("/gmall_coupon_alert"+ LocalDate.now()+"/_doc" ,Map("es.mapping.id" -> "id") )//提交偏移量ds.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)})}}}
五.启动APP

ES客户端查看

3.Kibana发布可视化界面
一.创建索引样式


二.做树状图




三.做饼图

四.看板展示

第二章.项目需求四:灵活分析
1.需求分析
一.灵活查询的场景
数仓中存储了大量的明细数据,但是Hadoop存储的数仓计算必须经过MR,所以即时交互性非常糟糕,为了方便数据分析人员查看信息,数据平台需要提供一个能够根据文字及选项等条件,进行灵活分析判断的数据功能

二.需求详细
输入参数
| 日期 | 查询数据的日期 |
|---|---|
| 关键字 | 根据商品名称涉及到的词进行搜索 |
返回结果
| 男女比例占比 | 男,女 |
|---|---|
| 年龄比例占比 | 20岁以下,20-30岁,30岁以上 |
| 购买行为数据明细 | 包括用户id,性别,年龄,级别,购买的时间,商品价格,订单状态等信息,可翻页 |
三.数据处理流程图

2.编辑子模块(gmall-canalclient)
编写canal客户端采集明细数据到kafka
package com.atguigu.client;import com.alibaba.fastjson.JSONObject;import com.alibaba.otter.canal.client.CanalConnector;import com.alibaba.otter.canal.client.CanalConnectors;import com.alibaba.otter.canal.protocol.CanalEntry;import com.alibaba.otter.canal.protocol.Message;import com.atguigu.constants.MyConstants;import com.google.protobuf.ByteString;import com.google.protobuf.InvalidProtocolBufferException;import java.net.InetSocketAddress;import java.util.List;//canalclient连接服务端public class CanalClient2 {public static void main(String[] args) throws InterruptedException, InvalidProtocolBufferException {//1.创建一个客户端对象CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("hadoop103", 11111), "example", null, null);//2.连接connector.connect();//3.发请求connector.subscribe("sparkproduct.*");//4.拉数据while(true){Message message = connector.get(100);//判断是否拉取到了数据if(message.getId() == -1){System.out.println("歇会再去");Thread.sleep(5000);continue;}//解析数据(message->拉取一次,多条SQL,造成的写操作变化)//List<CanalEntry.Entry> entrys:->保存的就是多条SQL引起的变化List<CanalEntry.Entry> entries = message.getEntries();for (CanalEntry.Entry entry : entries) {//Entry:一个SQL引起的变化//只要insert语句if(entry.getEntryType().equals(CanalEntry.EntryType.ROWDATA)){//ByteStrinng storeValue_存的是一条SQL引起的数据变化,,不能直接使用,必须反序列化String tableName = entry.getHeader().getTableName();ByteString storeValue = entry.getStoreValue();parseDate(tableName,storeValue);}}}//}private static void parseDate(String tableName,ByteString storeValue) throws InvalidProtocolBufferException {//反序列化CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);CanalEntry.EventType eventType = rowChange.getEventType();//只要insertif (tableName.equals("order_info") && eventType.equals(CanalEntry.EventType.INSERT) ){sendDataToKafka(rowChange,MyConstants.GMALL_ORDER_INFO);}else if(tableName.equals("order_detail") && eventType.equals(CanalEntry.EventType.INSERT)){sendDataToKafka(rowChange,MyConstants.GMALL_ORDER_DETAIL);}else if(tableName.equals("user_info") && (eventType.equals(CanalEntry.EventType.INSERT) || eventType.equals(CanalEntry.EventType.UPDATE))){sendDataToKafka(rowChange,MyConstants.GMALL_USER_INFO);}}public static void sendDataToKafka(CanalEntry.RowChange rowChange,String topicName){List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();//将每一行数据的所有列封装为json字符串for (CanalEntry.RowData rowData : rowDatasList) {JSONObject jsonObject = new JSONObject();//获取insert后的列的信息List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();for (CanalEntry.Column column : afterColumnsList) {jsonObject.put(column.getName(),column.getValue());}System.out.println(jsonObject.toJSONString());//生产到kafkaMyProducer.sendData(topicName,jsonObject.toJSONString());}}}
3.编辑子模块(gmall-realtime)
一.数据处理流程

二.样例类
package com.atguigu.realtime.beanscase class OrderDetail(id:String,order_id: String,sku_name: String,sku_id: String,order_price: String,img_url: String,sku_num: String)case class UserInfo(id:String,login_name:String,user_level:String,birthday:String,gender:String)import java.text.SimpleDateFormatimport java.utilcase class SaleDetail(var order_detail_id:String =null,var order_id: String=null,var order_status:String=null,var create_time:String=null,var user_id: String=null,var sku_id: String=null,var user_gender: String=null,var user_age: Int=0,var user_level: String=null,var sku_price: Double=0D,var sku_name: String=null,var dt:String=null) {def this(orderInfo:OrderInfo,orderDetail: OrderDetail) {thismergeOrderInfo(orderInfo)mergeOrderDetail(orderDetail)}def mergeOrderInfo(orderInfo:OrderInfo): Unit ={if(orderInfo!=null){this.order_id=orderInfo.idthis.order_status=orderInfo.order_statusthis.create_time=orderInfo.create_timethis.dt=orderInfo.create_datethis.user_id=orderInfo.user_id}}def mergeOrderDetail(orderDetail: OrderDetail): Unit ={if(orderDetail!=null){this.order_detail_id=orderDetail.idthis.sku_id=orderDetail.sku_idthis.sku_name=orderDetail.sku_namethis.sku_price=orderDetail.order_price.toDouble}}def mergeUserInfo(userInfo: UserInfo): Unit ={if(userInfo!=null){this.user_id=userInfo.idval formattor = new SimpleDateFormat("yyyy-MM-dd")val date: util.Date = formattor.parse(userInfo.birthday)val curTs: Long = System.currentTimeMillis()val betweenMs= curTs-date.getTimeval age=betweenMs/1000L/60L/60L/24L/365Lthis.user_age=age.toIntthis.user_gender=userInfo.genderthis.user_level=userInfo.user_level}}}
三.采集user_Info进入缓存(redis)
- 使用order_Info.userid和userinfo.id
- 当前这笔订单的userid是当前新注册的用户,还是之前注册的用户?都有可能!需要join user_info的全量用户
- 全量的user_info存储在哪里
- mysql中user_info性能不太好
- 将mysql中的全量user_info存入到redis中
- 目的:在redis中有全量的用户信息
- 写一个程序,批量将mysql的user_info表的数据读入,写出到redis!
- 如果可以获取全量用户的binlog日志,也可以使用canal,读取全量的binlog日志,将数据生产到kafka,再写入到redis(采用)
package com.atguigu.realtime.appimport com.alibaba.fastjson.JSONimport com.atguigu.constants.MyConstantsimport com.atguigu.realtime.utils.{MyKafkaUtil, RedisUtil}import org.apache.spark.SparkConfimport org.apache.spark.streaming.kafka010.{CanCommitOffsets, HasOffsetRanges}import org.apache.spark.streaming.{Seconds, StreamingContext}object UserApp extends BaseApp {override var appName: String = "UserApp"override var batchDuration: Int = 10val groupId = "gmallrealtime"def main(args: Array[String]): Unit = {ssc = new StreamingContext(new SparkConf().setMaster("local[*]").setAppName(appName),Seconds(batchDuration))runApp{//获取初始DSval ds = MyKafkaUtil.getKafkaStream(Array(MyConstants.GMALL_USER_INFO), ssc, groupId)ds.foreachRDD(rdd=>{if(!rdd.isEmpty()){//获取偏移量val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRangesrdd.foreachPartition(partition => {val jedis = RedisUtil.getJedisClient()partition.foreach(record => {val jSONObject = JSON.parseObject(record.value())jedis.set("userInfo:"+jSONObject.getString("id"),record.value())})jedis.close()})ds.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)}})}}}

四.ES索引建立
PUT _template/gmall2021_sale_detail_template{"index_patterns": ["gmall2021_sale_detail*"],"settings": {"number_of_shards": 3},"aliases" : {"{index}-query": {},"gmall2021_sale_detail-query":{}},"mappings" : {"_doc" : {"properties" : {"order_detail_id" : {"type" : "keyword"},"order_id" : {"type" : "keyword"},"create_time" : {"type" : "date" ,"format" : "yyyy-MM-dd HH:mm:ss"},"dt" : {"type" : "date"},"order_status" : {"type" : "keyword"},"sku_id" : {"type" : "keyword"},"sku_name" : {"type" : "text","analyzer": "ik_max_word"},"sku_price" : {"type" : "float"},"user_age" : {"type" : "long"},"user_gender" : {"type" : "keyword"},"user_id" : {"type" : "keyword"},"user_level" : {"type" : "keyword","index" : false}}}}}
五.双流join

package com.atguigu.realtime.appimport com.alibaba.fastjson.JSONimport com.atguigu.constants.MyConstantsimport com.atguigu.realtime.beans.{OrderDetail, OrderInfo, SaleDetail, UserInfo}import com.atguigu.realtime.utils.{MyKafkaUtil, RedisUtil}import com.google.gson.Gsonimport org.apache.kafka.clients.consumer.ConsumerRecordimport org.apache.spark.SparkConfimport org.apache.spark.rdd.RDDimport org.apache.spark.streaming.kafka010.{CanCommitOffsets, HasOffsetRanges, OffsetRange}import org.apache.spark.streaming.{Seconds, StreamingContext}import java.time.{LocalDate, LocalDateTime}import java.time.format.DateTimeFormatterimport scala.collection.mutable/*** SparkStreaming中双流join的注意事项* 1.两个流必须从一个StreamingContext中获取* 2.只有DStream[K-V],才能调用join算子* 3.join的原理是根据key进行join* 4.在join时,只有要当join的数据,位于同一批次,被处理时才能join上* 5.如果由于网络延迟,导致两个流要join的数据,位于不同的批次被消费,此时无法join*/object SaleDetailApp extends BaseApp {override var appName: String = "SaleDetailApp"override var batchDuration: Int = 10val groupId = "gmallrealtime"def main(args: Array[String]): Unit = {//将es的配置写入sparkconfval conf: SparkConf = new SparkConf().setMaster("local[4]").setAppName(appName)conf.set("es.index.auto.create", "true")conf.set("es.nodes", "hadoop102")conf.set("es.port", "9200")ssc = new StreamingContext(conf, Seconds(batchDuration))runApp{//获取初始DSval ds1 = MyKafkaUtil.getKafkaStream(Array(MyConstants.GMALL_ORDER_DETAIL), ssc, groupId)val ds2 = MyKafkaUtil.getKafkaStream(Array(MyConstants.GMALL_ORDER_INFO), ssc, groupId)//获取当前批次的偏移量,将初始DS,转换为DS[K-V]var orderInfoOffsetRanges:Array[OffsetRange] = nullvar orderDetailOffsetRanges:Array[OffsetRange] = nullval ds3 = ds1.transform(rdd => {orderDetailOffsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRangesrdd.map(record => {val orderDetail = JSON.parseObject(record.value(), classOf[OrderDetail])(orderDetail.order_id, orderDetail)})})val ds4 = ds2.transform(rdd => {orderInfoOffsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRangesparseRecordToOrderInfo(rdd)})val ds5 = ds4.fullOuterJoin(ds3)//使用缓存处理join后的数据,同一批次能join的就join,不能join的就写入缓存,等待后续批次//缓存使用的是redis,存在读写redis,以分区为单位获取连接val ds6 = ds5.mapPartitions(partition => {val jedis = RedisUtil.getJedisClient()val gson = new Gson()//准备一个集合,存放可以上的明细数据val results = mutable.ListBuffer[SaleDetail]()partition.foreach {case (orderId, (orderInfoOption, orderDetailOption)) => {if (orderInfoOption != None) {val oi = orderInfoOption.getif (orderDetailOption != None) {val od = orderDetailOption.get//关联当前批次可以join上的数据val saleDetail = new SaleDetail(oi, od)results.append(saleDetail)}//写入redisjedis.setex("orderInfo:" + orderId, 5 * 2 * 60, gson.toJson(oi))//从Redis中找,有没有之前批次早到的orderDetail,有就关联val set = jedis.smembers("orderDetail:" + orderId)//如果可以不存在,不会报空指针异常,此时set是一个[],并不是nullset.forEach(orderDetailStr => {val orderDetail = JSON.parseObject(orderDetailStr, classOf[OrderDetail])val saleDetail = new SaleDetail(oi, orderDetail)results.append(saleDetail)})} else {val od = orderDetailOption.get//到缓存中找有没有早到的orderInfo,有就关联val str = jedis.get("orderInfo:" + orderId)if (str != null) {val info = JSON.parseObject(str, classOf[OrderInfo])val saleDetail = new SaleDetail(info, od)results.append(saleDetail)} else {//到缓存中没有找到早到的orderInfo,说明orderDetail早到了,写入缓存jedis.sadd("orderDetail:" + orderId, gson.toJson(od))//设置过期时间jedis.expire("orderDetail:" + orderId, 5 * 2 * 60)}}}}jedis.close()results.iterator})//ds6是已经将orderInfo和orderDetail join后的DS,需要从redis中根据ds6的userId获取用户的其他信息val ds7 = ds6.mapPartitions(partition => {val jedis = RedisUtil.getJedisClient()val it = partition.map(saleDetail => {val userInfoStr = jedis.get("userInfo:" + saleDetail.user_id)val userInfo = JSON.parseObject(userInfoStr, classOf[UserInfo])saleDetail.mergeUserInfo(userInfo)saleDetail})jedis.close()it})ds7.cache()println("即将写入:" + ds7.count().print())ds7.print(1000)import org.elasticsearch.spark._//写入ESds7.foreachRDD(rdd => {// resource: 目的地 cfg: 配置rdd.saveToEs("/gmall2021_sale_detail"+ LocalDate.now()+"/_doc" ,Map("es.mapping.id" -> "order_detail_id") )// 提交偏移量ds1.asInstanceOf[CanCommitOffsets].commitAsync(orderDetailOffsetRanges)ds2.asInstanceOf[CanCommitOffsets].commitAsync(orderInfoOffsetRanges)})}}def parseRecordToOrderInfo(rdd: RDD[ConsumerRecord[String, String]]):RDD[(String,OrderInfo)] = {rdd.map(record=>{val orderInfo = JSON.parseObject(record.value(), classOf[OrderInfo])//"create_time": "2021-09-28 21:12:40",val formatter1 = DateTimeFormatter.ofPattern("yyyy-MM-dd")val formatter2 = DateTimeFormatter.ofPattern("HH")val formatter3 = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")// 先将 "2021-09-28 21:12:40" 转换为 LocalDateTime对象val localDateTime = LocalDateTime.parse(orderInfo.create_time, formatter3)orderInfo.create_date=localDateTime.format(formatter1)orderInfo.create_hour=localDateTime.format(formatter2)(orderInfo.id,orderInfo)})}}
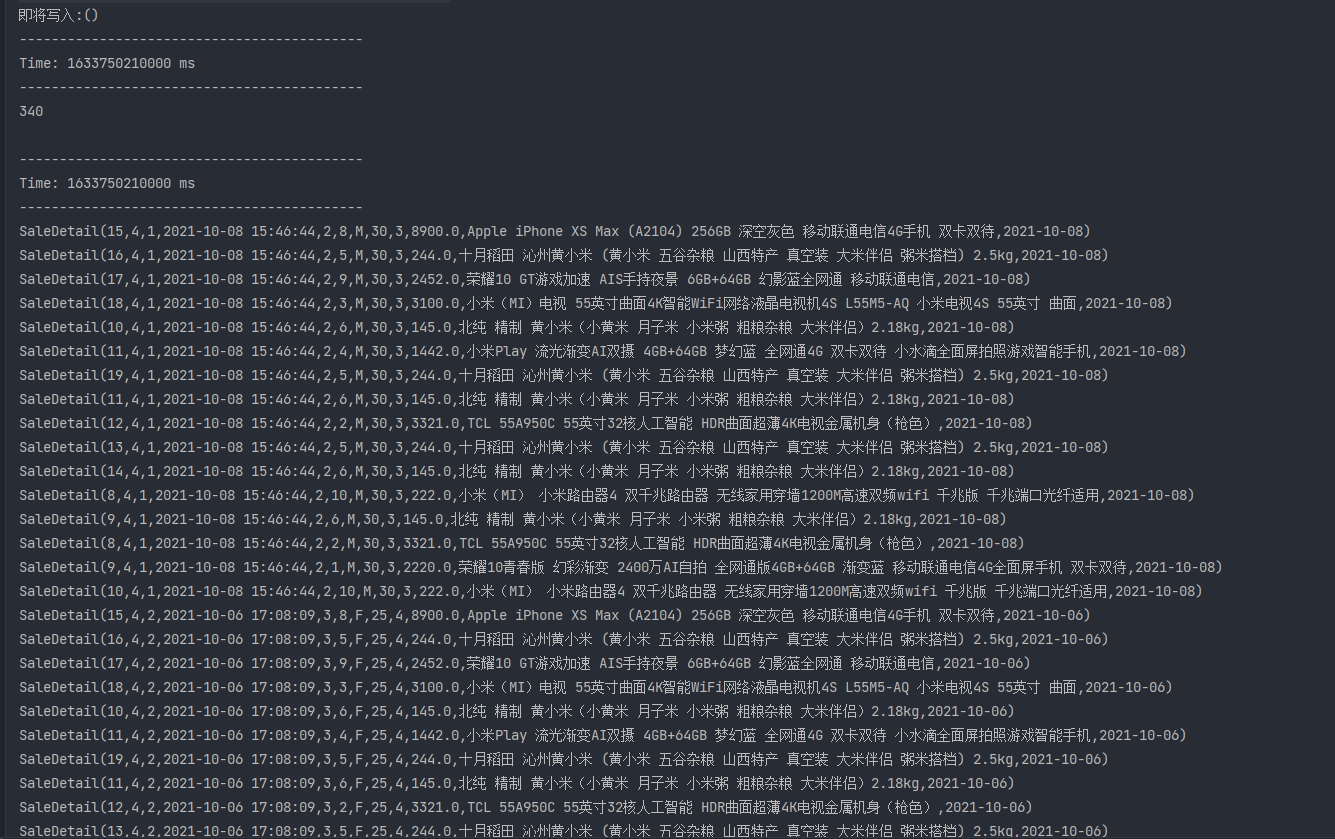

4.编辑子模块(gmall-publisher)
输入路径及参数
http://localhost:8070/sale_detail?date=2021-08-21&startpage=1&size=5&keyword=小米手机
一.pom.xml
<!--- ES依赖包-->
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
</dependency>
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.5.2</version>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
<version>2.7.8</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
二.配置 application.properties
#es
spring.elasticsearch.jest.uris=http://hadoop102:9200
三.业务代码实现
- pojo层
option.java(一个统计选项)
package com.example.gmallpublisher.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
@Data
@AllArgsConstructor
public class Option {
String name;
Double value;
}
SaleDetail.java(销售统计详情)
package com.example.gmallpublisher.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* Created by Smexy on 2021/10/8
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class SaleDetail {
private String order_detail_id;
private String order_id;
private String order_status;
private String create_time;
private String user_id;
private String sku_id;
private String user_gender;
private Integer user_age;
private String user_level;
private Double sku_price;
private String sku_name;
private String dt;
private String es_metadata_id;
}
Stat.java(一组统计选项)
import lombok.AllArgsConstructor;
import lombok.Data;
import java.util.List;
@Data
@AllArgsConstructor
public class Stat {
String title;
List<Option> options;
}
- dao层
单独创建dao层的原因
- 为了和Mybatis的mapper进行区分
- 因为在主程序上标注了@MapperScan,如果将ESDao也放入mapper包下,此时spring也会为ESDao提供代理对象,在创建对象时会报错,在创建对象时,会根据ESDao中的方法名,去匹配SQL,并没有SQL,报错
ESDao.java
package com.example.gmallpublisher.dao;
import com.alibaba.fastjson.JSONObject;
import java.io.IOException;
/**
* http://localhost:8070/sale_detail?date=2021-08-21&startpage=1&size=5&keyword=小米手机
*/
public interface ESDao {
JSONObject getData(String data,Integer startpage,Integer size,String keyword) throws IOException;
}
ESDaoImpl.java
package com.example.gmallpublisher.dao;
import com.alibaba.fastjson.JSONObject;
import com.example.gmallpublisher.pojo.Option;
import com.example.gmallpublisher.pojo.SaleDetail;
import com.example.gmallpublisher.pojo.Stat;
import com.ibm.icu.text.DecimalFormat;
import io.searchbox.client.JestClient;
import io.searchbox.core.Search;
import io.searchbox.core.SearchResult;
import io.searchbox.core.search.aggregation.MetricAggregation;
import io.searchbox.core.search.aggregation.TermsAggregation;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.terms.TermsBuilder;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* http://localhost:8070/sale_detail?date=2021-08-21&startpage=1&size=5&keyword=小米手机
* date:查询date这一天的购物明细
* 作用,生成要查询的indexName:gmall2021_sale_detail2021-10-09
* size:要查询多少条数据
* startpage:查询哪一页的数据
* keyword:检索的关键字
*
*/
@Repository
public class ESDaoImpl implements ESDao{
@Autowired
private JestClient jestClient;
public SearchResult getResult(String date,Integer startpage,Integer size,String keyword) throws IOException {
int from =(startpage - 1) * size;
String indexName = "gmall2021_sale_detail" + date;
//构造match{}
MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("sku_name", keyword);
//构造aggs:{}
TermsBuilder termsBuilder1 = AggregationBuilders.terms("gender_count").field("user_gender").size(2);
TermsBuilder termsBuilder2 = AggregationBuilders.terms("age_count").field("user_age").size(150);
//构造外层{}
String queryString = new SearchSourceBuilder().query(matchQueryBuilder).aggregation(termsBuilder1).aggregation(termsBuilder2)
.from(from).size(size).toString();
Search search = new Search.Builder(queryString).addIndex(indexName).addType("_doc").build();
SearchResult searchResult = jestClient.execute(search);
return searchResult;
}
//detail:[{SaleDetail},{}]
public ArrayList<SaleDetail> getDetail(SearchResult result){
ArrayList<SaleDetail> results = new ArrayList<>();
List<SearchResult.Hit<SaleDetail, Void>> hits = result.getHits(SaleDetail.class);
for (SearchResult.Hit<SaleDetail, Void> hit : hits) {
SaleDetail source = hit.source;
source.setEs_metadata_id(hit.id);
results.add(source);
}
return results;
}
public Stat getAgeStat(SearchResult result){
MetricAggregation aggregations = result.getAggregations();
TermsAggregation age_count = aggregations.getTermsAggregation("age_count");
List<TermsAggregation.Entry> buckets = age_count.getBuckets();
int ageFrom20To30 = 0;
int agelt20 = 0;
int agegt30 = 0;
for (TermsAggregation.Entry bucket : buckets) {
if (Integer.parseInt(bucket.getKey())<20){
agelt20 += bucket.getCount();
}else if(Integer.parseInt(bucket.getKey()) >=30){
agegt30 += bucket.getCount();
}else{
ageFrom20To30 += bucket.getCount();
}
}
double sumCount = ageFrom20To30 + agelt20 + agegt30;
DecimalFormat decimalFormat = new DecimalFormat("###.##");
ArrayList<Option> options = new ArrayList<Option>();
options.add(new Option("20岁到30岁",Double.parseDouble(decimalFormat.format(ageFrom20To30 / sumCount * 100))));
options.add(new Option("30岁及30岁以上",Double.parseDouble(decimalFormat.format(agegt30 / sumCount * 100))));
options.add(new Option("20岁以下",Double.parseDouble(decimalFormat.format(agelt20 / sumCount * 100))));
return new Stat("用户年龄占比",options);
}
public Stat getGenderStat(SearchResult result){
MetricAggregation aggregations = result.getAggregations();
TermsAggregation age_count = aggregations.getTermsAggregation("gender_count");
List<TermsAggregation.Entry> buckets = age_count.getBuckets();
int maleCount = 0;
int femaleCount = 0;
for (TermsAggregation.Entry bucket : buckets) {
if (bucket.getKey().equals("M")){
maleCount += bucket.getCount();
}else{
femaleCount+= bucket.getCount();
}
}
double sumCount = maleCount + femaleCount ;
DecimalFormat decimalFormat = new DecimalFormat("###.##");
ArrayList<Option> options = new ArrayList<>();
options.add(new Option("男",Double.parseDouble(decimalFormat.format(maleCount / sumCount * 100))));
options.add(new Option("女",Double.parseDouble(decimalFormat.format(femaleCount / sumCount * 100))));
return new Stat("用户性别占比",options);
}
@Override
public JSONObject getData(String date, Integer startpage, Integer size, String keyword) throws IOException {
SearchResult searchResult = getResult(date, startpage, size, keyword);
JSONObject jsonObject = new JSONObject();
ArrayList<Stat> stats = new ArrayList<>();
stats.add(getAgeStat(searchResult));
stats.add(getGenderStat(searchResult));
jsonObject.put("total",searchResult.getTotal());
jsonObject.put("stats",stats);
jsonObject.put("detail",getDetail(searchResult));
return jsonObject;
}
}
- service层
PublisherService.java
package com.example.gmallpublisher.service;
import com.alibaba.fastjson.JSONObject;
import com.example.gmallpublisher.pojo.DAUPerHour;
import com.example.gmallpublisher.pojo.GMVPerHour;
import java.io.IOException;
import java.util.List;
public interface PublisherService {
//查询单日日活
Integer getDAUByDate(String date);
//查询当日新增的设备数
Integer getNewMidCountByDate(String date);
//查询当日分时的设备数
List<DAUPerHour> getDAUPerHourData(String date);
//查询当天累计的GMV
Double getGMVByDate(String date);
//查询当天分时GMV
List<GMVPerHour> getGMVPerHourDate(String date);
//灵活分析查询
JSONObject getData(String date, Integer startpage, Integer size, String keyword) throws IOException;
}
PublisherServiceImpl.java
package com.example.gmallpublisher.service;
import com.alibaba.fastjson.JSONObject;
import com.example.gmallpublisher.dao.ESDao;
import com.example.gmallpublisher.mapper.DAUMapper;
import com.example.gmallpublisher.mapper.GMVMapper;
import com.example.gmallpublisher.pojo.DAUPerHour;
import com.example.gmallpublisher.pojo.GMVPerHour;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.List;
@Service
public class PublisherServiceImpl implements PublisherService {
@Autowired
private DAUMapper dauMapper;
@Autowired
private GMVMapper gmvMapper;
@Autowired
private ESDao esDao;
@Override
public Integer getDAUByDate(String date) {
System.out.println("遵循的业务步骤");
return dauMapper.getDAUByDate(date);
}
@Override
public Integer getNewMidCountByDate(String date) {
System.out.println("遵循的业务步骤");
return dauMapper.getNewMidCountByDate(date);
}
@Override
public List<DAUPerHour> getDAUPerHourData(String date) {
System.out.println("遵循业务步骤");
return dauMapper.getDAUPerHourData(date);
}
@Override
public Double getGMVByDate(String date) {
System.out.println("遵循业务步骤");
return gmvMapper.getGMVByDate(date);
}
@Override
public List<GMVPerHour> getGMVPerHourDate(String date) {
System.out.println("遵循业务步骤");
return gmvMapper.getGMVPerHourDate(date);
}
@Override
public JSONObject getData(String date, Integer startpage, Integer size, String keyword) throws IOException {
return esDao.getData(date,startpage,size,keyword);
}
}
- controller层
@Autowired
private PublisherService publisherService;
@RequestMapping(value="/sale_detail")
public Object handle3(String date,Integer startpage,Integer size,String keyword) throws IOException {
return publisherService.getData(date,startpage,size,keyword);
}
- index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>首页</title>
</head>
<body>
<a href=" http://localhost:8070/realtime-total?date=2021-10-07">请求今天DAU和GMV</a> <br>
<a href=" http://localhost:8070/realtime-hours?id=dau&date=2021-10-07">请求今天和昨天分时DAU</a>
<br/>
<a href=" http://localhost:8070/realtime-hours?id=order_amount&date=2021-10-07">请求今天和昨天分时GMV</a>
<a href=" http://localhost:8070/sale_detail?date=2021-10-09&startpage=2&size=10&keyword=小米手机">请求10-09日购物明细</a>
</body>
</html>
四.运行程序


若有收获,就点个赞吧
0 人点赞
