1、排序
1、order_by:
小例子:根据年龄进行升序排序
from sqlalchemy import create_enginefrom sqlalchemy import Column, String, Integerfrom sqlalchemy.orm import sessionmakerfrom sqlalchemy.ext.declarative import declarative_base# 定义引擎USERNAME = "root"PASSWORD = "147258"PORT = 3306HOSTNAME = "127.0.0.1"DATABASE = "wuyanxin"SLDG = f"mysql+mysqlconnector://{USERNAME}:{PASSWORD}@{HOSTNAME}:{PORT}/{DATABASE}?charset=utf8"engine = create_engine(SLDG)Base = declarative_base(engine)class Students(Base):__tablename__ = "students"id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(10), nullable=False)age = Column(Integer)def __str__(self):return f"姓名:{self.name}, 年龄:{self.age}"# Base.metadata.drop_all()Base.metadata.create_all()session = sessionmaker(bind=engine)()dates = session.query(Students).order_by(Students.age).all()for date in dates:print(date)session.commit()
结果显示: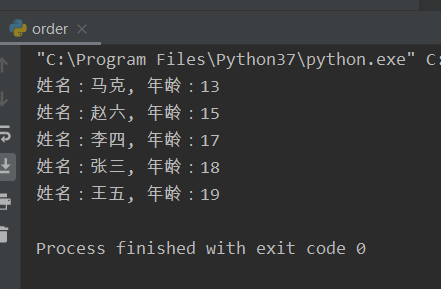
在默认情况下:order_by是进行升序排序的
进行降序的方法:
方法一:desc()
dates = session.query(Students).order_by(Students.age.desc()).all()for date in dates:print(date)
方法二:加负号
dates = session.query(Students).order_by(-Students.age).all()for date in dates:print(date)
2、mapper_args方法(推荐)
在模型中进行定义:
class Students(Base):__tablename__ = "students"id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(10), nullable=False)age = Column(Integer)# 按照age进行降序排序__mapper_args__ ={# 升序排序# "order_by": age"order_by": age.desc()}def __str__(self):return f"姓名:{self.name}, 年龄:{self.age}"# 之后只要进行正常查询即可,不需要order_by了
2、offset()、limit()以及切片(翻页功能就是这样实现的)
offset()表示从第几条数据开始查询,limit()表示查询几条数据
小例子:limit()查询前五条数据
dates = session.query(Students).limit(5).all()for date in dates:print(date)
小例子:offset()配合limit()查询3-5条数据:offset()的偏离量是从0开始的
dates = session.query(Students).offset(2).limit(3).all()for date in dates:print(date)
注意点:
如果使用order_by()进行排序,需要注意的是order_by()的顺序是要在切片之前,如果顺序写错,则报错
dates = session.query(Students).order_by(Students.age).offset(2).limit(3).all()
加入filter也是可以的
dates = session.query(Students).filter(Students.gender == "男").order_by(-Students.age).offset(0).limit(2).all()for date in dates:print(date)
切片:
这里的切片就是将数据取出后进行截取出来(因为获取到的dates数据是列表)
所以满足列表切片的特征:左闭右开,从零开始
完成查询3-5条数据的切片写法:
dates = session.query(Students).all()[2:5]for date in dates:print(date)
总结:
切片写法相对于offset和limit在写法上更加简洁,但是在查询速度上却比较慢,这是因为通过切片的方式是先将所有数据获取后进行切片。而offset和limit是直接查询目标数据,效率更搞。
3、高级查询
1、group_by()
知识点补充:
1、query(模型)—>表示查询所有,query(模型.字段)—>查询对应字段,在使用group_by()对某一字段进行分组时,query(模型.字段)基本上要与其保持一致,否则报错
2、聚合函数,配合进行统计
小例子:统计所有男女生的年龄平均值
from sqlalchemy import create_enginefrom sqlalchemy import Column, String, Integer, Enumfrom sqlalchemy.orm import sessionmakerfrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import func# 定义引擎USERNAME = "root"PASSWORD = "147258"PORT = 3306HOSTNAME = "127.0.0.1"DATABASE = "wuyanxin"SLDG = f"mysql+mysqlconnector://{USERNAME}:{PASSWORD}@{HOSTNAME}:{PORT}/{DATABASE}?charset=utf8"engine = create_engine(SLDG)Base = declarative_base(engine)class Students(Base):__tablename__ = "gender"id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(10), nullable=False)age = Column(Integer)gender = Column(Enum("男", "女"))# __mapper_args__ = {# "order_by": age# }def __str__(self):return f"姓名:{self.name}, 年龄:{self.age}"# Base.metadata.drop_all()Base.metadata.create_all()session = sessionmaker(bind=engine)()# 在query()中写入聚合函数dates = session.query(Students.gender, func.avg(Students.age)).group_by(Students.gender).all()print(dates)session.commit()
注意这种写法:query(Students.gender, func.avg(Students.age))
2、having
having查询的是处理后的数据,而不是直接处理原始数据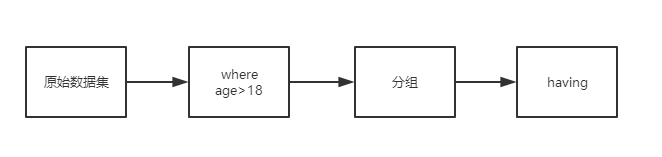
原始数据通过filter进行过滤,而分组数据则通过having进行过滤
小例子:找出所有成年人:
from sqlalchemy import create_enginefrom sqlalchemy import Column, String, Integer, Enumfrom sqlalchemy.orm import sessionmakerfrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import func# 定义引擎USERNAME = "root"PASSWORD = "147258"PORT = 3306HOSTNAME = "127.0.0.1"DATABASE = "wuyanxin"SLDG = f"mysql+mysqlconnector://{USERNAME}:{PASSWORD}@{HOSTNAME}:{PORT}/{DATABASE}?charset=utf8"engine = create_engine(SLDG)Base = declarative_base(engine)class Students(Base):__tablename__ = "gender"id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(10), nullable=False)age = Column(Integer)gender = Column(Enum("男", "女"))# __mapper_args__ = {# "order_by": age# }def __str__(self):return f"姓名:{self.name}, 年龄:{self.age}"# Base.metadata.drop_all()Base.metadata.create_all()session = sessionmaker(bind=engine)()dates = session.query(Students.age, func.count(Students.id)).group_by(Students.age).having(Students.age > 17).all()print(dates)# dates = session.query(Students.age).filter(Students.gender == "男").having(Students.age > 17).all()# print(dates)session.commit()
结果: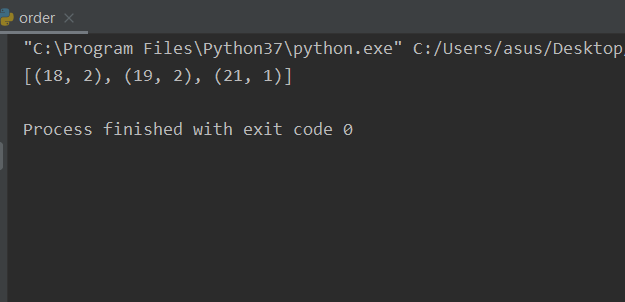
对比如下代码:
dates = session.query(Students.age, func.count(Students.id)).group_by(Students.age).having(Students.age > 17).all()print(dates)dates = session.query(Students.age).filter(Students.gender == "男").having(Students.age > 17).all()print(dates)dates = session.query(Students.age, func.count(Students.id)).filter(Students.gender == "男").group_by(Students.age).having(Students.age > 17).all()print(dates)
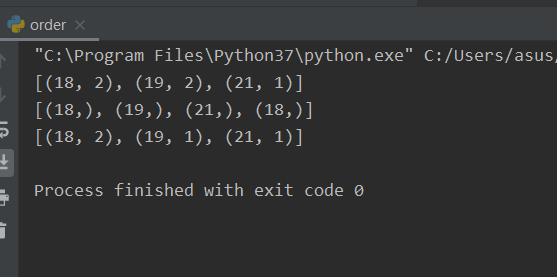
4、join
https://www.cnblogs.com/fudashi/p/7491039.html
5、子查询
相当于查询的嵌套(小知识扩展:网站中要存放表情使用的表的字符集是utf8mb4)
小例子:查询和龚祝俊同城市和同性别的人
普通查询:注意点query(模型),query(模型.字段,模型.字段),两者的区别就像是
from 模型 import *,from 模型 import 字段1,字段2,通过后者比起前者导入所有,只导入目标字段更加快
from sqlalchemy import create_engine, and_, subqueryfrom sqlalchemy import Column, String, Integer, Enumfrom sqlalchemy.orm import sessionmakerfrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import func# 定义引擎USERNAME = "root"PASSWORD = "147258"PORT = 3306HOSTNAME = "127.0.0.1"DATABASE = "wuyanxin"SLDG = f"mysql+mysqlconnector://{USERNAME}:{PASSWORD}@{HOSTNAME}:{PORT}/{DATABASE}?charset=utf8"engine = create_engine(SLDG)Base = declarative_base(engine)class Students(Base):__tablename__ = "gender"id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(10), nullable=False)age = Column(Integer)gender = Column(Enum("男", "女"))__mapper_args__ = {"order_by": age}def __str__(self):return f"Students(姓名:{self.name}, 年龄:{self.age}, 性别:{self.gender})"# Base.metadata.drop_all()Base.metadata.create_all()session = sessionmaker(bind=engine)()# 第一步,先找出目标数据,获得其年龄以及性别数据date = session.query(Students.age, Students.gender).filter(Students.name == "龚祝俊").first()# 第二步,通过找到的数据进行第二次过滤results = session.query(Students).filter(and_(Students.age == date.age, Students.gender == date.gender)).all()for result in results:print(result)
子查询:相对于普通查询而言查询速度更快
sub = session.query(Students.age.label("sub_age"), Students.gender.label("sub_gender")).filter(Students.name == "龚祝俊").subquery()results = session.query(Students).filter(Students.age == sub.c.sub_age, Students.gender == sub.c.sub_gender).all()for result in results:print(result)
注意点:
1、先写内层查询,查询到”样板数据”,并获取目标数据,然后写外层查询筛选所有的数据
2、知识点说明:
label():Students.age.label(“sub_age”)相当于取个别名,防止出现重名的现象,当然在引用时用的就是取的别名了
c:表示的是Column的意思
subquery():一般放在内层查询的末尾(子查询)

若有收获,就点个赞吧
0 人点赞
