1.0 本章导读
字符串相关的问题在各大互联网公司笔试面试中出现的频率极高,比如微软经典的单词翻转题:输入“I am a student.”,则输出“student. a am I”。
本章重点介绍6个经典的字符串问题,分别是旋转字符串、字符串包含、字符串转换成整数、回文判断、最长回文子串、字符串的全排列,这6个问题要么从暴力解法入手,然后逐步优化,要么多种思路多种解法。
读完本章后会发现,好的思路都是在充分考虑到问题本身的特征的前提下,或巧用合适的数据结构,或选择合适的算法降低时间复杂度(避免不必要的操作),或选用效率更高的算法。
1.1 旋转字符串
题目描述
给定一个字符串,要求把字符串前面的若干个字符移动到字符串的尾部,如把字符串“abcdef”前面的2个字符’a’和’b’移动到字符串的尾部,使得原字符串变成字符串“cdefab”。请写一个函数完成此功能,要求对长度为n的字符串操作的时间复杂度为 O(n),空间复杂度为 O(1)。
分析与解法
解法一:暴力移位法
初看此题,可能最先想到的方法是按照题目所要求的,把需要移动的字符一个一个地移动到字符串的尾部,如此我们可以实现一个函数LeftShiftOne(char* s, int n) ,以完成移动一个字符到字符串尾部的功能,代码如下所示:
void LeftShiftOne(char* s, int n){char t = s[0]; //保存第一个字符for (int i = 1; i < n; i++){s[i - 1] = s[i];}s[n - 1] = t;}
因此,若要把字符串开头的m个字符移动到字符串的尾部,则可以如下操作:
void LeftRotateString(char* s, int n, int m)
{
while (m--)
{
LeftShiftOne(s, n);
}
}
下面,我们来分析一下这种方法的时间复杂度和空间复杂度。
针对长度为n的字符串来说,假设需要移动m个字符到字符串的尾部,那么总共需要 m_n 次操作,同时设立一个变量保存第一个字符,如此,时间复杂度为O(m _n),空间复杂度为O(1),空间复杂度符合题目要求,但时间复杂度不符合,所以,我们得需要寻找其他更好的办法来降低时间复杂度。
解法二:三步反转法
对于这个问题,换一个角度思考一下。
将一个字符串分成X和Y两个部分,在每部分字符串上定义反转操作,如X^T,即把X的所有字符反转(如,X=”abc”,那么X^T=”cba”),那么就得到下面的结论:(X^TY^T)^T=YX,显然就解决了字符串的反转问题。
例如,字符串 abcdef ,若要让def翻转到abc的前头,只要按照下述3个步骤操作即可:
- 首先将原字符串分为两个部分,即X:abc,Y:def;
- 将X反转,X->X^T,即得:abc->cba;将Y反转,Y->Y^T,即得:def->fed。
- 反转上述步骤得到的结果字符串X^TY^T,即反转字符串cbafed的两部分(cba和fed)给予反转,cbafed得到defabc,形式化表示为(X^TY^T)^T=YX,这就实现了整个反转。
如下图所示:
代码则可以这么写:
void ReverseString(char* s,int from,int to)
{
while (from < to)
{
char t = s[from];
s[from++] = s[to];
s[to--] = t;
}
}
void LeftRotateString(char* s,int n,int m)
{
m %= n; //若要左移动大于n位,那么和%n 是等价的
ReverseString(s, 0, m - 1); //反转[0..m - 1],套用到上面举的例子中,就是X->X^T,即 abc->cba
ReverseString(s, m, n - 1); //反转[m..n - 1],例如Y->Y^T,即 def->fed
ReverseString(s, 0, n - 1); //反转[0..n - 1],即如整个反转,(X^TY^T)^T=YX,即 cbafed->defabc。
}
这就是把字符串分为两个部分,先各自反转再整体反转的方法,时间复杂度为O(n),空间复杂度为O(1),达到了题目的要求。
举一反三
1、链表翻转。给出一个链表和一个数k,比如,链表为1→2→3→4→5→6,k=2,则翻转后2→1→6→5→4→3,若k=3,翻转后3→2→1→6→5→4,若k=4,翻转后4→3→2→1→6→5,用程序实现。
2、编写程序,在原字符串中把字符串尾部的m个字符移动到字符串的头部,要求:长度为n的字符串操作时间复杂度为O(n),空间复杂度为O(1)。 例如,原字符串为”Ilovebaofeng”,m=7,输出结果为:”baofengIlove”。
3、单词翻转。输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变,句子中单词以空格符隔开。为简单起见,标点符号和普通字母一样处理。例如,输入“I am a student.”,则输出“student. a am I”。
1.2 字符串包含
题目描述
给定两个分别由字母组成的字符串A和字符串B,字符串B的长度比字符串A短。请问,如何最快地判断字符串B中所有字母是否都在字符串A里?
为了简单起见,我们规定输入的字符串只包含大写英文字母,请实现函数bool StringContains(string &A, string &B)
比如,如果是下面两个字符串:
String 1:ABCD
String 2:BAD
答案是true,即String2里的字母在String1里也都有,或者说String2是String1的真子集。
如果是下面两个字符串:
String 1:ABCD
String 2:BCE
答案是false,因为字符串String2里的E字母不在字符串String1里。
同时,如果string1:ABCD,string 2:AA,同样返回true。
分析与解法
题目描述虽长,但题意很明了,就是给定一长一短的两个字符串A,B,假设A长B短,要求判断B是否包含在字符串A中。
初看似乎简单,但实现起来并不轻松,且如果面试官步步紧逼,一个一个否决你能想到的方法,要你给出更好、最好的方案时,恐怕就要伤不少脑筋了。
解法一
判断string2中的字符是否在string1中?最直观也是最简单的思路是,针对string2中每一个字符,逐个与string1中每个字符比较,看它是否在String1中。
代码可如下编写:
bool StringContain(string &a,string &b)
{
for (int i = 0; i < b.length(); ++i) {
int j;
for (j = 0; (j < a.length()) && (a[j] != b[i]); ++j)
;
if (j >= a.length())
{
return false;
}
}
return true;
}
假设n是字符串String1的长度,m是字符串String2的长度,那么此算法,需要O(n*m)次操作。显然,时间开销太大,应该找到一种更好的办法。
解法二
如果允许排序的话,我们可以考虑下排序。比如可先对这两个字符串的字母进行排序,然后再同时对两个字串依次轮询。两个字串的排序需要(常规情况)O(m log m) + O(n log n)次操作,之后的线性扫描需要O(m+n)次操作。
关于排序方法,可采用最常用的快速排序,参考代码如下:
//注意A B中可能包含重复字符,所以注意A下标不要轻易移动。这种方法改变了字符串。如不想改变请自己复制
bool StringContain(string &a,string &b)
{
sort(a.begin(),a.end());
sort(b.begin(),b.end());
for (int pa = 0, pb = 0; pb < b.length();)
{
while ((pa < a.length()) && (a[pa] < b[pb]))
{
++pa;
}
if ((pa >= a.length()) || (a[pa] > b[pb]))
{
return false;
}
//a[pa] == b[pb]
++pb;
}
return true;
}
解法三
有没有比快速排序更好的方法呢?
我们换一种角度思考本问题:
假设有一个仅由字母组成字串,让每个字母与一个素数对应,从2开始,往后类推,A对应2,B对应3,C对应5,……。遍历第一个字串,把每个字母对应素数相乘。最终会得到一个整数。
利用上面字母和素数的对应关系,对应第二个字符串中的字母,然后轮询,用每个字母对应的素数除前面得到的整数。如果结果有余数,说明结果为false。如果整个过程中没有余数,则说明第二个字符串是第一个的子集了(判断是不是真子集,可以比较两个字符串对应的素数乘积,若相等则不是真子集)。
思路总结如下:
- 按照从小到大的顺序,用26个素数分别与字符’A’到’Z’一一对应。
- 遍历长字符串,求得每个字符对应素数的乘积。
- 遍历短字符串,判断乘积能否被短字符串中的字符对应的素数整除。
- 输出结果。
如前所述,算法的时间复杂度为O(m+n)的最好的情况为O(n)(遍历短的字符串的第一个数,与长字符串素数的乘积相除,即出现余数,便可退出程序,返回false),n为长字串的长度,空间复杂度为O(1)。
//此方法只有理论意义,因为整数乘积很大,有溢出风险
bool StringContain(string &a,string &b)
{
const int p[26] = {2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59,61, 67, 71, 73, 79, 83, 89, 97, 101};
int f = 1;
for (int i = 0; i < a.length(); ++i)
{
int x = p[a[i] - 'A'];
if (f % x)
{
f *= x;
}
}
for (int i = 0; i < b.length(); ++i)
{
int x = p[b[i] - 'A'];
if (f % x)
{
return false;
}
}
return true;
}
此种素数相乘的方法看似完美,但缺点是素数相乘的结果容易导致整数溢出。
解法四
如果面试官继续追问,还有没有更好的办法呢?计数排序?除了计数排序呢?
事实上,可以先把长字符串a中的所有字符都放入一个Hashtable里,然后轮询短字符串b,看短字符串b的每个字符是否都在Hashtable里,如果都存在,说明长字符串a包含短字符串b,否则,说明不包含。
再进一步,我们可以对字符串A,用位运算(26bit整数表示)计算出一个“签名”,再用B中的字符到A里面进行查找。
// “最好的方法”,时间复杂度O(n + m),空间复杂度O(1)
bool StringContain(string &a,string &b)
{
int hash = 0;
for (int i = 0; i < a.length(); ++i)
{
hash |= (1 << (a[i] - 'A'));
}
for (int i = 0; i < b.length(); ++i)
{
if ((hash & (1 << (b[i] - 'A'))) == 0)
{
return false;
}
}
return true;
}
这个方法的实质是用一个整数代替了hashtable,空间复杂度为O(1),时间复杂度还是O(n + m)。
举一反三
1、变位词
- 如果两个字符串的字符一样,但是顺序不一样,被认为是兄弟字符串,比如bad和adb即为兄弟字符串,现提供一个字符串,如何在字典中迅速找到它的兄弟字符串,请描述数据结构和查询过程。
1.3 字符串转换成整数
题目描述
输入一个由数字组成的字符串,把它转换成整数并输出。例如:输入字符串”123”,输出整数123。
给定函数原型int StrToInt(const char *str) ,实现字符串转换成整数的功能,不能使用库函数atoi。
分析与解法
本题考查的实际上就是字符串转换成整数的问题,或者说是要你自行实现atoi函数。那如何实现把表示整数的字符串正确地转换成整数呢?以”123”作为例子:
- 当我们扫描到字符串的第一个字符’1’时,由于我们知道这是第一位,所以得到数字1。
- 当扫描到第二个数字’2’时,而之前我们知道前面有一个1,所以便在后面加上一个数字2,那前面的1相当于10,因此得到数字:1*10+2=12。
- 继续扫描到字符’3’,’3’的前面已经有了12,由于前面的12相当于120,加上后面扫描到的3,最终得到的数是:12*10+3=123。
因此,此题的基本思路便是:从左至右扫描字符串,把之前得到的数字乘以10,再加上当前字符表示的数字。
思路有了,你可能不假思索,写下如下代码:
int StrToInt(const char *str)
{
int n = 0;
while (*str != 0)
{
int c = *str - '0';
n = n * 10 + c;
++str;
}
return n;
}
显然,上述代码忽略了以下细节:
- 空指针输入:输入的是指针,在访问空指针时程序会崩溃,因此在使用指针之前需要先判断指针是否为空。
- 正负符号:整数不仅包含数字,还有可能是以’+’或’-‘开头表示正负整数,因此如果第一个字符是’-‘号,则要把得到的整数转换成负整数。
- 非法字符:输入的字符串中可能含有不是数字的字符。因此,每当碰到这些非法的字符,程序应停止转换。
- 整型溢出:输入的数字是以字符串的形式输入,因此输入一个很长的字符串将可能导致溢出。
上述其它问题比较好处理,但溢出问题比较麻烦,所以咱们来重点看下溢出问题。
一般说来,当发生溢出时,取最大或最小的int值。即大于正整数能表示的范围时返回MAX_INT:2147483647;小于负整数能表示的范围时返回MIN_INT:-2147483648。
我们先设置一些变量:
- sign用来处理数字的正负,当为正时sign > 0,当为负时sign < 0
- n存放最终转换后的结果
- c表示当前数字
而后,你可能会编写如下代码段处理溢出问题:
//当发生正溢出时,返回INT_MAX
if ((sign == '+') && (c > MAX_INT - n * 10))
{
n = MAX_INT;
break;
}
//发生负溢出时,返回INT_MIN
else if ((sign == '-') && (c - 1 > MAX_INT - n * 10))
{
n = MIN_INT;
break;
}
但当上述代码转换” 10522545459”会出错,因为正常的话理应得到MAX_INT:2147483647,但程序运行结果将会是:1932610867。
为什么呢?因为当给定字符串” 10522545459”时,而MAX_INT是2147483647,即MAX_INT(2147483647) < n_10(1052254545_10),所以当扫描到最后一个字符‘9’的时候,执行上面的这行代码:
c > MAX_INT - n * 10
已无意义,因为此时(MAX_INT - n * 10)已经小于0,程序已经出错。
针对这种由于输入了一个很大的数字转换之后会超过能够表示的最大的整数而导致的溢出情况,我们有两种处理方式可以选择:
- 一个取巧的方式是把转换后返回的值n定义成long long,即long long n;
- 另外一种则是只比较n和MAX_INT / 10的大小,即:
- 若n > MAX_INT / 10,那么说明最后一步转换时,n*10必定大于MAX_INT,所以在得知n > MAX_INT / 10时,当即返回MAX_INT。
- 若n == MAX_INT / 10时,那么比较最后一个数字c跟MAX_INT % 10的大小,即如果n == MAX_INT / 10且c > MAX_INT % 10,则照样返回MAX_INT。
对于上面第一种方式,虽然我们把n定义了长整型,但最后返回时系统会自动转换成整型。咱们下面主要来看第二种处理方式。
对于上面第二种方式,先举两个例子说明下:
- 如果我们要转换的字符串是”2147483697”,那么当我扫描到字符’9’时,判断出214748369 > MAX_INT / 10 = 2147483647 / 10 = 214748364(C语言里,整数相除自动取整,不留小数),则返回MAX_INT;
- 如果我们要转换的字符串是”2147483648”,那么判断最后一个字符’8’所代表的数字8与MAX_INT % 10 = 7的大小,前者大,依然返回MAX_INT。
一直以来,我们努力的目的归根结底是为了更好的处理溢出,但上述第二种处理方式考虑到直接计算n _10 + c 可能会大于MAX_INT导致溢出,那么便两边同时除以10,只比较n和MAX_INT / 10的大小,从而巧妙的规避了计算n_10这一乘法步骤,转换成计算除法MAX_INT/10代替,不能不说此法颇妙。
如此我们可以写出正确的处理溢出的代码:
c = *str - '0';
if (sign > 0 && (n > MAX_INT / 10 || (n == MAX_INT / 10 && c > MAX_INT % 10)))
{
n = MAX_INT;
break;
}
else if (sign < 0 && (n > (unsigned)MIN_INT / 10 || (n == (unsigned)MIN_INT / 10 && c > (unsigned)MIN_INT % 10)))
{
n = MIN_INT;
break;
}
从而,字符串转换成整数,完整的参考代码为:
int StrToInt(const char* str)
{
static const int MAX_INT = (int)((unsigned)~0 >> 1);
static const int MIN_INT = -(int)((unsigned)~0 >> 1) - 1;
unsigned int n = 0;
//判断是否输入为空
if (str == 0)
{
return 0;
}
//处理空格
while (isspace(*str))
++str;
//处理正负
int sign = 1;
if (*str == '+' || *str == '-')
{
if (*str == '-')
sign = -1;
++str;
}
//确定是数字后才执行循环
while (isdigit(*str))
{
//处理溢出
int c = *str - '0';
if (sign > 0 && (n > MAX_INT / 10 || (n == MAX_INT / 10 && c > MAX_INT % 10)))
{
n = MAX_INT;
break;
}
else if (sign < 0 && (n >(unsigned)MIN_INT / 10 || (n == (unsigned)MIN_INT / 10 && c > (unsigned)MIN_INT % 10)))
{
n = MIN_INT;
break;
}
//把之前得到的数字乘以10,再加上当前字符表示的数字。
n = n * 10 + c;
++str;
}
return sign > 0 ? n : -n;
}
举一反三
- 实现string到double的转换
分析:此题虽然类似于atoi函数,但毕竟double为64位,而且支持小数,因而边界条件更加严格,写代码时需要更加注意。
1.4 回文判断
题目描述
回文,英文palindrome,指一个顺着读和反过来读都一样的字符串,比如madam、我爱我,这样的短句在智力性、趣味性和艺术性上都颇有特色,中国历史上还有很多有趣的回文诗。
那么,我们的第一个问题就是:判断一个字串是否是回文?
分析与解法
回文判断是一类典型的问题,尤其是与字符串结合后呈现出多姿多彩,在实际中使用也比较广泛,而且也是面试题中的常客,所以本节就结合几个典型的例子来体味下回文之趣。
解法一
同时从字符串头尾开始向中间扫描字串,如果所有字符都一样,那么这个字串就是一个回文。采用这种方法的话,我们只需要维护头部和尾部两个扫描指针即可。
代码如下::
bool IsPalindrome(const char *s, int n)
{
// 非法输入
if (s == NULL || n < 1)
{
return false;
}
const char* front,*back;
// 初始化头指针和尾指针
front = s;
back = s+ n - 1;
while (front < back)
{
if (*front != *back)
{
return false;
}
++front;
--back;
}
return true;
}
这是一个直白且效率不错的实现,时间复杂度:O(n),空间复杂度:O(1)。
解法二
上述解法一从两头向中间扫描,那么是否还有其它办法呢?我们可以先从中间开始、然后向两边扩展查看字符是否相等。参考代码如下:
bool IsPalindrome2(const char *s, int n)
{
if (s == NULL || n < 1)
{
return false;
}
const char* first, *second;
// m定位到字符串的中间位置
int m = ((n >> 1) - 1) >= 0 ? (n >> 1) - 1 : 0;
first = s + m;
second = s + n - 1 - m;
while (first >= s)
{
if (*first!= *second)
{
return false;
}
--first;
++second;
}
return true;
}
时间复杂度:O(n),空间复杂度:O(1)。
虽然本解法二的时空复杂度和解法一是一样的,但很快我们会看到,在某些回文问题里面,这个方法有着自己的独到之处,可以方便的解决一类问题。
举一反三
1、判断一条单向链表是不是“回文”
分析:对于单链表结构,可以用两个指针从两端或者中间遍历并判断对应字符是否相等。但这里的关键就是如何朝两个方向遍历。由于单链表是单向的,所以要向两个方向遍历的话,可以采取经典的快慢指针的方法,即先位到链表的中间位置,再将链表的后半逆置,最后用两个指针同时从链表头部和中间开始同时遍历并比较即可。
2、判断一个栈是不是“回文”
分析:对于栈的话,只需要将字符串全部压入栈,然后依次将各字符出栈,这样得到的就是原字符串的逆置串,分别和原字符串各个字符比较,就可以判断了。
1.5 最长回文子串
题目描述
分析与解法
最容易想到的办法是枚举所有的子串,分别判断其是否为回文。这个思路初看起来是正确的,但却做了很多无用功,如果一个长的子串包含另一个短一些的子串,那么对子串的回文判断其实是不需要的。
解法一
那么如何高效的进行判断呢?我们想想,如果一段字符串是回文,那么以某个字符为中心的前缀和后缀都是相同的,例如以一段回文串“aba”为例,以b为中心,它的前缀和后缀都是相同的,都是a。
那么,我们是否可以可以枚举中心位置,然后再在该位置上用扩展法,记录并更新得到的最长的回文长度呢?答案是肯定的,参考代码如下:
int LongestPalindrome(const char *s, int n)
{
int i, j, max,c;
if (s == 0 || n < 1)
return 0;
max = 0;
for (i = 0; i < n; ++i) { // i is the middle point of the palindrome
for (j = 0; (i - j >= 0) && (i + j < n); ++j){ // if the length of the palindrome is odd
if (s[i - j] != s[i + j])
break;
c = j * 2 + 1;
}
if (c > max)
max = c;
for (j = 0; (i - j >= 0) && (i + j + 1 < n); ++j){ // for the even case
if (s[i - j] != s[i + j + 1])
break;
c = j * 2 + 2;
}
if (c > max)
max = c;
}
return max;
}
代码稍微难懂一点的地方就是内层的两个 for 循环,它们分别对于以 i 为中心的,长度为奇数和偶数的两种情况,整个代码遍历中心位置 i 并以之扩展,找出最长的回文。
解法二、O(N)解法
在上文的解法一:枚举中心位置中,我们需要特别考虑字符串的长度是奇数还是偶数,所以导致我们在编写代码实现的时候要把奇数和偶数的情况分开编写,是否有一种方法,可以不用管长度是奇数还是偶数,而统一处理呢?比如是否能把所有的情况全部转换为奇数处理?
答案还是肯定的。这就是下面我们将要看到的Manacher算法,且这个算法求最长回文子串的时间复杂度是线性O(N)的。
首先通过在每个字符的两边都插入一个特殊的符号,将所有可能的奇数或偶数长度的回文子串都转换成了奇数长度。比如 abba 变成 #a#b#b#a#, aba变成 #a#b#a#。
此外,为了进一步减少编码的复杂度,可以在字符串的开始加入另一个特殊字符,这样就不用特殊处理越界问题,比如$#a#b#a#。
以字符串12212321为例,插入#和$这两个特殊符号,变成了 S[] = “$#1#2#2#1#2#3#2#1#”,然后用一个数组 P[i] 来记录以字符S[i]为中心的最长回文子串向左或向右扩张的长度(包括S[i])。
比如S和P的对应关系:
- S # 1 # 2 # 2 # 1 # 2 # 3 # 2 # 1 #
- P 1 2 1 2 5 2 1 4 1 2 1 6 1 2 1 2 1
可以看出,P[i]-1正好是原字符串中最长回文串的总长度,为5。
接下来怎么计算P[i]呢?Manacher算法增加两个辅助变量id和mx,其中id表示最大回文子串中心的位置,mx则为id+P[id],也就是最大回文子串的边界。得到一个很重要的结论:
- 如果mx > i,那么P[i] >= Min(P[2 * id - i], mx - i)
C代码如下:
//mx > i,那么P[i] >= MIN(P[2 * id - i], mx - i)
//故谁小取谁
if (mx - i > P[2*id - i])
P[i] = P[2*id - i];
else //mx-i <= P[2*id - i]
P[i] = mx - i;
下面,令j = 2*id - i,也就是说j是i关于id的对称点。
当 mx - i > P[j] 的时候,以S[j]为中心的回文子串包含在以S[id]为中心的回文子串中,由于i和j对称,以S[i]为中心的回文子串必然包含在以S[id]为中心的回文子串中,所以必有P[i] = P[j];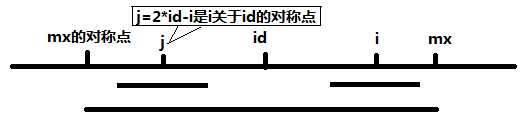
当 P[j] >= mx - i 的时候,以S[j]为中心的回文子串不一定完全包含于以S[id]为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以S[i]为中心的回文子串,其向右至少会扩张到mx的位置,也就是说 P[i] >= mx - i。至于mx之后的部分是否对称,再具体匹配。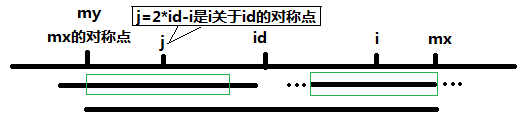
此外,对于 mx <= i 的情况,因为无法对 P[i]做更多的假设,只能让P[i] = 1,然后再去匹配。
综上,关键代码如下:
//输入,并处理得到字符串s
int p[1000], mx = 0, id = 0;
memset(p, 0, sizeof(p));
for (i = 1; s[i] != '\0'; i++)
{
p[i] = mx > i ? min(p[2 * id - i], mx - i) : 1;
while (s[i + p[i]] == s[i - p[i]])
p[i]++;
if (i + p[i] > mx)
{
mx = i + p[i];
id = i;
}
}
//找出p[i]中最大的
此Manacher算法使用id、mx做配合,可以在每次循环中,直接对P[i]的快速赋值,从而在计算以i为中心的回文子串的过程中,不必每次都从1开始比较,减少了比较次数,最终使得求解最长回文子串的长度达到线性O(N)的时间复杂度。
参考:http://www.felix021.com/blog/read.php?2040 。另外,这篇文章也不错:http://leetcode.com/2011/11/longest-palindromic-substring-part-ii.html 。
1.6 字符串的全排列
题目描述
输入一个字符串,打印出该字符串中字符的所有排列。
例如输入字符串abc,则输出由字符a、b、c 所能排列出来的所有字符串
abc、acb、bac、bca、cab 和 cba。
分析与解法
解法一、递归实现
从集合中依次选出每一个元素,作为排列的第一个元素,然后对剩余的元素进行全排列,如此递归处理,从而得到所有元素的全排列。以对字符串abc进行全排列为例,我们可以这么做:以abc为例
- 固定a,求后面bc的排列:abc,acb,求好后,a和b交换,得到bac
- 固定b,求后面ac的排列:bac,bca,求好后,c放到第一位置,得到cba
- 固定c,求后面ba的排列:cba,cab。
代码可如下编写所示:
void CalcAllPermutation(char* perm, int from, int to)
{
if (to <= 1)
{
return;
}
if (from == to)
{
for (int i = 0; i <= to; i++)
cout << perm[i];
cout << endl;
}
else
{
for (int j = from; j <= to; j++)
{
swap(perm[j], perm[from]);
CalcAllPermutation(perm, from + 1, to);
swap(perm[j], perm[from]);
}
}
}
解法二、字典序排列
首先,咱们得清楚什么是字典序。根据维基百科的定义:给定两个偏序集A和B,(a,b)和(a′,b′)属于笛卡尔集 A × B,则字典序定义为
(a,b) ≤ (a′,b′) 当且仅当 a < a′ 或 (a = a′ 且 b ≤ b′)。
所以给定两个字符串,逐个字符比较,那么先出现较小字符的那个串字典顺序小,如果字符一直相等,较短的串字典顺序小。例如:abc < abcd < abde < afab。
那有没有这样的算法,使得
- 起点: 字典序最小的排列, 1-n , 例如12345
- 终点: 字典序最大的排列,n-1, 例如54321
- 过程: 从当前排列生成字典序刚好比它大的下一个排列
答案是肯定的:有,即是STL中的next_permutation算法。
在了解next_permutation算法是怎么一个过程之前,咱们得先来分析下“下一个排列”的性质。
- 假定现有字符串(A)x(B),它的下一个排列是:(A)y(B’),其中A、B和B’是“字符串”(可能为空),x和y是“字符”,前缀相同,都是A,且一定有y > x。
- 那么,为使下一个排列字典顺序尽可能小,必有:
- A尽可能长
- y尽可能小
- B’里的字符按由小到大递增排列
现在的问题是:找到x和y。怎么找到呢?咱们来看一个例子。
比如说,现在我们要找21543的下一个排列,我们可以从左至右逐个扫描每个数,看哪个能增大(至于如何判定能增大,是根据如果一个数右面有比它大的数存在,那么这个数就能增大),我们可以看到最后一个能增大的数是:x = 1。
而1应该增大到多少?1能增大到它右面比它大的那一系列数中最小的那个数,即:y = 3,故此时21543的下一个排列应该变为23xxx,显然 xxx(对应之前的B’)应由小到大排,于是我们最终找到比“21543”大,但字典顺序尽量小的23145,找到的23145刚好比21543大。
由这个例子可以得出next_permutation算法流程为:
next_permutation算法
- 定义
- 升序:相邻两个位置ai < ai+1,ai 称作该升序的首位
- 步骤(二找、一交换、一翻转)
- 找到排列中最后(最右)一个升序的首位位置i,x = ai
- 找到排列中第i位右边最后一个比ai 大的位置j,y = aj
- 交换x,y
- 把第(i+ 1)位到最后的部分翻转
还是拿上面的21543举例,那么,应用next_permutation算法的过程如下:
- x = 1;
- y = 3
- 1和3交换
- 得23541
- 翻转541
- 得23145
23145即为所求的21543的下一个排列。参考实现代码如下:
bool CalcAllPermutation(char* perm, int num){
int i;
//①找到排列中最后(最右)一个升序的首位位置i,x = ai
for (i = num - 2; (i >= 0) && (perm[i] >= perm[i + 1]); --i){
;
}
// 已经找到所有排列
if (i < 0){
return false;
}
int k;
//②找到排列中第i位右边最后一个比ai 大的位置j,y = aj
for (k = num - 1; (k > i) && (perm[k] <= perm[i]); --k){
;
}
//③交换x,y
swap(perm[i], perm[k]);
//④把第(i+ 1)位到最后的部分翻转
reverse(perm + i + 1, perm + num);
return true;
}
然后在主函数里循环判断和调用calcAllPermutation函数输出全排列即可。
解法总结
由于全排列总共有n!种排列情况,所以不论解法一中的递归方法,还是上述解法二的字典序排列方法,这两种方法的时间复杂度都为O(n!)。
类似问题
1、已知字符串里的字符是互不相同的,现在任意组合,比如ab,则输出aa,ab,ba,bb,编程按照字典序输出所有的组合。
分析:非简单的全排列问题(跟全排列的形式不同,abc全排列的话,只有6个不同的输出)。 本题可用递归的思想,设置一个变量表示已输出的个数,然后当个数达到字符串长度时,就输出。
//copyright@ 一直很安静 && World Gao
//假设str已经有序
void perm(char* result, char *str, int size, int resPos)
{
if(resPos == size)
printf("%s\n", result);
else
{
for(int i = 0; i < size; ++i)
{
result[resPos] = str[i];
perm(result, str, size, resPos + 1);
}
}
}
2、如果不是求字符的所有排列,而是求字符的所有组合,应该怎么办呢?当输入的字符串中含有相同的字符串时,相同的字符交换位置是不同的排列,但是同一个组合。举个例子,如果输入abc,它的组合有a、b、c、ab、ac、bc、abc。
3、写一个程序,打印出以下的序列。
(a),(b),(c),(d),(e)……..(z)
(a,b),(a,c),(a,d),(a,e)……(a,z),(b,c),(b,d)…..(b,z),(c,d)…..(y,z)
(a,b,c),(a,b,d)….(a,b,z),(a,c,d)….(x,y,z)
+
….
(a,b,c,d,…..x,y,z)
1.7 本章字符串和链表的习题
1、第一个只出现一次的字符
在一个字符串中找到第一个只出现一次的字符。如输入abaccdeff,则输出b。
2、对称子字符串的最大长度
输入一个字符串,输出该字符串中对称的子字符串的最大长度。比如输入字符串“google”,由于该字符串里最长的对称子字符串是“goog”,因此输出4。
提示:可能很多人都写过判断一个字符串是不是对称的函数,这个题目可以看成是该函数的加强版。
3、编程判断俩个链表是否相交
给出俩个单向链表的头指针,比如h1,h2,判断这俩个链表是否相交。为了简化问题,我们假设俩个链表均不带环。
问题扩展:
- 如果链表可能有环列?
- 如果需要求出俩个链表相交的第一个节点列?
4、逆序输出链表
输入一个链表的头结点,从尾到头反过来输出每个结点的值。
5、在O(1)时间内删除单链表结点
给定单链表的一个结点的指针,同时该结点不是尾结点,此外没有指向其它任何结点的指针,请在O(1)时间内删除该结点。
6、找出链表的第一个公共结点
两个单向链表,找出它们的第一个公共结点。
7、在字符串中删除特定的字符
输入两个字符串,从第一字符串中删除第二个字符串中所有的字符。
例如,输入”They are students.”和”aeiou”,则删除之后的第一个字符串变成”Thy r stdnts.”。
8、字符串的匹配
在一篇英文文章中查找指定的人名,人名使用二十六个英文字母(可以是大写或小写)、空格以及两个通配符组成(、?),通配符“”表示零个或多个任意字母,通配符“?”表示一个任意字母。如:“J Smi??” 可以匹配“John Smith” .
9、字符个数的统计
char str = “AbcABca”; 写出一个函数,查找出每个字符的个数,区分大小写,要求时间复杂度是n(提示用ASCII码)
10、最小子串
给一篇文章,里面是由一个个单词组成,单词中间空格隔开,再给一个字符串指针数组,比如 char str[]={“hello”,”world”,”good”};
求文章中包含这个字符串指针数组的最小子串。注意,只要包含即可,没有顺序要求。
提示:文章也可以理解为一个大的字符串数组,单词之前只有空格,没有标点符号。
11、字符串的集合
给定一个字符串的集合,格式如:{aaa bbb ccc}, {bbb ddd},{eee fff},{ggg},{ddd hhh}要求将其中交集不为空的集合合并,要求合并完成后的集合之间无交集,例如上例应输出{aaa bbb ccc ddd hhh},{eee fff}, {ggg}。
提示:并查集。
*12、五笔编码
五笔的编码范围是a ~ y的25个字母,从1位到4位的编码,如果我们把五笔的编码按字典序排序,形成一个数组如下: a, aa, aaa, aaaa, aaab, aaac, … …, b, ba, baa, baaa, baab, baac … …, yyyw, yyyx, yyyy 其中a的Index为0,aa的Index为1,aaa的Index为2,以此类推。
- 编写一个函数,输入是任意一个编码,比如baca,输出这个编码对应的Index;
- 编写一个函数,输入是任意一个Index,比如12345,输出这个Index对应的编码。
13、最长重复子串
一个长度为10000的字符串,写一个算法,找出最长的重复子串,如abczzacbca,结果是bc。
提示:此题是后缀树/数组的典型应用,即是求后缀数组的height[]的最大值。
14、字符串的压缩
一个字符串,压缩其中的连续空格为1个后,对其中的每个字串逆序打印出来。比如”abc efg hij”打印为”cba gfe jih”。
15、最大重复出现子串
输入一个字符串,如何求最大重复出现的字符串呢?比如输入ttabcftrgabcd,输出结果为abc, canffcancd,输出结果为can。
给定一个字符串,求出其最长的重复子串。
分析:使用后缀数组,对一个字符串生成相应的后缀数组后,然后再排序,排完序依次检测相邻的两个字符串的开头公共部分。 这样的时间复杂度为:
- 生成后缀数组 O(N)
- 排序 O(NlogN*N) 最后面的 N 是因为字符串比较也是 O(N)
- 依次检测相邻的两个字符串 O(N * N)
故最终总的时间复杂度是 O(N^2logN)
16、字符串的删除
删除模式串中出现的字符,如“welcome to asted”,模式串为“aeiou”那么得到的字符串为“wlcm t std”,要求性能最优。
17、字符串的移动
字符串为号和26个字母的任意组合,把 号都移动到最左侧,把字母移到最右侧并保持相对顺序不变,要求时间和空间复杂度最小。
18、字符串的包含
输入:
L:“hello”“july”
S:“hellomehellojuly”
输出:S中包含的L一个单词,要求这个单词只出现一次,如果有多个出现一次的,输出第一个这样的单词。
19、倒数第n个元素
链表倒数第n个元素。
提示:设置一前一后两个指针,一个指针步长为1,另一个指针步长为n,当一个指针走到链表尾端时,另一指针指向的元素即为链表倒数第n个元素。
20、回文字符串
将一个很长的字符串,分割成一段一段的子字符串,子字符串都是回文字符串。有回文字符串就输出最长的,没有回文就输出一个一个的字符。
例如:
habbafgh
输出h,abba,f,g,h。
提示:一般的人会想到用后缀数组来解决这个问题。
21、最长连续字符
用递归算法写一个函数,求字符串最长连续字符的长度,比如aaaabbcc的长度为4,aabb的长度为2,ab的长度为1。
22、字符串反转
实现字符串反转函数。
*22、字符串压缩
通过键盘输入一串小写字母(a~z)组成的字符串。请编写一个字符串压缩程序,将字符串中连续出席的重复字母进行压缩,并输出压缩后的字符串。 压缩规则:
- 仅压缩连续重复出现的字符。比如字符串”abcbc”由于无连续重复字符,压缩后的字符串还是”abcbc”。
- 压缩字段的格式为”字符重复的次数+字符”。例如:字符串”xxxyyyyyyz”压缩后就成为”3x6yz”。
要求实现函数: void stringZip(const char _pInputStr, long lInputLen, char _pOutputStr);
- 输入pInputStr: 输入字符串lInputLen: 输入字符串长度
- 输出 pOutputStr: 输出字符串,空间已经开辟好,与输入字符串等长;
注意:只需要完成该函数功能算法,中间不需要有任何IO的输入输出
示例
- 输入:“cccddecc” 输出:“3c2de2c”
- 输入:“adef” 输出:“adef”
- 输入:“pppppppp” 输出:“8p”
23、集合的差集
已知集合A和B的元素分别用不含头结点的单链表存储,请求集合A与B的差集,并将结果保存在集合A的单链表中。例如,若集合A={5,10,20,15,25,30},集合B={5,15,35,25},完成计算后A={10,20,30}。
24、最长公共子串
给定字符串A和B,输出A和B中的第一个最长公共子串,比如A=“wepiabc B=“pabcni”,则输出“abc”。
25、均分01
给定一个字符串,长度不超过100,其中只包含字符0和1,并且字符0和1出现得次数都是偶数。你可以把字符串任意切分,把切分后得字符串任意分给两个人,让两个人得到的0的总个数相等,得到的1的总个数也相等。
例如,输入串是010111,我们可以把串切位01, 011,和1,把第1段和第3段放在一起分给一个人,第二段分给另外一个人,这样每个人都得到了1个0和两个1。我们要做的是让切分的次数尽可能少。
考虑到最差情况,则是把字符串切分(n - 1)次形成n个长度为1的串。
26、合法字符串
用n个不同的字符(编号1 - n),组成一个字符串,有如下2点要求:
- 1、对于编号为i 的字符,如果2 * i > n,则该字符可以作为最后一个字符,但如果该字符不是作为最后一个字符的话,则该字符后面可以接任意字符;
- 2、对于编号为i的字符,如果2 _i <= n,则该字符不可以作为最后一个字符,且该字符后面所紧接着的下一个字符的编号一定要 >= 2 _i。
问有多少长度为M且符合条件的字符串。
例如:N = 2,M = 3。则abb, bab, bbb是符合条件的字符串,剩下的均为不符合条件的字符串。
假定n和m皆满足:2<=n,m<=1000000000)。
27、最短摘要生成
你我在百度或谷歌搜索框中敲入本博客名称的前4个字“结构之法”,便能在第一个选项看到本博客的链接,如下图2所示:
在上面所示的图2中,搜索结果“结构之法算法之道-博客频道-CSDN.NET”下有一段说明性的文字:“程序员面试、算法研究、编程艺术、红黑树4大经典原创系列集锦与总结 作者:July—结构之法算法…”,我们把这段文字称为那个搜索结果的摘要,亦即最短摘要。我们的问题是,请问,这个最短摘要是怎么生成的呢?
28、实现memcpy函数
已知memcpy的函数为: void* memcpy(void* dest , const void* src , size_t count)其中dest是目的指针,src是源指针。不调用c++/c的memcpy库函数,请编写memcpy。
分析:参考代码如下:
void* memcpy(void *dst, const void *src, size_t count)
{
//安全检查
assert( (dst != NULL) && (src != NULL) );
unsigned char *pdst = (unsigned char *)dst;
const unsigned char *psrc = (const unsigned char *)src;
//防止内存重复
assert(!(psrc<=pdst && pdst<psrc+count));
assert(!(pdst<=psrc && psrc<pdst+count));
while(count--)
{
*pdst = *psrc;
pdst++;
psrc++;
}
return dst;
}
29、实现memmove函数
分析:memmove函数是的标准函数,其作用是把从source开始的num个字符拷贝到destination。最简单的方法是直接复制,但是由于它们可能存在内存的重叠区,因此可能覆盖了原有数据。
比如当source+count>=dest&&source
//void * memmove ( void * destination, const void * source, size_t num );)
void* memmove(void* dest, void* source, size_t count)
{
void* ret = dest;
if (dest <= source || dest >= (source + count))
{
//正向拷贝
//copy from lower addresses to higher addresses
while (count --)
*dest++ = *source++;
}
else
{
//反向拷贝
//copy from higher addresses to lower addresses
dest += count - 1;
source += count - 1;
while (count--)
*dest-- = *source--;
}
return ret;
}

若有收获,就点个赞吧
0 人点赞
