方法介绍
https://download.csdn.net/download/qq482850611/10152364?utm_source=bbsseo
一、什么是Bloom Filter
Bloom Filter,被译作称布隆过滤器,是一种空间效率很高的随机数据结构,Bloom filter可以看做是对bit-map的扩展,它的原理是:
- 当一个元素被加入集合时,通过K个Hash函数将这个元素映射成一个位阵列(Bit array)中的K个点,把它们置为1**。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:
- 如果这些点有任何一个0,则被检索元素一定不在;
- 如果都是1,则被检索元素很可能在。
其可以用来实现数据字典,进行数据的判重,或者集合求交集。
但Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
1.1、集合表示和元素查询
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。
为了表达S={x, x,…,x}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置h(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位,即第二个“1“处)。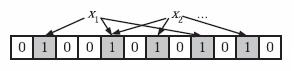
在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有h(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y就不是集合中的元素(因为y1有一处指向了“0”位)。y或者属于这个集合,或者刚好是一个false positive。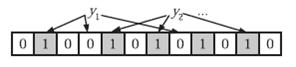
1.2、错误率估计






1.3、最优的散列函数个数




1.4、位数组的大小


问题实例
1、给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
分析:如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。”
垃圾邮件过滤


若有收获,就点个赞吧
0 人点赞
