论文:lite Transformer.pdf
代码:https://github.com/mit-han-lab/lite-transformer
Abstract
本文提出了一种高效的移动 NLP 架构 Lite Transformer,以促进在边缘设备上部署移动 NLP 应用程序。 关键原语是 Long-Short Range Attention (LSRA),其中一组头部专门从事局部上下文建模(通过卷积),而另一组专门从事远程关系建模(通过注意力)。 这种专业化在三个成熟的语言任务上对 vanilla transformer 带来了持续改进:机器翻译、抽象摘要和语言建模。�
Contributions
- 本文系统地分析了现代神经网络中常用的计算bottleneck结构,发现如果使用 FLOPs 作为品质因数,bottleneck设计对于一维注意力并不是最优的。�
- 本文提出了一个专门的多分支特征提取器,Long-Short Range Attention (LSRA),作为我们转换器的基本构建块,其中卷积有助于捕获局部上下文,注意力集中在全局上下文上。�
- 本文基于 LSRA 构建 Lite Transformer。 在移动计算资源限制(500M Multi-Adds)下,Lite Transformer 展示了对三个广泛使用的机器翻译数据集的一致改进。 通过对其他任务的额外实验,Lite Transformer 对于多语言应用程序非常有效。�
Is Bottleneck Effective for 1-D Attention
注意力机制被广泛应用于各类应用,如1-D(语言处理),2-D(图像检测),3-D(视频检测)。它计算所有输入元素之间的成对点积以模拟短期和长期关系�。尽管有效,但这种操作引入了大量计算。假设输入注意力层的元素数量为N(例如,语言处理中的tokens长度,图像中的像素数等),特征(如通道)的维度是d,点积所需的计算量为N2d。对于图像和视频,N通常很大。例如,视频网络中的中间特征图有16帧,每帧分辨率 112x112,导致 N=2x105。卷积层和全连接层关于N的计算量是线性增长的,而注意层关于N的计算量是二次增长的。注意力模块的计算量很快会被一个大N淹没。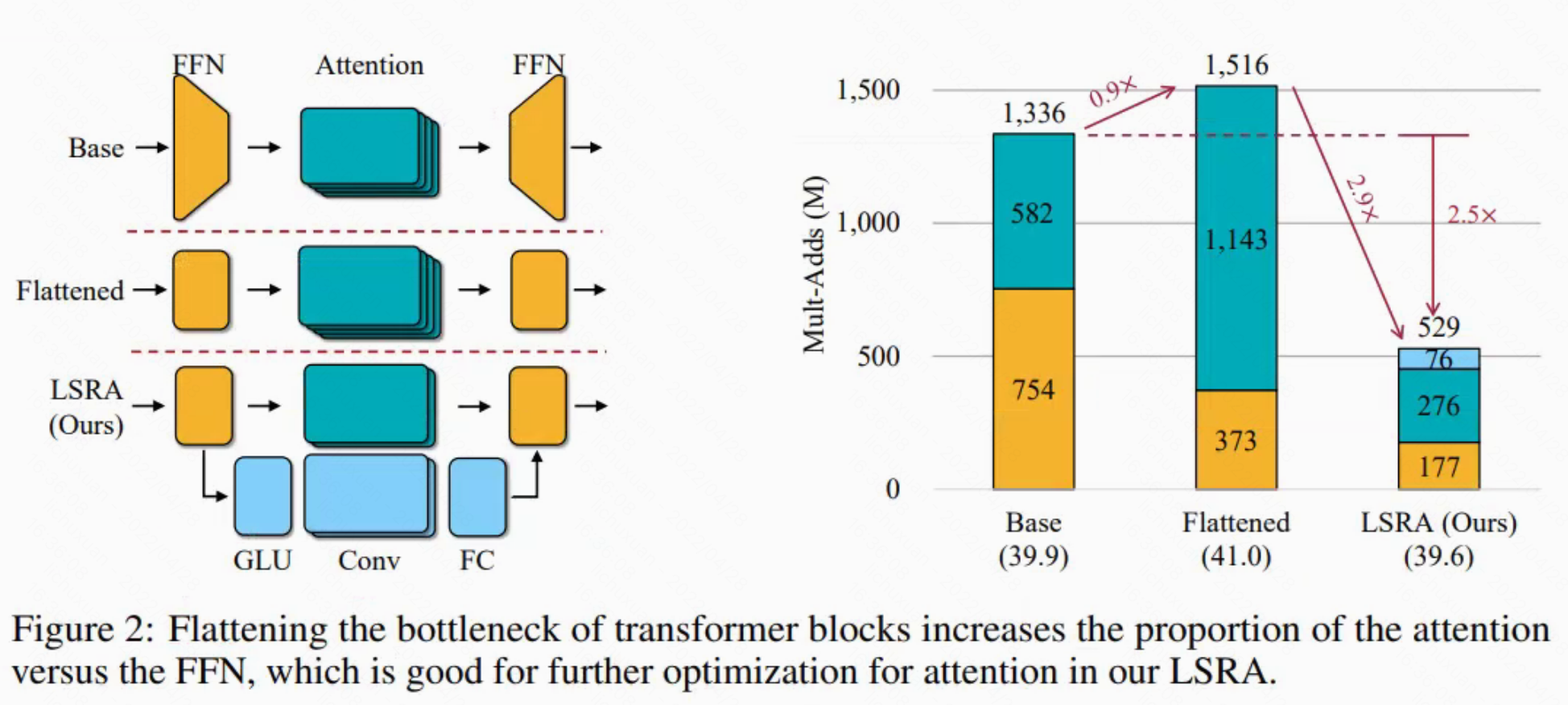
为了解决这个难题,一种常见的做法是在应用注意力之前首先使用线性投影层减少通道数 d,然后再增加维度(如图 2 所示)。�在transformer的原始设计中,注意力模块中的通道维数比FFN层的通道维数小4。
同样,在非局部视频网络中,在应用非局部注意力模块之前,首先将通道数减少一半。这种做法减少了16倍或4倍的计算。然而,它也降低了具有较小特征维度的注意力层的上下文捕获能力。 语言处理的情况可能更糟,因为注意力是上下文捕获的主要模块(与卷积进行主要信息捕获的图像和视频不同)。
�对于像翻译这样的任务,输入序列 N 的长度往往很小,通常在 20-30 左右。�transformer块由一个注意力模块(或两个用于解码器)和一个前馈网络(FFN)组成。对于注意力层,Mult-Adds为 ;对于FFN,Mult-Adds为
;对于FFN,Mult-Adds为 。给定一个小的 N,bottleneck设计是否是计算和一维注意力准确性之间的良好折衷是值得怀疑的。�为了验证这个想法,我们首先在图 2 中描述了 transformer 中的计算分解。令人惊讶的是,对于原始Transformer(在图中表示为 Base),FFN 层实际上消耗了大部分计算。 这是不可取的,因为 FFN 本身不能执行任何上下文捕获。 总之,由于 N 较小,bottleneck设计不能显著减少 1D attention 中的计算量,而较大的 FFN 层进一步损害了计算量减少的有限收益。 由于维度较小,它也损害了注意力层的容量,而注意力层是 Transformer 中主要的上下文捕获单元。�
。给定一个小的 N,bottleneck设计是否是计算和一维注意力准确性之间的良好折衷是值得怀疑的。�为了验证这个想法,我们首先在图 2 中描述了 transformer 中的计算分解。令人惊讶的是,对于原始Transformer(在图中表示为 Base),FFN 层实际上消耗了大部分计算。 这是不可取的,因为 FFN 本身不能执行任何上下文捕获。 总之,由于 N 较小,bottleneck设计不能显著减少 1D attention 中的计算量,而较大的 FFN 层进一步损害了计算量减少的有限收益。 由于维度较小,它也损害了注意力层的容量,而注意力层是 Transformer 中主要的上下文捕获单元。�
因此本文认为bottleneck设计对于1-D attention不是最优的。本文设计了一个扁平化版本的transform block,它不会减少和增加通道维度。有了新的设计,attention部分现在占据了图2中flattened transformer模型中的主要计算,为进一步优化留下了更大空间。
Long-Short Range Attention(LSRA)
研究人员试图了解注意力所捕捉到的背景。 Kovaleva et al.(2019) 和 Clark et al.(2020) 可视化了 BERT 中不同层的注意力权重。 如图 3b 所示,权重 w 说明了源句和目标句中的单词之间的关系(self-attention 也是如此)。 权重 wij 越大(颜色越深),源句中的第 i 个词越关注目标句中的第 j 个词。 注意力图通常具有很强的模式:稀疏和对角线。 它们代表了一些特定词之间的关系:长期信息的稀疏,以及小邻域中相关性的对角线。 我们将前者称为全局关系,将后者称为局部关系。�
对于翻译任务,注意力模块必须同时捕获全局和局部上下文,这需要很大的容量。 与专门的设计相比,这并不是最佳的。 以硬件设计为例,CPU 等通用硬件的效率低于 FPGA 等专用硬件。
在这里,本文专注于全局和本地上下文捕获。 当模型容量较大时,可以容忍冗余,甚至可以提供更好的性能。 然而,当涉及到移动应用程序时,由于计算和功率限制,模型应该更有效。 因此,专门的上下文捕获要求更高。 为了解决这个问题,我们提出了一种更专业的架构,即长短程注意力(LSRA),而不是使用一个用于一般信息的模块,它分别捕获全局和局部上下文�。
如图 3a 所示,LSRA 模块遵循双分支设计。左分支捕获全局上下文,而右分支模拟本地上下文。�并非将整个输入送入两个分支,而是将其沿通道维度分为两部分,再由FFN层混合。该做法将整体计算量减少了2倍。左分支是通道维度减少了一半的普通注意力模块。
对于局部关系的右分支,一个自然的想法是在序列上应用卷积。通过滑动窗口,模块可以轻松覆盖对角线组。为了进一步减少计算量,本文使用由线性层和depth-wise conv替换了普通卷积。通过这种方式将注意力模块和卷积模块并排放置
图 3 中可视化了经过充分训练的基本 Transformer 和我们的 Lite Transformer 的同一层的平均注意力权重。�很容易区分,LSRA 中的注意力模块没有尝试对全局和局部上下文进行建模,而是仅关注全局上下文捕获(无对角线模式),将局部上下文捕获留给卷积分支。�
Experimental Setup
Mobile Settings
大多数机器翻译架构都受益于大模型尺寸和计算复杂性。 然而,边缘设备,如手机和物联网,在计算上受到高度限制。 那些庞大的架构不再适合现实世界的移动应用程序。 为了形式化这个问题,我们根据计算量和参数数量定义了 NLP 模型的移动设置�
- 定义机器翻译任务的移动端设置:30个token(机器翻译的一般长度)计算约束在500M Mult-Adds(或1G FLOPs)以下
- 参数量限制在10M左右
Architecture
模型结构基于序列学习的编-解码器结构。
机器翻译的基线模型是基于Vaswani等人(2017)提出的WMT基线模型。IWSLT遵循Wu等人(2019b)中的设置。汇总任务采用了与WMT相同的模型�
语言模型与Baevski&Auli(2019)提出的模型一致,受资源限制,维度dmodel=512,层数L=12.
量化技术
Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding
剪枝技术
Learning both weights and connections for efficient neural network

若有收获,就点个赞吧
0 人点赞
