
简介
linux轻量级的高可用(High Avalilability,HA)解决方案
它与HeartBeat RoseHA 实现相同类似的功能,都可以实现服务或者网络的高可用。
HeartBeat是一个专业的、功能完善的高可用软件,它提供了HA 软件所需的基本功能,比如:心跳检测、资源接管,检测集群中的服务,在集群节点转移共享IP地址的所有者等等。HeartBeat功能强大,但是部署和使用相对比较麻烦
Keepalived主要是通过虚拟路由冗余来实现高可用功能,虽然它没有HeartBeat功能强大,但是Keepalived部署和使用非常的简单,所有配置只需要一个配置文件即可以完成
是什么?
1.起初是为LVS设计的,使用IPVS内核模块,专门用来监控集群系统中各个服务节点的状态,如果某个服务器节点出现故障,Keepalived将检测到后自动将节点从集群系统中剔除.
2.后来加入了VRRP(虚拟路由冗余协议),目的是解决静态路由出现的单点故障,通过vrrp协议可以实现网络不间断稳定运行
高可用
功能
1.健康检测:采用tcp三次握手,icmp请求,http请求、udpecho请求等方式对负载均衡后的真实后端服务器保活
2.失败切换:主要应用于配置了主备模式的负载均衡器,用vrrp协议维持主备均衡器的心跳,当主负载均衡出现问题的时候,有备负载均衡器承载对应的业务,从而在最大限度上减少流量的损失
vrrp协议
- 1.vrrp协议是一种容错的主备协议,保证当主机的下一条路由出现故障的时候,由另外一台路由器来替换出现故障的路由器进行工作,通过vrrp可以在网络发生故障时透明的进行设备切换而不影响主机之间的通信
- 2.虚拟路由器:vrrp组中所有路由器,拥有虚拟IP+MAC(00-00-5e-00-01-VRID)地址
- 3.主路由器:虚拟路由器内部,通常只由一台物理路由器对外提供服务,主路由器是由选举算法选举对外提供各种网络功能
4.备份路由器:vrrp组中除了主路由器之外的所有路由器,不对外提供任何服务,只接收主路由器的通信,当主路由器挂掉时,重新进行选举算法,接替master路由器
vrrp选举机制
三种状态:
- Initialize状态:初始化状态
- Master状态
- Backup状态
- 选举机制:
- 优先级
- 抢占模式下,一旦有优先级高的路由加入,即成为master
- 非抢占模式下,只要master不挂,优先级高的路由器只能等待
工作原理
Keepalived工作在tcp/ip模型的3、4、5层,也就网络层、传输层、应用层运行机制:
网络层:通过ICMP协议向服务集群中的每个节点发送一个ICMP数据包,如果某个节点没有返回响应数据包,那么认为该节点发生了故障,Keepalivesd将报告节点失效,并从服务器集群中将故障节点剔除
四个协议:互联网络IP协议,互联网络可控制报文协议ICMP、地址转换协议ARP、反向地址转换协议RARP
传输层:利用TCP大的端口连接和扫描技术来判断集群节点的端口是否正常。一旦检测到这些端口没有数据响应和数据返回,就认为这些端口发生了异常,然后强制这些端口所有的节点从服务器集群中剔除掉 两个主要协议:传输控制协议TCP和用户数据协议UDP
应用层:自定义Keepalived工作方式。 可以运行FTP,TELNET,SMTP,DNS等各种不同类型的高层协议
体系结构
内核空间层
IPVS模块:是可配置的,如果需要负载均衡功能,在编译Keepalived的时候打开负载均衡功能
NETLINK模块:主要用于实现一些高级路由框架和一些相关参数的网络功能,完成用户空间层Netlink Reflector模块发来的各种网络请求
用户空间层(4部分)
Scheduler - I/O Multiplexer :一个I/O复用分发调度器,负载安排Keepalives所有内部的任务请求
Memory Mngt:一个内存管理机制,这个框架提供了访问内存的一些通用方法
Control Plane:Keepalived的控制面板,可以实现对配置文件编译和解析
Core componets: 五部分
Watchdog:是计算机可靠领域中简单而有效的检测工具,Keepalived是通过它来监控Checkers和VRRP进程的 Checkers:可以实现对服务器运行状态检测和故障隔离
VRRP Stack:可以实现对HA集群中失败切换功能
IPVS wrapper:IPVS功能的一个实现,可以将设置好的IPVS规则发送到内核空间并且提供给IPVS模块,最终实现IPVS模块的负载功能
Netlink Reflector:用来实现高可用集群Failover时虚拟IP(VIP)的设置和切换,它的所有请求最后发送到内核空间层的NETLINK模块来处理
Keepalived在运行时,会启动三个进程
- core:负责主进程的启动,维护和全局配置文件的加载
- check:负责健康检查
- vrrp:用来实现vrrp协议
对比
| Service高可用 | Keepalived高可用 |
|---|---|
| 模拟路由的高可用,保证网络连接不中断 | Heartbeat和Corosync |
| 实现前端高可用 组合方式: Keepalived +Nginx Keepalived+haproxy+MYSQL Keepalived+LVS |
常用组合方式: |
Heartbeat v3 | Corosync+Pacemaker+NFS+Httpd Heartbeat v3 |Corosync+Pacemaker +NFS+MySQL |
安装
yum install keepalived -y
软件包:keepalived
主配置文件:/etc/keepalived/keepalived.conf
守护进程配置文件:/usr/lib/systemd/system/keepalived.service
相关命令:/usr/sbin/keepalived
主配置文件
[root@node4 conf.d]# cat /etc/keepalived/keepalived.conf! Configuration File for keepalivedglobal_defs { #定义全局notification_email { #邮件通知相关配置acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}notification_email_from Alexandre.Cassen@firewall.locsmtp_server 192.168.200.1 #smtp服务:网络主机管理服务smtp_connect_timeout 30router_id LVS_DEVEL #router id 唯一标识vrrp_skip_check_adv_addr #vrrp是否跳过健康检查vrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0}vrrp_instance VI_1 { 定义vrrp组(组名VI_1)state MASTER 状态interface eth0 访问接口virtual_router_id 51 虚拟路由器的IPpriority 100 优先级advert_int 1authentication { 身份验证auth_type PASSauth_pass 1111}virtual_ipaddress { VIP地址192.168.200.16192.168.200.17192.168.200.18}}##下面是关于LVS server的配置virtual_server 192.168.200.100 443 {delay_loop 6lb_algo rrlb_kind NATpersistence_timeout 50protocol TCPreal_server 192.168.201.100 443 {weight 1SSL_GET {url {path /digest ff20ad2481f97b1754ef3e12ecd3a9cc}url {path /mrtg/digest 9b3a0c85a887a256d6939da88aabd8cd}connect_timeout 3nb_get_retry 3delay_before_retry 3}}}virtual_server 10.10.10.2 1358 {delay_loop 6lb_algo rrlb_kind NATpersistence_timeout 50protocol TCPsorry_server 192.168.200.200 1358real_server 192.168.200.2 1358 {weight 1HTTP_GET {url {path /testurl/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl2/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl3/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}connect_timeout 3nb_get_retry 3delay_before_retry 3}}real_server 192.168.200.3 1358 {weight 1HTTP_GET {url {path /testurl/test.jspdigest 640205b7b0fc66c1ea91c463fac6334c}url {path /testurl2/test.jspdigest 640205b7b0fc66c1ea91c463fac6334c}connect_timeout 3nb_get_retry 3delay_before_retry 3}}}virtual_server 10.10.10.3 1358 {delay_loop 3lb_algo rrlb_kind NATpersistence_timeout 50protocol TCPreal_server 192.168.200.4 1358 {weight 1HTTP_GET {url {path /testurl/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl2/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl3/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}connect_timeout 3nb_get_retry 3delay_before_retry 3}}real_server 192.168.200.5 1358 {weight 1HTTP_GET {url {path /testurl/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl2/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl3/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}connect_timeout 3nb_get_retry 3delay_before_retry 3}}}
keepalivedx+ nginx 实验
一、首先部署Nginx负载均衡
web1 192.168.10.138
web2 192.168.10.140
proxy1 192.168.10.144
proxy2 192.168.10.149
VIP 192.155.142.100
首先关闭selinux和firewalld
getenforce 0 && systemctl stop firewalld && systemctl disable firewalld
1.web1 web2 安装httpd服务
web1 (web 2 与1相同)
[root@node1 ~]# yum install httpd -y[root@node1 ~]# systemctl start httpd[root@node1 ~]# systemctl status httpd● httpd.service - The Apache HTTP ServerLoaded: loaded (/usr/lib/systemd/system/httpd.service; disabled; vendor preset: disabled)Active: active (running) since Wed 2020-03-25 09:16:23 EDT; 1min 18s agoDocs: man:httpd(8)man:apachectl(8)Process: 16096 ExecStop=/bin/kill -WINCH ${MAINPID} (code=exited, status=0/SUCCESS)Main PID: 16101 (httpd)Status: "Total requests: 0; Current requests/sec: 0; Current traffic: 0 B/sec"CGroup: /system.slice/httpd.service├─16101 /usr/sbin/httpd -DFOREGROUND├─16103 /usr/sbin/httpd -DFOREGROUND├─16104 /usr/sbin/httpd -DFOREGROUND├─16105 /usr/sbin/httpd -DFOREGROUND├─16106 /usr/sbin/httpd -DFOREGROUND└─16107 /usr/sbin/httpd -DFOREGROUND
2.在修改index.html文件
[root@node1 ~]# echo "this is $HOMENAME" > /var/www/html/index.html[root@node1 ~]# cd /var/www/html/[root@node1 html]# lsindex.html[root@node1 html]# cat index.htmlthis is node1
3.重新开始httpd,并进行测试
[root@node1 html]# systemctl restart httpd
[root@node1 html]# curl 192.168.10.138
this is node1
二、配置nginx负载均衡
在proxy1,proxy2上进行
(proxy2的配置与proxy上的步骤相同)
1.在proxy1 上 安装nginx
yum install nginx -y
2.配置nginx
vim proxy.server.conf
upstream webserver{
server 192.168.10.138; #web1的地址
server 192.168.10.140; #web2的地址
}
server {
listen 8080; #监听端口
server_name 192.168.10.144; #proxy的地址
location / {
proxy_pass http://webserver;
}
}
3.重启nginx,并且进行测试
systemctl restart nginx
nginx -s reload
显示结果如下,说明配置成功
[root@node4 conf.d]# curl 192.168.10.144:8080
this is node1
[root@node4 conf.d]# curl 192.168.10.144:8080
this is node3
三、配置Keepalived
1.安装keepalived
yum install keepalived -y
2.在proxy1和proxy2上分别执行下面的脚本
#!/bin/bash
yum install keepalived -y
mv /etc/keepalived/keepalived.conf{,.bak}
cat > /etc/keepalived/keepalived.conf << EOF
! Configuration File for keepalived
global_defs {
router_id node1 # node2修改
}
vrrp_instance VI_1 {
state MASTER # node2节点BACKUP
interface ens33
virtual_router_id 10
priority 100 # node2节点小于100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.10.100
}
}
EOF
具体操作
vim keepalived.sh #新建一个keepalived.sh
##写入以下内容
#!/bin/bash
mv /etc/keepalived/keepalived.conf{,.bak} ## 将之前的配置文件备份一下
cat > /etc/keepalived/keepalived.conf << EOF
! Configuration File for keepalived
global_defs {
router_id node1
}
vrrp_instance VI_1 {
state MASTER
interface ens34
virtual_router_id 10
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.10.100
}
}
EOF
[root@node4 ~]#chmod +x keepalived.sh #赋予执行的权限
[root@node4 ~]#./keepalived.sh #执行这个文件
修改配置文件中的内容
[root@node4 ~]# cd /etc/keepalived
[root@node4 keepalived]# lskeepalived.conf keepalived.conf.bak
[root@node4 keepalived]# vim keepalived.conf
! Configuration File for keepalived
global_defs {
router_id node4 #这个node的名称
}
vrrp_instance nginx_group { #VRRP组的名称
state MASTER #Master状态
interface ens34 #192.168.10.144 所在的网卡接口的名称
virtual_router_id 10
priority 100 #默认优先级
advert_int 1
authentication { #认证
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.155.142.100 #VIP的地址
}
}
~
proxy2最后的配置文件为
! Configuration File for keepalived
global_defs {
router_id node5 #node名称
}
vrrp_instance ngxin_group { #所在vrrp组的名称
state BACKUP #状态 为backup状态
interface ens34 #192.168.10.149所在的网卡的接口
virtual_router_id 10
priority 98 #优先级要低于100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { #VIP的地址
192.155.142.100
}
}
3.分别在proxy1和proxy2上启动keepalived服务
systemctl restart keepalived
proxy1的状态
proxy2的状态
VIP地址在proxy1上
实现主机网络的高可用,检测主机kp服务和是否down
四、测试
1.在浏览器上访问 VIP的地址+监听的端口,刷新之后在node1和node3之间变换

2.模拟故障: 关闭proxy1 节点或者停止proxy1 上的kp服务,VIP地址是否漂移到node2
在proxy1上,关闭keepalived
[root@node4 keepalived]# systemctl stop keepalived
在浏览器上看,Keepalived还是工作正常的
观察proxy2上keepalived的状态
代替proxy1 成为了MASTER,承担起它的任务,这是因为VRRP开启了抢占模式(默认是开启的)
VIP地址漂移到了proxy2上
关于Nginx的检测
如果Nginx宕机,会导致用户请求失败,但是Keepalived并不会进行地址漂移
配置检测脚本来进行检测
1.判断nginx的进程数量,判断是否正常,0为不正常,1为正常
#!/bin/bash
A=`ps -C nginx --no-header |wc -l`
if [ $A -eq 0 ];then
systemctl start nginx
if [ `ps -C nginx --no-header |wc -l` -eq 0 ];then
exit 1
else
exit 0
fi
else
exit 0
fi
[root@node4 ~]# ps -C nginx —no-header |wc -l #查看nginx进程数
3
[root@node4 ~]# systemctl stop nginx
[root@node4 ~]# ps -C nginx —no-header |wc -l
0
[root@node4 bin]# cd /usr/local/bin
[root@node4 bin]# ls
nginx_check.sh
[root@node4 bin]# chmod +x nginx_check.sh
2.把相关的配置配置到keepalived当中去。去检测脚本,服务的健康检查
[root@node4 bin]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id node4
}
vrrp_script chk_http_port {
script "/usr/local/bin/nginx_check.sh" ##脚本要有可执行权限
interval 1
weight -5 #减后的优先级要小于backup的优先级,开启抢占模式
}
vrrp_instance nginx_group {
state MASTER
interface ens34
virtual_router_id 10
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
# 调用script脚本
track_script {
chk_http_port
}
virtual_ipaddress {
192.155.142.100
}
}
尝试着关闭nginx,观察Keepalived的相关信息
keepalived目前可以检测主机服务是否down,不能检测nginx,需要用nginx检测脚本
web关掉,nginx正常
nginx后端的健康检测是由nginx自己做的
Keepalived + Haproxy + MySQL
mysql:主主模型 做双主数据库的高可用
环境准备:
node haproxy 192.168.10.144
node haproxy 192.168.10.149
MYSQL 1:192.168.10.138 node1
MYSQL2: 192.168.10.151 node3
VIP :192.155.142.99
一、MySQL 主主配置
在node1和node2上执行下面的脚本
#!/bin/bash
Ip_addr="192.168.10.40" # 修改为对端的node地址
User_pwd="000000" #**做slave操作的时候需要有密码**
systemctl stop firewalld
setenforce 0
yum install mariadb-server -y
sed -i '/^\[mysqld\]$/a\binlog-ignore = information_schema' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\binlog-ignore = mysql' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\skip-name-resolve' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\auto-increment-increment = 1' /etc/my.cnf.d/server.cnf # 注意node3节点上必须不同 自动增量
sed -i '/^\[mysqld\]$/a\log-bin = mysql-bin' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\auto_increment_offset = 1' /etc/my.cnf.d/server.cnf # 注意node3节点上必须不同 自动增量偏移
sed -i '/^\[mysqld\]$/a\server-id = 1' /etc/my.cnf.d/server.cnf # 注意node4节点上必须不同 ID
systemctl restart mariadb
前提,关闭selinux和firewalld
1.在node1上进行
vim mysqlmaster.sh
## 写入以下内容
#!/bin/bash
Ip_addr="192.168.10.151" #对端的IP地址
User_pwd="000000"
yum install mariadb-server -y
sed -i '/^\[mysqld\]$/a\binlog-ignore = information_schema' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\binlog-ignore = mysql' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\skip-name-resolve' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\auto-increment-increment = 1' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\log-bin = mysql-bin' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\auto_increment_offset = 1' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\server-id = 1' /etc/my.cnf.d/server.cnf
systemctl restart mariadb
mysql -uroot -e "grant replication slave on *.* to 'repuser'@'$Ip_addr' identified by '$User_pwd';"
之后用scp传输一份到192.168.10.151上
[root@node1 ~]# scp mysqlmaster.sh 192.168.10.151:/root/
执行脚本文件
[root@node1 ~]# chmod +x mysqlmaster.sh
[root@node1 ~]# ./mysqlmaster.sh
2.在node2上,修改mysqlmaster.sh的内容
[root@node2 ~]# cat mysqlmaster.sh
#!/bin/bash
Ip_addr="192.168.10.138" ##这个地址
User_pwd="000000"
yum install mariadb-server -y
sed -i '/^\[mysqld\]$/a\binlog-ignore = information_schema' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\binlog-ignore = mysql' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\skip-name-resolve' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\auto-increment-increment = 2' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\log-bin = mysql-bin' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\auto_increment_offset = 2' /etc/my.cnf.d/server.cnf
sed -i '/^\[mysqld\]$/a\server-id =2' /etc/my.cnf.d/server.cnf
systemctl restart mariadb
mysql -uroot -e "grant replication slave on *.* to 'repuser'@'$Ip_addr' identified by '$User_pwd';"
执行脚本文件
[root@node2 ~]# chmod +x mysqlmaster.sh
[root@node2 ~]# sh mysqlmaster.sh
3.检查mariadb状态和日志状态
4.查看master状态
node1
[root@node1 ~]# mysql -uroot
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 3
Server version: 5.5.64-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> show master status;
+------------------+----------+--------------+--------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+--------------------------+
| mysql-bin.000003 | 403 | | mysql,information_schema |
+------------------+----------+--------------+--------------------------+
1 row in set (0.00 sec)
node 2
[root@node2 ~]# mysql -uroot
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 3
Server version: 5.5.64-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> show master status;
+------------------+----------+--------------+--------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+--------------------------+
| mysql-bin.000003 | 408 | | mysql,information_schema |
+------------------+----------+--------------+--------------------------+
1 row in set (0.00 sec)
4.在node1上,执行命令
MariaDB [(none)]> change master to master_host='192.168.10.151',master_port=3306,master_user='repuser',master_password='000000',master_log_file='mysql-bin.000003',master_log_pos=408;
###让master成为某个节点的从节点,master_host地址需要修改,master_log_pos需要进行修改
MariaDB [mysql]> start slave;
node2上
MariaDB [(none)]> change master to master_host='192.168.10.138',master_port=3306,master_user='repuser',master_password='000000',master_log_file='mysql-bin.000003',master_log_pos=403;
MariaDB [mysql]> start slave;
检查slave状态,观察IO和SQL线程是否为YES
测试:
在node1上创建mydb数据库
MariaDB [(none)]> create database mydb;在node2上在test数据库中创建test表
MariaDB [(none)]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mydb | | mysql | | performance_schema | | test | +--------------------+ MariaDB [(none)]> use mydb; Database changed MariaDB [mydb]> create table stu(id int(4),name varchar(10)); Query OK, 0 rows affected (0.09 sec)最终要实现node1和node2上保持数据同步
在node1上进行查看,是否与node2上的数据同步MariaDB [(none)]> use mydb; MariaDB [mydb]> show tables; +----------------+ | Tables_in_mydb | +----------------+ | stu | +----------------+ 1 row in set (0.00 sec) MariaDB [mydb]> desc stu; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | int(4) | YES | | NULL | | | name | varchar(10) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 2 rows in set (0.01 sec)
二、完成haproxy对双主模型的负载均衡
在node4 和node5上面 执行脚本
#!/bin/bash
yum install haproxy -y
mv /etc/haproxy/haproxy.cfg{,.bak}
cat > /etc/haproxy/haproxy.cfg << EOF
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
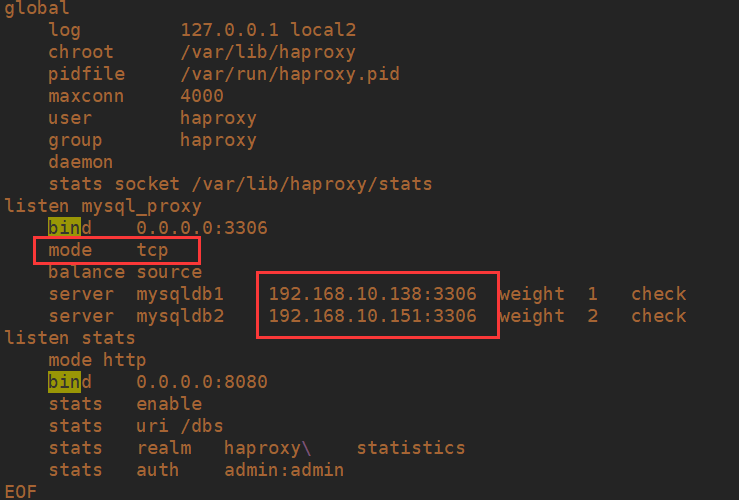
listen mysql_proxy
bind 0.0.0.0:3306
mode tcp
balance source
server mysqldb1 192.168.10.138:3306 weight 1 check
server mysqldb2 192.168.10.151:3306 weight 2 check
listen stats
mode http
bind 0.0.0.0:8080
stats enable
stats uri /dbs
stats realm haproxy\ statistics
stats auth admin:admin
EOF
systemctl start haproxy
在node4上
[root@node4 ~]# vim haproxy.sh
[root@node4 ~]# scp haproxy.sh 192.168.10.149:/root/
[root@node4 ~]# chmod +x haproxy.sh
[root@node4 ~]# ./haproxy.sh
在node5上
[root@node5 ~]# chmod +x haproxy.sh
[root@node5 ~]# ./haproxy.sh
在node3和node5上分别检测端口
[root@node4 ~]# ss -tanl | grep 8080
LISTEN 0 128 *:8080 *:*
[root@node4 ~]# ss -tanl | grep 3306
LISTEN 0 128 *:3306 *:*
测试
- 创建一个test用户远程访问
#node 1 或者node2 上创建一个名为test,密码000000的用户 MariaDB [mydb]> grant all privileges on *.* to "test"@"%" identified by "000000";
2.使用test用户从远程连接 192.168.10.144/149 (连接的haproxy对外的地址)

连接成功,如下
监控
访问192.168.10.144/149:8080/dbs 登录用户明密码都是admin

三、Keepalived相关配置实现haproxy的高可用
1.在node4上,vim /etc/keepalived/keepalived.conf,在里面添加下面的内容
vrrp_instance haproxy_group {
state BACKUP
interface ens34
virtual_router_id 20
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.155.142.99
}
}
2.在node5上, vim /etc/keepalived/keepalived.conf,
vrrp_instance haproxy_group {
state MASTER
interface ens34
virtual_router_id 20
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.155.142.99
}
}
node5是MASTER,地址在node5上

测试:
1.远程连接,通过192.155.142.99连接
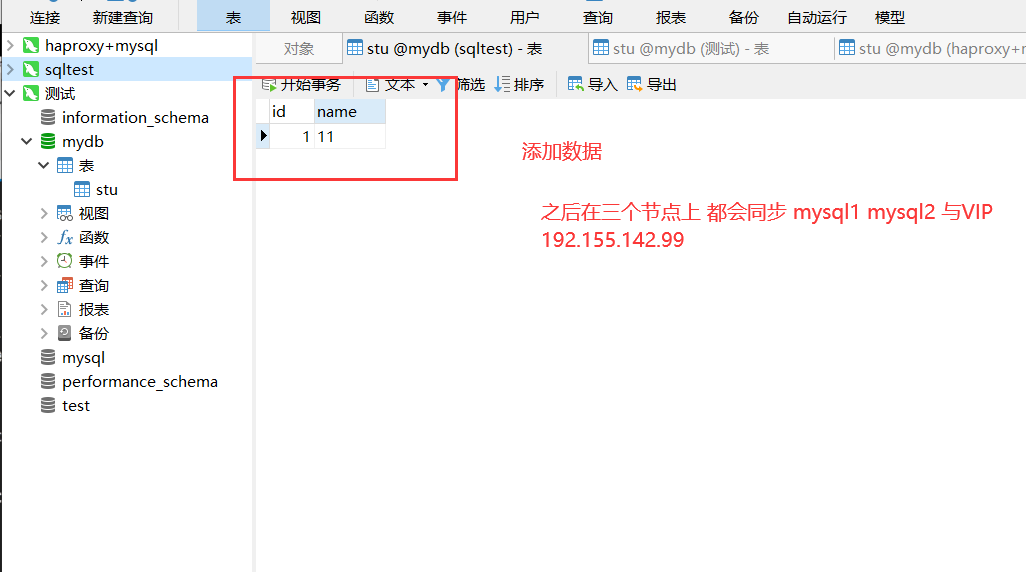
在node1 上进行验证
2.健康检查需要做:同nginx脚本;并且尝试着关闭 haproxy服务发现地址是否漂移
node5上
[root@node5 keepalived]# systemctl stop keepalived

VRRP组
VRRP组: 定义多个组;都可以拥有自己的VIP地址和策略
- haproxy : node4 master node5 backup
- nginx: node5 master node4 backup
充分利用主机资源; nginx —> node4 ; haproxy —-> node25Keepalived + LVS-DR
可以调用ipvsadm工具来创建虚拟服务器,管理服务器池,而不仅仅用来做双击热备
优势体现在:对LVS负载调度器实现热备切换,提高可用性,对服务器池中的节点进行健康检查,自动移除失效节点,恢复后再重新加入。在基于LVS-Keepalived实现的LVS群集结构中,至少包括两台热备的负载调度器,两台以上的节点服务器,本例将以DR模式的LVS群集为基础,增加一台从负载调度器,使用Keepalived来实现主、从调度器的热备,从而构建建有负载均衡、高可用两种能力的LVS网站群集平台。
环境准备
node1(DS1):192.168.10.144
node2(DS2):192.168.10.149
node3(RS1):192.168.10.151
node4(RS2):192.168.10.138
VIP:192.168.10.98(单主模型)
首先node1和node2要在httpd的基础上
[root@node2 html]# curl 192.168.10.138
this is node1
[root@node2 html]# curl 192.168.10.151
this is node2
一、RS的部署
1.在node1和node2上进行执行脚本
node1上
[root@node1 ~]# vim lvs_dr.sh
#!/bin/bash
yum install net-tools -y
vip="192.168.10.98"
mask="255.255.255.255"
ifconfig lo:0 $vip broadcast $vip netmask $mask up
route add -host $vip lo:0
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce
[root@node1 ~]# scp lvs_dr.sh 192.168.10.151:/root/
[root@node1 ~]# chmod +x lvs_dr.sh
[root@node1 ~]# ./lvs_dr.sh
node2上
[root@node2 ~]# ls
anaconda-ks.cfg lvs_dr.sh mysqlmaster.sh
[root@node2 ~]# chmod +x lvs_dr.sh
[root@node2 ~]# ./lvs_dr.sh
2.在node1和node2上分别进行检查,看是否有地址为VIP地址的环回口
[root@node1 ~]# ip a | grep glo
inet 192.168.10.98/32 brd 192.168.10.98 scope global lo:0
inet 192.155.142.162/24 brd 192.155.142.255 scope global noprefixroute dynamic ens33
inet 192.168.10.138/24 brd 192.168.10.255 scope global noprefixroute dynamic ens34
二、DR相关配置(Keepalived中)
配置文件
[root@node1 keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
router_id node1 # 设置lvs的id,一个网络中应该唯一
}
vrrp_instance VI_1 {
state MASTER # 指定Keepalived的角色
interface ens33 # 网卡
virtual_router_id 10 # 虚拟路由器ID,主备需要一样
priority 100 # 优先级越大越优,backup路由器需要设置比这小!
advert_int 1 # 检查间隔1s
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.10.99 # 定义虚拟IP地址,可以定义多个
}
}
# 定义虚拟主机,对外服务的IP和port
virtual_server 192.168.10.99 80 { #VIP地址
delay_loop 6 # 设置健康检查时间,单位是秒
lb_algo wrr # 负责调度算法
lb_kind DR # LVS负载均衡机制
persistence_timeout 10
protocol TCP
# 指定RS主机IP和port
real_server 192.168.10.138 80 {
weight 2
# 定义TCP健康检查
TCP_CHECK {
connect_timeout 10
nb_get_retry 3
delay_before_retry 3
connect_port 80
}
}
real_server 192.168.10.151 80 {
weight 1
TCP_CHECK {
connect_timeout 10
nb_get_retry 3
delay_before_retry 3
connect_port 80
}
}
}
具体操作
在node4上
[root@node4 ~]# yum install ipvsadm -y
[root@node4 ~]# cd /etc/keepalived
[root@node4 keepalived]# mv keepalived.conf{,.bak2} #将之前的配置文件备份
[root@node4 keepalived]# vim keepalived.conf
[root@node4 keepalived]# scp keepalived.conf 192.168.10.149:/etc/keepalived/
[root@node4 keepalived]# vim keepalived.conf
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.10.98 #与之前RS上的IP保持一致
}
}
# 定义虚拟主机,对外服务的IP和port
virtual_server 192.168.10.98 80 {
delay_loop 6
lb_algo wrr
lb_kind DR
persistence_timeout 0
protocol TCP
# 指定RS主机IP和port
real_server 192.168.10.138 80 {
weight 2
# 定义TCP健康检查
TCP_CHECK {
connect_timeout 10
nb_get_retry 3
delay_before_retry 3
connect_port 80
}
}
real_server 192.168.10.151 80 {
weight 1
TCP_CHECK {
connect_timeout 10
nb_get_retry 3
delay_before_retry 3
connect_port 80
}
}
}
[root@node4 keepalived]# systemctl restart keepalived
##检查规则是否生效
[root@node4 keepalived]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.10.99:80 wrr
-> 192.168.10.138:80 Route 2 0 0
-> 192.168.10.151:80 Route 1 0 0
分别检查一下status和glo
ss -tanl | grep 80 不显示80端口
报错:Unknown keyword ‘nb_get_retry’
Mar 26 22:16:47 node5 Keepalived_healthcheckers[7113]: Unknown keyword ‘nb_get_retry’
测试
- 关闭node4,VIP地址会漂移到node5上
- 查看ipvsadm 策略
[root@node4 ~]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.10.98:80 wrr persistent 10
-> 192.168.10.138:80 Route 2 0 0
-> 192.168.10.151:80 Route 1 0 0
(当关闭后端web服务的时候)
[root@node1 keepalived]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.10.98:80 wrr
-> 192.168.10.151:80 Route 1 0 0 **

若有收获,就点个赞吧
0 人点赞
