介绍
Redis是一个开源的key-value(键值)数据库。和Memcached类似,支持存储的value相对更多,包括string(字符串)、list(列表)、set(集合)、zset(sorted set 有序集合)和hash(哈希类型)。这些数据类型都支持push/pop,add/remove及取交集和差集等丰富的操作,这些操作都是原子性的。在此基础上,redis支持各种不同方式的排列。
数据都是缓存在内存中的,redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现master-slave(主从)同步。
特点
1.速度快
2.支持丰富数据类型,支持事务
3.工作模型:单线程+IO多路复用(epoll)+存储在内存中
4.持久化存储
5.集群方案
redis性能高的原因?
1.纯内存操作
redis是一个内存数据库,数据都存储在内存中,读写数据都是在内存中进行的,速度很快。
redis是一个KV内存数据库,内部构建了一个哈希白哦,根据指定的KEY访问的时候,只需要O(1)的时间复杂度就可以找到对应的数据。同时redis有丰富的数据类型,并使用高效的方式进行操作,操作都在内存中进行,不会大量消耗CPU资源,所以速度很快。
2.使用IO多路复用技术
redis采用IO多路复用和非阻塞IO,这个技术由操作系统提供,redis只需要操作系统的API就可以。
reids在单线程中监听多个socket的请求,在任意一个socket可读/可写的时候,redis去读取客户端请求,在内存中操作对应的数据,然后再写回到socket中,只针对有活动的socket采取反应。
3.非CPU密集型任务
redis的大部分操作不是CPU密集型操作,redis的瓶颈在于内存和网络带宽。
在高并发情况下,redis需要更多的内存和更高的网络带宽,可以部署多个redis节点,组成集群的方式来利用多核CPU的能力,而不是在单个实列上使用多线程来处理。
4.单线程
严格来说,Redis server是多线程的,只是它的请求处理整个流程是单线程处理的。
单线程的优点:
没有了多线程上下文切换的性能损耗
没有了访问共享资源加锁的性能损耗
开发和调试非常友好,可维护性高
缺点:
如果前一个请求发生耗时比较久的操作,那么整个redis就会阻塞住,其他请求也无法进来,知道这个耗时久的操作处理完成并返回,其他操作才能被处理到。
应用场景
1.缓存
2.排行系统
3.统计器应用
4.社交网络
5.消息队列系统
6.热数据(冷数据一般不要用redis)
安装与启动
安装
- 安装:二进制安装、yum包安装
[root@localhost ~]# yum install redis -y如果安装不了,换源[root@localhost ~]# wget http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm安装epel:[root@localhost ~]# rpm -ivh epel-release-6-8.noarch.rpmwarning: epel-release-6-8.noarch.rpm: Header V3 RSA/SHA256 Signature, key ID 0608b895: NOKEYPreparing... ################################# [100%]Updating / installing...1:epel-release-6-8
配置文件
[root@localhost ~]# rpm -ql redis
/etc/logrotate.d/redis
/etc/rc.d/init.d/redis
/etc/rc.d/init.d/redis-sentinel
/etc/redis-sentinel.conf
/etc/redis.conf #主配置文件
/etc/security/limits.d/95-redis.conf
/usr/bin/redis-benchmark #redis性能检测工具
/usr/bin/redis-check-aof #AOF文件检测工具
/usr/bin/redis-check-rdb #RDB文件检测工具
/usr/bin/redis-cli #redis客户端
/usr/bin/redis-sentinel
/usr/bin/redis-server #redis服务端
/usr/libexec/redis-shutdown
/usr/share/doc/redis-3.2.12
/usr/share/doc/redis-3.2.12/00-RELEASENOTES
/usr/share/doc/redis-3.2.12/BUGS
/usr/share/doc/redis-3.2.12/CONTRIBUTING
/usr/share/doc/redis-3.2.12/COPYING
/usr/share/doc/redis-3.2.12/MANIFESTO
/usr/share/doc/redis-3.2.12/README.md
/usr/share/man/man1/redis-benchmark.1.gz
/usr/share/man/man1/redis-check-aof.1.gz
/usr/share/man/man1/redis-check-rdb.1.gz
/usr/share/man/man1/redis-cli.1.gz
/usr/share/man/man1/redis-sentinel.1.gz
/usr/share/man/man1/redis-server.1.gz
/usr/share/man/man5/redis-sentinel.conf.5.gz
/usr/share/man/man5/redis.conf.5.gz
/var/lib/redis
/var/log/redis
/var/run/redis
启动redis服务
[root@localhost ~]# systemctl start redis
连接redis服务端
默认监听的端口6379
redis-cli [OPTIONS] [cmd [arg [arg …]]]
[root@redis_server ~]# cat /etc/redis.conf | grep -Ev "^$|^#"
bind 127.0.0.1 #redis服务端监听地址
protected-mode yes
port 6379 #监听端口
tcp-backlog 511 #tcp全连接数
timeout 0 #设置客户端连接超时时间
tcp-keepalive 300 #tcp长连接超时时间
daemonize no #是否允许再后台允许
supervised no #supervised管理是否打开
pidfile /var/run/redis_6379.pid #redis服务的pid文件位置
loglevel notice #日志等级记录
logfile /var/log/redis/redis.log #日志存放位置
databases 16
# 自动触发rdb持久化存储的策略: 900s -> w1 ; 300s -> w10 ; 60s - 10000
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes # bgsave(手动触发rdb持久化存储) 命令执行失败,停止写入
rdbcompression yes #rdb文件压缩(RDB文件有自己二进制压缩机制)
rdbchecksum yes #rdb文件校验
dbfilename dump.rdb #rdb文件名称
dir /var/lib/redis #redis服务目录
slave-serve-stale-data yes
slave-read-only yes #当此节点作为哦slave的时候开启只读
## master-slave之间的复制策略
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
slave-priority 100 #slave优先级
appendonly no #没有开启aof持久化存储
appendfilename "appendonly.aof" #aof文件名称
appendfsync everysec #aof追加同步磁盘策略
no-appendfsync-on-rewrite no #是否触发重写操作
# 自动触发aof策略: 如果达到64mb 立马进行重写,下次重写会对比上次重写的文件大小2倍
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
lua-time-limit 5000 # lua脚本执行超时时间
slowlog-log-slower-than 10000 #慢日志设定时间
slowlog-max-len 128 #慢日志记录时间
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
#数据类型底层编码的一些策略: 相同的数据类型,底层数据结构编码方式可以不同
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
activerehashing yes
# 客户端输出缓冲区限制 策略
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
# 内存回收策略: 定时删除过期任务每s运行次数
hz 10
aof-rewrite-incremental-fsync yes
Redis基本数据类型
String
操作:
设置键值: SET key value [EX seconds] [PX milliseconds] [NX|XX]
SETNX:如果键存在则不设置其值
MSET:批量设置键值
exists key:判断key是否存在,若存在返回1,若不存在返回0
获取键值:GET key
MGET:批量获取键值
获取键值的生存时间:TTL key 当ttl<=0的时候,k-v不存在
为键对应的数值进行加减操作:(必须是数值才能进行下面的操作)
incr key:+1
decr key:-1
incrby key N:+N,为k所对应的数值+increment(增量)
decrby key N: -N,为k所对应的数值-increment(减量)
mget批量操作命令可以有效提高开发效率,注意网络成为性能瓶颈(字符串不能操作512MB)
内部编码:
int:8bytes长整型
embstr:小于或等于39bytes的字符串
raw:大于39bytes的字符串
使用object encoding key 命令获取编码类型
[root@node1 ~]# redis-cli
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379> mset k1 v11 k2 v2 k3 v33
OK
127.0.0.1:6379> mget k2 k2 k3
1) "v2"
2) "v2"
3) "v33"
127.0.0.1:6379> get k1
"v11"
127.0.0.1:6379> exists k1
(integer) 1
127.0.0.1:6379> set k5 5
OK
127.0.0.1:6379> incr k5
(integer) 6
127.0.0.1:6379> decr k5
(integer) 5
127.0.0.1:6379> incrby k5 5
(integer) 15
127.0.0.1:6379> decrby k5 5
(integer) 10
127.0.0.1:6379>
127.0.0.1:6379> object encoding k1
"embstr"
127.0.0.1:6379> object encoding k5
"int"
使用场景
1.缓存功能:加速读写和降低后端压力的作用
2.计数:视频播放次数等
3.共享session:分布式web服务器需要将用户的sessionn信息保存再各自服务器中
4.限速:限制用户每分钟给获取验证码的频率
Hash
键值本身又是一个键值对的结构
操作
设置: HSET key field value #key:键 field:字段 value:值
获取: HGET key field
获取键的所有字段值: HGETALL key
获取键的所有字段:HKEYS *
获取键的所有字段长度:HLEN
删除: HDEL key field
判断给定字段是否在所对应的键中:在返回1;不在返回0
HEXISTS key field
[root@node1 ~]# redis-cli
127.0.0.1:6379> hset a k1 v1
(integer) 1
127.0.0.1:6379> hget a k1
"v1"
127.0.0.1:6379> hkeys a
1) "k1"
127.0.0.1:6379> hlen a
(integer) 1
127.0.0.1:6379> hexists a k1
(integer) 1
127.0.0.1:6379> hexists a k2
(integer) 0
127.0.0.1:6379> hdel a k1
(integer) 1
127.0.0.1:6379> hexists a k1 #删除之后,显示不存在
(integer) 0
内部编码
ziplist:压缩列表;当哈希类型元素个数小于hash-max-ziplist-entries配置默认(512个)和所有小于hash-max-ziplist-vlaue配置默认(64bytes)时,会使用ziplist内部编码
hashtable:哈希表,当无法满足ziplist的条件的时候,会使用hashtable作为哈希的内部实现
使用场景
1.关系型数据库表保存用户信息
2.使用哈希类型缓存用户信息
ps:哈希类型是稀疏的,关系型数据库是完全结构化的。
eg:哈希类型每个键可以有不同的field,而关系型数据库一旦添加新的列,所有行都要为其设置值
缓存用户信息的方法
1.原生字符串操作:简单直观,每个属性都支持更新操作,但占用更多的键,内存占用量较大,同时用户信息内聚性较差(生产环境一般不用)
2.序列化字符串类型:简化编程,但序列化和反序列化有一定的开销,同时每次更新属性都需要把全部数据取出进行反序列化,更新后再序列化到redis中
3.哈希类型:简单直观,但是hashtable会消耗更多的内存
List
用来存储多个有序的字符串(元素),最多存储2^32-1个元素(可以充当栈和队列的角色)
操作
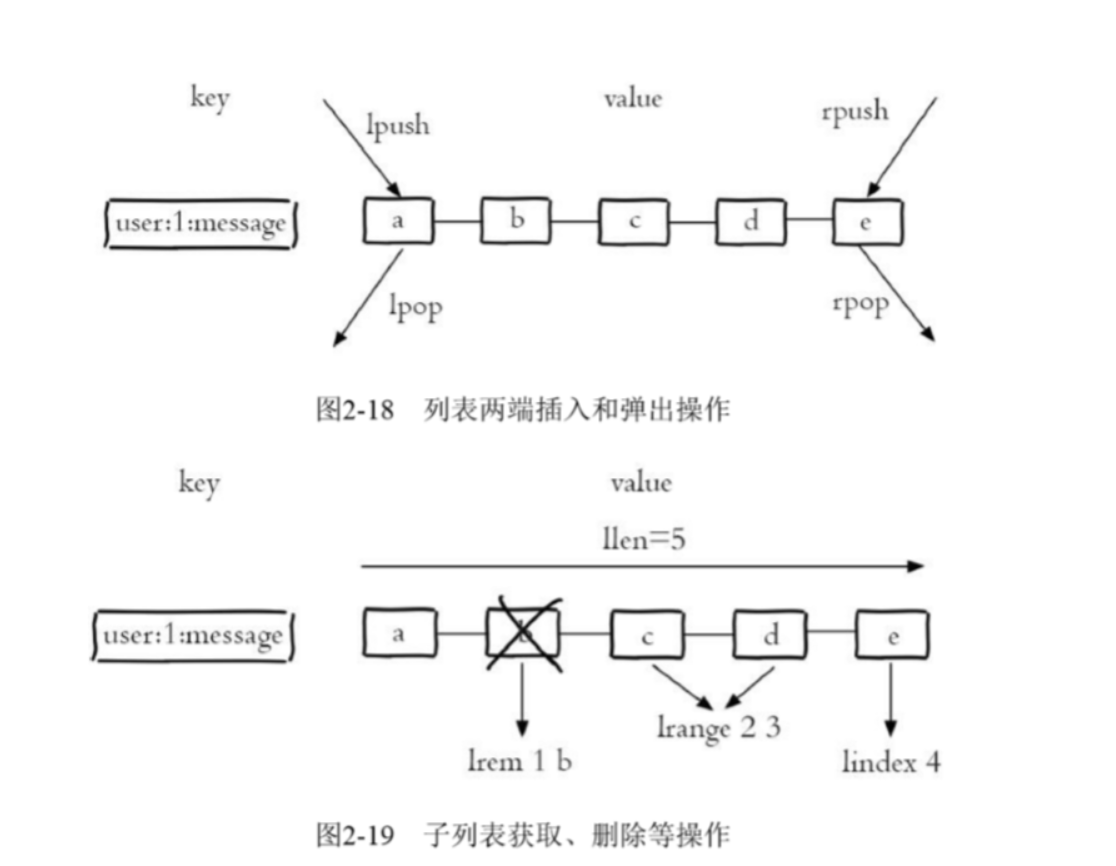
添加值:
lpush key valus…
lpushx : 仅当key存在时才能够在列表头部进行添加
rpush key valus…
删除值:
lpop key
rpop key
获取列表中元素:
lrange start stop
根据索引设置列表中的值:
lset key index value
获取索引所对应的值:
lindex key index
[root@node1 ~]# redis-cli
127.0.0.1:6379> lpush list1 v1 v2 v3 v4
(integer) 4
127.0.0.1:6379> lpushx list1 v5
(integer) 5
127.0.0.1:6379> lrange list1 0 4
1) "v5"
2) "v4"
3) "v3"
4) "v2"
5) "v1"
127.0.0.1:6379> rpush list1 v7 v7
(integer) 5
127.0.0.1:6379> lrange list1 0 -1
1) "v4"
2) "v3"
3) "v2"
4) "v7"
5) "v7"
127.0.0.1:6379> lpop list1
"v5"
127.0.0.1:6379> lrange list1 0 -1
1) "v4"
2) "v3"
3) "v2"
4) "v1"
127.0.0.1:6379> rpop list1
"v1"
127.0.0.1:6379> lrange list1 0 -1
1) "v4"
2) "v3"
3) "v2
127.0.0.1:6379> lset list1 3 v44
OK
127.0.0.1:6379> lrange list1 0 -1
1) "v4"
2) "v3"
3) "v2"
4) "v44"
5) "v7"
127.0.0.1:6379> lindex list1 0
"v4"
内部编码
ziplist:压缩列表;当哈希类型元素个数小于hash-max-ziplist-entries配置默认(512个)和所有值小于 hash-max-ziplist-value配置默认(64bytes)时,会使用ziplist内部编码
linkedlist:链表;当无法满足ziplist的条件时,会使用linkedlist作为列表的内部实现
使用场景
消息队列:redis的push+brpop命令组合即可使用实现阻塞队列
文件列表:每篇文章使用哈希存储,然后将哈希加入到列表中
开发口诀
lpush + lpop = Stack
lpush + rpop = Queue
lpush + ltrim = Capped Collection(有限集合)
lpush + brpop = Message Queue
Set
用来保存多个字符串元素,但集合中不允许有重复元素,最多存储2^32-1个元素
操作
添加:sadd key value
判断集合中的元素:scard key
差集:sdiff key1 key2
交集:sinter key1 key2
并集:sunion key1 key2
查看集合中的元素:smembers key
删除集合中的元素:spop key [count](随机删除)
移除集合中的元素:srem key
127.0.0.1:6379> sadd set1 12 32 45 ddd 43 djj kljl hjfhj
(integer) 4
127.0.0.1:6379> sadd set2 dhhh 12 34 djj
(integer) 4
127.0.0.1:6379> scard set1
(integer) 8
127.0.0.1:6379> sdiff set1 set 2
1) "43"
2) "32"
3) "45"
4) "12"
5) "djj"
6) "kljl"
127.0.0.1:6379> sinter set1 set2
1) "12"
2) "djj"
127.0.0.1:6379> sunion set1 set2
1) "12"
2) "32"
3) "43"
4) "45"
5) "djj"
6) "dhhh"
7) "kljl"
8) "34"
127.0.0.1:6379> spop set1
"hjfhj"
127.0.0.1:6379> srem set1 ddd
(integer) 1
127.0.0.1:6379> smembers set1
1) "12"
2) "32"
3) "43"
4) "45"
5) "djj"
6) "kljl"
内部编码
intset:整数集合;当集合中的元素小于set-max-intset-entries配置(默认512个)
hashtable:哈希表;当集合类型无法满足intset条件时
使用场景
标签:一个用户喜欢娱乐和体育,另一个用户喜欢历史和新闻,有这些数据就可以得到喜欢同一个标签的用
注意:用户和标签的关系维护应该在一个事务内执行,防止部分命令失败造成的数据不一致
Zset 有序集合
保留集合不能有重复成员的特性,但有序集合中的元素可以排序

操作
添加:zadd key score member
判断有序集合中的元素个数:zcard key
根据score判断有序集合中的元素:zcount key min max
获取有序集合中的元素:zrange key start stop
获取有序集合中的元素排名:zrank key member
键迁移:migrate命令
遍历所有键:keys命令| scan命令(渐进式,有效防止阻塞)
数据库管理:dbsize命令|select命令|flushdb/flushall命令
[root@node1 ~]# redis-cli
127.0.0.1:6379> zadd zset1 0 a 1 b 3 d 4 f 5 h
(integer) 5
127.0.0.1:6379> zcard zset1
(integer) 5
127.0.0.1:6379> zcount zset1 1 2
(integer) 1
127.0.0.1:6379> zrange zset1 0 -1
1) "a"
2) "b"
3) "d"
4) "f"
5) "h"
127.0.0.1:6379> zrank zset1 d
(integer) 2
127.0.0.1:6379> zrank zset1 h
(integer) 4
内部编码
ziplist:压缩列表,当集合中的元素小于set-max-ziplist-entries配置(默认512个)
skiplist:跳跃表;当集合类型无法满足ziplist条件时
使用场景
Redis持久化存储
RDB持久化存储
介绍
RDB是Redis用来进行持久化的一种方式,就是把当前内存中的数据及快照写入磁盘,也就是Snapshot 快照(数据 库中所有键值对数据)。恢复时是将快照文件直接读到内存里。
优点
1.RDB是一个非常紧凑(compact)的文件,它保存了redis某个时间点上的数据集,这种文件非常适合用于进行备份和灾难恢复
2.生成RDB文件的时候,redis进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作
3.RDB再恢复大数据集的速度比AOF的恢复速度要快
缺点
1.RDB方式数据没办法做到实时持久化/秒数持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作(内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑),频繁执行成本过高(影响性能)
2.RDB文件使用特定二进制格式保存,Redis新老版本之间不兼容
3.在一定间隔时间做一次备份,所有如果redis意外down掉的话,就会丢失最后一次快照后的所有修改(数据有丢失)
4.RDB压缩会消耗CPU资源
触发方式
手动触发:bysave,Redis进程执行fork操作创建子进程,由子进程负责完成后自动结束(save命令被丢弃)
自动触发:主配置文件中save字段
[root@node1 ~]# cat /etc/redis.conf | grep save
# save <seconds> <changes>
# Will save the DB if both the given number of seconds and the given
# In the example below the behaviour will be to save:
# Note: you can disable saving completely by commenting out all "save" lines.
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# save ""
save 900 1
save 300 10
save 60 10000
# (at least one save point) and the latest background save failed.
stop-writes-on-bgsave-error yes
# If you want to save some CPU in the saving child set it to 'no' but
# algorithms (in order to save memory), so you can tune it for speed or
# the configured save points).
# saving process (a background save or AOF log background rewriting) is
# Lists are also encoded in a special way to save a lot of space.
# order to save a lot of space. This encoding is only used when the length and
文件存储位置及存储名称
127.0.0.1:6379> config get dir
1) "dir"
2) "/var/lib/redis" #存放目录
redis服务时,会去 dir 下读取 dbfilename 文件;如果有dbfilename文件则进行数据恢复
通过配置中定义:服务启动的时候可以进行指定dir & dbfilename
服务启动时,热更新配置:
config set dir /path/to/
config set dbfilename value
工作流程

1.执行bgsave命令,redis父进程判断当前是否存在正在执行的子进程,如RDB/AOF子进程,如果存在bgsave命令直接返回
2.父进程执行fork操作创建子进程,fork操作过程中父进程会阻塞,通过infoe status命名查看latest_fork_usec选项,可以获取最近一个fork操作的耗时,单位为微秒
3.父进程完成创建后,bgsave命令返回“Background saving started”信息并不再阻塞父进程,可以继续响应其他命令
4.子进程创建DRB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。执行latestsave命令可以获取最后一次生成RDB的时候,对应info统计的rdb_lst_save_time选项
5.子进程发送信号给父进程表示完成,父进程更新统计信息
恢复数据
将备份文件(dump.rdb)移动到redis安装目录并启动服务即可,redis就会自动加载文件数据至内存。Redis服务在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止
停止RDB持久化
在配置文件redis.conf中,注释掉所有save行来停用保存功能或者之间一个空字符串来实现停用:sava“”
AOF持久化存储
介绍
是通过彼此有你Redis服务器所指向的写命令来记录数据库状态
优点
1.提供了多种的同步频率,即使使用默认的同步频率每s同步一次,redis最多也就丢失1s的数据而已
2.使用redis命令追加的形式来构造。Redis只能向AOF文件写入命令的片段,使用redis-check-aof工具也很容易修正AOF文件
3.AOF文件的格式可读性较强,为使用者提供了更灵活的处理方式。例如,如果我们不小心错用了 FLUSHALL 命令,在重写还没进行时,我们可以手工将最后的 FLUSHALL 命令去掉,然后再使用 AOF 来恢复数据。
缺点
1.对于具有相同数据的redis,AOF文件通常会比RDB文件体积更大
2.默认情况下,每秒同步一次的频率也具有较高的性能。但在Redis的负载较高时,RDB比AOF具有更好的性能保证
3.RDB使用快照的形式来持久化整个Redis数据,而AOF只是将每次执行的命令追加到AOF文件中。从 理论上说,RDB 比 AOF 方式更健壮。官方文档也指出,AOF 的确也存在一些 BUG,这些 BUG 在 RDB 没有 存在。
触发方式
手动触发:bgrewriteaof操作
自动触发: auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
文件存储位置及存储名称
AOF文件存储位置及存储名称:
打开AOF持久化存储1: appendonly no & appendfilename “appendonly.aof”
服务启动时,热更新配置:
127.0.0.1:6379> config set appendonly yes
工作流程

1.所有的写入命令会追加到缓冲区(aof_buf)中
2.AOF缓冲区会将操作命令根据策略向磁盘做同步操作
3.随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩目的
4.当redis服务器重启时,可以加载AOF文件进行数据恢复
AOF 文件同步
Redis提供多种AOF缓冲区同步文件策略,由appendfsync提供
1.always:调用系统fsync操作同步到AOF文件,完成后线程返回 (write -> 缓冲区 -> fsync操作 -> 磁盘上) (可靠性更好,阻塞更长)
2.everysec:调用write操作,完成后线程返回,fsync同步文件操作由专门线程每秒调用一次
相对于 always 和 no 来说:可靠性和效率都有所保证;默认同步策略
3.no:调用write操作,不对AOF文件做fsync同步,同步硬盘操作由操作系统负责,通常同步周期最长30s (write -> 缓冲区后便返回; 缓冲区中的数据同步到磁盘上是由 系统调度机制去完成的)
write操作:会触发延迟写机制,应为Linux在内核提供页缓冲区来提供磁盘IO性能,write操作在写入系统缓冲区后直接返回,同步硬盘依赖于系统调度机制
fsync操作:针对单个文件操作,做强制硬盘同步,fsync将阻塞直到写入硬盘完成后退出,保证了数据持久化
AOF 重写
重写原因:随着命令不断写入AOF,文件会越来越大
AOF文件重写是把Redis进程内的数据转化为命令同步到新AOF文件的过程
重写之后文件变小:
1.进程内已经超时的数据不再写入文件
2.旧的AOF文件包含无效命令,重写使用进程内数据直接生成
3.多条命令可以合并为一
降低文件占用空间,更小的AOF文件更快被Redis加载
触发方式:
手动触发:直接调用bgrewriteaof命令
自动触发:根据auto-aof-rewrite-min-size(表示运行AOF重写时文件小体积,默认为64MB)和autoaof-rewrite-percentage(代表当前AOF文件空间(aof_current_size)和上一次重写后AOF文件空间 (aof_base_size)的比值;可以通过info persistence统计信息查看)参数确定自动触发时机 自动触发时机= 以上两个参数都满足的时候
运作流程
执行AOF重写请求
如果当前进程正在执行AOF重写,此次请求不执行;
如果当前进程正在进行bgsave操作,重写命令延迟到bgsave命令完成之后再执行
1.父进程执行fork创建子进程,开销等同于bgsave进程
2.fork操作完成后,继续响应其他命令,所有修改命令依然写入到AOF缓冲区并根据appendfsync策略同步到硬盘中
3.由fork操作运行写时复制技术,父进程依然响应命令,Redis使用AOF重写缓冲区来保存这部分数据,防止新的AOF文件生成期间丢失这部分数据
4.子进程根据内存快照,按照命令合并规则写入到新的AOF文件,每次批量写入硬盘数据量由aof-rewriteincreamental-fsync控制,默认为32MB,防止单次刷盘数据过多造成硬盘堵塞
5.新的AOF文件写入完成后,子进程发送信号给父进程,父进程更新统计信息
6.父进程把AOF重写缓冲区的数据写入到新的AOF文件
6.使用新的AOF文件替换老的AOF文件,完成AOF重写
AOF 恢复
重启 Redis 之后就会进行 AOF 文件的载入。异常修复命令:redis-check-aof –fix 进行修复
Redis持久化文件加载流程

1.AOF持久化开启且存在AOF文件时,优先加载AOF文件
2.AOF关闭或者AOF文件不存在时,加载RDB文件
3.加载AOF/RDB文件成功后,Redis启动成功
4.AOF/RDB文件存在错误时,Redis启动失败
复制
从节点复制主节点数据,从节点只能够响应读操作
结构:
1.一主一从:当应用写命令并发量高且需要持久化时,可以只在从节点上开启AOF,这样即保证数据安全性又避 免了持久化对主节点的性能干扰
2.一主多重:多个从节点实现读写分离(适合读并发量高场景)
3.树状主从:从节点不但可以复制主节点数据,同时可以作为其他从节点的主节点继续向下层辅助
复制过程

1.保存主节点(master)信息:主节点的IP和port被保存下来
2.从节点(slave)内部通过定时任务维护复制相关逻辑,当定时任务发现新的主节点后,会尝试从该节点建立网络,从节点建立一个socket套接字,于主节点的24555端口连接,专门用于接收主节点发送的复制命令
3.发送ping命名:检测主从之间网络套接字是否可用,检测主节点当前是否可以接收处理命令,如果接收到pong回复或超时,会断开复制连接进行重连(超时的轮询重试是1s)
4.进行权限验证:从节点要去复制主节点数据的时候会有身份验证这个过程,身份验证相关信息可以配置在主节点上
5.同步数据库:首次建立复制,主节点会把持有的数据全部发送给从节点
6.命令持续复制:第一次建立复制之后,主节点会把持续的写命令发送给从节点,保证数据一致性
复制方式
全量复制:Redis全量复制发生在slave节点初始化阶段,从节点将主节点的所有数据复制到本地(第一次复制的时候)<br /> 增量复制:slave初始化后开始正常工作,主节点持续响应用户请求操作,然后同步到本地去执行
主从复制优缺点
优点:备份 读写分离
缺点:
- 如果主节点down掉之后,我们需要人工切换slave节点的新主节点信息(slaveof),无法实现高可用
- 主从复制主节点的写能力有限
- 单机存储容量受限(数据只会存储在master节点上),master节点读操作负载容易变高
同步策略:
主从刚刚建立连接的时候,进行全量复制;全同步之后,进行增量复制。
如果有需要的话,slave在任何时候都可以发起全量同步。
redis的策略:无论如何,先尝试进行增量同步,如果不成功,要求从节点进行全量同步
全量复制过程

1.slave节点会向master节点发送sync命令
2.master节点收到这样的请求时,判断为全量复制响应+FULLRESYNC,包含master节点的runid+offset
3.slave节点接收到响应之后,会保存master节点的信息
4.master节点会执行bgsave命令生成RDB文件
5.将RDB文件发送给slave节点,slave节点收到来自mater节点的RDB文件的时候清除旧的数据,并加载RDB文件
6在生成RDB快照文件及发送RDB文件的过程中,会继续响应客户端请求,所有更新记录都会记录到缓冲区中,当RDB文件发送完成之后,将缓冲区的这些命令发送给slave服务器
7.slave节点执行master发送的缓冲区,完成复制操作
8.判断AOF是否开启,如果开启,立即执行一次bgrewriteaof操作,否则全量复制完成
部分复制过程

1.全量复制的时候,slave节点已经自动保存了主节点的runnid+offset
2.slave和master节点会因为网络波动等丢失了连接
3.此时,master节点会将用户请求操作存储一部分到”复制缓冲区“中
4.网络恢复时,从节点再次连接到主节点
5.slava节点会发送psync 、runid、offset
6.主节点接收这些请求之后,会去比较runnid是否是自己的,然后去判断偏移量offset(200——>因为连接丢失之后,master依旧会响应用户请求,它此时的offset300)就会将100数据最后发往slave节点
7.master节点发送CONTINUE响应
8.将部分数据(100)发往slave节点
主从复制部署
通过配置文件方式
节点规划: 在node1上不同端口上
master:127.0.0.1 6379
slave1: 127.0.0.1 6380
slave2: 127.0.0.1 6381
在生产环境中,要部署在不同的物理机上
redis-6379.conf
[root@node1 ~]# vim redis-6379.conf
daemonize yes #是否开启后台
port 6379 #端口
dir ./
logfile "redis-6379.log"
dbfilename "dump-6379.rdb"
pidfile "/var/run/redis-6379.pid"
redis-6380.conf
[root@node1 ~]# vim redis-6380.conf
daemonize yes
port 6380
dir ./
logfile "redis-6380.log"
dbfilename "dump-6380.rdb"
pidfile "/var/run/redis-6380.pid"
slaveof 127.0.0.1 6379
redis-6381.conf
[root@node1 ~]# vim redis-6381.conf
daemonize yes
port 6381
dir ./
logfile "redis-6381.log"
dbfilename "dump-6381.rdb"
pidfile "/var/run/redis-6381.pid"
slaveof 127.0.0.1 6379
启动三个redis服务,并检测端口
[root@node1 ~]# redis-server redis-6379.conf
[root@node1 ~]# redis-server redis-6380.conf
[root@node1 ~]# redis-server redis-6381.conf
[root@node1 ~]# ps -ef|grep redis-server | grep -v 'grep'
root 10393 1 1 22:00 ? 00:00:00 redis-server *:6379
root 10397 1 0 22:00 ? 00:00:00 redis-server *:6380
root 10402 1 0 22:01 ? 00:00:00 redis-server *:6381
主节点
[root@node1 ~]# redis-cli -h 127.0.0.1 -p 6379 info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=85,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=85,lag=1
master_repl_offset:85
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:84
从节点6380
[root@node1 ~]# redis-cli -h 127.0.0.1 -p 6380 info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_repl_offset:99
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
从节点6381
[root@node1 ~]# redis-cli -h 127.0.0.1 -p 6381 info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:141
slave_priority:10
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
使用 slaveof 建立复制关系
[root@node1 ~]# redis-cli -p 6380
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK Already connected to specified master
[root@node1 ~]# redis-cli -p 6381
127.0.0.1:6381> slaveof 127.0.0.0.1 6379
OK Already connected to specified master
config rewrite 目录重写配置文件:
[root@node1 ~]# redis-cli -p 6380 config rewrite
OK
[root@node1 ~]# cat redis-6380.conf
daemonize yes
port 6380
dir "/root"
logfile "redis-6380.log"
dbfilename "dump-6380.rdb"
pidfile "/var/run/redis-6380.pid"
slaveof 127.0.0.1 6379
断开复制关系
[root@node1 ~]# redis-cli -p 6380 slaveof no one
OK
[root@node1 ~]# redis-cli -p 6379 info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:1373
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:1372
日志分析
[root@node1 ~]# ls
anaconda-ks.cfg dump.rdb redis-6380.conf
dump-6379.rdb epel-release-6-8.noarch.rpm redis-6380.log
dump-6380.rdb redis-6379.conf redis-6381.conf
dump-6381.rdb redis-6379.log redis-6381.log
[root@node1 ~]# cat redis-6379.log #master节点
10393:M 01 Apr 22:00:51.470 * The server is now ready to accept connections on port 6379
#master接收到来自slave1的全量复制请求
10393:M 01 Apr 22:00:57.464 * Slave 127.0.0.1:6380 asks for synchronization
10393:M 01 Apr 22:00:57.464 * Full resync requested by slave 127.0.0.1:6380
10393:M 01 Apr 22:00:57.464 * Starting BGSAVE for SYNC with target: disk
#bgsave执行过程
10400:C 01 Apr 22:00:57.571 * DB saved on disk
10400:C 01 Apr 22:00:57.571 * RDB: 4 MB of memory used by copy-on-write
10393:M 01 Apr 22:00:57.594 * Background saving started by pid 10400
10393:M 01 Apr 22:00:57.594 * Background saving terminated with success
#把数据同步给slave1,增量复制
10393:M 01 Apr 22:00:57.594 * Synchronization with slave 127.0.0.1:6380 succeeded
#master接收到来自slave2的全量复制请求
10393:M 01 Apr 22:01:01.335 * Slave 127.0.0.1:6381 asks for synchronization
10393:M 01 Apr 22:01:01.335 * Full resync requested by slave 127.0.0.1:6381
10393:M 01 Apr 22:01:01.335 * Starting BGSAVE for SYNC with target: disk
#bgsave执行过程
10405:C 01 Apr 22:01:01.362 * DB saved on disk
10405:C 01 Apr 22:01:01.363 * RDB: 4 MB of memory used by copy-on-write
10393:M 01 Apr 22:01:01.392 * Background saving started by pid 10405
10393:M 01 Apr 22:01:01.435 * Background saving terminated with success
#把数据同步给slave2,增量复制
10393:M 01 Apr 22:01:01.435 * Synchronization with slave 127.0.0.1:6381 succeeded
10393:M 01 Apr 22:04:11.476 # Connection with slave 127.0.0.1:6381 lost.
10393:M 01 Apr 22:17:20.683 # Connection with slave 127.0.0.1:6380 lost.
10393:signal-handler (1585793917) Received SIGTERM scheduling shutdown...
10393:M 01 Apr 22:18:37.923 # User requested shutdown...
10393:M 01 Apr 22:18:37.924 * Removing the pid file.
10393:M 01 Apr 22:18:37.924 # Redis is now ready to exit, bye bye...
[root@node1 ~]# cat redis-6380.log #从节点日志分析
10397:S 01 Apr 22:00:57.462 * The server is now ready to accept connections on port 6380
#与master节点进行连接通信
10397:S 01 Apr 22:00:57.462 * Connecting to MASTER 127.0.0.1:6379
#全量复制开始前准备阶段
10397:S 01 Apr 22:00:57.463 * MASTER <-> SLAVE sync started
10397:S 01 Apr 22:00:57.463 * Non blocking connect for SYNC fired the event.
10397:S 01 Apr 22:00:57.463 * Master replied to PING, replication can continue...
10397:S 01 Apr 22:00:57.464 * Partial resynchronization not possible (no cached master)
#全量复制开始
10397:S 01 Apr 22:00:57.594 * Full resync from master: 752a2742ad0e075e5367e9f44561d49e99d7c3bc:1
10397:S 01 Apr 22:00:57.594 * MASTER <-> SLAVE sync: receiving 77 bytes from master
10397:S 01 Apr 22:00:57.595 * MASTER <-> SLAVE sync: Flushing old data
10397:S 01 Apr 22:00:57.595 * MASTER <-> SLAVE sync: Loading DB in memory
10397:S 01 Apr 22:00:57.595 * MASTER <-> SLAVE sync: Finished with success
架构
哨兵架构
工作原理
每个哨兵会向其他哨兵(sentinel)、master、slave定时发送消息,以确定对方是否”活着“,如果发现对方在指定时间内未回应,则暂时认为对方已挂(主观宕机:sdown),若”哨兵群“中的多数sentinel,都报告某一master没响应,系统才认为该master”彻底死亡“(客观上的真正down机:odown),通过一定的vote(选举)算法,从剩下的slave节点中,选一台提升为master,然后自动修改相关配置
主观下线:某个哨兵发现master挂掉了,就认为master暂时下线
客观下线:如果整个哨兵群多数发现master挂掉,就认为master真正下线

优点
备份、读写分离,可以自动去换主节点
缺点
1.单机存储容量受限
2.主节点写负载会变高
3.拓展性差
4.在这种模式下每台redis服务器都存储相同的数据,很浪费内存
配置及优化
port:Sentinel节点的端口
dir:Sentinel节点的工作目录
sentinel monitor <master‐name> <ip> <port> <quorum>:Sentinel节点要监控的master节点及其判定不可 达的票数
<quorum>:代表至少几个Sentinel节点认为主机节点不可达;同时还和Sentinel节点的领导者选举有关,至少要 有max(quorum,num(sentinel)/2 + 1)个Sentinel节点参与选举,才能选出领导者Sentinel
sentienl down‐after‐milliseconds <master‐name> <times>:每个Sentinel节点都要通过定期发送ping命 令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过以上设置的时间且没有有效的恢复,则判定节点 不可达,单位是ms。(虽然以master‐name为参数,但实际上对Sentinel节点、主从节点的失败判定同时有效)
sentinel parallel‐syncs <master‐name> <nums>:当故障转移操作完成后,限制每次向新的主节点发起复制 操作的从节点个数
sentinel failover‐timeout <master‐name> <times>:故障转移超时时间,但实际上它作用于故障转移的各阶段:
1. 选出合适从节点:当对一个主节点故障转移失败,那么下次再对该主机节点做故障转移的起始时间是failovertimeout的2倍
2. 晋升选出的从节点为主节点:在前一阶段选出的从节点执行slaveof no one 一直失败,当此过程超过 failover‐timeout,则故障转移失败
3. 命令其余从节点复制新的主节点:如果2阶段执行成功,Sentinel节点还会执行info命令来确认1阶段选出来的 节点确实晋升为主节点,如果此过程执行时间超过failover‐timeout,则故障转移失败 4. 等待原主节点会后后命令它去复制新的主节点:如果3阶段执行时间超过failover‐timeout(不包含复制时 间),则故障转移失败;即使超过了这个时间,Sentinel节点也会终配置从节点去同步新的主节点
sentinel auth‐pass <master‐name> <password>:如果Sentinel监控的主节点配置密码,则需要配置相关参 数
sentinel notification‐script <master‐name> <script‐path>:在故障转移期间,当一些警告级别的 Sentinel事件发生时,会触发对应路径的脚本,并向脚本发送相应的事件参数
sentinel client‐reconfig‐script <master‐name> <script‐path> :在故障转移结束后,会触发对应的路径脚本
如果想要监控多个主节点:
sentinel monitor master1 10.10.1.1 6379 2 sentinel monitor master2 10.10.2.1 6379 2
部署操作
[root@node1 ~]# redis-sentinel redis-sentinel26378.conf
[root@node1 ~]# redis-server
11663:C 02 Apr 11:22:46.072 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
11663:M 02 Apr 11:22:46.074 * Increased maximum number of open files to 10032 (it was originally set to 1024).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 3.2.12 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 11663
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
#这个配置文件不要直接复制,要自己敲上去
[root@node1 ~]# vim redis-sentinel26378.conf
port 26378 #Sentinel节点的端口
daemonize yes #Sentinel节点的工作目录
dir "/tmp"
sentinel monitor mymaster 127.0.0.1 6379 1
sentinel down-after-milliseconds mymaster 6000
sentinel failover-timeout mymaster 18000
logfile "/usr/sentienl-26378.log"
[root@node1 ~]# vim redis-sentinel26379.conf
port 26379
daemonize yes
dir "/tmp"
sentinel monitor mymaster 127.0.0.1 6379 1
sentinel down-after-milliseconds mymaster 6000
sentinel failover-timeout mymaster 18000
logfile "/usr/sentienl-26379.log" #日志位置
#开启哨兵服务
[root@node1 ~]# redis-sentinel redis-sentinel26378.conf
[root@node1 ~]# redis-sentinel redis-sentinel26379.conf
#检测端口状态
[root@node1 ~]# ps -elf | grep redis
5 S root 10665 1 0 80 0 - 35731 ep_pol 05:47 ? 00:01:04redis-sentinel *:26379 [sentinel]
5 S root 10909 1 0 80 0 - 35730 ep_pol 07:23 ? 00:00:43redis-sentinel *:26378 [sentinel]
4 S root 11667 10108 0 80 0 - 35731 ep_pol 11:24 pts/0 00:00:00redis-server *:6379
0 S root 11681 11448 0 80 0 - 5525 n_tty_ 11:26 pts/2 00:00:00redis-cli -p 26379
0 S root 11684 10917 0 80 0 - 28177 pipe_w 11:29 pts/1 00:00:00 grep --color=auto redis
测试验证
sentinel master [master‐name]: 显示所有被监控的主节点状态及其相关的统计信息 sentinel slaves <master‐name>:显示指定<master‐name>的从节点状态以及相关的统计信息 sentinel sentinels <master name>:显示指定<master‐name>的Sentinel节点集合(不包含当前Sentinel节 点)
sentinel get‐master‐addr‐by‐name <master‐name>
sentinel reset <pattern>
sentinel failover <master‐name>:强制故障转移
sentinel ckquorum <master‐name>:检查当前可达的Sentinel节点总数是否到<quoru>的个数 sentinel flushconfig:将Sentinel节点的配置强制刷到磁盘上
sentinel remove <master‐name>:取消当前Sentinel节点对于指定<master‐name>主节点的监控 sentinel monitor <master name><ip><port><quorum>:监控指定<master‐name>主节点 sentinel set <master‐name>:动态修改Sentinel节点配置
sentinel is‐master‐down‐by‐addr:Sentinel节点之间用来交换对主节点是否下线的判断
模拟master节点挂掉
[root@node1 ~]# kill -9 11667
11667:M 02 Apr 11:24:08.556 * The server is now ready to accept connections on port 6379
Killed
查看日志
关闭master上redis服务
查看日志字段:
+switch‐master mymaster 127.0.0.1 6380 127.0.0.1 6382
master切换
重启旧master上redis服务
查看日志字段:
+convert‐t‐slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6382 成为slave
127.0.0.1:6382> info Replication # Replication role:master
connected_slaves:2 slave0:ip=127.0.0.1,port=6381,state=online,offset=131255,lag=0 slave1:ip=127.0.0.1,port=6380,state=online,offset=131388,lag=0 master_repl_offset:131388
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:131387
集群架构
在redis3.0上加入了cluster模式,实现的redis的分布式存储,也就是说每台redis节点上存储不同 的内容
工作原理
hash一致性算法去做 —> 虚拟槽技术
1.对象保存在Redis之前经过CRC16哈希到一个指定的node上
2.每个节点被平均分配了一个slot段(0-16384),slot不能重复也不能缺失,否则会导致对象重复存储或无法存储
3.节点之间相互监听,一旦有node退出或者加入,会按照slot为单位做数据的迁移。
eg:Node1如果掉线了,05640这些Slot将会平均分摊到Node2和Node3上,由于Node2和Node3本身维护的Slot还会在自己身上不会被重新 分配,所以迁移过程中不会影响到5641-16384Slot段的使用。
优点
每个节点都可以存储数据,每个节点都可以响应读写操作,提高写的并发能力,更容易扩容
缺点
部署复杂,:每个Node承担着互相监听、高并发数据写入、高并发数据读出,工作任务繁重 ,redis部分cli命令受限。eg:批量操作等
cluster部署
必须是5.0以上的
准备 二进制安装
[root@node2 ~]# yum install gcc-c++ -y
[root@node2 ~]# yum install lrzsz -y
[root@node2 ~]# rz
[root@node2 ~]# ls
1.sh anaconda-ks.cfg redis-5.0.8.tar.gz
[root@node2 redis-5.0.8]# tar xzf redis-5.0.8.tar.gz
[root@node2 ~]#cd redis-5.0.8
[root@node2 redis-5.0.8]# make install PREFIX=/usr/local/redis
[root@node2 redis-5.0.8]# PATH=$PATH:/usr/local/redis/bin #环境变量
部署
[root@node2 ~]# mkdir /usr/local/redis-cluster
[root@node2 ~]# cd /usr/local/redis-cluster
[root@node2 redis-cluster]# cat redis-cluster.sh
#!/bin/bash
mkdir /usr/local/redis-cluster/redis{7000..7005} -pv
touch /usr/local/redis-cluster/redis{7000..7005}/redis.conf
for i in {7000..7005};
do
cat << EOF > /usr/local/redis-cluster/redis$i/redis.conf
daemonize yes
port $i
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster/redis$i/nodes-$i.conf
cluster-node-timeout 5000
appendonly yes
EOF
redis-server /usr/loacl/redis-cluster/redis$i/redis.conf
done
[root@node2 redis-cluster]# chmod +x redis-cluster.sh
[root@node2 redis-cluster]# sh redis-cluster.sh
#部署完成之后检查各进程是否ok ,有六个结点
[root@node2 ~]# ps -elf | grep redis
5 S root 12081 1 0 80 0 - 38475 ep_pol 12:51 ? 00:00:00 redis-server *:7000 [cluster]
5 S root 12086 1 0 80 0 - 38475 ep_pol 12:51 ? 00:00:00 redis-server *:7001 [cluster]
5 S root 12091 1 0 80 0 - 38475 ep_pol 12:51 ? 00:00:00 redis-server *:7002 [cluster]
5 S root 12096 1 0 80 0 - 38475 ep_pol 12:51 ? 00:00:00 redis-server *:7003 [cluster]
5 S root 12101 1 0 80 0 - 38475 ep_pol 12:51 ? 00:00:00 redis-server *:7004 [cluster]
5 S root 12106 1 0 80 0 - 38475 ep_pol 12:51 ? 00:00:00 redis-server *:7005 [cluster]
0 S root 12111 7682 0 80 0 - 28178 pipe_w 12:52 pts/1 00:00:00 grep --color=auto redis
[root@node2 redis-cluster]# redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001\> 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005\> --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:7004 to 127.0.0.1:7000
Adding replica 127.0.0.1:7005 to 127.0.0.1:7001
Adding replica 127.0.0.1:7003 to 127.0.0.1:7002
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: d29c8b02c10bfc4d902f5424f524d596656b934e 127.0.0.1:7000
slots:[0-5460] (5461 slots) master
M: c469fd91c8922c8de3645c03dbe101ef43b6116b 127.0.0.1:7001
slots:[5461-10922] (5462 slots) master
M: 45c87d664835f805638cc946e559a34ae241fbb1 127.0.0.1:7002
slots:[10923-16383] (5461 slots) master
S: 65f1d3ebc4546418790996357a3d260feadbfaef 127.0.0.1:7003
replicates 45c87d664835f805638cc946e559a34ae241fbb1
S: d86c0610c8a6f7c0cfcf3f8cd305167a39eab3e0 127.0.0.1:7004
replicates d29c8b02c10bfc4d902f5424f524d596656b934e
S: b3663305dda3bc5d8c8dcbeb48443e522edc68d5 127.0.0.1:7005
replicates c469fd91c8922c8de3645c03dbe101ef43b6116b
Can I set the above configuration? (type 'yes' to accept): yes ##输入yes,即按照此方式分配master和slave
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
...
>>> Performing Cluster Check (using node 127.0.0.1:7000)
M: d29c8b02c10bfc4d902f5424f524d596656b934e 127.0.0.1:7000
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: d86c0610c8a6f7c0cfcf3f8cd305167a39eab3e0 127.0.0.1:7004
slots: (0 slots) slave
replicates d29c8b02c10bfc4d902f5424f524d596656b934e
M: c469fd91c8922c8de3645c03dbe101ef43b6116b 127.0.0.1:7001
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 65f1d3ebc4546418790996357a3d260feadbfaef 127.0.0.1:7003
slots: (0 slots) slave
replicates 45c87d664835f805638cc946e559a34ae241fbb1
M: 45c87d664835f805638cc946e559a34ae241fbb1 127.0.0.1:7002
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: b3663305dda3bc5d8c8dcbeb48443e522edc68d5 127.0.0.1:7005
slots: (0 slots) slave
replicates c469fd91c8922c8de3645c03dbe101ef43b6116b
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
验证测试
[root@node2 redis-cluster]# redis-cli -c -p 7000
#查询集群信息
127.0.0.1:7000> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:259
cluster_stats_messages_pong_sent:253
cluster_stats_messages_sent:512
cluster_stats_messages_ping_received:248
cluster_stats_messages_pong_received:259
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:512
#查询集群各节点
127.0.0.1:7000> cluster nodes
d86c0610c8a6f7c0cfcf3f8cd305167a39eab3e0 127.0.0.1:7004@17004 slave d29c8b02c10bfc4d902f5424f524d596656b934e 0 1585847095526 5 connected
c469fd91c8922c8de3645c03dbe101ef43b6116b 127.0.0.1:7001@17001 master - 0 1585847095526 2 connected 5461-10922
65f1d3ebc4546418790996357a3d260feadbfaef 127.0.0.1:7003@17003 slave 45c87d664835f805638cc946e559a34ae241fbb1 0 1585847094000 4 connected
45c87d664835f805638cc946e559a34ae241fbb1 127.0.0.1:7002@17002 master - 0 1585847094620 3 connected 10923-16383
b3663305dda3bc5d8c8dcbeb48443e522edc68d5 127.0.0.1:7005@17005 slave c469fd91c8922c8de3645c03dbe101ef43b6116b 0 1585847095627 6 connected
d29c8b02c10bfc4d902f5424f524d596656b934e 127.0.0.1:7000@17000 myself,master - 0 1585847094000 1 connected 0-5460
127.0.0.1:7000> set k3 jjjj
OK
127.0.0.1:7000> set k1 v1
-> Redirected to slot [12706] located at 127.0.0.1:7002 #数据k1 v1 CRC16 计算 分配到slot 12706端口 #数据分配特性
OK
RDB持久化:
RDB是redis用来进行持久化的一种方式,是把当前内存的数据及快照写入磁盘
恢复:将快照文件之间读到内存中
优点:
1.快照保存了redis某一个时间点上的所有数据集,这种文件非常适合进行备份和灾难恢复
2.生成RDB文件的时候,redis主进程会fork()一个子进程来处理保存工作,主进程不需要进行任何的磁盘IO操作
3.RDB在恢复大数据集的时候速度会比AOF快
缺点:
1.RDB方式无法做到秒级持久化,因为每次save都要执行fork操作,属于重量级操作,需要将内存中的数据克隆一份,频繁操作成本会很高(性能受到影响)
2.RDB文件使用特定的二进制格式保存,redis版本迭代的过程中,出现了多重RDB格式,老版本的无法兼容新版本
3.在一定时间内左一次备份,如果redis意外down掉的话,就会丢失一次最后一次块状的所有
触发方式:
手动触发:bgsave
自动触发:
恢复数据:
将备份的dump.rdb移动到redis安装目录并启动服务即可,redis会自动
RDB持久化停止:
有些情况下,我们只需要redis缓存功能,并不想使用redis的持久化操作,那么这时就需要停止RDB持久化,可以在redis.conf中修改配置文件,就可以停用RDB持久化

若有收获,就点个赞吧
0 人点赞
