一. 概念
1.1 进程
就是一个程序从开始运行到结束的过程。在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程中的一个线程,也称主线程。
1.2 线程
线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
1.3 进程和线程区别
一个进程中可以有多个线程,多个线程共享进程的堆和方法区 (JDK1.8 之后的元空间)的资源,但是每个线程有自己的程序计数器、虚拟机栈和本地方法栈。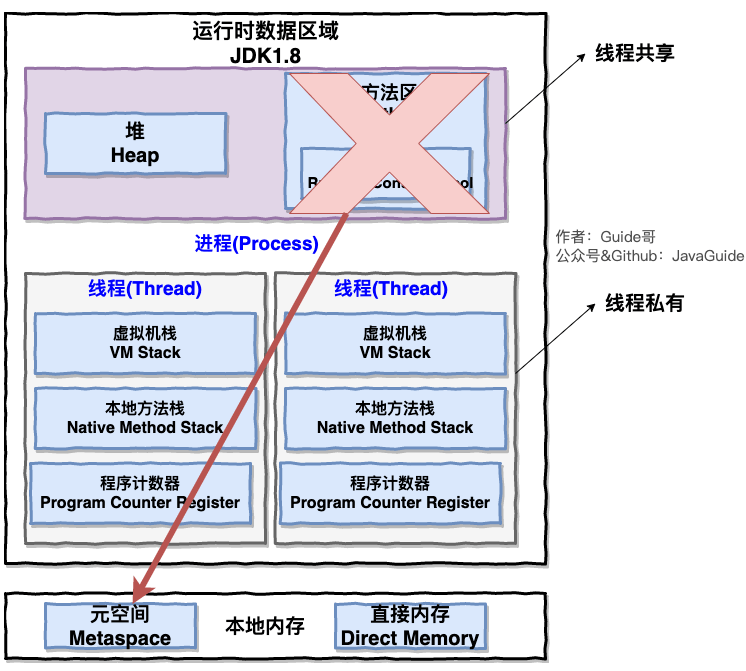
总结: 线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反。
1.3.1 为什么程序计数器线程私有
程序计数器的作用:
- 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
- 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
需要注意的是,如果执行的是 native 方法,那么程序计数器记录的是 undefined 地址,只有执行的是 Java 代码时程序计数器记录的才是下一条指令的地址。
所以,程序计数器私有主要是为了线程切换后能恢复到正确的执行位置。
1.3.2 虚拟机栈和本地方法栈为什么私有
两个栈的作用
- 虚拟机栈: 每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
- 本地方法栈: 和虚拟机栈所发挥的作用非常相似,区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
所以,为了保证线程中的局部变量不被别的线程访问到,虚拟机栈和本地方法栈是线程私有的。
1.4 堆和方法区
堆和方法区是所有线程共享的资源
- 堆是进程中最大的一块内存,主要用于存放新创建的对象 (几乎所有对象都在这里分配内存)
- 方法区主要用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
1.5 并发与并行
- 并发: 同一时间段,多个任务都在执行 (单位时间内不一定同时执行);
- 并行: 单位时间内,多个任务同时执行。
1.6 为什么使用多线程
先从总体上来说:
- 从计算机底层来说: 线程间的切换和调度的成本远远小于进程。另外,多核 CPU 时代意味着多个线程可以同时运行,这减少了线程上下文切换的开销。
- 从当代互联网发展趋势来说: 高并发量要求多线程。
再深入到计算机底层来探讨:
- 单核时代: 在单核时代多线程主要是为了提高单进程利用 CPU 和 IO 系统的效率。 假设只运行了一个 Java 进程的情况,当我们请求 IO 的时候,如果 Java 进程中只有一个线程,此线程被 IO 阻塞则整个进程被阻塞。CPU 和 IO 设备只有一个在运行,那么可以简单地说系统整体效率只有 50%。当使用多线程的时候,一个线程被 IO 阻塞,其他线程还可以继续使用 CPU。从而提高了 Java 进程利用系统资源的整体效率。
- 多核时代: 多核时代多线程主要是为了提高进程利用多核 CPU 的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个 CPU 核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个 CPU 上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU 核心数)。
1.6.1 多线程产生的问题
内存泄漏、死锁、线程不安全等等。
1.6.2 线程的生命周期和状态
Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种不同状态的其中一个状态
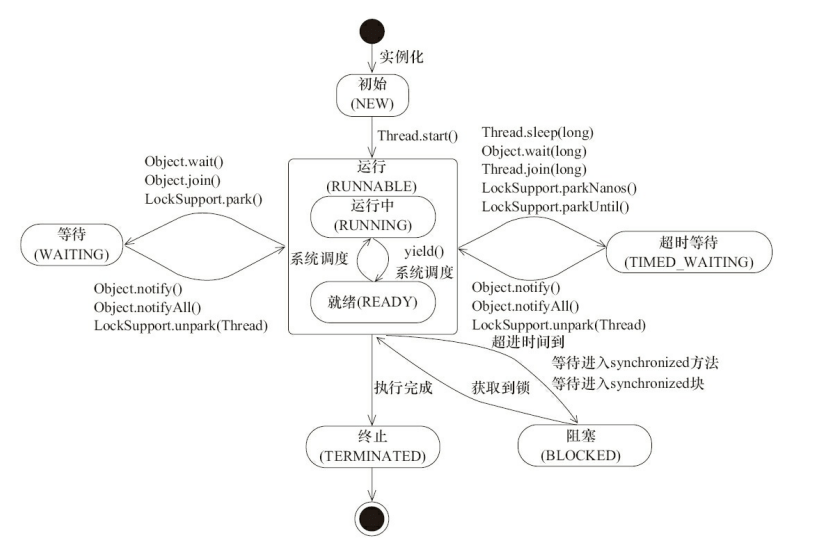
1.6.3 上下文切换
线程在执行过程中会有自己的运行条件和状态(也称上下文),比如上文所说到过的程序计数器,栈信息等。当出现如下情况的时候,线程会从占用 CPU 状态中退出。
- 主动让出 CPU,比如调用了 sleep(), wait() 等。
- 时间片用完,因为操作系统要防止一个线程或者进程长时间占用CPU导致其他线程或者进程饿死。
- 调用了阻塞类型的系统中断,比如请求 IO,线程被阻塞。
- 被终止或结束运行
这其中前三种都会发生线程切换,线程切换意味着需要保存当前线程的上下文,留待线程下次占用 CPU 的时候恢复现场。并加载下一个将要占用 CPU 的线程上下文。这就是所谓的 上下文切换。
上下文切换是现代操作系统的基本功能,因其每次需要保存信息恢复信息,这将会占用 CPU,内存等系统资源进行处理,也就意味着效率会有一定损耗,如果频繁切换就会造成整体效率低下。
1.7 为什么调用start()方法会自动执行run()方法,能不能直接调用run()方法呢?
new 一个 Thread,线程进入了新建状态。调用 start()方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。
但是,直接执行 run() 方法,会把 run() 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
总结: 调用 start() 方法方可启动线程并使线程进入就绪状态,直接执行 run() 方法的话不会以多线程的方式执行。
二. 线程同步的关键字们
2.1 synchronized
2.1.1 定义
synchronized 关键字解决的是多个线程之间访问资源的同步性,synchronized关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。
另外,在 Java 早期版本中,synchronized 属于 重量级锁,效率低下。其原因如下
因为监视器锁(monitor)是依赖于底层的操作系统的 Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高。
庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对 synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6 对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
目前各种开源框架还是 JDK 源码都大量使用了 synchronized 关键字。
2.1.2 怎么使用
1. 修饰实例方法
对当前的实例对象加锁,进入同步代码块的时候,必须要先获取当前对象实例这把锁,才能进入同步代码块执行代码
synchronized void method() {//业务代码}
2. 修饰静态方法
也就是给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 当前 class 的锁。
因为静态成员不属于任何一个实例对象,是类成员( static 表明这是该类的一个静态资源,不管 new 了多少个对象,只有一份)。
所以,如果一个线程 A 调用一个实例对象的非静态 synchronized 方法,而线程 B 需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。
class A {
// static method
public synchronized static void printA{
System.out.print("aaa");
}
// instance method
public synchronized void printB{
System.out.print("bbb");
}
}
class B{
public static void main(String[] args) {
A a = new A();
new Thread(() -> {
a.printA();
}).start();
new Thread(() -> {
a.printB();
}).start();
}
}
3. 修饰代码块
指定某个对象或者类,作为同步代码块的锁
synchronized(this|object) 表示进入同步代码库前要获得给定对象的锁。
synchronized(类.class) 表示进入同步代码前要获得 当前 class 的锁
synchronized(this) {
//业务代码
}
4. 单例模式之双重锁校验
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance == null) {
//类对象加锁
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
另外,需要注意 uniqueInstance 采用 volatile 关键字修饰也是很有必要。
uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
- 为 uniqueInstance 分配内存空间
- 初始化 uniqueInstance
- 将 uniqueInstance 指向分配的内存地址
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。
例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
PS:构造方法不能使用 synchronized 关键字修饰。
构造方法本身就属于线程安全的,不存在同步的构造方法一说。
2.1.3 原理
1. 修饰代码块的时候
public class SynchronizedDemo {
public void method() {
synchronized (this) {
System.out.println("synchronized 代码块");
}
}
}
使用javap -v 命令,把class文件反编译成可读的字节码文件。得到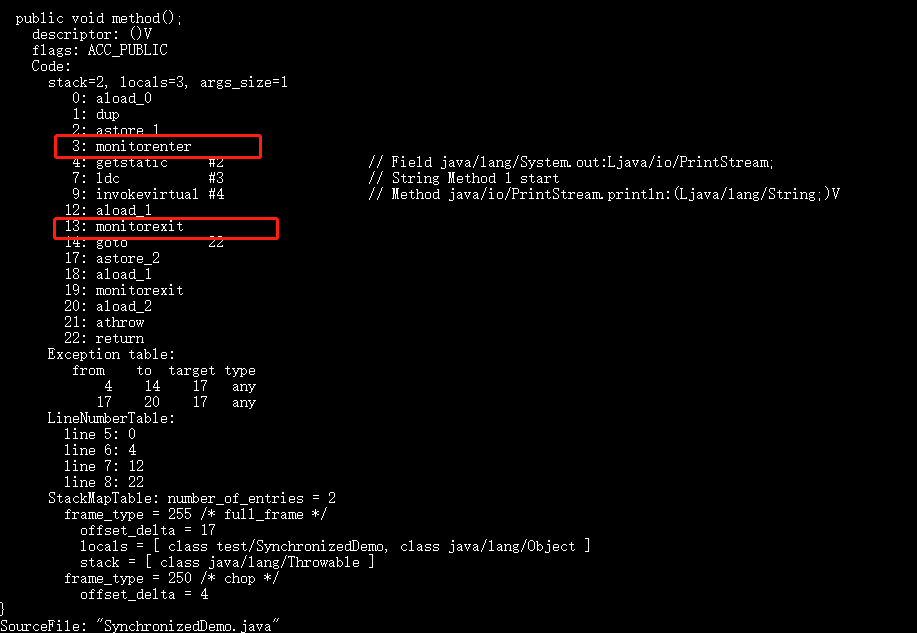
上面我们可以看出:
synchronized 同步语句块的实现使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。
当执行 monitorenter 指令时,线程试图获取锁也就是获取 对象监视器 monitor 的持有权。
在 Java 虚拟机(HotSpot)中,Monitor 是基于 C++实现的。每个对象中都内置了一个 ObjectMonitor对象。
另外,wait/notify等方法也依赖于monitor对象,这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。
在执行monitorenter时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
在执行 monitorexit 指令后,将锁计数器设为 0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
2. 修饰方法的时候
public class SynchronizedDemo2 {
public synchronized void method() {
System.out.println("synchronized 方法");
}
}
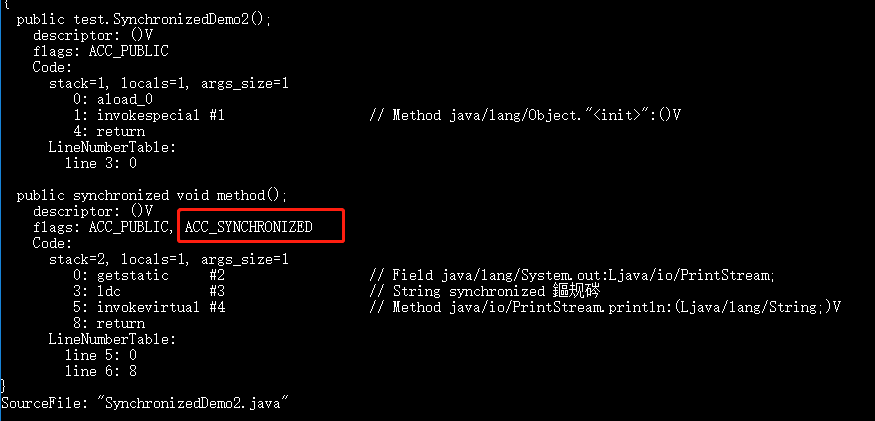
synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令,取得代之的确实是 ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法。
JVM 通过该 ACC_SYNCHRONIZED 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
2.1.3 JDK1.6 之后的 synchronized 关键字底层做了哪些优化
JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
下文将介绍Java SE 1.6 中为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁,以及锁的存储结构和升级过程。
1. java对象头(存储类型)
在 HotSpot 虚拟机中,对象在内存中的布局分为三块区域:对象头,实例数据和对齐填充。
对象头中包含两部分:MarkWord 和 类型指针。如果是数组对象的话,对象头还有一部分是存储数组的长度。
多线程下 synchronized 的加锁就是对同一个对象的对象头中的 MarkWord 中的变量进行CAS操作。
- MarkWord
Mark Word 用于存储对象自身的运行时数据,如 HashCode、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID等等。
占用内存大小与虚拟机位长一致(32位JVM -> MarkWord是32位,64位JVM -> MarkWord是64位)。
- 类型指针
虚拟机通过这个指针确定该对象是哪个类的实例
- 对象头的长度 | 长度 | 内容 | 说明 | | —- | —- | —- | | 32/64bit | MarkWord | 存储对象的hashCode或锁信息等 | | 32/64bit | Class Metadata Address | 存储对象类型数据的指针 | | 32/64bit | Array Length | 数组的长度(如果当前对象是数组) |
2. 优化后synchronized锁分类
级别从低到高依次是:
- 无锁状态
- 偏向锁状态
- 轻量级锁状态
- 重量级锁状态
锁可以升级,但不能降级。即:无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁是单向的。
下面看一下每个锁状态时,对象头中的 MarkWord 这一个字节中的内容是什么。
以32位系统为例:
无锁状态 | 25bit | 4bit | 1bit(是否是偏向锁) | 2bit(锁标志位) | | —- | —- | —- | —- | | 对象的hashCode | 对象分代年龄 | 0 | 01 |
偏向锁状态 | 23bit | 2bit | 4bit | 1bit | 2bit | | —- | —- | —- | —- | —- | | 线程ID | epoch | 对象分代年龄 | 1 | 01 |
这里 线程ID 和 epoch 占用了 hashCode 的位置,所以,如果对象如果计算过 identityHashCode 后,便无法进入偏向锁状态,反过来,如果对象处于偏向锁状态,并且需要计算其 identityHashCode 的话,则偏向锁会被撤销,升级为重量级锁。
epoch:
对于偏向锁,如果 线程ID = 0 表示未加锁。
什么时候会计算 HashCode 呢?比如:将对象作为 Map 的 Key 时会自动触发计算,List 就不会计算,日常创建一个对象,持久化到库里,进行 json 序列化,或者作为临时对象等,这些情况下,并不会触发计算 hashCode,所以大部分情况不会触发计算 hashCode。
Identity hash code是未被覆写的 java.lang.Object.hashCode() 或者 java.lang.System.identityHashCode(Object) 所返回的值。
- 轻量级锁状态 | 30bit | 2bit | | —- | —- | | 指向线程栈锁记录的指针 | 00 |
这里指向栈帧中的 Lock Record 记录,里面当然可以记录对象的 identityHashCode。
- 重量级锁状态 | 30bit | 2bit | | —- | —- | | 指向锁监视器的指针 | 10 |
这里指向了内存中对象的 ObjectMonitor 对象,而 ObectMontitor 对象可以存储对象的 identityHashCode 的值。
// todo 目前没有搜索到较好的博客讲这一段,以后遇到好的再更新
三. ReentrantLock
3.1 synchronized和ReentrantLock的区别
3.1.1 都是可重入锁
“可重入锁” 指的是自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的。
如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增 1,所以要等到锁的计数器下降为 0 时才能释放锁。
3.1.2 synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
- synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 synchronized 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。
- ReentrantLock 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
3.1.3 ReentrantLock 比 synchronized 增加了一些高级功能
相比synchronized,ReentrantLock增加了一些高级功能。主要来说主要有三点:
- 等待可中断 : ReentrantLock提供了一种能够中断等待锁的线程的机制,通过 lock.lockInterruptibly() 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
- 可实现公平锁 : ReentrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。ReentrantLock默认情况是非公平的,可以通过 ReentrantLock类的ReentrantLock(boolean fair)构造方法来制定是否是公平的。
- 可实现选择性通知(锁可以绑定多个条件): synchronized关键字与wait()和notify()/notifyAll()方法相结合可以实现等待/通知机制。ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition()方法。
四. Volatile关键字
4.1 CPU缓存模型
为什么需要CPU缓存呢?
计算机中,执行速度最快是的CPU,接下来就是内存,最慢的是硬盘IO。因为CPU的速度远超内存,所以程序运行的时候,会把内存的数据先复制到PCU缓存里面在执行,这样就提高了程序运行的速度。
总结:CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。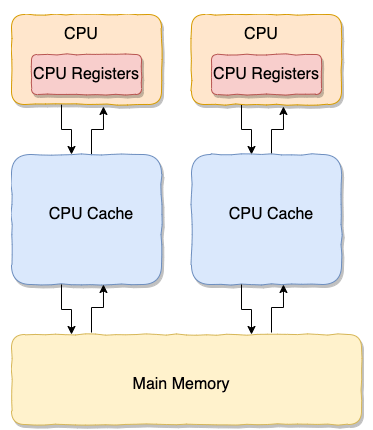
CPU Cache 的工作方式:
先复制一份数据到 CPU Cache 中,当 CPU 需要用到的时候就可以直接从 CPU Cache 中读取数据,当运算完成后,再将运算得到的数据写回 Main Memory 中。
但是,这样存在 内存缓存不一致性的问题 !比如我执行一个 i++操作的话,如果两个线程同时执行的话,假设两个线程从 CPU Cache 中读取的 i=1,两个线程做了 1++运算完之后再写回 Main Memory 之后 i=2,而正确结果应该是 i=3。
CPU 为了解决内存缓存不一致性问题可以通过制定缓存一致协议或者其他手段来解决。
4.2 JMM(java内存模型)
在 JDK1.2 之前,Java 的内存模型实现总是从主存(即共享内存)读取变量,是不需要进行特别的注意的。而在当前的 Java 内存模型下,线程可以把变量保存本地内存(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成数据的不一致。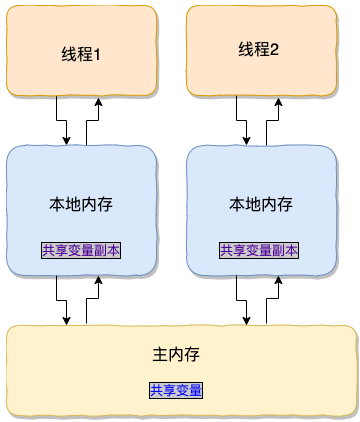
要解决这个问题,就需要把变量声明为 volatile ,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
所以,volatile 关键字 除了防止 JVM 的指令重排 ,还有一个重要的作用就是保证变量的可见性。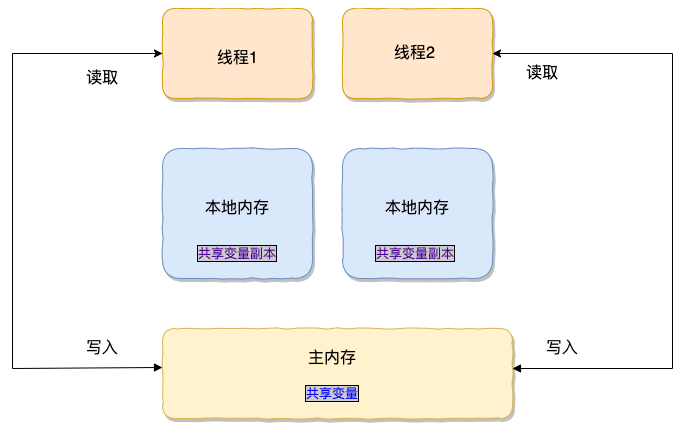
4.3 并发编程的三个特性
- 原子性 : 一个的操作或者多次操作,要么所有的操作全部都得到执行并且不会收到任何因素的干扰而中断,要么所有的操作都执行,要么都不执行。synchronized 可以保证代码片段的原子性。
- 可见性 :当一个线程对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值。volatile 关键字可以保证共享变量的可见性。
- 有序性 :代码在执行的过程中的先后顺序,Java 在编译器以及运行期间的优化,代码的执行顺序未必就是编写代码时候的顺序。volatile 关键字可以禁止指令进行重排序优化。
4.4 synchronized 关键字和 volatile 关键字的区别
synchronized 关键字和 volatile 关键字是两个互补的存在,而不是对立的存在!
- volatile 关键字是线程同步的轻量级实现,所以 volatile 性能肯定比synchronized关键字要好 。但是 volatile 关键字只能用于变量而 synchronized 关键字可以修饰方法以及代码块 。
- volatile 关键字能保证数据的可见性,但不能保证数据的原子性。synchronized 关键字两者都能保证。
- volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized 关键字解决的是多个线程之间访问资源的同步性。
五. ThreadLocal
5.1 简介
通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。如果想实现每一个线程都有自己的专属本地变量该如何解决呢? JDK 中提供的ThreadLocal类正是为了解决这样的问题。 ThreadLocal类主要解决的就是让每个线程绑定自己的值,可以将ThreadLocal类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。
如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是ThreadLocal变量名的由来。他们可以使用 get() 和 set() 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。
5.2 示例
import java.text.SimpleDateFormat;
import java.util.Random;
public class ThreadLocalExample implements Runnable{
// SimpleDateFormat 不是线程安全的,所以每个线程都要有自己独立的副本
private static final ThreadLocal<SimpleDateFormat> formatter =
ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyyMMdd HHmm"));
public static void main(String[] args) throws InterruptedException {
ThreadLocalExample obj = new ThreadLocalExample();
for(int i=0 ; i<10; i++){
Thread t = new Thread(obj, ""+i);
Thread.sleep(new Random().nextInt(1000));
t.start();
}
}
@Override
public void run() {
System.out.println("Thread Name= "+Thread.currentThread().getName()+
" default Formatter = "+formatter.get().toPattern());
try {
Thread.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
formatter.set(new SimpleDateFormat());
System.out.println("Thread Name= "+Thread.currentThread().getName()+
" formatter = "+formatter.get().toPattern());
}
}
结果
Thread Name= 0 default Formatter = yyyyMMdd HHmm
Thread Name= 0 formatter = yy-M-d ah:mm
Thread Name= 1 default Formatter = yyyyMMdd HHmm
Thread Name= 2 default Formatter = yyyyMMdd HHmm
Thread Name= 1 formatter = yy-M-d ah:mm
Thread Name= 3 default Formatter = yyyyMMdd HHmm
Thread Name= 2 formatter = yy-M-d ah:mm
Thread Name= 4 default Formatter = yyyyMMdd HHmm
Thread Name= 3 formatter = yy-M-d ah:mm
Thread Name= 4 formatter = yy-M-d ah:mm
Thread Name= 5 default Formatter = yyyyMMdd HHmm
Thread Name= 5 formatter = yy-M-d ah:mm
Thread Name= 6 default Formatter = yyyyMMdd HHmm
Thread Name= 6 formatter = yy-M-d ah:mm
Thread Name= 7 default Formatter = yyyyMMdd HHmm
Thread Name= 7 formatter = yy-M-d ah:mm
Thread Name= 8 default Formatter = yyyyMMdd HHmm
Thread Name= 9 default Formatter = yyyyMMdd HHmm
Thread Name= 8 formatter = yy-M-d ah:mm
Thread Name= 9 formatter = yy-M-d ah:mm
从输出中可以看出,Thread-0 已经改变了 formatter 的值,但仍然是 thread-2 默认格式化程序与初始化值相同,其他线程也一样。
5.3 原理
public class Thread implements Runnable {
//......
//与此线程有关的ThreadLocal值。由ThreadLocal类维护
ThreadLocal.ThreadLocalMap threadLocals = null;
//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
//......
}
从上面Thread类 源代码可以看出Thread 类中有一个 threadLocals 和 一个 inheritableThreadLocals 变量,它们都是 ThreadLocalMap 类型的变量,我们可以把 ThreadLocalMap 理解为ThreadLocal 类实现的定制化的 HashMap。
默认情况下这两个变量都是 null,只有当前线程调用 ThreadLocal 类的 set或get方法时才创建它们,实际上调用这两个方法的时候,我们调用的是ThreadLocalMap类对应的 get()、set()方法。
ThreadLocal类的set()方法
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
通过上面这些内容,我们足以通过猜测得出结论:最终的变量是放在了当前线程的 ThreadLocalMap 中,并不是存在 ThreadLocal 上,ThreadLocal 可以理解为只是ThreadLocalMap的封装,传递了变量值。 ThrealLocal 类中可以通过Thread.currentThread()获取到当前线程对象后,直接通过getMap(Thread t)可以访问到该线程的ThreadLocalMap对象。
每个Thread中都具备一个ThreadLocalMap,而ThreadLocalMap可以存储以ThreadLocal为 key ,Object 对象为 value 的键值对。
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
//......
}
比如我们在同一个线程中声明了两个 ThreadLocal 对象的话,会使用 Thread内部都是使用仅有那个ThreadLocalMap 存放数据的,ThreadLocalMap的 key 就是 ThreadLocal对象,value 就是 ThreadLocal 对象调用set方法设置的值。
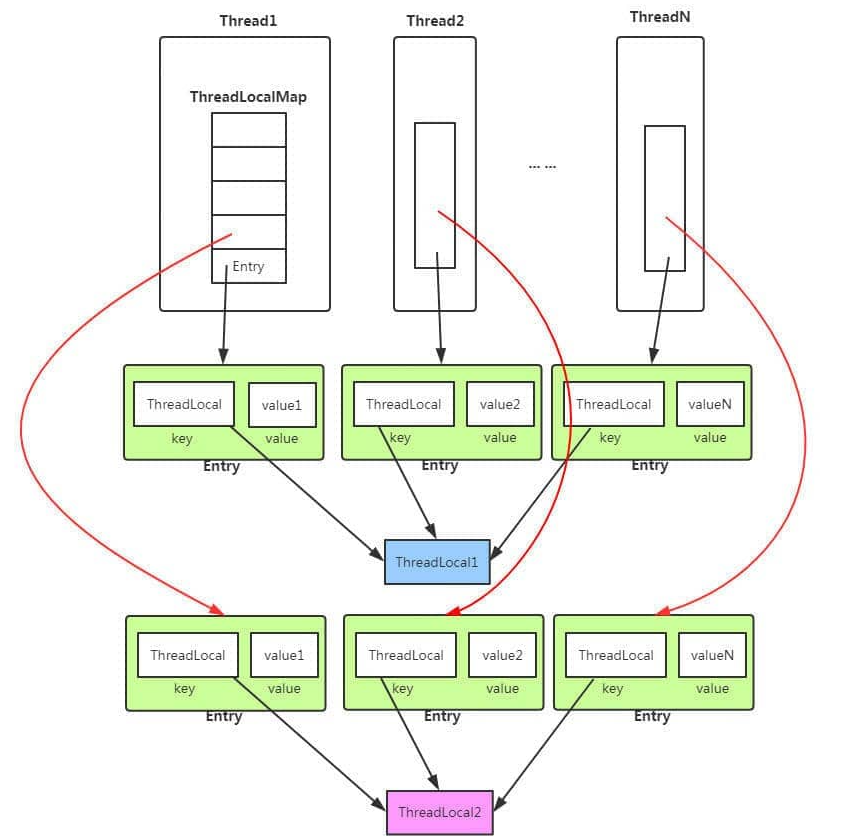
5.4 关于内存泄漏
ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,而 value 是强引用。所以,如果 ThreadLocal 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,ThreadLocalMap 中就会出现 key 为 null 的 Entry。
假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap 实现中已经考虑了这种情况,在调用 set()、get()、remove() 方法的时候,会清理掉 key 为 null 的记录。使用完 ThreadLocal方法后 最好手动调用remove()方法
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}

若有收获,就点个赞吧
0 人点赞
