一 Java内存区域详解
1.1 概述
在虚拟机能自动内存管理机制下,java不需要像C/C++程序开发一样,为每一个new操作去写对应的delete/free操作,不容易出现内存泄漏和内存溢出的问题。但也正因为将内存管理的任务交给虚拟机来做,所以一旦出现内存泄漏和溢出方面的问题,排查会很难。
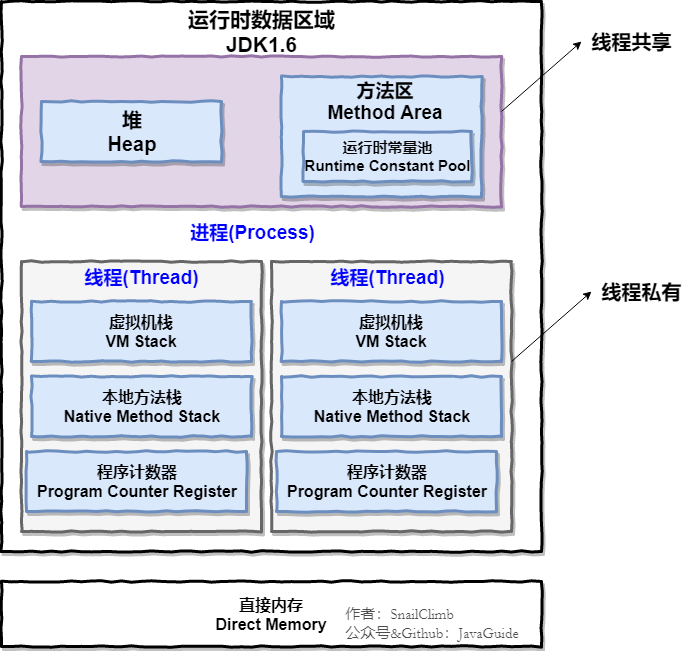
1.2 运行时数据区域
Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域。JDK 1.8 和之前的版本略有不同,下面会介绍到。
- Java8之前
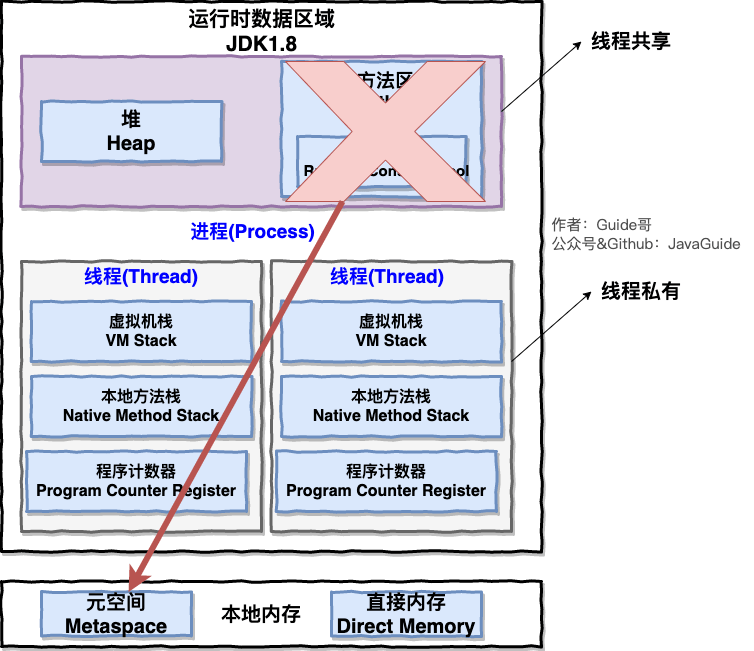
- java8之后


- 线程私有的
- 程序计数器
- 虚拟机栈
- 本地方法栈
- 线程共享
- 堆
- 方法去
- 直接内存
1.2.1 程序计数器
程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。其作用是
- 字节码解释器通过改变程序计数器来依次读取要执行的指令,从而实现代码的流程控制。(条件,循环,选择,异常)
- 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
- 程序计数器是唯一一个不会出现 OutOfMemoryError 的内存区域,它的生命周期随着线程的创建而创建,随着线程的结束而死亡。
1.2.2 Java虚拟机栈
线程私有,生命周期同线程相同。描述的是java方法执行的内存模型,每次方法调用的数据都是通过栈传递的。Java 内存可以粗糙的区分为堆内存(Heap)和栈内存 (Stack),其中栈就是现在说的虚拟机栈,或者说是虚拟机栈中局部变量表部分。
1.2.2.1 栈帧
每一个方法开始执行,都会像虚拟机栈中,压入一个方法的栈帧,当该方法执行完毕后,这个方法栈帧会被弹出虚拟机栈。栈帧存储了方法的局部变量表,操作数栈,动态连接和方法返回地址等信息。
在编译程序代码的时候,栈帧中需要多大的局部变量表内存,多深的操作数栈都已经完全确定了。 因此一个栈帧需要分配多少内存,不会受到程序运行期变量数据的影响,而仅仅取决于具体的虚拟机实现。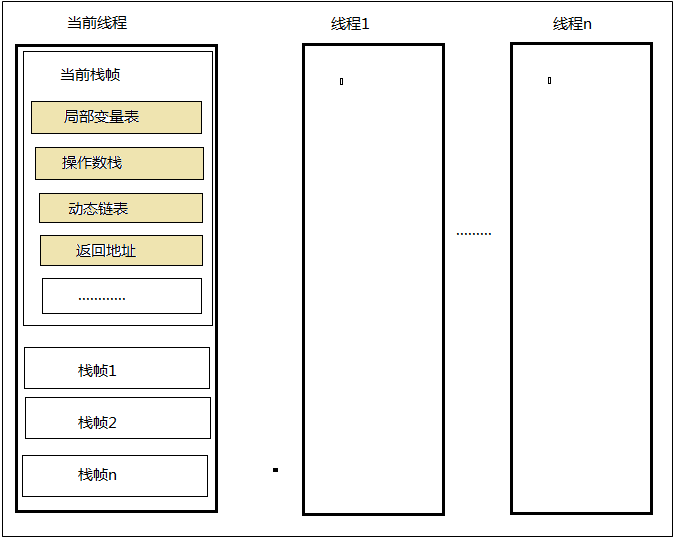
注意:
在活动线程中,只有位于栈顶的栈帧才是有效的,称为当前栈帧,与这个栈帧相关联的方法称为当前方法。
执行引擎运行的所有字节码指令都只针对当前栈帧进行操作。
1.2.2.2 局部变量表
- 局部变量表(Local Variable Table)是一组变量值存储空间,用于存放方法参数和方法内部定义的局部变量。并且在Java编译为Class文件时,就已经确定了该方法所需要分配的局部变量表的最大容量。
- 局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)「String是引用类型」,对象引用(reference类型) 和 returnAddress类型(它指向了一条字节码指令的地址)
注意:
很多人说:基本数据和对象引用存储在栈中。
当然这种说法虽然是正确的,但是很不严谨,只能说这种说法针对的是局部变量。
局部变量存储在局部变量表中,随着线程而生,线程而灭。并且线程间数据不共享。
但是,如果是成员变量,或者定义在方法外对象的引用,它们存储在堆中。
因为在堆中,是线程共享数据的,并且栈帧里的命名就已经清楚的划分了界限 : 局部变量表!
1.2.2.3 变量槽
局部变量表的容量以变量槽为最小单位,每个变量槽都可以存储32位长度的内存空间,例如boolean、byte、char、short、int、float、reference。
对于64位长度的数据类型(long,double),虚拟机会以高位对齐方式为其分配两个连续的Slot空间,也就是相当于把一次long和double数据类型读写分割成为两次32位读写。
1.2.2.4 动态链接
在一个class文件中,一个方法要调用其他方法,需要将这些方法的符号引用转化为其在内存地址中的直接引用,而符号引用存在于方法区中的运行时常量池。
Java虚拟机栈中,每个栈帧都包含一个指向运行时常量池中该栈所属方法的符号引用,持有这个引用的目的是为了支持方法调用过程中的动态连接(Dynamic Linking)。
这些符号引用一部分会在类加载阶段或者第一次使用时就直接转化为直接引用,这类转化称为静态解析。另一部分将在每次运行期间转化为直接引用,这类转化称为动态连接。
1.2.2.5 方法出口
当一个方法开始执行后,只有2种方式可以退出这个方法 :
方法返回指令 : 执行引擎遇到一个方法返回的字节码指令,这时候有可能会有返回值传递给上层的方法调用者,这种退出方式称为正常完成出口。
异常退出 : 在方法执行过程中遇到了异常,并且没有处理这个异常,就会导致方法退出。
无论采用任何退出方式,在方法退出之后,都需要返回到方法被调用的位置,程序才能继续执行,方法返回时可能需要在栈帧中保存一些信息。
一般来说,方法正常退出时,调用者的PC计数器的值可以作为返回地址,栈帧中会保存这个计数器值。
而方法异常退出时,返回地址是要通过异常处理器表来确定的,栈帧中一般不会保存这部分信息。
1.2.2.6 操作数栈
操作数栈(Operand Stack)也常称为操作栈,它是一个后入先出栈(LIFO)。同局部变量表一样,操作数栈的最大深度也在编译的时候写入到方法的Code属性的max_stacks数据项中。
操作数栈的每一个元素可以是任意Java数据类型,32位的数据类型占一个栈容量,64位的数据类型占2个栈容量,且在方法执行的任意时刻,操作数栈的深度都不会超过max_stacks中设置的最大值。
当一个方法刚刚开始执行时,其操作数栈是空的,随着方法执行和字节码指令的执行,会从局部变量表或对象实例的字段中复制常量或变量写入到操作数栈,再随着计算的进行将栈中元素出栈到局部变量表或者返回给方法调用者,也就是出栈/入栈操作。一个完整的方法执行期间往往包含多个这样出栈/入栈的过程。
1.2.2.7 实例
由如下的类,将其编译称为字节码class文件以后。APP.class文件看着像乱码,其实每个都是有对应的含义的,oracle官方是有专门的jvm字节码指令手册来查询每组指令对应的含义的。
package com.juc.learn;public class App {private String name;private Object object = new Object();/**** 运算*/public int add() {int a = 1;int b = 2;int c = (a + b) * 100;return c;}/*** 程序入口*/public static void main(String[] args) throws InterruptedException {App app = new App();int result = app.add();System.out.println(result);}}
jdk有自带一个javap的命令,可以将上述class文件生成一种更可读的字节码文件。
javap -c App.class > App.txt
产生了App.txt文件,内容如下
Compiled from "App.java"public class com.juc.learn.App {public com.juc.learn.App();Code:0: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: aload_05: new #2 // class java/lang/Object8: dup9: invokespecial #1 // Method java/lang/Object."<init>":()V12: putfield #3 // Field object:Ljava/lang/Object;15: returnpublic int add();Code:0: iconst_11: istore_12: iconst_23: istore_24: iload_15: iload_26: iadd7: bipush 1009: imul10: istore_311: iload_312: ireturnpublic static void main(java.lang.String[]) throws java.lang.InterruptedException;Code:0: new #4 // class com/juc/learn/App3: dup4: invokespecial #5 // Method "<init>":()V7: astore_18: aload_19: invokevirtual #6 // Method add:()I12: istore_213: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;16: iload_217: invokevirtual #8 // Method java/io/PrintStream.println:(I)V20: return}
我们来详细分析一下,add方法做了哪些事情
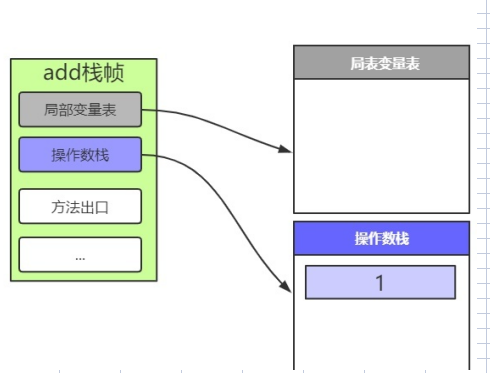
- 压栈
将int类型常量1,压入操作数栈
0: iconst_1 就是将1压入操作数栈
- 存储
将int类型值存入局部变量1
istore_1 局部变量1,在我们代码中也就是第一个局部变量a,先给a在局部变量表中分配内存,然后将int类型的值,也就是目前唯一的一个1存入局部变量a
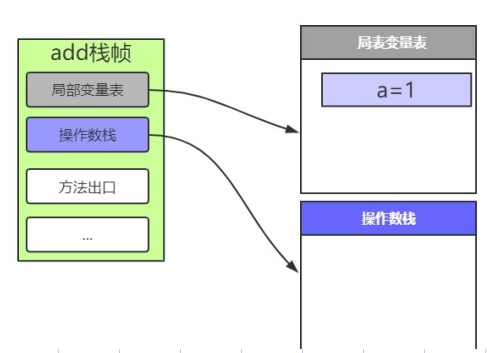
- 第二个变量的存储
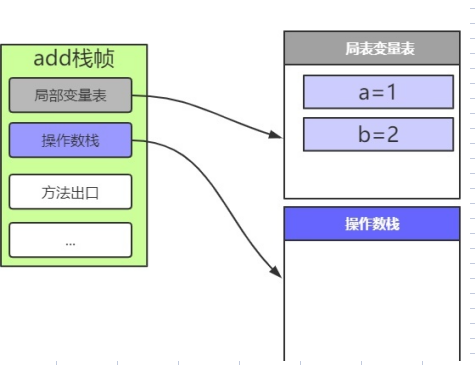
2: iconst_23: istore_2
这两行代码,和上面的一样
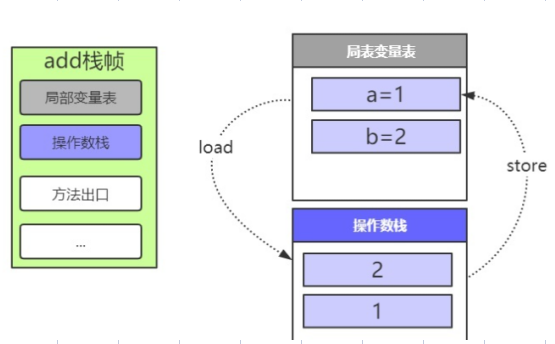
- 装载
4: iload_1 5: iload_2把局部变量表里面的数据,装在到操作数栈中
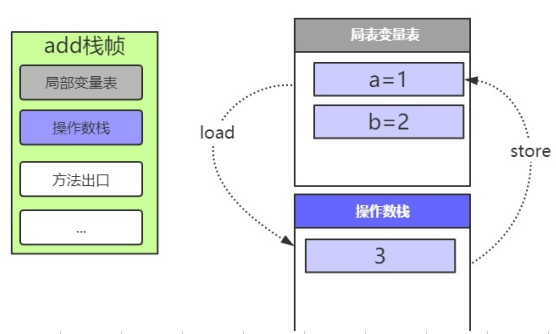
- 执行加法
6: iaddiadd指令以执行,会将操作数栈中的1和2依次从栈中弹出并且相加,然后把运算结果再压入操作数栈中
- 压栈 100
将一个8位带符号整数压入栈
7: bipush 100这个指令就是将100压入栈
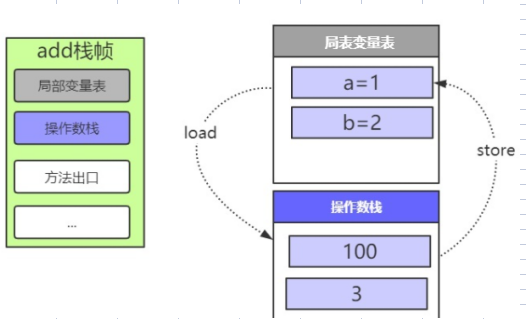
- 乘法
9: imul
这里就类似上面的加法了,将3和100弹出栈,把结果300压入栈
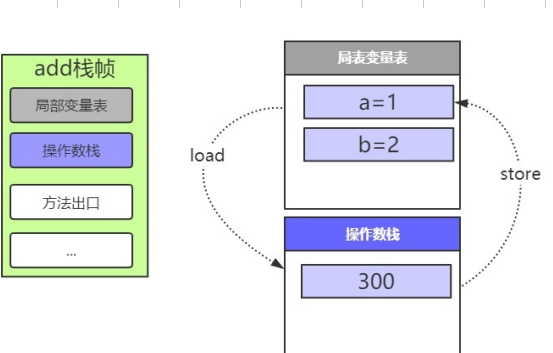
- 存储结果
10: istore_3
将300存入局部变量3,也就是c
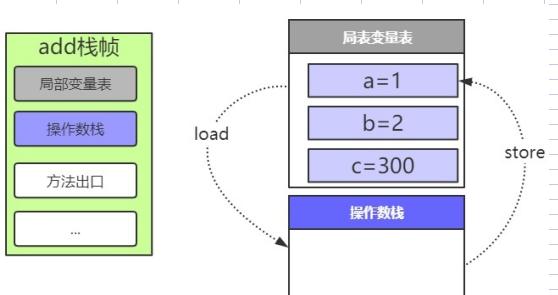
- 装载
11: iload_3
从局表变量3加载到操作数栈
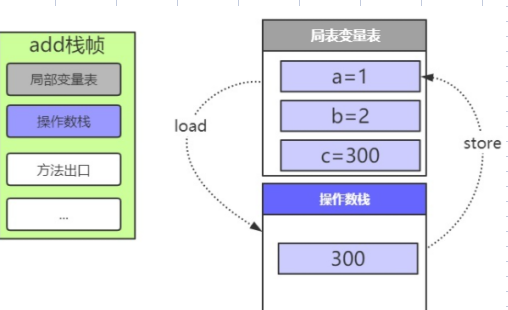
- 返回
我们add方法是被main方法中调用的,所以通过方法出口返回到mian方法中result变量存储。
方法出口就是方法执行完了之后要出到哪里,那么我们知道上面add()方法执行完之后应该回到main()方法第三行那么当main()方法调用add()的时候,add()栈帧中的方法出口就存储了当前要回到的位置,那么当add()方法执行完之后,会根据方法出口中存储的相关信息回到main()方法的相应位置。看图中的红线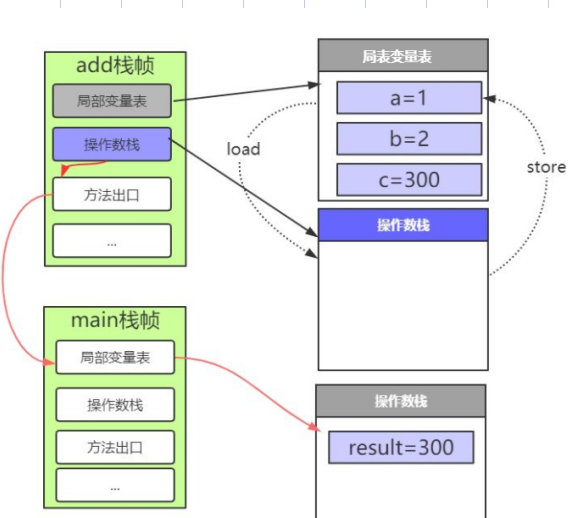
1.2.3 本地方法栈
1.2.3.1 本地方法
一个Native Method就是一个Java调用非Java代码的接囗。该方法的实现由非Java语言实现,比如C。这个特征并非Java所特有,很多其它的编程语言都有这一机制,比如在C++中,你可以用extern “C” 告知C++编译器去调用一个C的函数。
“A native method is a Java method whose implementation is provided by non-java code.”
在定义一个native method时,并不提供实现体(有些像定义一个Java interface),因为其实现体是由非java语言在外面实现的。
例如java.lang.Object中的public final native Class<?> getClass()方法;又如java.lang.Thread中的private native void start0()方法… …
/**
* Returns the runtime class of this {@code Object}. The returned
* {@code Class} object is the object that is locked by {@code
* static synchronized} methods of the represented class.
*
* <p><b>The actual result type is {@code Class<? extends |X|>}
* where {@code |X|} is the erasure of the static type of the
* expression on which {@code getClass} is called.</b> For
* example, no cast is required in this code fragment:</p>
*
* <p>
* {@code Number n = 0; }<br>
* {@code Class<? extends Number> c = n.getClass(); }
* </p>
*
* @return The {@code Class} object that represents the runtime
* class of this object.
* @jls 15.8.2 Class Literals
*/
public final native Class<?> getClass();
本地接口的作用是融合不同的编程语言为Java所用,它的初衷是融合C/C++程序。
Tips:标识符native可以与其它java标识符连用,abstract除外。
1.2.3.2 为什么需要本地方法
- 与java环境交互
有时Java应用需要与Java外面的环境交互,这是本地方法存在的主要原因。你可以想想Java需要与一些底层系统,如操作系统或某些硬件交换信息时的情况。本地方法正是这样一种交流机制:它为我们提供了一个非常简洁的接口,而且我们无需去了解Java应用之外的繁琐的细节。
- 与操作系统交互
JVM支持着Java语言本身和运行时库,它是Java程序赖以生存的平台,它由一个解释器(解释字节码)和一些连接到本地代码的库组成。然而不管怎样,它毕竟不是一个完整的系统,它经常依赖于一底层系统的支持。这些底层系统常常是强大的操作系统。通过使用本地方法,我们得以用Java实现了jre的与底层系统的交互,甚至JVM的一些部分就是用C写的。还有,如果我们要使用一些Java语言本身没有提供封装的操作系统的特性时,我们也需要使用本地方法。
1.2.3.3 本地方法栈图示
和虚拟机栈相似,也有自己的局部变量表,操作数栈,动态链接等等。方法执行完毕后相应的栈帧也会出栈并释放内存空间,也会出现 StackOverFlowError 和 OutOfMemoryError 两种错误。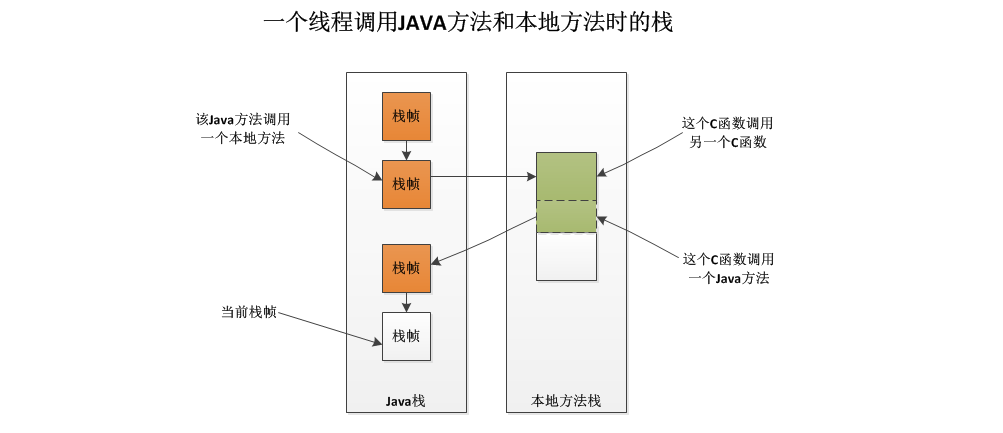
1.2.4 堆
堆是虚拟机管理的内存中最大的一块,是所有线程共享的一块内存区域,再虚拟机启动的时候创建。此区域用来存放对象实例,几乎所有的对象实例以及数组都再这里分配内存。(但随着JIT编译器发展,也有的对象再栈上分配内存)
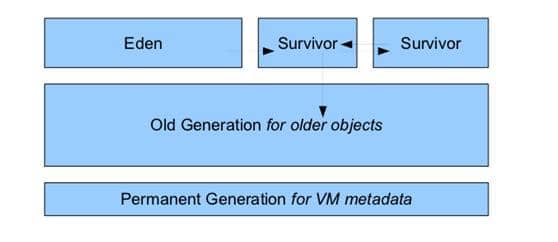
堆是垃圾收集器管理的主要区域,因此也被称为GC堆(Garbage Collected Heap)。因为收集器基本采用垃圾分代回收算法,所以堆还可以划分为:新生代(里面又有伊甸园,幸存者区1,幸存者区2),老年代,永久代
1.2.4.1 java8之前
堆内存通常被分为三个部分
- 新生代(Young Generation)
- 老年代(Old Generation)
- 永久代(Permanent Generation)
1.2.4.2 java8以后
方法区(hotspot的永久代)被彻底移出堆中,取而代之的是元空间。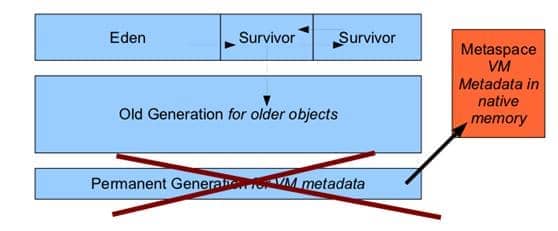
1.2.4.3 年轻代补充
年轻代可以细化为Eden, SurvivorFrom, SurvivorTo。大部分情况下,对象会现在Eden分配内存,再一次新生代垃圾回收后,如果对象还或者,就把这个对象放进SurvivorFrom或者 SurvivorTo,并且年龄+1。当年龄增加到一定程度(默认15),就会被放到老年代中。
这个15的阈值,可以通过
-XX:MaxTenuringThreshold
来设置。
1.2.5 方法区
方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然 Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 Non-Heap(非堆),目的应该是与 Java 堆区分开来。方法区也被称为永久代。
1.2.5.1 方法区和永久代的关系
《Java 虚拟机规范》只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。那么,在不同的 JVM 上方法区的实现肯定是不同的了。
方法区和永久代的关系很像 Java 中接口和类的关系,类实现了接口,而永久代就是 HotSpot 虚拟机对虚拟机规范中方法区的一种实现方式。 也就是说,永久代是 HotSpot 的概念,方法区是 Java 虚拟机规范中的定义,是一种规范,而永久代是一种实现,一个是标准一个是实现,其他的虚拟机实现并没有永久代这一说法
1.2.5.2 常用参数
- java8之前 ```java //方法区 (永久代) 初始大小 -XX:PermSize=N
//方法区 (永久代) 最大大小,超过这个值将会抛出 OutOfMemoryError // 异常:java.lang.OutOfMemoryError: PermGen -XX:MaxPermSize=N
- java8之后
```java
//设置 Metaspace 的初始(和最小大小)
-XX:MetaspaceSize=N
//设置 Metaspace 的最大大小
-XX:MaxMetaspaceSize=N
1.2.5.3 为什么用元空间代替方法区
- 整个永久代有一个 JVM 本身设置的固定大小上限,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
- 元空间里面存放的是类的元数据,这样加载多少类的元数据就不由 MaxPermSize 控制了, 而由系统的实际可用空间来控制,这样能加载的类就更多了。
- 为永久代设置空间是很难确定的
- 对永久代进行调优是很困难的
1.2.6 常量池
1.2.6.1 Class文件常量池
常量池里面存放的东西,如图所示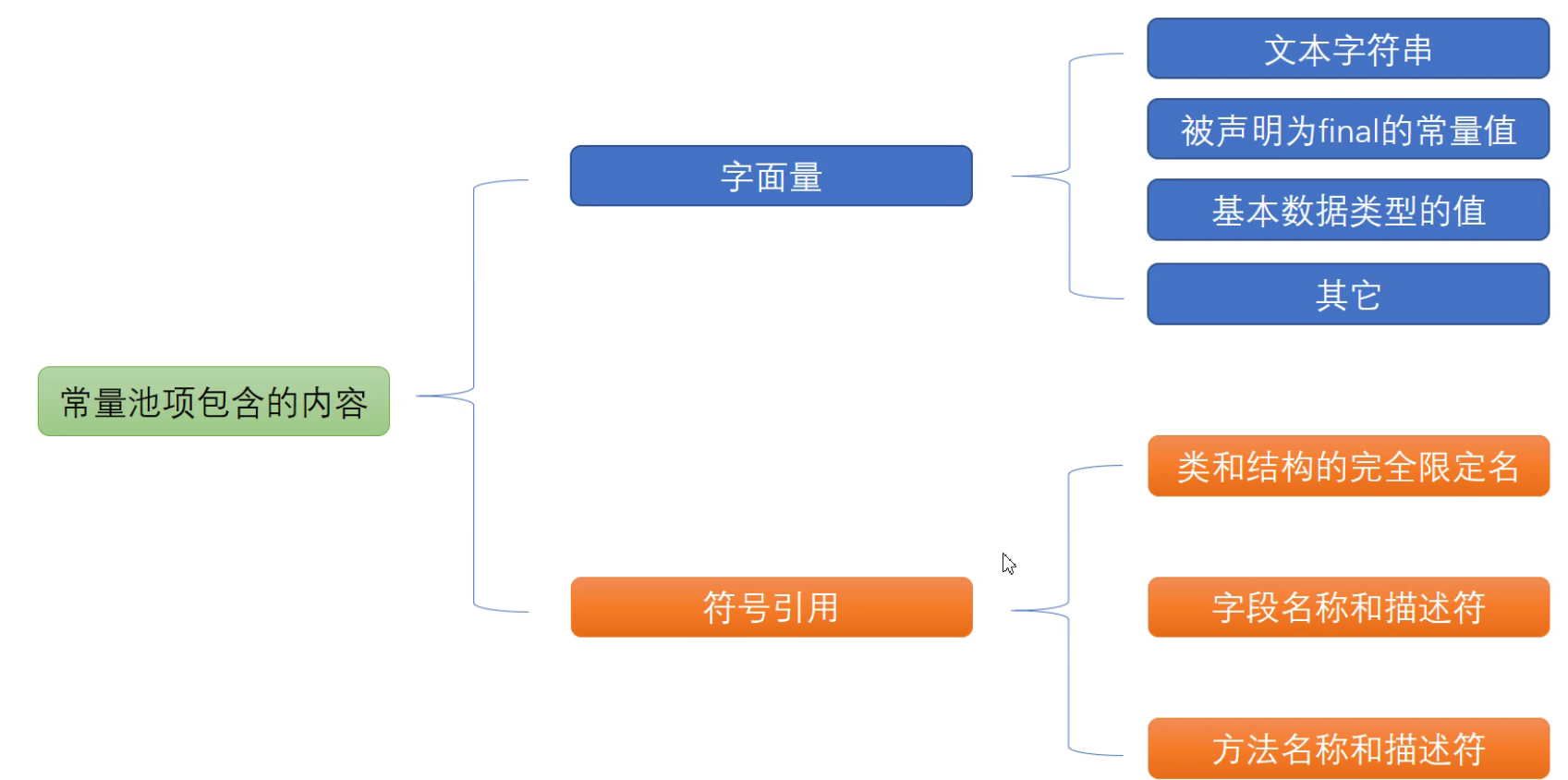
看了上图,其实也不知道常量池是个啥东西。上代码
package com.juc.learn;
public class Review {
public static void main(String[] args) {
String info = "点赞";
int a = 6666;
final int b = 666;
}
}
编译之后使用javap命令,来查看字节码文件javap -v Review.class
Classfile /D:/ITLearning/Java/jucLearning/target/classes/com/juc/learn/Review.class
Last modified 2021/11/30; size 494 bytes
MD5 checksum efdc15d57b1f55c326ee422831fe0d91
Compiled from "Review.java"
public class com.juc.learn.Review
minor version: 0
major version: 52
flags: (0x0021) ACC_PUBLIC, ACC_SUPER
this_class: #3 // com/juc/learn/Review
super_class: #4 // java/lang/Object
interfaces: 0, fields: 0, methods: 2, attributes: 1
// 注意,这里就是常量池
Constant pool:
#1 = Methodref #4.#23 // java/lang/Object."<init>":()V
// #2的位置是一个string, 这个string真正的位置,是在#24, 那么就去找#24的位置
#2 = String #24 // 点赞
#3 = Class #25 // com/juc/learn/Review
#4 = Class #26 // java/lang/Object
#5 = Utf8 <init>
#6 = Utf8 ()V
#7 = Utf8 Code
#8 = Utf8 LineNumberTable
#9 = Utf8 LocalVariableTable
#10 = Utf8 this
// 类的全限定名
#11 = Utf8 Lcom/juc/learn/Review;
// 方法和描述符
#12 = Utf8 main
#13 = Utf8 ([Ljava/lang/String;)V
#14 = Utf8 args
#15 = Utf8 [Ljava/lang/String;
// 字段名称和描述符
#16 = Utf8 info
#17 = Utf8 Ljava/lang/String;
// 字段名称和描述符
#18 = Utf8 a
#19 = Utf8 I
#20 = Utf8 b
#21 = Utf8 SourceFile
#22 = Utf8 Review.java
#23 = NameAndType #5:#6 // "<init>":()V
// #24的位置是一个utf8编码的点赞的字符串。 文本字符串
#24 = Utf8 点赞
#25 = Utf8 com/juc/learn/Review
#26 = Utf8 java/lang/Object
{
public com.juc.learn.Review();
descriptor: ()V
flags: (0x0001) ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/juc/learn/Review;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=4, args_size=1
// ldc 从常量池找#2的位置,加载到操作数栈中
0: ldc #2 // String 点赞
// astore 把操作数栈的值,赋值到局部变量表中
2: astore_1
3: sipush 6666
6: istore_2
7: sipush 666
10: istore_3
11: return
LineNumberTable:
line 5: 0
line 6: 3
line 7: 7
line 8: 11
LocalVariableTable:
Start Length Slot Name Signature
0 12 0 args [Ljava/lang/String;
3 9 1 info Ljava/lang/String;
7 5 2 a I
11 1 3 b I
}
SourceFile: "Review.java"
1.2.6.2 运行时常量池
在class常量池里面,#数字这些东西,在程序运行起来的时候,把class文件加载到内存中,会把这些占位的#数字,转换为内存中的真正的地址,这就变成了运行时常量池。
每一个class一个运行时常量池。JV规范中如下描述:The Java Virtual Machine maintains a run-time constant pool for each class and interface .M
1.2.6.3 字符串常量池
自己定义的用双引号引起来的字符串,就是存放在字符串常量池中的。
- JDK1.7 之前运行时常量池逻辑包含字符串常量池存放在方法区, 此时 hotspot 虚拟机对方法区的实现为永久代
- JDK1.7 字符串常量池被从方法区拿到了堆中, 这里没有提到运行时常量池,也就是说字符串常量池被单独拿到堆,运行时常量池剩下的东西还在方法区, 也就是 hotspot 中的永久代 。
- JDK1.8 hotspot 移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆, 运行时常量池还在方法区, 只不过方法区的实现从永久代变成了元空间(Metaspace)
1.3 HotSpot虚拟机对象
1.3.1 对象的创建
以下是对象创建的过程,需要默写出来,掌握每一步都干了什么。
- 类加载检查
- 分配内存
- 初始化零值
- 设置对象头
- 执行init方法
1.3.1.1 类加载检查
首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
1.3.1.2 分配内存
类加载检查通过后,接下来虚拟机为新生对象分配内存。所需的内存大小在类加载完成后便可以确定,分配时,把一块确定大小的内存从java堆中划分出来。
分配方式有 指针碰撞 和 空闲列表 两种。选择哪种分配方式由java堆是否规整决定,而java堆是否规整又取决于所采用的垃圾收集器是否带有压缩整理功能。
内存分配的两种方式:(补充内容,需要掌握)
选择以上两种方式中的哪一种,取决于 Java 堆内存是否规整。而 Java 堆内存是否规整,取决于 GC 收集器的算法是”标记-清除”,还是”标记-整理”(也称作”标记-压缩”),值得注意的是,复制算法内存也是规整的
1.3.1.3 初始化零值
内存分配完成以后,虚拟机需要将分配到的内存空间到初始化为零值(不包括对象头),这保证了对象的实例字段在java代码中可以不赋初始值就可以直接使用。
1.3.1.4 设置对象头
初始化零值完成之后,虚拟机要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息。 这些信息存放在对象头中。 另外,根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
1.3.1.5 执行init方法
在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,
这个init方法,执行的就是构造方法。
1.3.2 对象的内存布局
Java中通过new关键字创建一个类的实例对象,对象存于内存的堆中并给其分配一个内存地址,那么如下这些问题的答案是什么呢?
- 这个实例对象是以怎样的形态存在与内存中的?
- 一个Object对象在内存中占用多大?
- 对象中的属性是如何在内存中分配的?
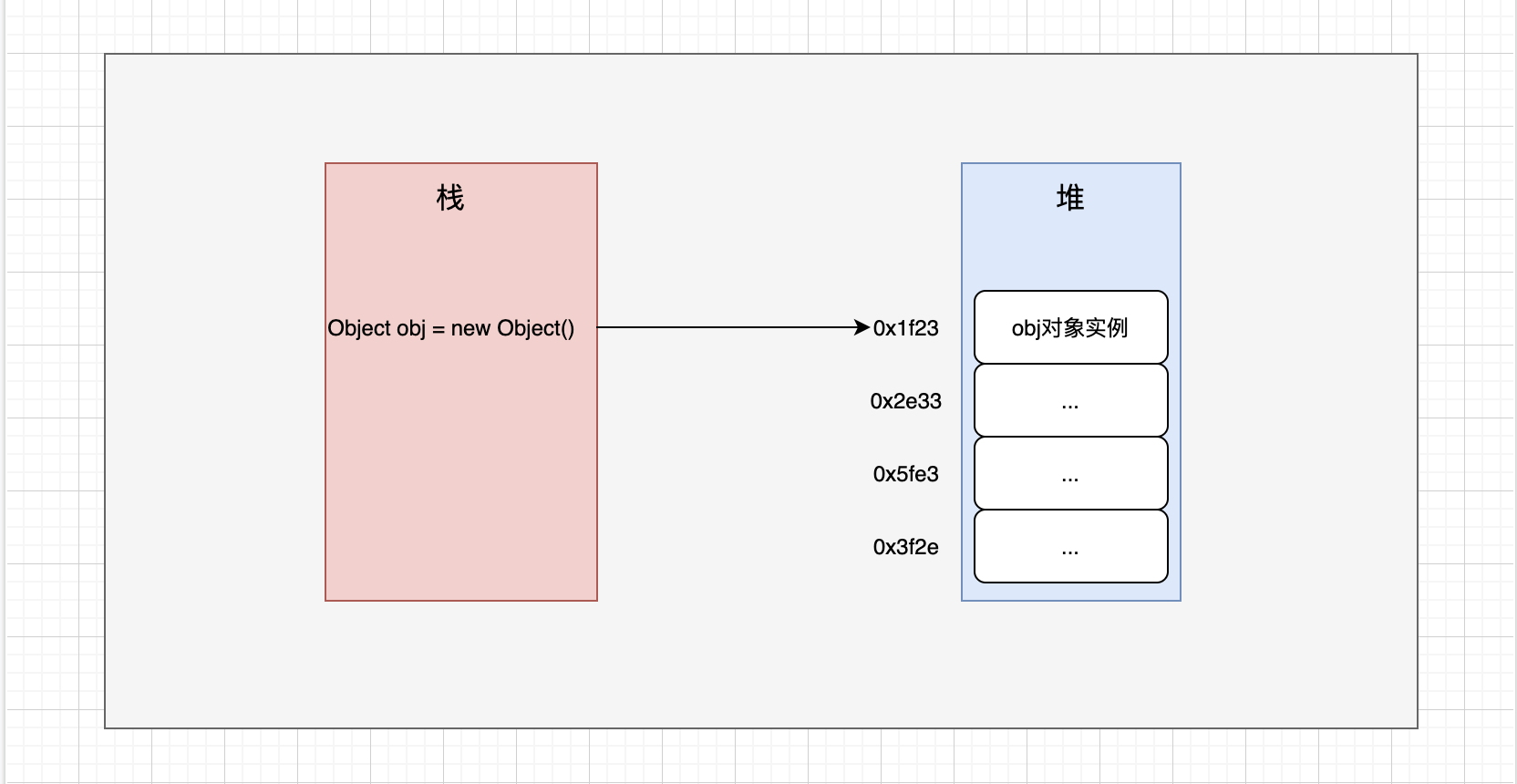
在JVM中,Java对象保存在堆中时,由以下三部分组成。
- 对象头(Object header):包括了关于堆对象的布局,类型,GC状态,同步状态和表实哈希码的基本信息。Java对象和vm内部对象都有一个共同的对象头格式
- 实例数据(Instance Data):主要时存放类的数据信息,父类的信息,对象字段属性信息。
- 对其填充(Padding):为了字节对齐,填充的数据,不是必须的
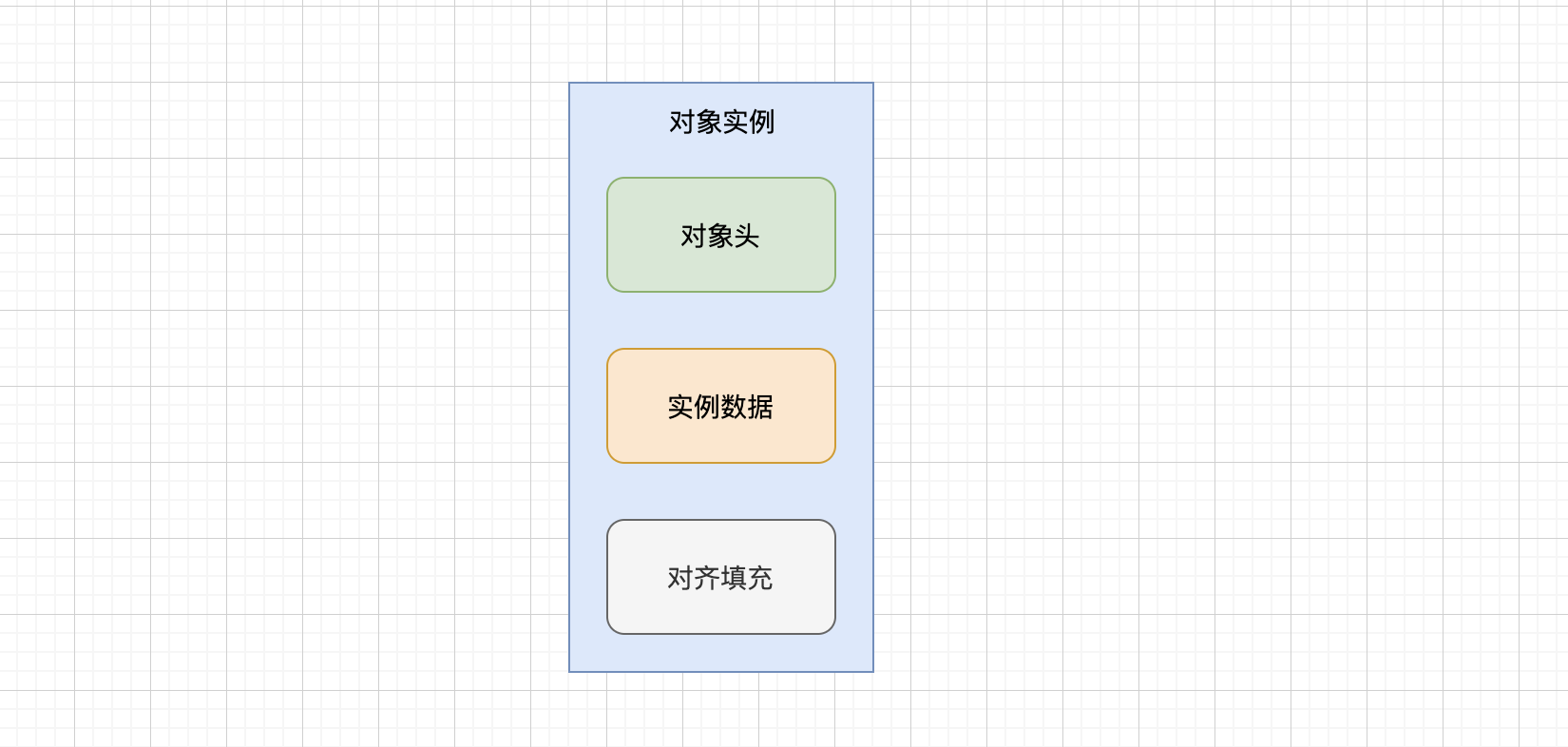
1.3.2.1 对象头
普通的对象由两部分组成mark word 和 klass pointer。如果时数组对象的话,那么还有一个length来记录数组的长度。
- Mark Word
用于存储对象自身的运行时数据,如哈希码(HashCode),GC分代年龄,锁状态标志,线程持有的锁,偏向线程ID,偏向时间戳等。Mark Word在32位JVM中的长度是32bit,在64位JVM中长度是64bit。
Mark Word在不同的锁状态下存储的内容不同,在32位JVM中是这么存的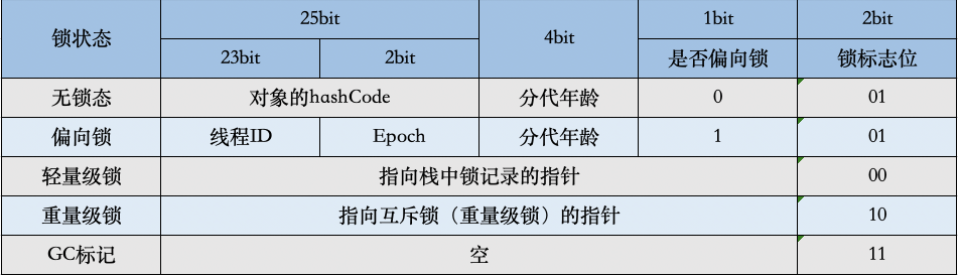
在64位JVM中是这么存的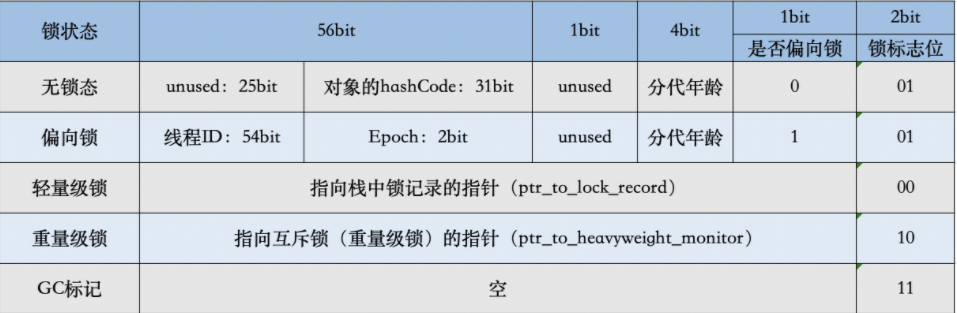
虽然在不同位数的JVM中长度不一样,但是基本组成内容是一致的。
- 锁标识位(Lock):区分锁状态,11时表实对象等待GC回收状态,只有最后2为锁标识(11)有效
- 偏向锁(Biased_Lock):是否偏向锁,由于无缩和偏向锁的锁标识都是01,没办法区分,这里引入以为的偏向锁标识位
- 分代年龄(age):表示对象被GC的次数,当该次数达到阈值的时候,对象就会转移到老年代
- 对象的HashCode(hash):运行期间调用System.identityHashCode()来计算,延迟计算,并把运行结果赋值到这里。当对象加锁后,计算的结果31位不够表示,在偏向锁,轻量锁,重量锁,hashCode会被转移到Monitor中。
- 偏向锁的线程ID(JavaThread):偏向模式的时候,当某个线程持有对象的时候,对象这里就会被置为该线程的ID。在后面的操作中,就无需再进行尝试获取锁的动作。
- epoch:偏向锁在CAS锁操作过程中,偏向性标识,表示对象更偏向哪个锁。
- ptr_to_lock_record:轻量级锁状态下,指向栈中锁记录的指针。当锁获取是无竞争的时,JVM使用原子操作而不是OS互斥。这种技术称为轻量级锁定。在轻量级锁定的情况下,JVM通过CAS操作在对象的标题字中设置指向锁记录的指针。
- ptr_to_heavyweight_monitor:重量级锁状态下,指向对象监视器Monitor的指针。如果两个不同的线程同时在同一个对象上竞争,则必须将轻量级锁定升级到Monitor以管理等待的线程。在重量级锁定的情况下,JVM在对象的ptr_to_heavyweight_monitor设置指向Monitor的指针。
1.3.2.2 KlassPointer 类指针
即类型指针,时对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象时哪个类的实例。
1.3.2.3 实例数据
如果对象有属性字段,则这里会有数据信息。如果对象无属性字段,则这里就不会有数据。根据字段类型的不同占不同的字节,例如:boolean类型占一个字节,int类型占4个字节。
1.3.2.4 对其数据
对象可以有对齐数据也可以没有。默认情况下,Java虚拟机堆中对象的起始地址需要对齐至8的倍数。如果一个对象用不到8N个字节则需要对其填充,以此来补齐对象头和实例数据占用内存之后剩余的空间大小。如果对象头和实例数据已经占满了JVM所分配的内存空间,那么就不用再进行对齐填充了。
所有的对象分配的字节总SIZE需要是8的倍数,如果前面的对象头和实例数据占用的总SIZE不满足要求,则通过对齐数据来填满。
为什么要对齐数据?字段内存对齐的其中一个原因,是让字段只出现在同一CPU的缓存行中。如果字段不是对齐的,那么就有可能出现跨缓存行的字段。也就是说,该字段的读取可能需要替换两个缓存行,而该字段的存储也会同时污染两个缓存行。这两种情况对程序的执行效率而言都是不利的。其实对其填充的最终目的是为了计算机高效寻址。
至此,我们已经了解了对象在堆内存中的整体结构布局,如下图所示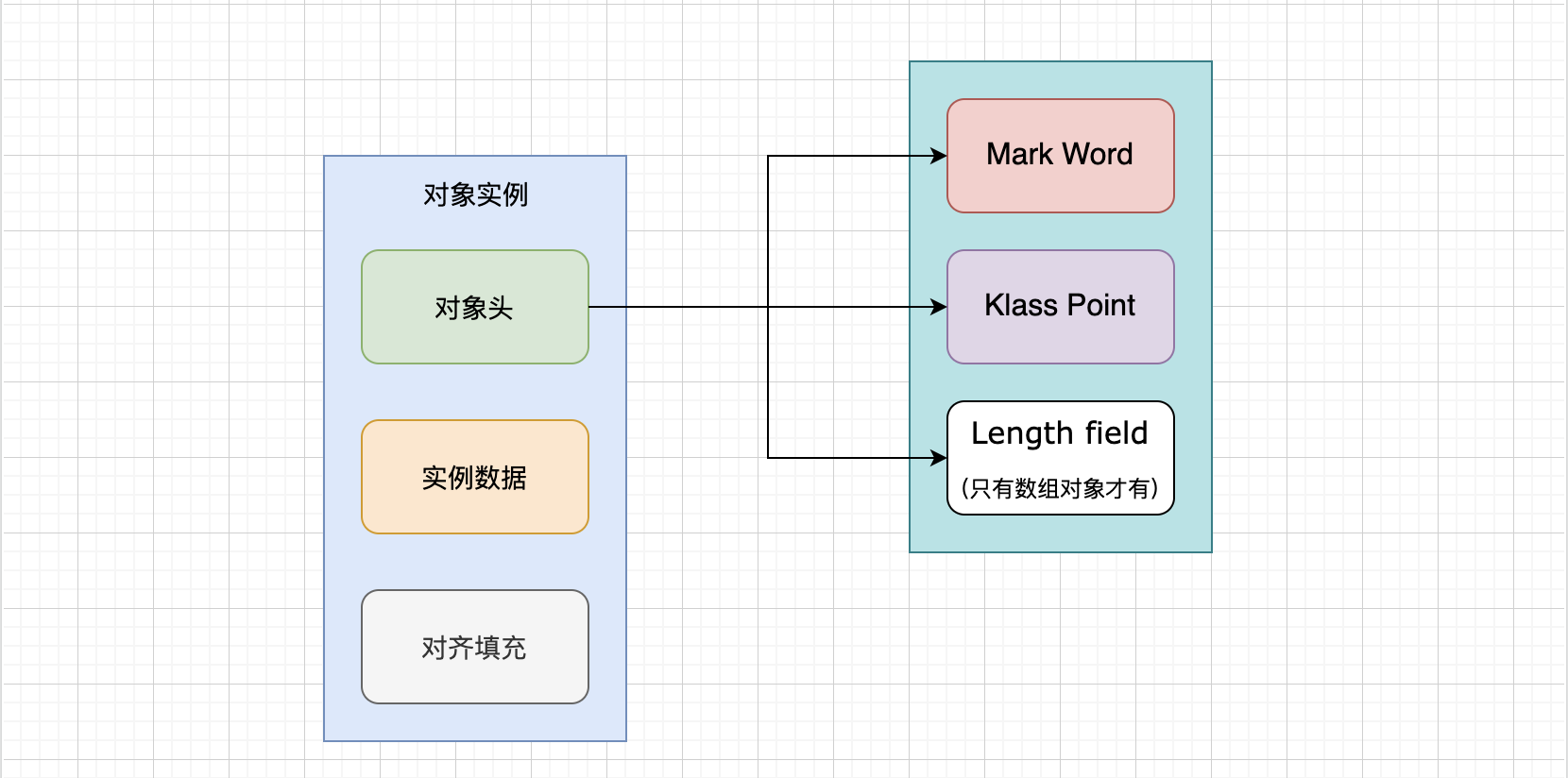

若有收获,就点个赞吧
0 人点赞
