赛题本质是一个文本分类问题,需要根据每句的字符进行分类,但赛题给出的数据是匿名化的,不能直接使用中文分词的操作,要对匿名字符进行建模,进而完成文本分类的过程。
我们先从以下几个方面分析数据的特征。
- 新闻文本长度
- 数据的类别分布
- 数据的字符分布
句子长度分析
在赛题数据中每行句子的字符使用空格进行隔开,所以可以直接统计单词的个数来得到每个句子的长度。
代码:
结果: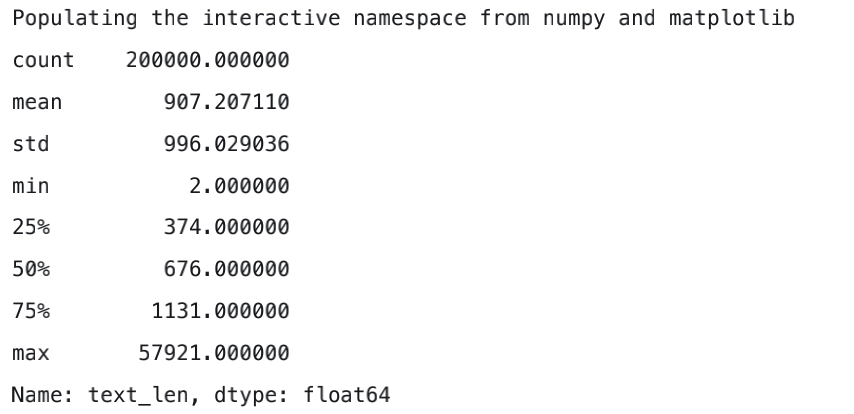
对新闻句子的统计可以得出,本次赛题给定的文本比较长,每个句子平均由907个字符组成,最长的句子长度为57921 。将句子长度绘制直方图后,可见大部分句子的长度都集中在2000以内。可能需要截断。,而截断值为2000。
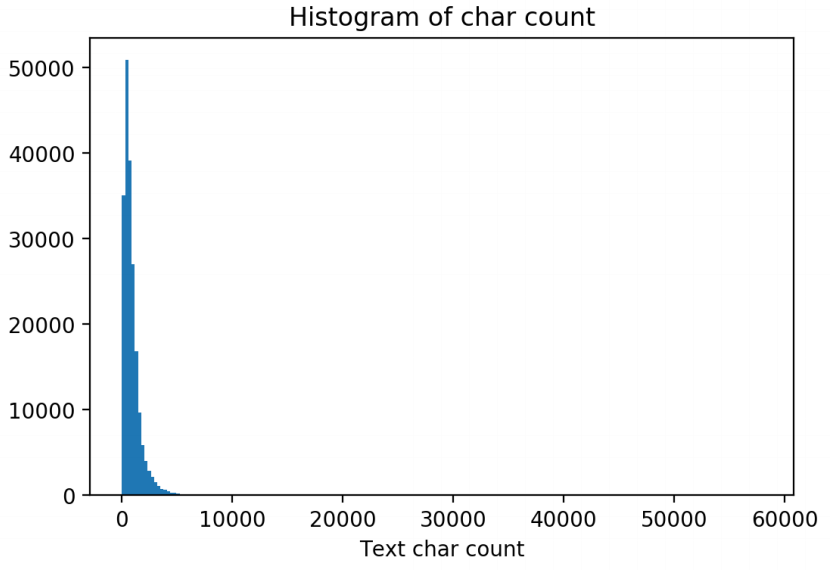
新闻类别分布
对数据集的类别进行分布统计,具体统计每类新闻的样本个数
对应的关系如下:{‘科技’:0,’股票’:1,’体育’:2,’娱乐’:3,’时政’:4,’社会’:5,’教育’:6,’财经’:7,’家居’:8,’游戏’:9,’房产’:10,’时尚’:11,’彩票’:12,’星座’:13}
从统计结果可以看出,赛题的数据集类别分布存在较为不均匀的情况,其中科技类的新闻最多,其次是股票类,星座类的新闻最少。需要用采样方法解决。不同类别的文章长度也不同,可以把长度和句子个数作为一个Feature,以供机器学习模型训练。
字符分布统计
将训练集中所有的句子进行拼接再划分成字符,统计每个字符的数量。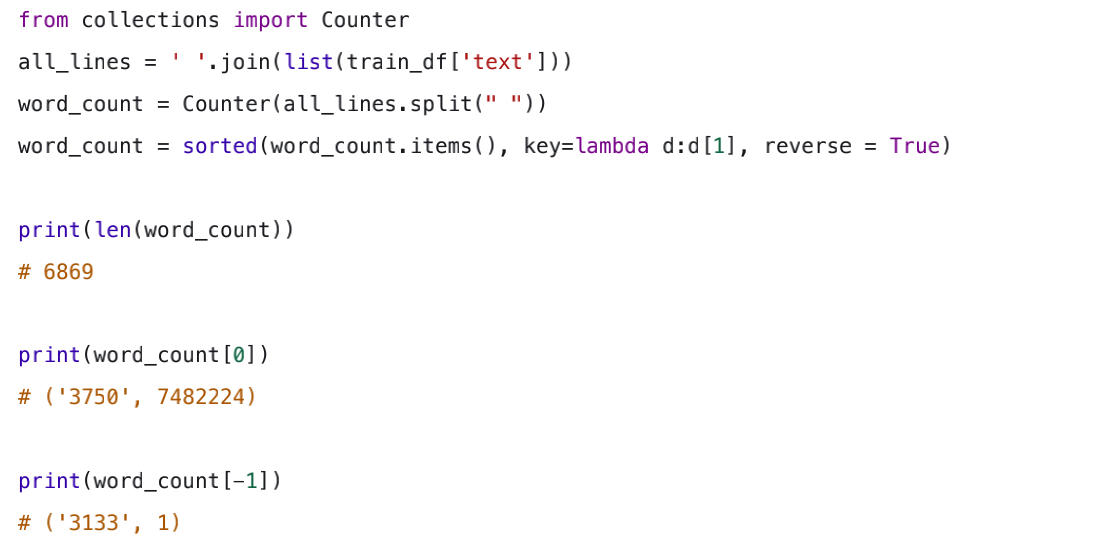
从统计结果可以看出,在训练集中总共包括6869个字,其中编号3750的出现次数最多,而出现最少的3133只出现了一次。
统计不同字符在句子中出现的次数。
其中字符3750、字符900和字符648在20w新闻的覆盖率接近99%,很有可能是标点符号。按照这种划分,训练集中每条新闻平均句子个数约为19。
基于深度学习的模型选型
词嵌入将不定长的文本转换到定长的空间,是文本分类的第一步。
nlp领域,我们也需要构造特征,但是一句话中的文本长度是不定长的,将文本表示成计算机能够运算的数字或向量的方法一般称为词嵌入(word embedding)。
FastText
FastText是一个三层的神经网络,输入层、隐含层和输出层,由于其Embeding空间维度低,可以快速进行训练,但只能分类相似的句子,精度不高。直接Pass。
常见的思路有:
word2vec训练词向量+TextCNN进行文本表示
word2vec训练词向量+TextRNN进行文本表示
BERT(基于双向Transformer的多层Encoder模型)
这四种方法都是当前比较主流的文本分类方法,我们实验就尝试了这四种方法。下面简要介绍一下这四种方法的原理:
word2vec模型
word2vec模型背后的基本思想是对出现在上下文环境里的词进行预测。
对于每个文本我们选取一个上下文窗口和一个中心词,并基于这个中心词取预测窗口里其他词出现的概率。
word2vec的主要思路:通过单词和上下文彼此预测。
对应的两个算法分别为:
Skip-grams(SG):预测上下文
Continuous Bag of Words(CBOW):预测目标单词
从直观理解Skip-grams是给定input word来预测上下文,而CBOW是给定上下文来预测input word。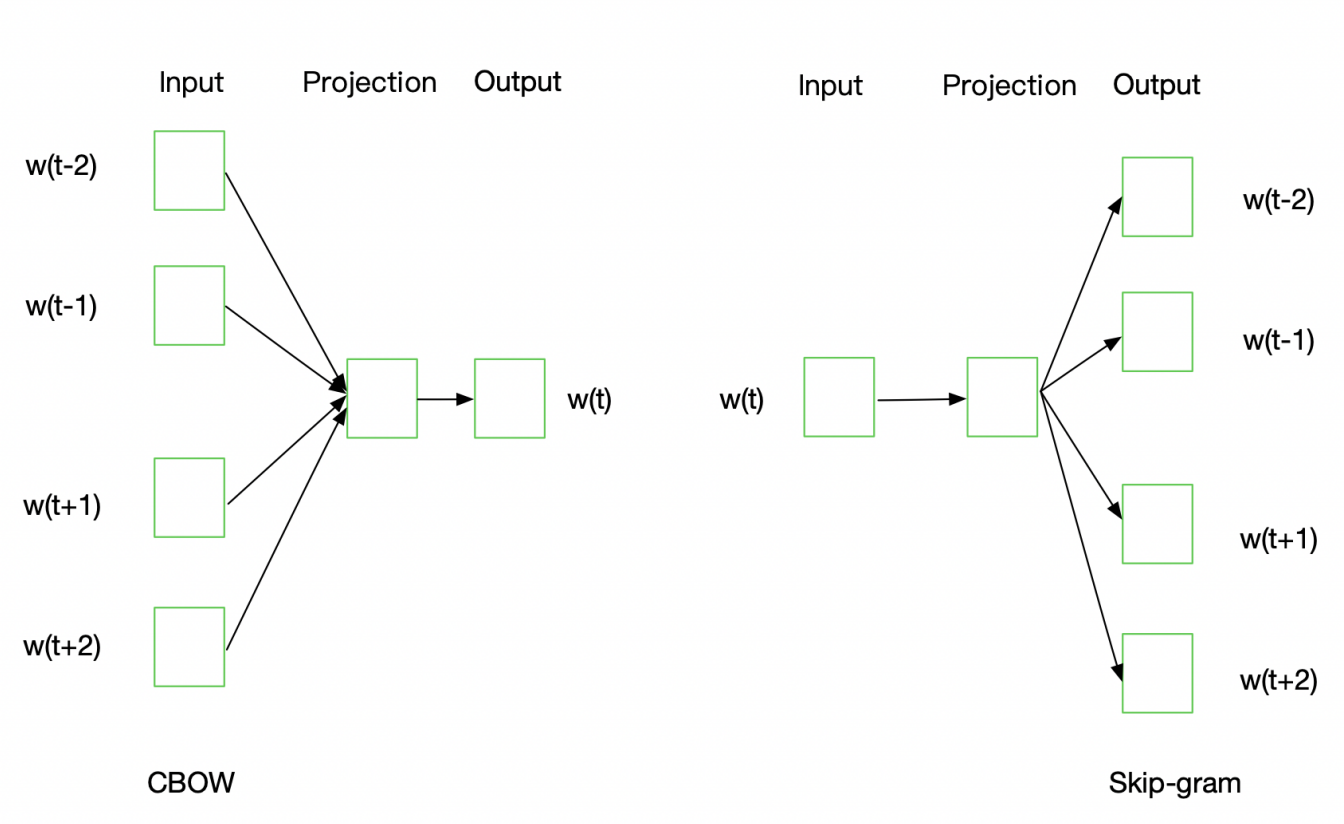
TextCNN
TextCNN利用CNN(卷积神经网络)进行文本特征抽取,不同大小的卷积核分别抽取n-gram特征(加入相邻单词组合成为新的单词,再统计每个字出现的次数),卷积计算出的特征图经过MaxPooling保留最大 的特征值,然后将拼接成一个向量作为文本的表示。
若分别采用100个大小为2,3,4的卷积核,最后得到的文本向量大小为100*3=300维。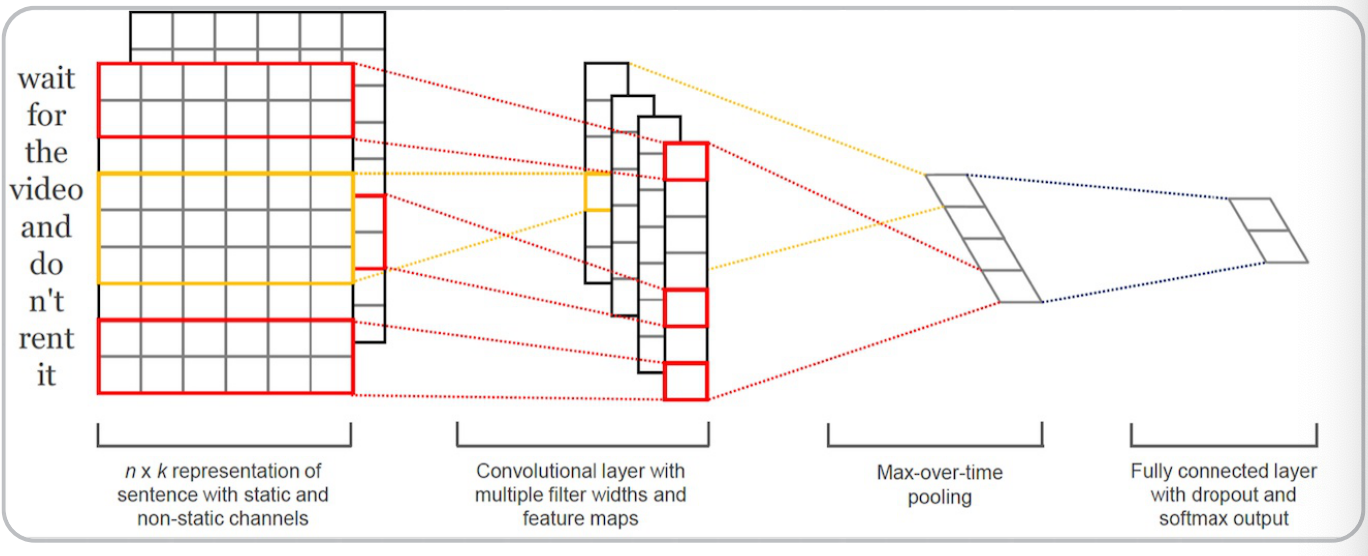
TextRNN
TextRNN利用RNN(循环神经网络)进行文本特征抽取,由于文本本身是一种序列,而LSTM适合建模序列数据。TextRNN将句子中每个词的词向量依次输入到双向双层LSTM,分别将两个方向最后一个有效位置的隐藏层拼接成一个向量作为文本的表示。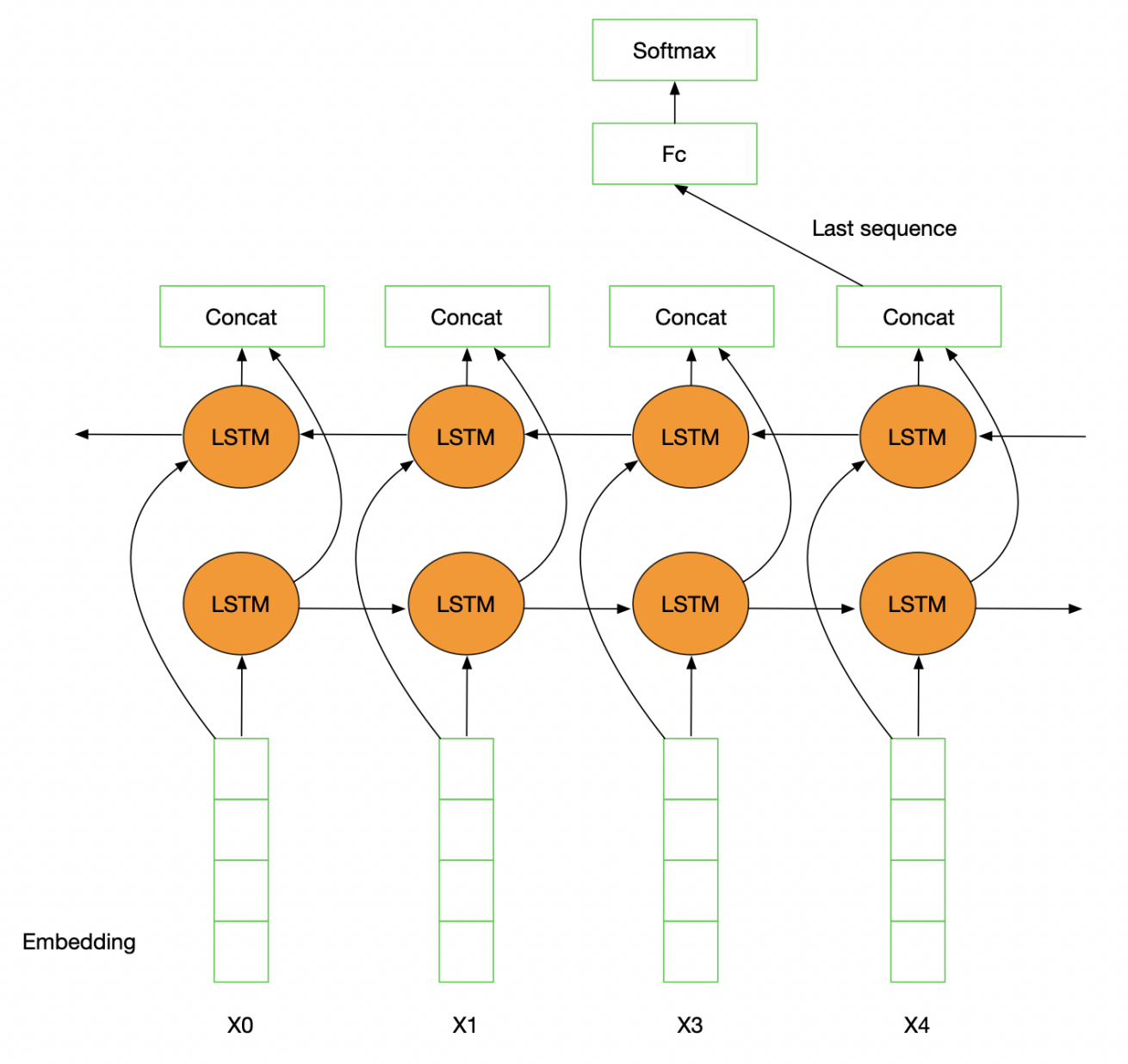
Transformer
Transformer用于BERT的语言模型预训练,模型的编码部分是一组编码器的堆叠,模型的解码部分是由相同数量的解码器的堆叠。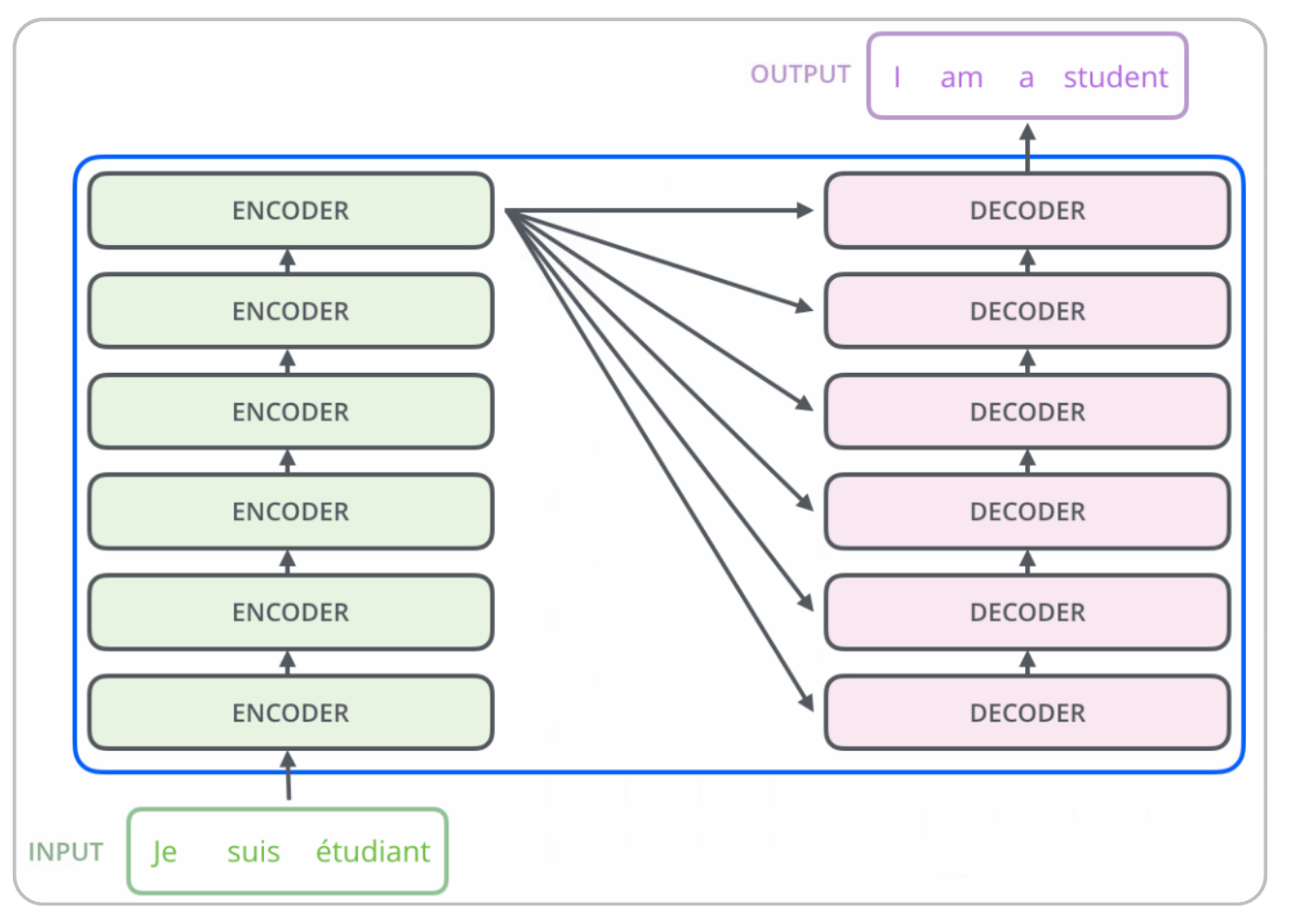
每个编码器可以拆解成两部分:
- 在对输入序列做词的向量化后,首先流过self-attention层,该层帮助编码器在它编码单词时能看到输入序列中的其他单词。
- 随后Self-attention的输出流向一个前向网络,每个输入位置对应的前向网络独立互不干扰。
最后将输出传入下一个编码器。
BERT
BERT模型采用基于预训练语言模型的词表示,通过预训练Transformer模型得到更深层的上下文表示。进而解决了传统静态词向量不能建模“一词多义”的问题。
在模型结构方面采用双向语言模型,并提出掩码语言模型,即类似完形填空的方式通过上下文来预测单词本身,而不是从左到右、从右到左进行建模,这使得模型能够自由编码每个层中来自两个方向的信息。
模型预训练的两个步骤
- 第一个步骤是把一篇文章中,随机选择15% 的词汇遮盖,让模型根据上下文全向地预测被遮盖的词。这些词汇不会一直被遮盖,80%的时间用[MASK]标记替换单词,10%的时间用一个随机的单词替换该单词,10%的时间保持单词不变。通过全向预测被遮盖住的词汇,来初步训练 Transformer 模型的参数。
- 用第二个步骤继续训练模型的参数。句子对中的第二个句子有50%来自与原有的连续句子,其余50%的句子通过在其他句子中随机采样。然后让 Transformer 模型来识别这 20 万对语句,哪些是连续的,哪些不连续。
训练结束后的 Transformer 模型,包括它的参数,是作者期待的通用的语言表征模型。
数据预处理
对TextCNN的数据预处理:
TextCNN可以直接输入数据,所以我们只需处理其训练集和验证集。
这里我们使用10折交叉验证,每折使用9/10的数据进行训练,剩余1/10作为验证集检验模型的效果。
主要代码如下:
首先根据 label 来划分数据行所在 index, 生成 label2id。
label2id 是一个 dict,key 为 label,value 是一个 list,存储的是该类对应的 index。 然后根据label2id,把每一类别的数据,划分到 10 份数据中。
然后根据label2id,把每一类别的数据,划分到 10 份数据中。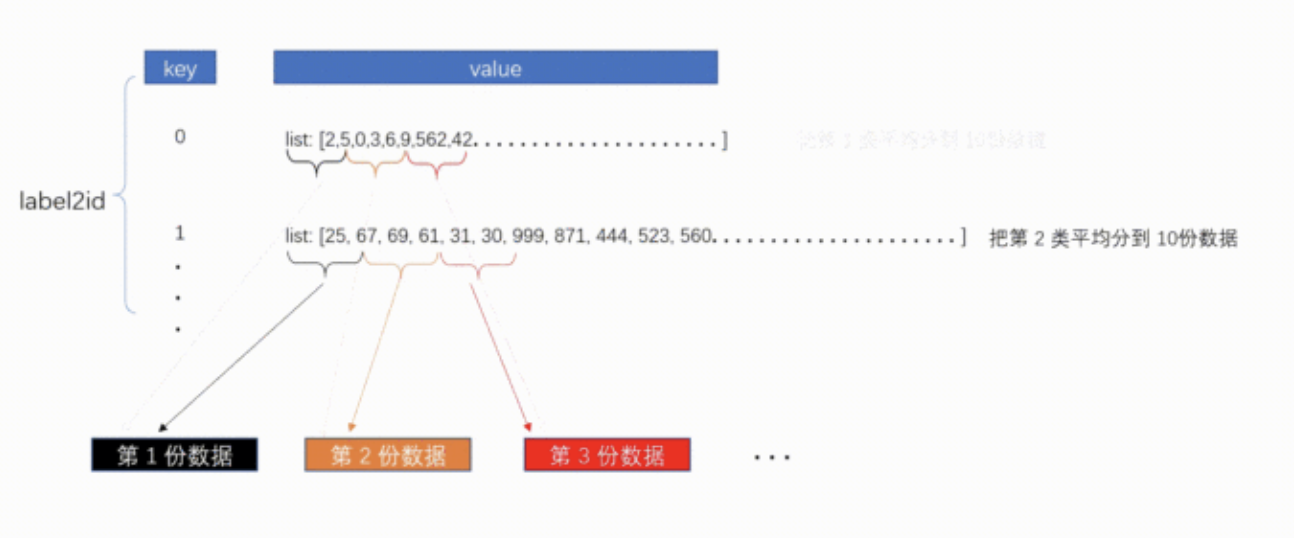
最后,我们把前 9 份数据作为训练集,最后一份数据作为验证集。
对Bert的数据预处理:
我们知道,在 Bert 训练的目标有两个:掩码训练和预测下一句。
在我们的任务中,只有文本分类,而没有上下文句子的推理,所以数据预处理步骤,主要是对文本进行 mask,获得 mask 后的数据。
和TextCNN的预处理类似将数据分成10份。
流程如下:
- 首先读取文件,把每篇文章转换成list并分割为句子
- 在句子前后添加[CLS]和[SEP]
- 开始对句子进行mask操作,随机生成15%的token
- 进入 for 循环,遍历每个 token:
- 首先判断已经生成的 mask 数量是否已经达到
num_to_predict,如果达到了这个数量,则退出循环。 - 80% 的概率替换为
[MASK]。 - 10% 的概率保留原来的 token。
- 10% 的概率替换为随机的一个 token。
- 保存 mask 的位置和真实的 token
- 首先判断已经生成的 mask 数量是否已经达到
- 得到经过mask的所有句子list后,长度补齐,保存到文件中

若有收获,就点个赞吧
0 人点赞
