分类的概念
在已知研究对象可分为若干类的情况下,确定新的对象属于哪一类。
分类的数据分析任务中,需要构建一个模型或者分类器(classifer)来预测类标号。
数据分类是一个两阶段的过程,包括学习阶段(构建分类模型)和分类阶段(使用模型预测给定数据的类标号)。
- 学习阶段
分类算法通过从训练集中学习来构造分类器。训练集由数据库元组和它们相关联的类标号组成。
元组是用n维属性向量表示,,每个元组都属于一个预先定义的类,即确定一个类标号属性。这些元组也叫做样本、实例、数据点或对象。
提供了类标号的的学习也叫监督学习。(分类是监督学习,聚类是无监督学习)
分类的任务就是学习一个从元组到类别的映射 ,给定一组数据,输出类标号。 分类阶段
用第一阶段的模型进行分类,首先要在验证集上预测分类器的准确率,如果认为分类器的准确率是可以接受的,那么就可以用它对类标号未知的数据元组进行分类。
决策树算法
贪心算法
设Dt是与节点t相关联的训练记录集,yi是类标号
- 如果Dt中所有记录都属于同一个类yt,则t是叶节点,用yt标记。
如果Dt中包含属于多个类的记录,则选择一个属性作为测试条件,将记录划分成较小的子集。对于测试条件的每个输出,创建一个子女结点,并根据测试结果将Dt中的记录分布到子女节点中。对每个子女节点,递归调用该算法。
关键问题
如何分裂训练过程(属性选择度量)
- 如何停止分裂过程(剪枝)
基尼指数
连续属性的基尼指数
- 考虑二元划分
- 按照年收入将训练记录排序
- 从两个相邻的排过序的属性值中选择中间值作为候选划分点
- 计算每个候选划分点的Gini值,从中选择具有最小值的候选划分点
熵
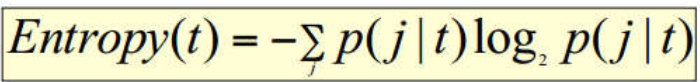
j是该事务集中j的数量,t是该事务集的总数信息增益
Parent的熵-划分后总的子熵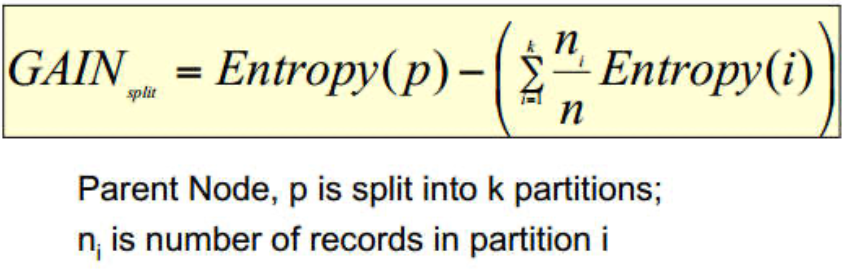
增益率
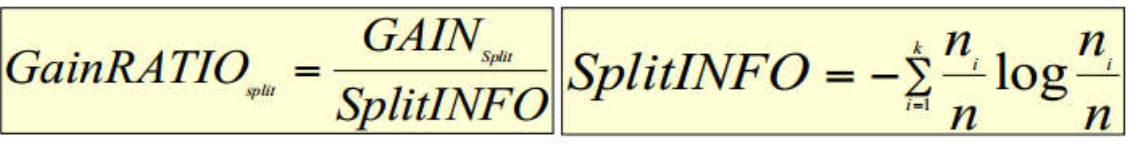
分类误差
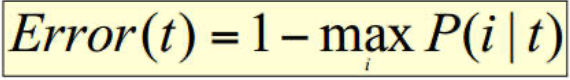
二元属性
标称属性
序数属性
连续属性
划分度量的方法
不纯性度量
二路划分
多路划分
最佳划分标准
父节点(划分前)的不纯程度P和子女节点(划分后)的不纯程度M(加权平均),差距越大,属性测试条件的效果越好!
Gain=P-M
造成模型过分拟合的原因
- 噪声导致的过分拟合
- 缺乏代表性样本导致的过分拟合
训练误差:在训练集中表现出的误差
测试误差:在测试集中表现出的误差
泛化误差估计
- 使用再代入估计
- 结合模型复杂度
- 使用验证集
如何计算各种误差估计?
如何处理过分拟合?
模型评价

精确率和召回率的适应情况

若有收获,就点个赞吧
0 人点赞
