频繁项集
频繁模式是频繁地出现在数据集中的模式(如项集、子序列、或子结构)。
支持度和置信度
支持度
support(A=>B)=P(AUB) 即A和B这两个项集同时在事务集D中出现的概率=AB同时出现次数/总items数量
满足最小支持度阈值的称为频繁项集
用支持度阈值对项集进行筛选。
置信度
confidence(A=>B)=P(B|A)即出现项集A的事务集D中,项集B也同时出现的概率=P(AB)/P(B) AB同时出现的次数/A出现的次数
在同一关系中,支持度是一样的,如support(AB=>C)=support(C=>AB),但对于置信度来说,=>的前后位置是不一样的。
关联规则
同时满足最小支持度阈值(min_sup)和最小置信度阈值(min_conf)的规则称为强规则。
从包含d个项的数据集提取到的可能的规则的总数为: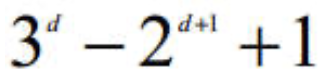
因同一项集的支持度一样,但置信度不同,所以我们需要同时考虑支持度和置信度的需要。
关联规则挖掘步骤
频繁项集的产生
规则的产生
从上一步发现的频繁项集中提取所有高置信度(满足最小置信度阈值)的规则,这些规则称为强规则
频繁项集的产生
Apriori算法原理及实现
先验性质
反单调性
一个集合不是频繁的,它的所有超集也不是频繁的,称为反单调性。
但一个集合是频繁的,则它所有子集也是频繁的。
Apriori算法
首先,找出所有的频繁项集,即所有符合最小支持度的项集。再从频繁项集中找出符合最小置信度的项集,最终便得到有强规则(符合支持度和置信度)的项集(即我们所需的项的关联性)。
用一个例子来理解
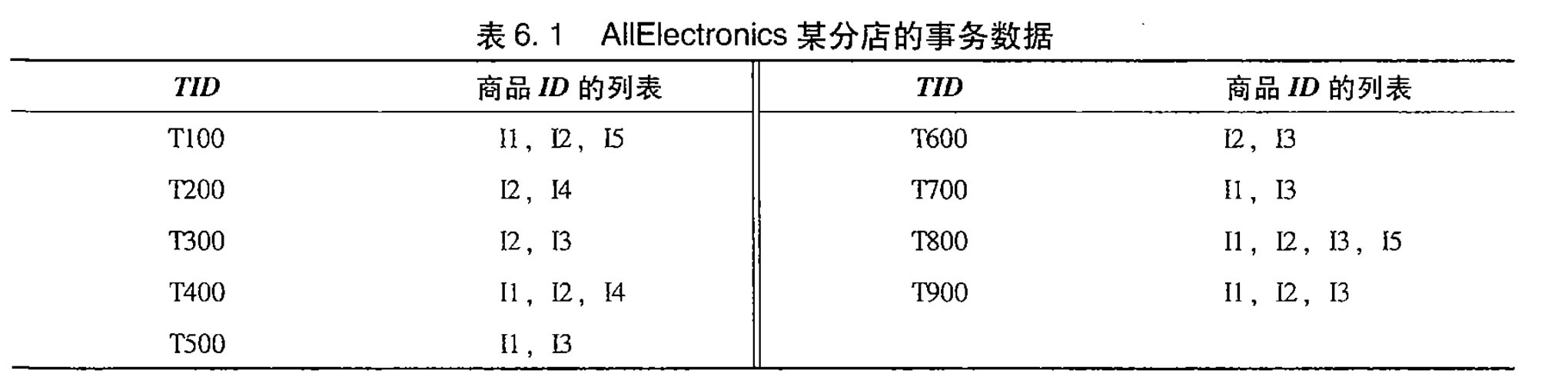
假设最小支持度计数为2,对应的相对支持度为2/9=22%。
- 每个项都是候选1项集的集合C1的成员。算法扫描所有的事务,获得每个项,生成C1。然后对每个项进行计数。然后根据最小支持度从C1中删除不满足的项,从而获得频繁1项集L1。
- 对L1的自身连接生成的集合执行剪枝策略产生候选2项集的集合C2,然后,扫描所有事务,对C2中每个项进行计数。同样的,根据最小支持度从C2中删除不满足的项,从而获得频繁2项集L2。
对L2的自身连接生成的集合执行剪枝策略产生候选3项集的集合C3,然后,扫描所有事务,对C3每个项进行计数。同样的,根据最小支持度从C3中删除不满足的项,从而获得频繁3项集L3。
进行自连接时候如何生成C3项集中
,它的二项子集为
, L2中有它全部的二项子集,这样才能自连接生成
以此类推,对Lk-1的自身连接生成的集合执行剪枝策略产生候选k项集Ck,然后,扫描所有事务,对Ck中的每个项进行计数。然后根据最小支持度从Ck中删除不满足的项,从而获得频繁k项集。
上面每一步得到
都由
自连接,得到k+1项集
上述过程apriori做了两个动作,连接和剪枝,剪枝就是利用先验性质删除具有非频繁子集的候选。
避免产生重复候选集的一种方法是确保每个频繁项集中的项以字典序存储,每个频繁(k-1)项集X只用字典序比X中所有的项都大的频繁项进行扩展。
选好了频繁项集之后,再用最小置信度的阈值来筛选出强关联的规则。

若有收获,就点个赞吧
0 人点赞
