1、体系结构
1.1、C/S结构模型介绍
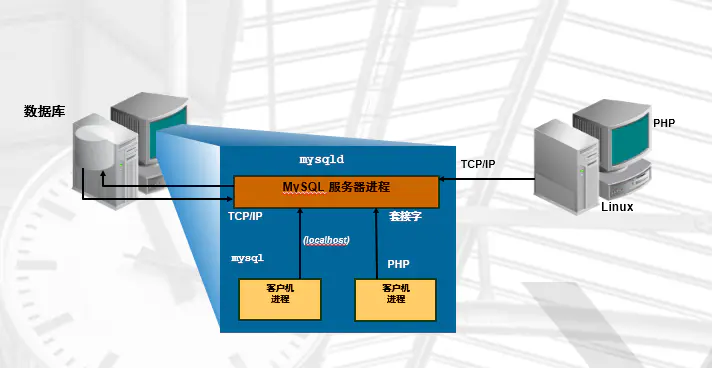
TCP/IP方式 (远程、本地)mysql -uroot -p123 -h 192.168.10.10 -P 3306Socket方式(仅本机)mysql -uroot -p123 -S /tmp/mysql.sock
1.2、MySQL 实例结构介绍
实例=mysqld后台守护进程 + Master Thread + 干活的Thread + 预分配的内存
公司=老板 + 经理 + 员工 + 办公室
1.3、mysqld程序运行原理
1.3.1、mysqld程序结构
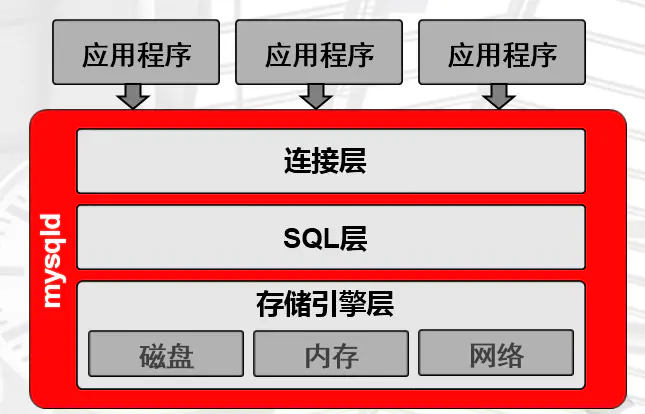
1.3.2、一条SQL语言执行过程
1.3.2.1、连接层
(1). 提供连接协议: TCP/IP、SOCKET
(2). 提供验证: 用户、密码、IP、SOCKET
(3). 提供专用连接线程: 接收用户SQL、返回结果
通过以下语句可以查看到连接线程基本情况
mysql> show processlist;
1.3.2.2、SQL层 (重点)
(1). 接收上层传送的SQL语句
(2). 语法验证模块: 验证语句语法,是否满足SQL_MODE
(3). 语义检查: 判断SQL语句的类型
DDL: 数据定义语言
DCL: 数据控制语言
DML: 数据操作语言
DQL: 数据查询语言
(4). 权限检查:用户对库表有没有权限
(5). 解析器:对语句执行前,进行预处理,生成解析树 (执行计划),说白了就是生成多种执行方案
(6). 优化器: 根据解析器得出的多种执行计划,进行判断,选择最优的执行计划
代价模型: 资源 (CPU IO MEM) 的耗损评估性能好坏
(7). 执行器: 根据最优执行计划,执行SQL语句,产生执行结果
执行结果: 在磁盘的xxxx位置上
(8). 提供查询缓存 (默认是没开启的),会使用redis tair替代查询缓存功能
(9). 提供日志记录 (日志管理章节): binlog,默认是没开启的
1.3.2.3、存储引擎层 (类似Linux中的文件系统)
负责根据SQL层执行的结果,从磁盘上拿数据
将16进制的磁盘数据,交由SQL结构化化成表
连接层的专用线程返回给用户
1.4、逻辑结构
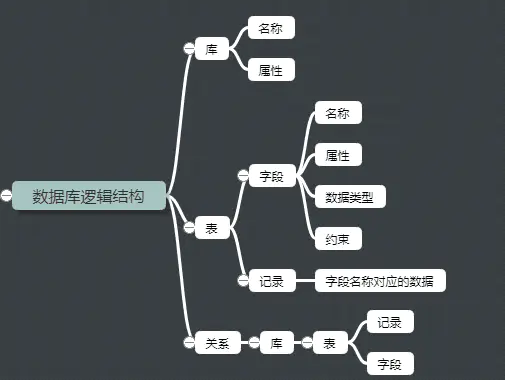
1.4.1、库
库名、库属性
1.4.2、表
表名、属性
列、列名(字段)、列属性(数据类型、约束等)
行(记录)
1.5、物理结构
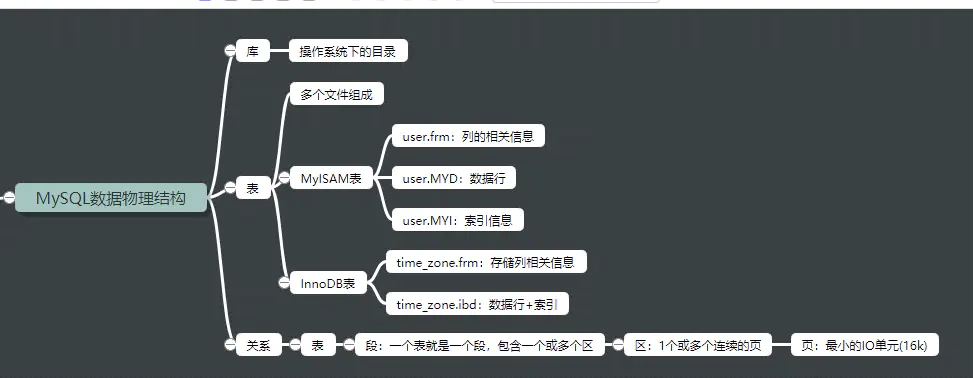
1.5.1、库的物理结构
对应文件系统的目录
1.5.2、表的物理结构
MyISAM 存储引擎的表结构:
-rw-r----- 1 mysql mysql 10816 Apr 18 11:37 user.frm
-rw-r----- 1 mysql mysql 396 Apr 18 12:20 user.MYD
-rw-r----- 1 mysql mysql 4096 Apr 18 14:48 user.MYI
InnoDB 储存引擎的表结构:
-rw-r----- 1 mysql mysql 8636 Apr 18 11:37 time_zone.frm
-rw-r----- 1 mysql mysql 98304 Apr 18 11:37 time_zone.ibd
time_zone.frm: 存储列相关信息
time_zone.ibd: 数据行+索引
1.5.3、表的段、区、页
段: 一个表就是一个段,包含一个或多个区
区: 64个连续的页,共1M
页: 最小的存储单元,默认16KB
2、MySQL 结构代价分析
SQL层 —-> CPU
存储引擎层 —-> 磁盘I/O
I/O优化: 缓存热点数据到内存, 直接从内存返回数据 (Redis)
3、MySQL 工作原理
一、连接层
作用: 类似于Linux操作系统、Linux OS
1.连接协议: TCP/IP、UNIX套接字socket
2.加载授权表: (mysql.user、mysql.db .. )、用户密码验证
3.通过密码验证之后生成连接线程
二、SQL层
作用: 负责SQL语句的处理、类似于shell解释器、(sql线程)
过程:
1. SQL语句语法检查、语义检查 (这句SQL到底查的是什么)
DDL、DCL、DML
2. 对象存在性、权限检查 (查找对象是否存在、是否有查看权限)
3. SQL语句解析、预处理
SQL语句解析预处理 ---> 生成解析树, 并统计执行代价 ---> 统计信息 (存放在:mysql.innodb_index_stats、mysql.innodb_table_stats中)
4. 优化器进行优化
根据 (每种执行计划的代价评估/SQL语句的执行顺序/查询方式的选择) ---> 查看资源消耗情况 (IO/CPU/内存) ---> 选择出SQL线程认为代价最低的执行计划
5. 按照执行计划执行SQL语句
得出需要的数据的具体位置 (哪个磁盘的哪个位置) ---> 告知Engine层
三、引擎层
Engine层和磁盘进行交互, 相当于Linux文件系统
Engine层获取的数据是16进制数据, 用户会看不懂, 所以Engine层会把数据返还给SQL层, SQL层会把数据生成表格的形式返回给用户, 显示到界面上
MySQL 核心工作原理总结
其实, 客户端发送一条查询数据给MySQL服务端, 服务端会先查询缓存, 如果命中了缓存, 则立刻返回存储在缓存中的结果。
否则, 服务端进行SQL解析、预处理、再由优化器生成对应的执行计划, 按照执行计划, SQL语句告知Engine层与磁盘做交互,
获取到数据交给SQL层, SQL层生成表格格式的数据, 返回给用户

若有收获,就点个赞吧
0 人点赞
