1、优化器算法查询
mysql>select @@optimizer_switch;index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on
2、修改优化器算法
#修改配置, 重启生效
1. my.cnf
optimizer_switch='batched_key_access=on'
#命令设置, 退出重进
2. set global optimizer_switch='batched_key_access=on';
#不修改配置, 使用SQL语句指定
3. hints 了解即可
SELECT /*+ NO_RANGE_OPTIMIZATION(t3 PRIMARY, f2_idx) */ f1
FROM t3 WHERE f1 > 30 AND f1 < 33;
SELECT /*+ BKA(t1) NO_BKA(t2) */ * FROM t1 INNER JOIN t2 WHERE ...;
SELECT /*+ NO_ICP(t1, t2) */ * FROM t1 INNER JOIN t2 WHERE ...;
SELECT /*+ SEMIJOIN(FIRSTMATCH, LOOSESCAN) */ * FROM t1 ...;
EXPLAIN SELECT /*+ NO_ICP(t1) */ * FROM t1 WHERE ...;
https://dev.mysql.com/doc/refman/5.7/en/optimizer-hints.html
3、单表优化器算法介绍
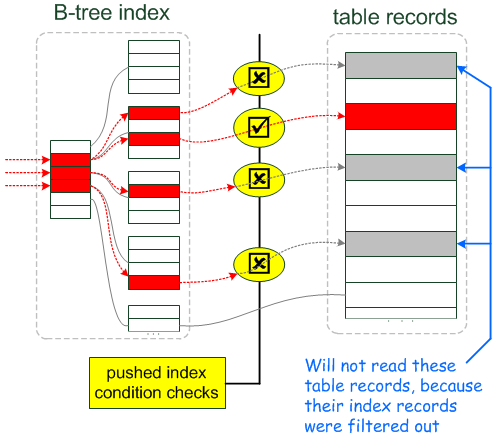
3.1、index_condition_pushdown (ICP)
介绍:
索引下推, 5.6+ 加入的特性, 默认开启
举例:
index idx (a,b,c);
WHERE a = xxx and b > xxx and c = xxx;
说明:
正常情况下, 只有a,b会走索引, c不走索引
可以优化成为: index idx (a,c,b);
但是如果c的重复值较大, 比如性别, 这种索引性能较差
index_condition_pushdown
作用:
SQL层做完过滤后, 只能用a,b的部分辅助索引, 将c列条件的过滤下推到engine层, 进行再次过滤, 排除无用的数据页
最终去磁盘上拿数据页
大大减少无用IO的访问
原理:
通过索引查到a,b列结果集时, 用c列的条件过滤, 下推到engin层, 过滤完结果集, 排除无用的数据再取数据到内存
具体参考:
https://dev.mysql.com/doc/refman/5.7/en/index-condition-pushdown-optimization.html
https://mariadb.com/kb/en/index-condition-pushdown/
原理图:
https://mariadb.com/kb/en/index-condition-pushdown/+image/index-access-2phases
https://mariadb.com/kb/en/index-condition-pushdown/+image/index-access-with-icp
测试1: 开启index_condition_pushdown时
SET global optimizer_switch='index_condition_pushdown=ON';
#添加索引
ALTER TABLE test.t100w ADD INDEX idx_k1_k2(k1,k2);
#压测
/data/app/mysql5728/bin/mysqlslap --defaults-file=/data/3307/conf/my.cnf --concurrency=100 --iterations=1 --create-schema='test' \
--query="select * from test.t100w where k1 > 'Za' and k2='rsEF'" engine=innodb --number-of-queries=2000 -uroot -p123 -verbose
测试2: 关闭index_condition_pushdown时
SET global optimizer_switch='index_condition_pushdown=OFF';
#测试3: 优化索引, 调整顺序
ALTER TABLE test.t100w ADD INDEX idx_k2_k1(k2,k1);
测试结论:
在t100w表中, 通过调整索引顺序, 比ICP效果好, 因为k2的重复数据行少

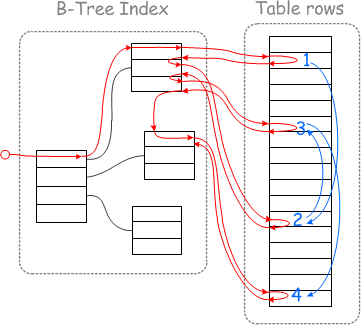
3.2、MRR: Multi Range Read
作用: 减少回表, 减少随机IO
开关方法:
set global optimizer_switch='mrr=on,mrr_cost_based=off';
参树说明:
mrr=on: 开启mrr优化算法
mrr_cost_based=on: SQL层根据代价评估, 是否走MRR优化算法, 默认开启
off代表强制启用MRR, 不同点见压测结果
具体参考:
https://dev.mysql.com/doc/refman/5.7/en/mrr-optimization.html
https://mariadb.com/kb/en/multi-range-read-optimization/
原理图:
https://mariadb.com/kb/en/multi-range-read-optimization/+image/no-mrr-access-pattern
https://mariadb.com/kb/en/multi-range-read-optimization/+image/mrr-access-pattern
原理说明:
辅助索引去请求聚簇索引时, 拿着id字段的值, 逐个进行请求, 容易照成回表次数过多
MRR优化算法在中间加了一层缓冲区: rowid_buffer
1. 将辅助索引要请求聚簇索引的id结果集进行排序
2. 排序完成后, 再去请求聚簇索引, 根据叶子节点双向指针进行顺序请求
压测:
#创建name字段索引
ALTER TABLE world.city ADD INDEX idx_name(name);
#开启代价评估
'mrr=on,mrr_cost_based=on'
#关闭代价评估, 强制MRR
'mrr=on,mrr_cost_based=off'
/data/app/mysql5728/bin/mysqlslap --defaults-file=/data/3307/conf/my.cnf --concurrency=100 --iterations=1 \
--create-schema='world' --query="select * from world.city where name in ('Aachen','Aalborg','Aba','Abadan','Abaetetuba')" engine=innodb --number-of-queries=20000 -uroot -p123 -verbose
压测结果:
通过压测对比, 开启mrr代价评估, 效果更佳, 生产中以压测为准
4、多表连接查询优化算法
4.1、SNLJ 普通嵌套循环连接
驱动表选择
例子:
A join B
ON A.xx = B.yy
伪代码:
#SNLJ原理 (笛卡尔乘积)
for each row in A matching range {
block
for each row in B {
A.xx = B.yy , send to client
}
}
执行流程:
A表的行数作为循环次数, 与B表每一行进行匹配, 外层循环A表作为驱动表, B层作为非驱动表
例子:
use school
desc select * from teacher join course on teacher.tno=course.tno;
+----+-------------+---------+------------+--------+---------------+---------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+--------+---------------+---------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | course | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | SIMPLE | teacher | NULL | eq_ref | PRIMARY | PRIMARY | 4 | school.course.tno | 1 | 100.00 | NULL |
+----+-------------+---------+------------+--------+---------------+---------+---------+-------------------+------+----------+-------+
第一行显示的表作为驱动表 course, 后面的为非驱动表 teacher
优化器默认优化规则:
默认选择方式 (非驱动表)
按照on的条件列, 是否有索引, 索引的类型选择
1. 在on条件中, 优化器优先选择有索引的列为非驱动表
2. 如果两个列都有索引, 一般选择唯一值的列作为驱动表 (小表驱动大表)
3. 特殊情况, 如果两个列都有索引优化器会按照执行的代价去选择驱动表和非驱动表 (代价评估)
for each row in course matching range {
join buffer
block
for each row in teacher {
course.tno = tracher.tno ,send to client
}
}
#特殊情况说明
#给 city表添加索引
ALTER TABLE world.city ADD INDEX idx_code(countrycode);
#查看两张表结构
desc country;
countrycode | MUL
desc city;
code | PRI
查询语句执行代价:
desc format=json select * from city join country on city.countrycode=country.code ;
"query_cost": "5231.03"
#强制选择驱动表
desc format=json select * from city left join country on city.countrycode=country.code ;
"query_cost": "5888.20"
结论:
通过代价对比, 优化器选择了 desc country表 countrycode | MUL作为驱动表, 因为代价更低 (条件3)
desc select * from city join country on city.countrycode=country.code ;
+----+-------------+---------+------------+------+----------------------+-------------+---------+--------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+----------------------+-------------+---------+--------------------+------+----------+-------+
| 1 | SIMPLE | country | NULL | ALL | PRIMARY | NULL | NULL | NULL | 239 | 100.00 | NULL |
| 1 | SIMPLE | city | NULL | ref | CountryCode,idx_code | CountryCode | 3 | world.country.Code | 18 | 100.00 | NULL |
+----+-------------+---------+------------+------+----------------------+-------------+---------+--------------------+------+----------+-------+
#选择驱动表, 还是以压测为准, 以压测结果为准, 检测人为干预 和 优化器自主选择的效果
left join: 这类的操作可以强制指定驱动表
不能完全用优化器自主优化, 以压测为准哪个性能好
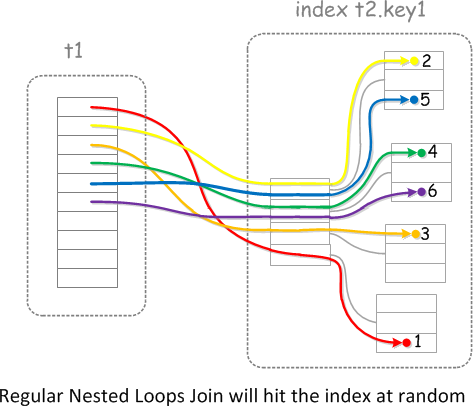
4.2、BNLJ
优化算法:
select @@optimizer_switch;
block_nested_loop=on
作用:
在 A和B关联条件匹配时, 不再一次一次进行循环, 采用块循环连接
A表中需要关联的数据, 先在join buffer缓冲, 采用一次性将驱动表的关联值和非驱动表匹配, 一次性返回结果
主要优化了CPU消耗, 减少了一部分IO消耗
触发条件: 非驱动表的连接条件有辅助索引
原理图:
https://mariadb.com/kb/en/multi-range-read-optimization/+image/key-sorting-regular-nl-join
t1为驱动表, t2为分驱动表
t1表与t2表关联查询, 先将t1的结果集放在join buffer块中, 一次性请求t2表, 进行匹配
缺点:
当join buffer块与t2表进行关联查询时, 因为没有排序, 存在一个数据页被反复读取多次的情况
例如: 请求1时在最下面数据页, 2在第一个数据页, 请求5时, 又要请求这个数据页, 反复读了两次, 增加循环次数
4.3、BKA
主要作用, 使用来优化非驱动表的关联列有辅助索引
BNL+ MRR的功能算法, BNL的升级版
原理图:
https://mariadb.com/kb/en/multi-range-read-optimization/+image/key-sorting-join
在BNLJ的基础上加了排序功能, 请求t2之前, 将join buffer块和数据页页进行排序, 然后再进行匹配, 减少1个数据页被反复读取的情况
开启方式:
set global optimizer_switch='mrr=on,mrr_cost_based=off';
set global optimizer_switch='batched_key_access=on';
注意:batched_key_access=off
batched_key_access=off, 默认是关闭的, 若想使用, 需要开启batched_key_access=on 和 mrr_cost_based=off 强制使用MRR算法, MRR对性能有影响, 需要经过验证公司业务, 是否适用此类场景

5、总结-多表连接优化
5.1、驱动表选择
A join B on A.x=b.y
1. 让优化器自己决定:
(1). 在on条件中, 优化器优先选择有索引的列为非驱动表
(2). 如果两个列都有索引, 优化器会按照执行的代价去选择驱动表和非驱动表
2. 自主选择
left join 人为干预强制驱动表
3. 关于驱动表选择的优化思路:
理论支撑:
desc select * from city join country on city.countrycode=country.code;
desc select * from city left join country on city.countrycode=country.code;
查询语句执行代价:
desc format=json select * from city join country on city.countrycode=country.code ;
desc format=json select * from city left join country on city.countrycode=country.code ;
实践检验:
压测
5.2、优化器-触发不同场景
情景一: 触发SNL的情况
非驱动表, 关联条件如果没有任何索引的话, 只能默认使用SNL算法
代价较高, 建议做合理优化
例如:
将非驱动表关联条件建立索引
1. 主键或唯一键, 会自动使用 eq_ref算法进行执行查询
2. 辅助索引, 默认会采用BNL优化算法, 如果开启BKA, 会走BKA
场景二: 触发BNL的情况
情景三: 触发BKA的情况
非驱动表, 连接条件如果有普通索引
默认是关闭的, 启动方式:
set global optimizer_switch='mrr=on,mrr_cost_based=off';
set global optimizer_switch='batched_key_access=on';
选择 BNL和BKA算法的判断思路:
理论支撑:
desc select * from city join country on city.countrycode=country.code ;
desc select * from city left join country on city.countrycode=country.code ;
查询语句执行代价:
desc format=json select * from city join country on city.countrycode=country.code ;
desc format=json select * from city left join country on city.countrycode=country.code ;
实践检验:
mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='world' --query="select * from city left join country on city.countrycode=country.code ;" engine=innodb --number-of-queries=2000 -uroot -p123 -verbose
mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='world' --query="select * from city join country on city.countrycode=country.code ;" engine=innodb --number-of-queries=2000 -uroot -p123 -verbose
最终结论: 不管是优化单表或多表, 重点是在于索引和语句本身优化

若有收获,就点个赞吧
0 人点赞
