1.Lucene Index存储方式
Elasticsearch是基于Lucene实现的。从前面的课程我们知道Elasticsearch的数据是分片存储的,每个分片都会运行一个Lucene实例。在Lucene中,单个倒排索引文件被称为Segment。Segment是自包含的,不可变更的。多个Segment汇总到一起,组成Lucene的index,它会对应Elasticsearch的shard(分片)。当新的索引文档写入时,就会生成新的Segment。如果我们需要对索引进行查询,需要针对Segments进行查询,然后再对查询结果进行汇总。如图所示Lucene中有一个文件,叫做Commit Point,它用来记录所有Segments信息。如果删除索引文档,并不会立刻物理删除,删除的文档信息保存在.del文件中。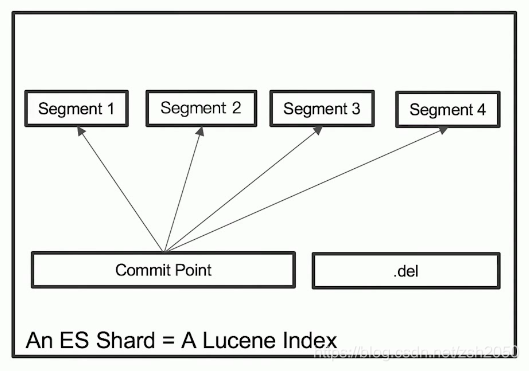
从上面对lucene Index的描述中我们获得了几个信息:
- 每个Elasticsearch的shard(分片)对应一个lucene index。
- 每个倒排索引文件对应一个segment。
- 查询索引文件就是从每个segment中去查找,然后汇总。
2.Elasticsearch的Refresh
索引文件的存储过程:
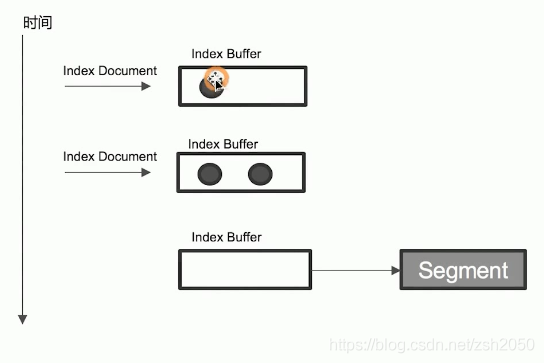
- 索引文件(Index Document)最开始写入是被存放到内存的一个区域内,这个区域叫做Index Buffer。放到这个区域的索引文件暂时是不能被Elasticsearch搜索到的,这样就是为什么订单刚刚更新的时候,数据不能被搜索到的原因。
- Elasticsearch中有一种机制会将Index Buffer中的数据写入到Segment中,这种机制就是Refresh。写入到Segment中的数据就可以被Elasticsearch搜索到了,也就是说订单更新的数据需要通过Refresh写到Segment以后才能被搜索到。
- Refresh触发的条件有两种,其中一种是按照时间频率触发,默认情况是每1秒触发1次Refresh,可通过index.refresh_interval设置。这也是为什么人们称Elasticsearch为近实时搜索的原因了。还有一种触发方式是当Index Buffer被占满的时候,会触发Refresh,Index Buffer的大小默认值是JVM所占内存容量的10%。
- 当Refresh 之后 Index Buffer的数据会写入到Segment中,此时Index Buffer的数据会被清空。

若有收获,就点个赞吧
0 人点赞
