1.分词器原理
在全文搜索(Fulltext Search)中,词(Term)是一个搜索单元,表示文本中的一个词,标记(Token)表示在文本字段中出现的词,由词的文本、在原始文本中的开始和结束偏移量、以及数据类型等组成。
ElasticSearch 把文档数据写到倒排索引(Inverted Index)的结构中,倒排索引建立词(Term)和文档之间的映射,索引中的数据是面向词,而不是面向文档的。分析器(Analyzer)的作用就是分析(Analyse),用于把传入Lucene的文档数据转化为倒排索引,把文本处理成可被搜索的词。
分析器由一个分词器(Tokenizer)和零个或多个标记过滤器(TokenFilter)组成,也可以包含零个或多个字符过滤器(Character Filter)。
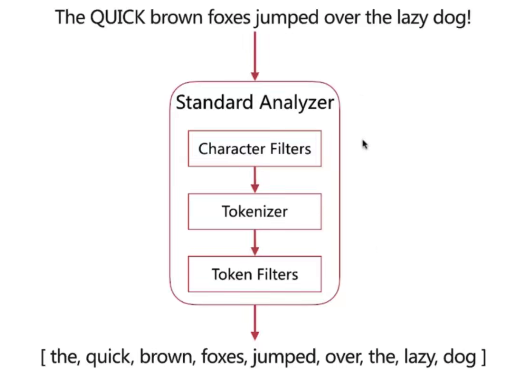
在ElasticSearch引擎中,分析器的任务是分析(Analyze)文本数据,分析是分词,规范化文本的意思,如图所示,其工作流程如下:
- 首先,字符过滤器(Character Filter)对分析(analyzed)文本进行过滤和处理,例如从原始文本中移除HTML标记,根据字符映射替换文本等,
- 过滤之后的文本被分词器(Tokenizer)接收,分词器把文本分割成标记流,也就是一个接一个的标记,
- 然后,标记过滤器对标记流进行过滤处理(Token Filters),例如,移除停用词,把词转换成其词干形式,把词转换成其同义词等,
- 最终,过滤之后的标记流被存储在倒排索引中;
根据上述规则Elasticsearch会为大家提供一些内置分词器:
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
- Patter Analyzer - 正则表达式,默认\W+(非字符分割)
- Language - 提供了30多种常见语言的分词器
- Customer Analyzer 自定义分词器
当然也可以根据自己的需要自定义分词器。
如图所示,我们可以通过setting-analysis-analyzer的方式自定义分词器,其中需要设置type为custom,tokenizer选择了Elasticsearch提供的standard,filter使用了lowercase(小写转换)和asciifolding。定义完成以后,可以在mapping中使用,在对应字段的analyzer属性中可以设置定义好的分词器的名字std_folded。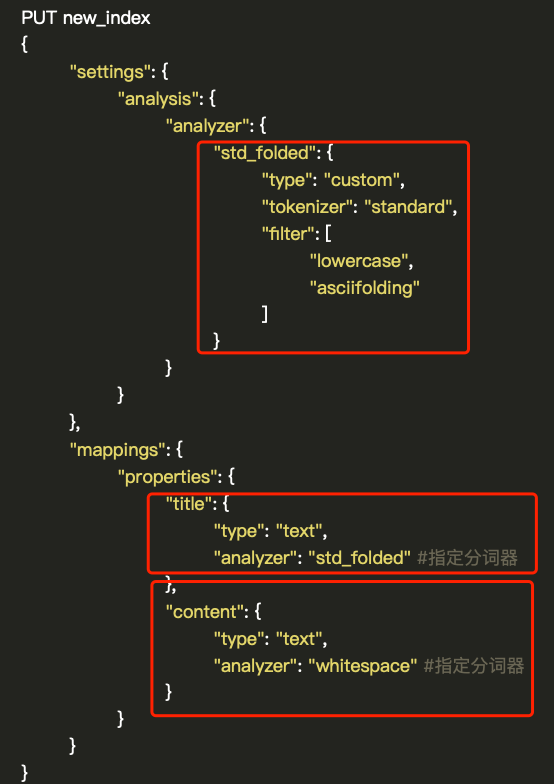
2.IK分词器
2.1.安装
- 下载插件 https://github.com/medcl/elasticsearch-analysis-ik/releases
解压至plugins目录
mkdir ikunzip elasticsearch-analysis-ik-7.15.0.zip ikmv ik /elasticsearch-7.15.0/plugins
-
2.2.测试
GET _analyze{"analyzer": "ik_max_word","text": "中华人民共和国"}
结果:
{"tokens" : [{"token" : "中华人民共和国","start_offset" : 0,"end_offset" : 7,"type" : "CN_WORD","position" : 0},{"token" : "中华人民","start_offset" : 0,"end_offset" : 4,"type" : "CN_WORD","position" : 1},{"token" : "中华","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 2},{"token" : "华人","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 3},{"token" : "人民共和国","start_offset" : 2,"end_offset" : 7,"type" : "CN_WORD","position" : 4},{"token" : "人民","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 5},{"token" : "共和国","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 6},{"token" : "共和","start_offset" : 4,"end_offset" : 6,"type" : "CN_WORD","position" : 7},{"token" : "国","start_offset" : 6,"end_offset" : 7,"type" : "CN_CHAR","position" : 8}]}

若有收获,就点个赞吧
0 人点赞
