狂神说ElasitcSearch笔记
ElasticSearch简介
关于这部分,大家可以自己科普一下,有兴趣的,可以去B站UP主:狂神说Java关于ElasitcSearch这个课程的教程
ElasticSearch安装
声明JDK1.8:最低要求
基于Java开发
ElasticSearch的版本和我们之后对应的Java的核心jar包!版本对应!
下载
Windows安装
解压即可
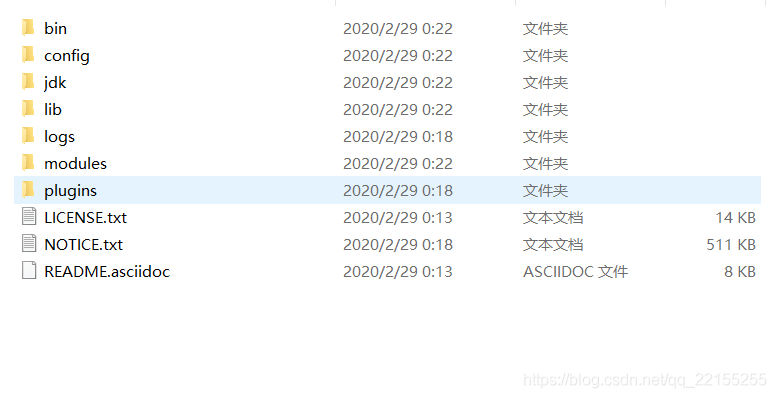
目录
bin 启动文件config 配置文件log4j2 日志配置文件jvm.options Java虚拟机相关的配置elasticsearch.yml elasticsearch配置文件 默认端口(9200) 跨域问题!!lib 相关jar包logs 日志文件modules 功能模块plugins 插件123456789
启动
访问9200
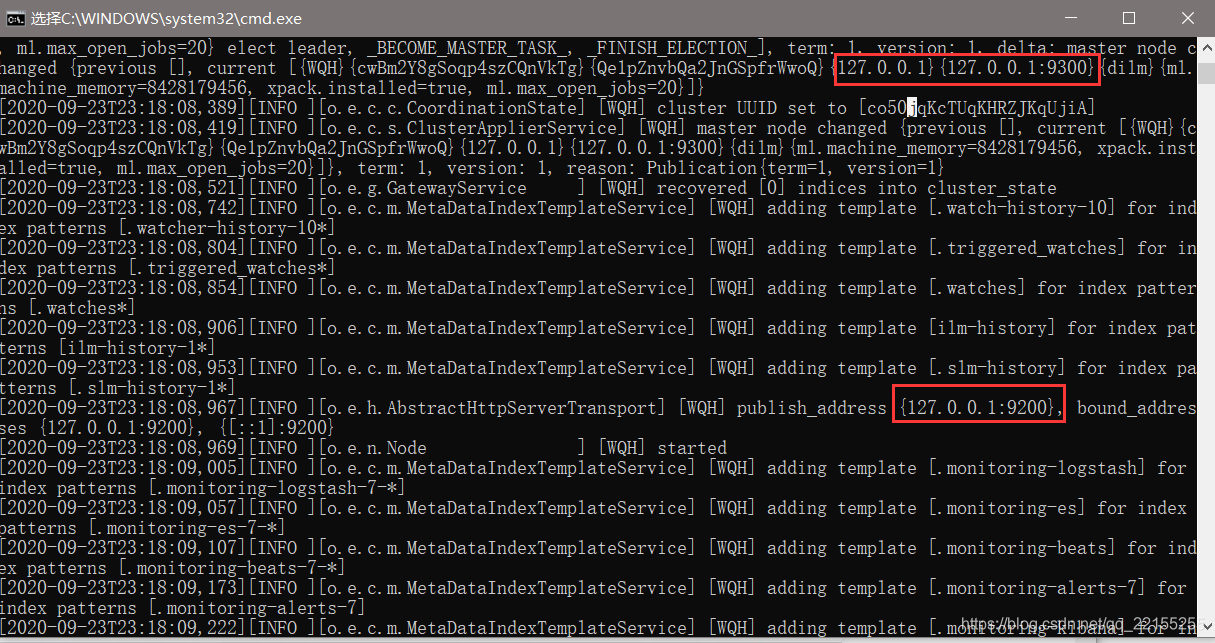
访问测试【返回如下启动正常】

说明你的ES已经安装好啦
下面我们来安装可视化界面
安装可视化界面
es head插件
包括一些跨越问题的解决
教程:https://www.cnblogs.com/hts-technology/p/8477258.html
2.启动
npm install#cnpm installnpm run start12
跨域问题解决
D:\ElasticSearch\elasticsearch-7.6.2\config
elasticsearch.yml
注意“:”和值之间的空格
http.cors.enabled: truehttp.cors.allow-origin: "*"
成功!!!
head插件页面
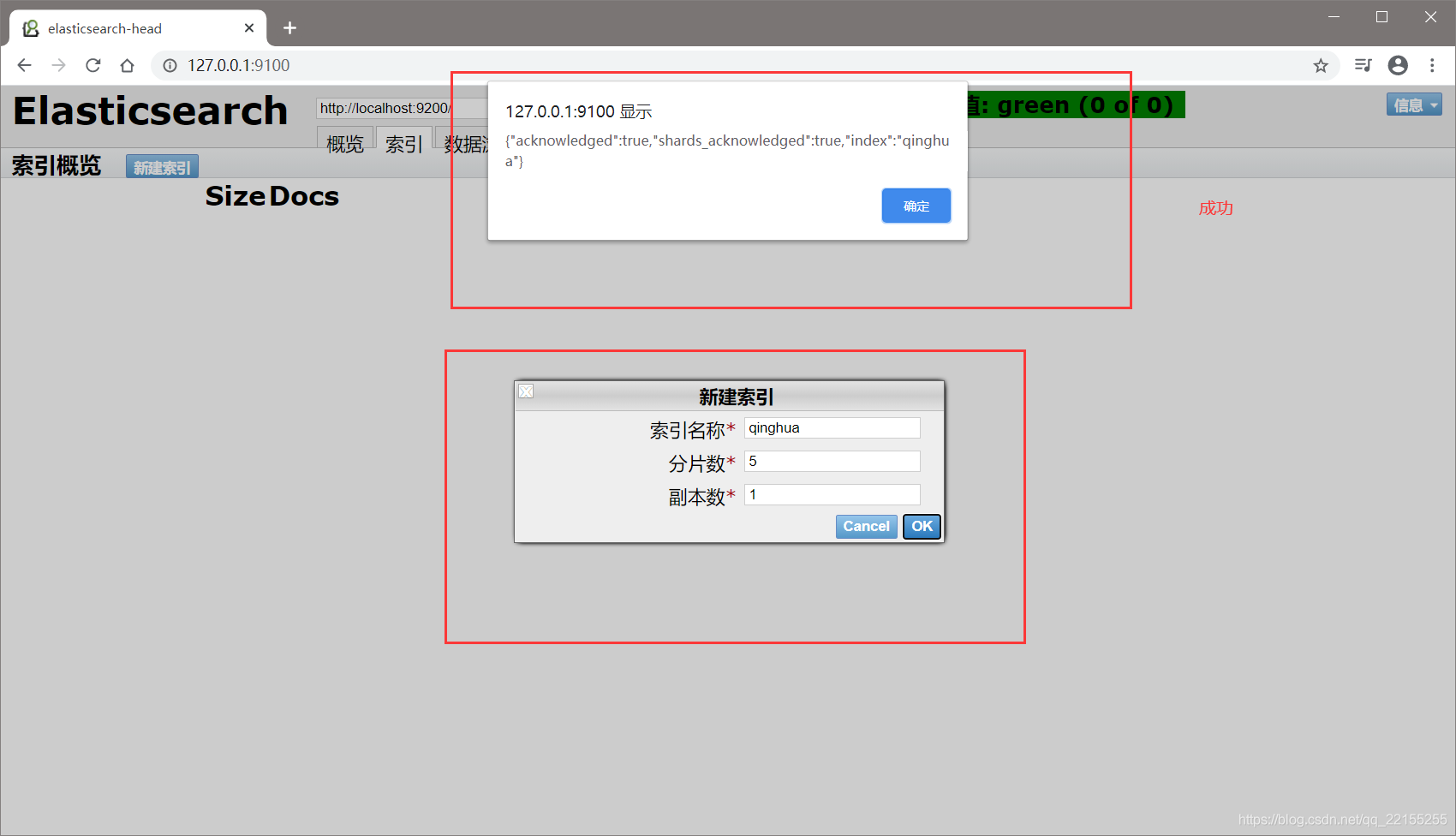
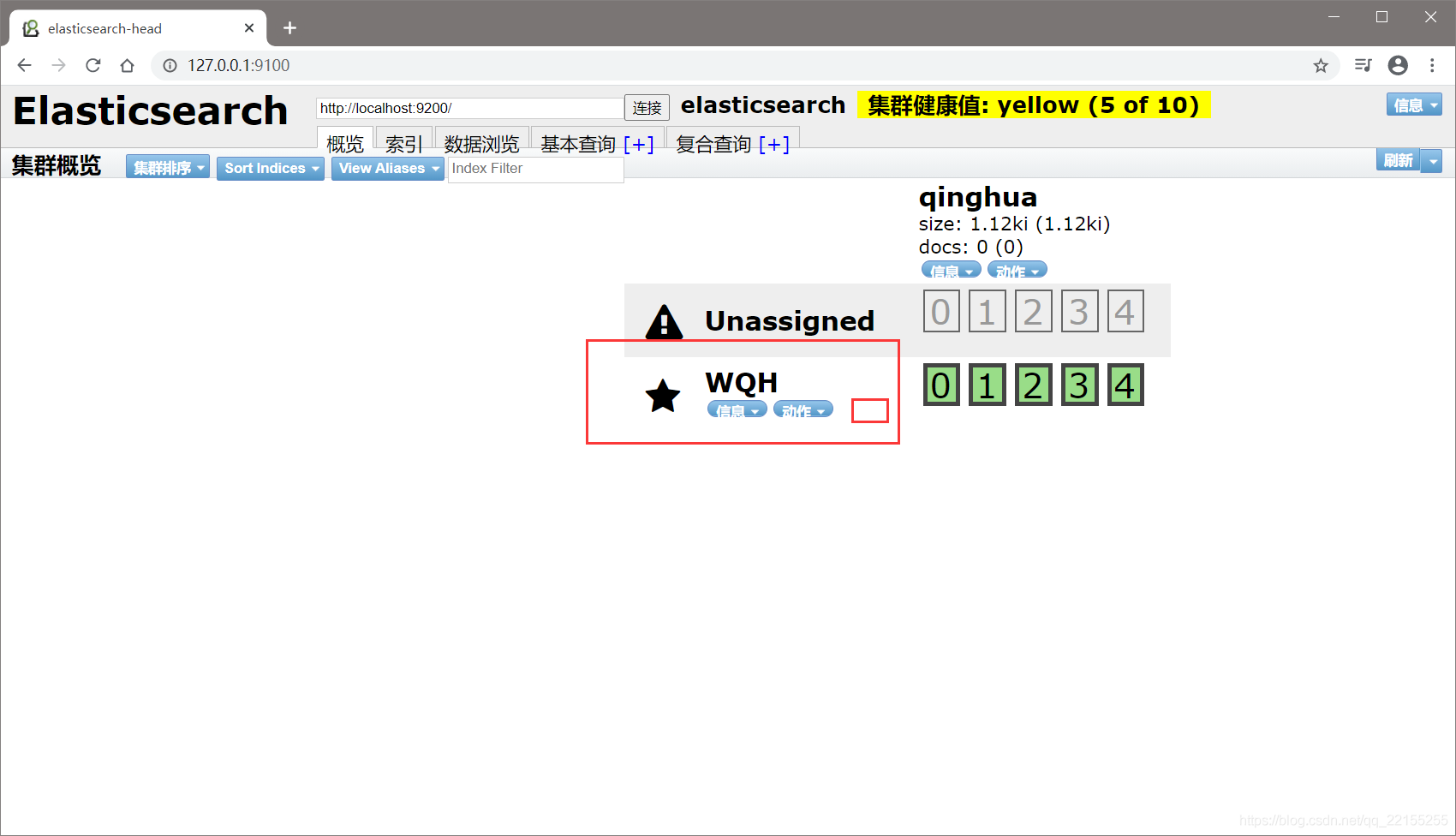
把索引当做数据库!(可以建立索引(库),文档(库中的数据))
命令在这里写
这个head我们就把他当做数据展示工具,我们后面所有的查询在kibana做
ELK介绍
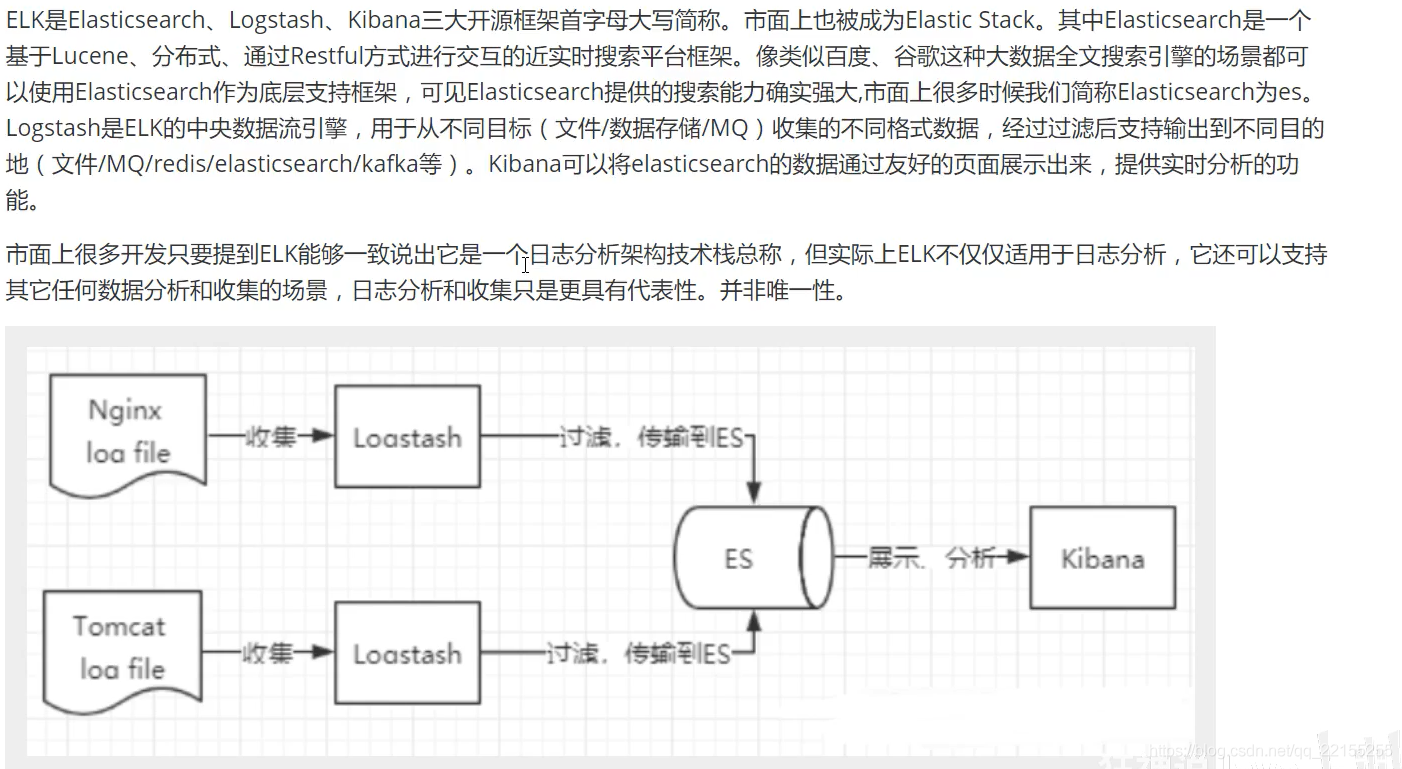
数据分析 数据清晰 kibana
拆箱即用
Kibana
安装
官网:https://www.elastic.co/cn/kibana
注意
Kibana要和ES版本一致
解压需要时间不短
目录
启动
端口:5601
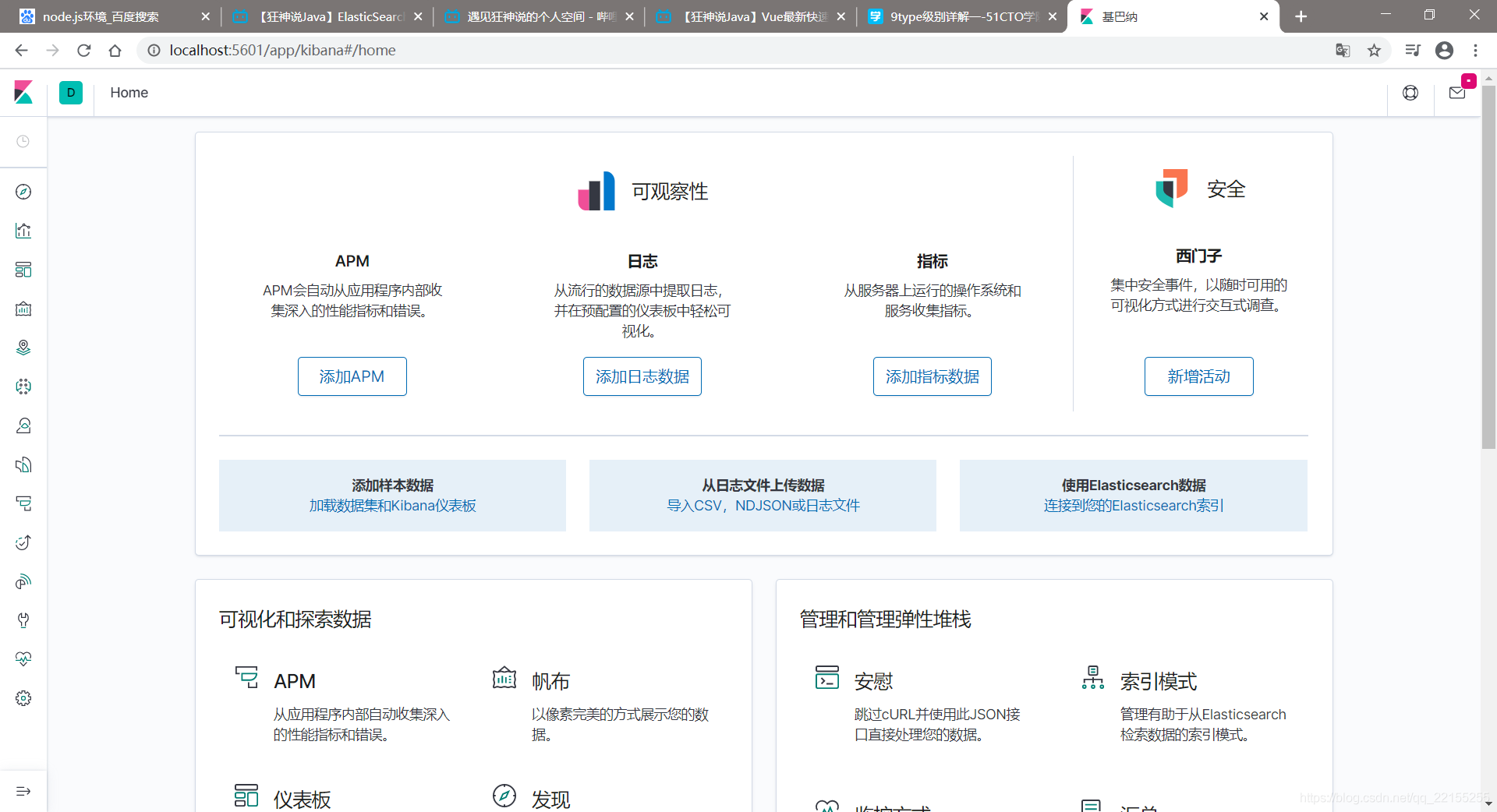
访问测试
开发工具
Post crul head 谷歌插件测试 Kibana测试
我们之后的操作在这里编写
汉化自己修改配置
i18n.locale: “zh-CN”
在这里插入图片描述
ES核心概念
核心概念
在前面的学习中,我们已经掌握了es是什么,同时也把es的服务已经安装启动,那么es是如何去存储数据,数据结构是什么,又是如何实现搜索的呢?我们先来聊聊ElasticSearch的相关概念吧!
集群,节点,索引,类型,文档,分片,映射是什么?
elasticsearch是面向文档关系行数据库 和elasticsearch 客观的对比!
一切都是JSON
| Relational DB | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types (慢慢被弃用) |
| 行(rows) | documents |
| 字段(columns) | fields |
elasticsearch(集群)中可以包含多个索引数据库) ,每个索引中可以包含多个类型(表) ,每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)。
物理设计
elasticsearch在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移
一个人就是一个集群!默认的集群名称就是elaticsearh
逻辑设计
一个索引类型中,包含多个文档,比如说文档1 , 文档2。
当我们索引一篇文档时,可以通过这样的一各顺序找到它:索引—类型
—文档ID ,通过这个组合我们就能索引到某个具体的文档。
注意:ID不必是整数,实际上它是个字符串。
文档
相当于我们的一条条数据
user1 zhangsan 182 wangwu 18123
之前说elasticsearch是面向文档的,那么就意味着索弓|和搜索数据的最小单位是文档, elasticsearch中,文档有几个重要属性:
- 自我包含,一篇文档同时包含字段和对应的值 ,也就是同时包含key:value !比如,name:wang 他就会帮我们自动去查询name=wang的文章
- 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的!就是JSON对象,fastjson可以进行自动转换
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中, 对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射 ,比如name映射为字符串类型。
我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段 ,那么elasticsearch是怎么做的呢?
elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型, elasticsearch就开始猜,如果这个值是18 ,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对 ,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。也就是我们创建数据类型的时候直接规定好我们的映射类型
索引
索引其实就是数据库!
索引是映射类型的容器, elasticsearch中的索引是一个非常大的文档集合。 索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
物理设计:节点和分片 如何工作
一个集群至少有一一个节点,而一个节点就是一个elasricsearch进程 ,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片( primary shard ,又称主分片)构成的,每-一个主分片 会有一个副本( replica shard ,又称复制分片)
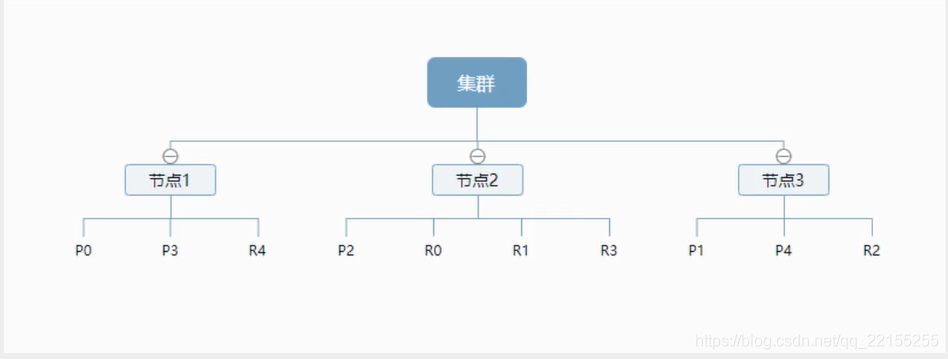
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同- -个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上, 一个分片是一个Lucene索引 , 一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。不过,等等,倒排索引是什么鬼?
倒排索引
elasticsearch使用的是一种称为倒排索引的结构 ,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词, 都有一个包含它的文档列表。例如,现在有两个文档,每个文档包含如下内容:
Study every day, good good up to forever#文档1包含的内容To forever,study every day,good good up #文档2包含的内容12
为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens) ,然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
| term | doc_1 | doc_2 |
|---|---|---|
| Study | √ | × |
| To | × | × |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | x | √ |
| good | √ | √ |
| every | √ | √ |
| to | √ | x |
| up | √ | √ |
现在,我们试图搜索to forever ,只需要查看包含每个词条的文档
| term | doc_1 | doc_2 |
|---|---|---|
| to | √ | x |
| forever | √ | √ |
| total | 2 | 1 |
两个文档都匹配,但是第一个文档比第 二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。(分数or权重)
再来看一-个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构:
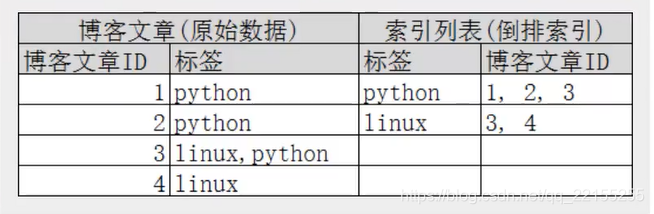
如果要搜索含有python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可。
elasticsearch的索引和Lucene的索引对比
在elasticsearch中,索引(库)这个词被频繁使用,这就是术语的使用。elasticsearch中 ,索引被分为多个分片,每份分片是一个Lucene的索引。
所以一个elasticsearch索引是由多个Lucene索引组成的。别问为什么,谁让elasticsearch使用Lucene作为底层呢!
如无特指,说起索引都是指elasticsearch的索引。
接下来的一切操作都在kibana中Dev Tools下的Console里完成。基础操作!
IK分词器插件
什么是IK分词器
分词:
即把一-段中文或者别的划分成-个个的关键字,我们在搜索时候会把自己的信息进行分词会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词 ,比如“我爱狂神”会被为“我”爱”“狂”神” ,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
IK提供了两个分词算法: ik smart和ik_max_word ,其中ik smart为最少切分, ik max _word为最细粒度划分!
安装我们的IK分词器,注意版本对应
| IK版本 | ES版 |
|---|---|
| 主 | 7.x->主 |
| 6.x | 6.x |
| 5.x | 5.x |
| 1.10.6 | 2.4.6 |
| 1.9.5 | 2.3.5 |
| 1.8.1 | 2.2.1 |
| 1.7.0 | 2.1.1 |
| 1.5.0 | 2.0.0 |
| 1.2.6 | 1.0.0 |
| 1.2.5 | 0.90.x |
| 1.1.3 | 0.20.x |
| 1.0.0 | 0.16.2-> 0.19.0 |
下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.2
然后解压到我们es中的plugins文件夹中,文件夹名字为ik
重启有关我们ElasticSeacher的所有服务
测试IK分词器
使用kibana测试ik_smart
GET _analyze{"analyzer": "ik_smart","text":"我要看电视剧"}结果{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "要看","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 1},{"token" : "电视剧","start_offset" : 3,"end_offset" : 6,"type" : "CN_WORD","position" : 2}]}12345678910111213141516171819202122232425262728293031
使用kibana测试ik_max_word
GET _analyze{"analyzer": "ik_max_word","text":"我要看电视剧"}结果{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "要看","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 1},{"token" : "看电视","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 2},{"token" : "电视剧","start_offset" : 3,"end_offset" : 6,"type" : "CN_WORD","position" : 3},{"token" : "电视","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 4},{"token" : "剧","start_offset" : 5,"end_offset" : 6,"type" : "CN_CHAR","position" : 5}]}12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152
我们发现换的词不一样,他的结果不一样,因为他有一个词库,词库觉得这是个单词,就拼到一块,不是单词一个一个划分,我们可以多举几个例子!
//我爱狂神说 ik_smart测试 他觉得我爱狂神说,都是单个字{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "爱","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1},{"token" : "狂","start_offset" : 2,"end_offset" : 3,"type" : "CN_CHAR","position" : 2},{"token" : "神","start_offset" : 3,"end_offset" : 4,"type" : "CN_CHAR","position" : 3},{"token" : "说","start_offset" : 4,"end_offset" : 5,"type" : "CN_CHAR","position" : 4}]}要是把爱换成喜欢,就变成了我 喜欢 狂 神 说,因为是最少切分,他就得喜欢是一个词,就不分开了1234567891011121314151617181920212223242526272829303132333435363738394041
问题来了:作为他的粉丝,我不想这个狂神说被分开,就需要增加自己的词到字典中
ik分词器增加自己的配置
在我们的ik分词器的目录下有IKAnalyzer.cfg.xml
里面可以配置我们自己的字典
先编写一个自己的字典,我这里就写了一个kuang.dic,将狂神说当成一个词
然后在我们的IKAnalyzer.cfg.xml中导入我们自己的字典
<!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">kuang.dic</entry>12
重启我们的ES测试
GET _analyze{"analyzer": "ik_smart","text":"我超级喜欢狂神说"}{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "超级","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 1},{"token" : "喜欢","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 2},{"token" : "狂神说","start_offset" : 5,"end_offset" : 8,"type" : "CN_WORD","position" : 3}]}可以发现我们的狂神说已经成为了一个词,最小切分就不会在切分他了1234567891011121314151617181920212223242526272829303132333435363738
过于head的页面,如果不能显示数据,可以参照网上说的修改配置,这个很简单,一搜就能搜到,主要是ES7严格规范了头部信息,还有一种可能是head页面做的比较落后,你的数据有可能在页面中间或者下方藏着,仔细找找
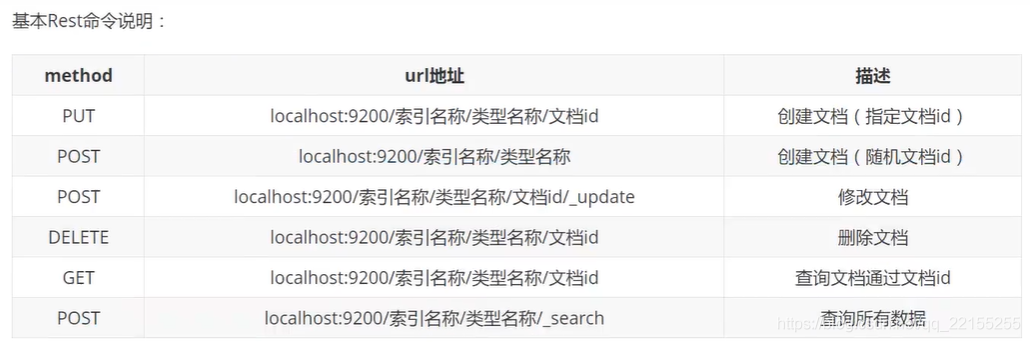
Rest风格
这个就是我们一般的开发规则,这里就不一一赘述了,如果不明白的
,可以搜索其他的博客,这个有很多介绍的,一下就展示我的一些测试例子
关于索引的基本操作
创建索引
# put /索引名(数据库名)/类型名(以后会弃用)/文档id# { 请求体 }put /test1/type1/1{"name":"小狂神","age":20}#! Deprecation: [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}).{"_index" : "test1", #数据库名字"_type" : "type1", #类型"_id" : "1", #文档id"_version" : 1, #版本没有被修改过"result" : "created", #创建好了"_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1}12345678910111213141516171819202122232425
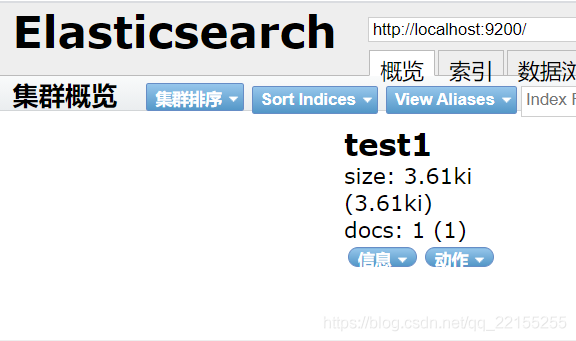
我们发现已经有了这个数据库
那么以后我们一些常用的就可以在这建立索引,就不需要再去走后台了
建立一个索引(数据库)
PUT /test3{"mappings": {"properties": {"name":{"type": "text"},"age":{"type": "long"},"birthday":{"type": "date"}}}}{"acknowledged" : true,"shards_acknowledged" : true,"index" : "test3"}###### 查看数据库信息GET test3{"test3" : {"aliases" : { },"mappings" : {"properties" : {"age" : {"type" : "long"},"birthday" : {"type" : "date"},"name" : {"type" : "text"}}},"settings" : {"index" : {"creation_date" : "1606996465007","number_of_shards" : "1","number_of_replicas" : "1","uuid" : "36Hoc3O7SvSwfa_f_iAvxw","version" : {"created" : "7060199"},"provided_name" : "test3"}}}}12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455
查看默认的信息
PUT /tes2/_doc/1{"name":"小狂神","age":13,"birth":"1997-05-12"}GET test31234567
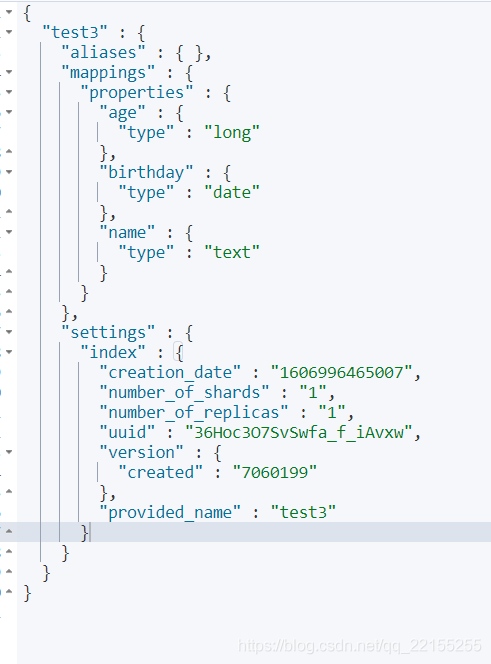
如果我们的字段没有指定,那么es就会给我们默认配置字段类型
拓展:
# 查看我们的健康值,yellow状态GET _cat/health# 查看具体信息(数据库等等)GET _cat/indices?v12345
修改 提交还是使用PUT覆盖
PUT /tes2/_doc/1{"name":"狂神123243","age":13,"birth":"1997-05-12"}{"_index" : "tes2","_type" : "_doc","_id" : "1","_version" : 2, #是修改的话,我们的版本+1了"result" : "updated", #状态 修改"_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1}弊端是,如果漏掉一个,那原来的就没了####### 改进的方法POST /tes2/_doc/1/_update{"doc":{ #doc表示你要修改的文档"name":"法外狂徒涛涛"}}{"_index" : "tes2","_type" : "_doc","_id" : "1","_version" : 3, #再次加一"result" : "updated", #状态为修改"_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 2,"_primary_term" : 1}123456789101112131415161718192021222324252627282930313233343536373839404142434445
删除
DELETE tes1 #删除test1索引#我们的返回信息{"acknowledged" : true}再去我们的head看,我们的test1索引(数据库)没了DELETE tes2/_doc/1 #删除tes2索引下的文档编号为1的数据12345678
通过DELETE命令实现删除、根据你的请求来判断是 删除索引还是删除文档记录!
关于文档的基本操作
基本操作
模拟创建数据
PUT /wang/user/1{"name":"小王","age":23,"desc":"一顿操作猛如虎,一看工资2500","tags":["技术宅","帅气","宅男"]}PUT /wang/user/2{"name":"法外狂徒涛涛","age":13,"desc":"法外狂徒","tags":["技术宅","打游戏","渣男"]}PUT /wang/user/3{"name":"上海名媛fww","age":20,"desc":"上海名媛","tags":["靓女","名媛","渣女"]}PUT /wang/user/4{"name":"小王学长","age":23,"desc":"一顿操作猛如虎,一看工资2500","tags":["技术宅","帅气","宅男"]}PUT /wang/user/5{"name":"王公子","age":23,"desc":"一顿操作猛如虎,一看工资2500","tags":["技术宅","帅气","宅男"]}123456789101112131415161718192021222324252627282930313233343536
查询数据
GET wang/user/1######## 结果{"_index" : "wang","_type" : "user","_id" : "1","_version" : 3,"_seq_no" : 2,"_primary_term" : 1,"found" : true,"_source" : {"name" : "小王","age" : 23,"desc" : "一顿操作猛如虎,一看工资2500","tags" : ["技术宅","帅气","宅男"]}}###这两个不再展示GET wang/user/2GET wang/user/3################################################################## 更新数据PUT /wang/user/3{"name":"上海名媛婉儿","age":20,"desc":"上海名媛","tags":["靓女","名媛","渣女"]}### 更推荐下面的更新方式### put不传值的地方被空值覆盖,使用_update可以避免POST wang/user/1/_update{"doc":{"name":"小王同学"}}12345678910111213141516171819202122232425262728293031323334353637383940
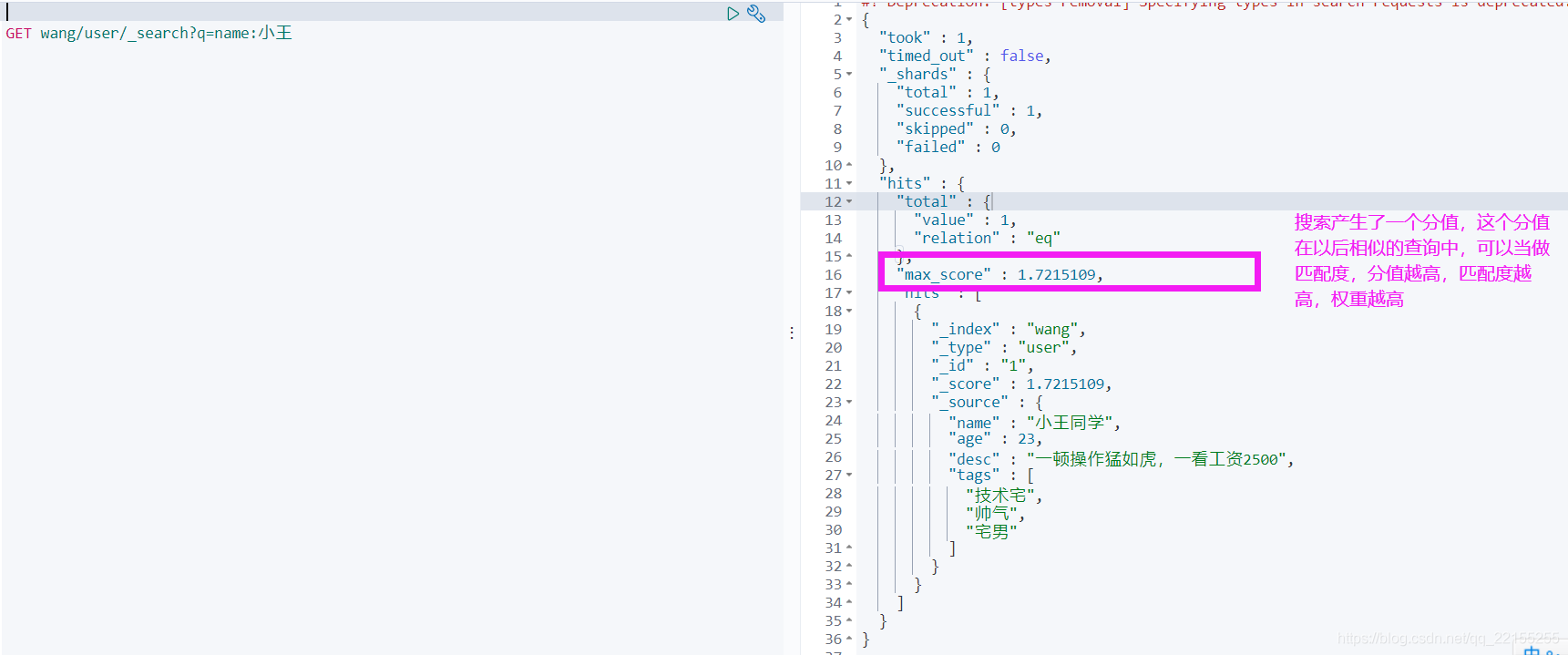
简单搜索
################################################################### 根据默认的映射规则,使用基本的查询GET wang/user/_search?q=name:小王同学 (小王也能搜出来)12
复杂操作
排序,分页,高亮,模糊查询,精准查询
实例
我们的查询的参数体是json数据
################################################################ name包含小王的文档GET wang/user/_search{"query": {"match": {"name": "小王"}}}######### 结果{"took" : 411,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : { ##在java中对应我们的对象"total" : { #总量"value" : 3,"relation" : "eq"},"max_score" : 1.494195, ##最大分值是谁 我们可以根据"hits" : [ ## 分数来排序谁最复合{"_index" : "wang","_type" : "user","_id" : "1","_score" : 1.494195,"_source" : {"name" : "小王同学","age" : 23,"desc" : "一顿操作猛如虎,一看工资2500","tags" : ["技术宅","帅气","宅男"]}},{"_index" : "wang","_type" : "user","_id" : "4","_score" : 1.494195,"_source" : {"name" : "小王学长","age" : 23,"desc" : "一顿操作猛如虎,一看工资2500","tags" : ["技术宅","帅气","宅男"]}},{"_index" : "wang","_type" : "user","_id" : "5","_score" : 0.6284153, #但是对应的他的分值较低"_source" : {"name" : "王公子", #不带小的也能查询出来"age" : 23,"desc" : "一顿操作猛如虎,一看工资2500","tags" : ["技术宅","帅气","宅男"]}}]}}## 我输出结果不想要那么多怎么做GET wang/user/_search{"query": {"match": {"name": "小王"}},"_source": ["name","desc"] # 结果过滤,只显示我们规定的} # 运行结果我就不贴代码了############################################################### 排 序GET wang/user/_search{"query": {"match": {"name": "小王"}},"sort": [ ### 根据我们的age年龄排序{"age": { # asc升序排序"order": "asc" #desc降序排序}}]}############################################################### 分 页GET wang/user/_search{"query": {"match": {"name": "小王"}},"sort": [{"age": {"order": "asc"}}],"from": 0, ### 从第几个数据开始"size": 2 ### 返回多少个数据(单页面的数据)}### 数据下标还是从0开始的
布尔值查询
############################################################### 多条件精确查询GET wang/user/_search{"query": {"bool": {"must": [ #must(and) 必须都满足,所有条件都要符合{"match": {"name": "小王"}},{"match": {"age": 23}}]}}}################################################################## 模糊查询GET wang/user/_search{"query": {"bool": {"should": [ #相当于or 满足其一即可{"match": {"name": "小王"}},{"match": {"age": 23}}]}}}################################################################## not 查询年龄不是23的人GET wang/user/_search{"query": {"bool": {"must_not": [{"match": {"age": 23}}]}}}
询
############################################################### 多条件精确查询GET wang/user/_search{"query": {"bool": {"must": [ #must(and) 必须都满足,所有条件都要符合{"match": {"name": "小王"}},{"match": {"age": 23}}]}}}################################################################## 模糊查询GET wang/user/_search{"query": {"bool": {"should": [ #相当于or 满足其一即可{"match": {"name": "小王"}},{"match": {"age": 23}}]}}}################################################################## not 查询年龄不是23的人GET wang/user/_search{"query": {"bool": {"must_not": [{"match": {"age": 23}}]}}}12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455
ElasticSearch学习笔记(二)
小Wang_start 2020-12-04 21:23:56  28
28  收藏 1
收藏 1
################################################################## 查询名字中有王 且 过滤 筛选中age>10岁的GET wang/user/_search{"query": {"bool": {"must": [{"match": {"name": "王"}}],"filter": {"range": {"age": {"gt": 10}}}}}}#### gt大于 gte大于等于 lt小于 lte小于等于GET wang/user/_search{"query": {"bool": {"must": [{"match": {"name": "王"}}],"filter": {"range": {"age": {"gte": 10, #大于等于10岁"lt": 26 #小于26岁}}}}}}123456789101112131415161718192021222324252627282930313233343536373839404142434445
匹配多个搜索条件
################################################################### 多个条件查询#### 含有渣的都会被搜索出来,只要满足一个结果就可以查出来### 渣男渣女都能查出来 两个都符合 分数比较高,权重高### 多个条件 空格隔开GET wang/user/_search{"query": {"match": {"tags": "渣 技术"}}}123456789101112
精确查询
term查询是直接通过倒排索引指定的词条进程精确查找的
关于分词:
- 直接查询精确的
- match 会使用分词器去解析(先分析文档,然后在通过分析的文档进行查询)
那我们要了解我们有两个类型的数据是text,keyword
怎么理解呢
################################################################### 创建索引数据库PUT testdb{"mappings":{"properties": {"name":{"type": "text" #name是text类型},"desc":{"type":"keyword" #desc是keyword类型}}}}############# 存放数据PUT testdb/_doc/1{"name":"狂神说Java name","desc":"狂神说Java desc"}PUT testdb/_doc/2{"name":"狂神说Java name","desc":"狂神说Java desc2"}######## 查找GET _analyze{"analyzer": "keyword","text": "狂神说Java name" #如果是keyword,就不会拆分}GET _analyze{"analyzer":"standard", #普通类型则会拆分 被拆分成了一个个字"text": "狂神说Java name"}######## 复杂查询测试GET testdb/_search{"query": {"term": {"name": "狂"}}} ### 结果会被查询出来,因为上面的name是text类型,会被分 词器解析,只要包含这个字,就能查出来# desc是keyword 那我搜他的子句能搜到么GET testdb/_search{"query": {"term": {"desc": "狂神说Java desc"}}} ##只有1条数据出来了 狂神说Java desc2 没有被查出来12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455
因此得出我们的结论,类型为keyword的字段是不会被分词器解析的
多个值匹配的精确查询
###### 构造数据PUT testdb/_doc/3{"t1":"22","t2":"2020-12-04"}PUT testdb/_doc/4{"t1":"33","t2":"2019-12-04"}##### 多条件精确查询GET testdb/_search{"query": {"bool": {"should": [ #有{"term": {"t1":"22"}},{"term": {"t1":"33"}}]}}}22 33都能被查出来 精确查询t1=22 或 33的文档1234567891011121314151617181920212223242526272829303132
高亮查询
########## 高亮显示GET wang/user/_search{"query": {"match": {"name": "小王"}},"highlight": {"fields": {"name":{}}}}########## 展示部分结果"hits" : [{"_index" : "wang","_type" : "user","_id" : "1","_score" : 1.8534994,"_source" : {"name" : "小王同学","age" : 23,"desc" : "一顿操作猛如虎,一看工资2500","tags" : ["技术宅","帅气","宅男"]},"highlight" : {"name" : ["<em>小</em><em>王</em>同学" #高亮被em包裹起来]}12345678910111213141516171819202122232425262728293031323334353637
我想自己设置高亮怎么做
上述代码改进
###### 自定义高亮条件GET wang/user/_search{"query": {"match": {"name": "小王"}},"highlight": {"pre_tags": "<p class='key' style='color:red'>","post_tags": "</p>","fields": {"name":{}}}}###### 部分结果"_index" : "wang","_type" : "user","_id" : "1","_score" : 1.8534994,"_source" : {"name" : "小王同学","age" : 23,"desc" : "一顿操作猛如虎,一看工资2500","tags" : ["技术宅","帅气","宅男"]},"highlight" : {"name" : ["<p class='key' style='color:red'>小</p><p class='key' style='color:red'>王</p>同学" #已被包裹]}12345678910111213141516171819202122232425262728293031323334353637
Spring Boot集成
导入依赖 原生依赖
<dependency><groupId> org.elasticsearch.client </ groupId><artifactId > elasticsearch -rest-high-level-client </ artifactId><version> 7.6.2 </ version></dependency>
初始化 对象
//第一步 构建一个RestHighLevelClientRestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http"),new HttpHost("localhost", 9201, "http")));//单机即new HttpHost一个就行//用完一定要关闭client.close();12345678
配置基本项目
一定要保证我们导入的版本和我们的ES版本一致
<properties><java.version>1.8</java.version><!-- 自定义版本依赖--><elasticsearch.version>7.6.1</elasticsearch.version></properties>
关于索引的API操作
@SpringBootTestclass WangEsApiApplicationTests {@Autowiredprivate RestHighLevelClient restHighLevelClient;/// 索引相关操作//测试索引的创建 Request@Testvoid testCreateIndex() throws IOException {//1.创建索引请求CreateIndexRequest request = new CreateIndexRequest("wang_index");//2.执行创建请求CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);System.out.println(createIndexResponse);//我们的head会出现wang_index索引库}//测试是否存在索引库 只能判断存不存在@Testvoid testExitstIndex() throws IOException {GetIndexRequest request = new GetIndexRequest("wang_index");boolean exists = restHighLevelClient.indices().exists(request,RequestOptions.DEFAULT);System.out.println(exists);}//删除索引void testDeleteIndex() throws IOException {DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("wang_index");AcknowledgedResponse delete = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);System.out.println(delete.isAcknowledged());//结果显示true代表成功删除}}123456789101112131415161718192021222324252627282930313233
关于文档的操作
//模拟实体类@Data@AllArgsConstructor@NoArgsConstructor@Componentpublic class User {private String name;private int age;}/ 测试文档操作@Test//测试添加文档void testAddDocument() throws IOException {//创建对象User user = new User("小王同学",3);//创建请求IndexRequest request = new IndexRequest("wang_index");//指定我们的规则request.id("1");request.timeout(TimeValue.timeValueSeconds(1));request.timeout("1s");//将我们的数据放入请求request.source(JSON.toJSONString(user), XContentType.JSON);//客户端发送请求IndexResponse indexResponse = restHighLevelClient.index(request, RequestOptions.DEFAULT);System.out.println(indexResponse.toString());System.out.println(indexResponse.status());}//测试文档是否存在@Testvoid testIsExists() throws IOException {GetRequest getRequest = new GetRequest("wang_index","1");//不获取返回的_source的上下文getRequest.fetchSourceContext(new FetchSourceContext(false));boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);System.out.println(exists);// 返回True}@Test//测试获取文档void testGetDocument() throws IOException {GetRequest getRequest = new GetRequest("wang_index", "1");GetResponse documentFields = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);System.out.println(documentFields.getSourceAsString());System.out.println(documentFields);//这里打印的全部内容跟我们的命令是一样的}@Test//测试update文档void update() throws IOException {UpdateRequest request = new UpdateRequest("wang_index", "1");request.timeout("1s");User user = new User("王公子", 18);request.doc(JSON.toJSONString(user),XContentType.JSON);UpdateResponse update = restHighLevelClient.update(request, RequestOptions.DEFAULT);System.out.println(update.status());System.out.println(update.toString());}@Test//测试删除文档void testDelete() throws IOException {DeleteRequest request = new DeleteRequest("wang_index", "1");request.timeout("1s");DeleteResponse delete = restHighLevelClient.delete(request, RequestOptions.DEFAULT);System.out.println(delete.status());System.out.println(delete.toString());}1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465
测试大批量放入请求
@Test//批量导入数据voidtestBulkRequest() throws IOException {BulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");ArrayList<User> users = new ArrayList<>();users.add(new User("wang",12));users.add(new User("王",43));users.add(new User("涛",33));users.add(new User("涛涛",13));users.add(new User("诸葛",53));users.add(new User("猪哥",13));users.add(new User("涛1",43));users.add(new User("小王2",33));users.add(new User("wang1",23));users.add(new User("wang2",33));users.add(new User("wang3",93));for (int i = 0; i <users.size() ; i++) {bulkRequest.add(new IndexRequest("wang_index").id(""+(i+1)) //不写id的话我们会生成随机的id.source(JSON.toJSONString(users.get(i)),XContentType.JSON));}BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(bulk.hasFailures());//测试是否失败}@Test//测试查询//SearchRequest 搜索请求//SearchSourceBuilder 搜索条件构造//HighlightBuilder 构建高亮// TermQueryBuilder 精确查询构造//MatchAllQueryBuilder 全部条件构造//xxxxQueryBuilder 对应我们看到的所有命令void testSelect() throws IOException {SearchRequest request = new SearchRequest("wang_index");//构建搜索条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//查询条件,我们可以使用QueryBuilders工具类来实现//QueryBuilders.termQuery精确匹配//QueryBuilders.matchAllQuery()查询所有TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name","涛");searchSourceBuilder.query(termQueryBuilder);//设置分页searchSourceBuilder.from(0);searchSourceBuilder.size(3);searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));request.source(searchSourceBuilder);SearchResponse search = restHighLevelClient.search(request, RequestOptions.DEFAULT);System.out.println(JSON.toJSONString(search.getHits()));//遍历for (SearchHit documentFields : search.getHits().getHits()) {System.out.println(documentFields);}}

若有收获,就点个赞吧
0 人点赞
