RabbitMQ 基础
初步了解 MQ
- 队列能干啥?
削峰、系统解耦、消息分发、异步、日志收集 为什么要用 RabbitMQ?
市面上很多 MQ。为什么要选择 RabbitMQ ?又或者说什么情况下适合选择 RabbitMQ ?
- 支持持久化(内存、文件方式)
- 消息延迟性低
- 支持 amqp 协议 (高级消息队列协议)
- 多语言支持
- 消费消息支持 pull 和 push
- 具有高可用性,分布式系统
- 单机吞吐量:万级 相较 kafka(十万级)较低
- 丢失率低、可以控制重复度 (kafka不能保证不重复)
- 灵活的路由:在消息进入队列之前,通过Exchange来路由消息。对于典型的路由功能,Rabbit已经提供了一些内置的Exchange来实现。针对更复杂的路由功能,可以将多个Exchange绑定在一起,也通过插件机制实现自己的Exchange。
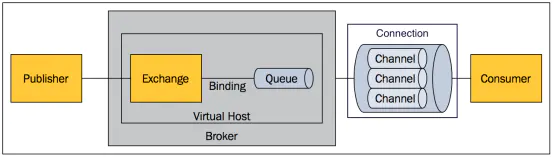
- AMQP 协议
AMQP 中增加了 Exchange 和 Binging 的角色。生产者把消息发布到Exchange 上,消息最终到达队列并被消费者接收,而 Bingding 决定交换器的消息应该发送到哪个队列。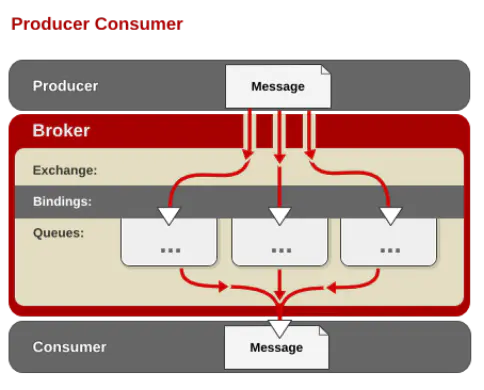
RabbitMQ
RabbitMQ的整体架构:
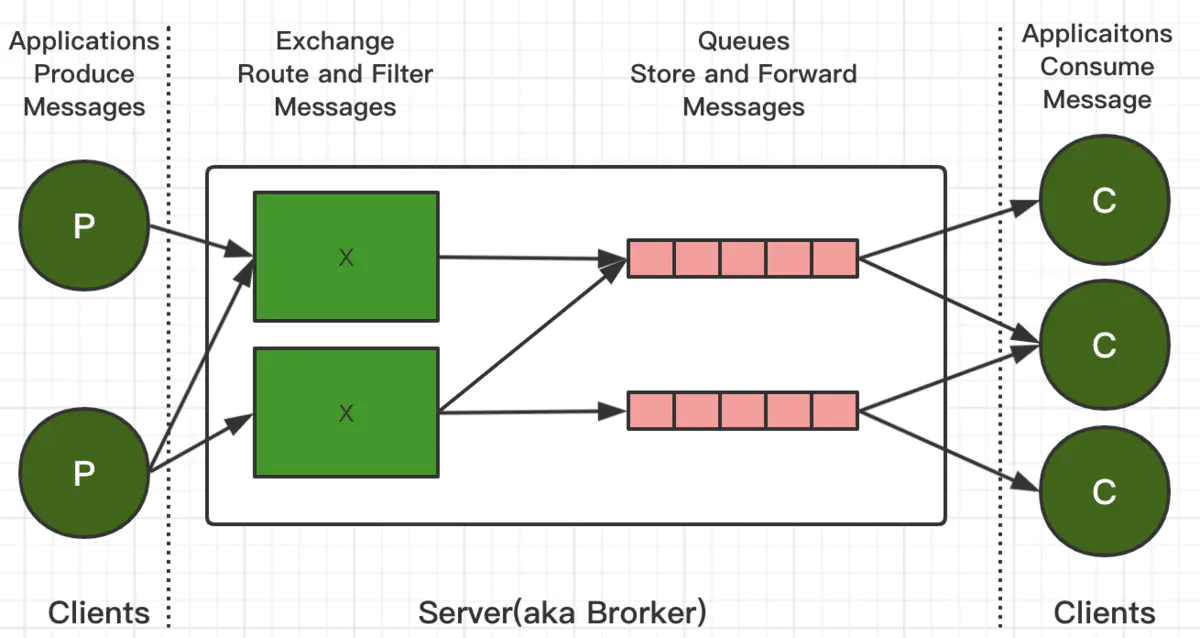
RabbitMQ的消息流转
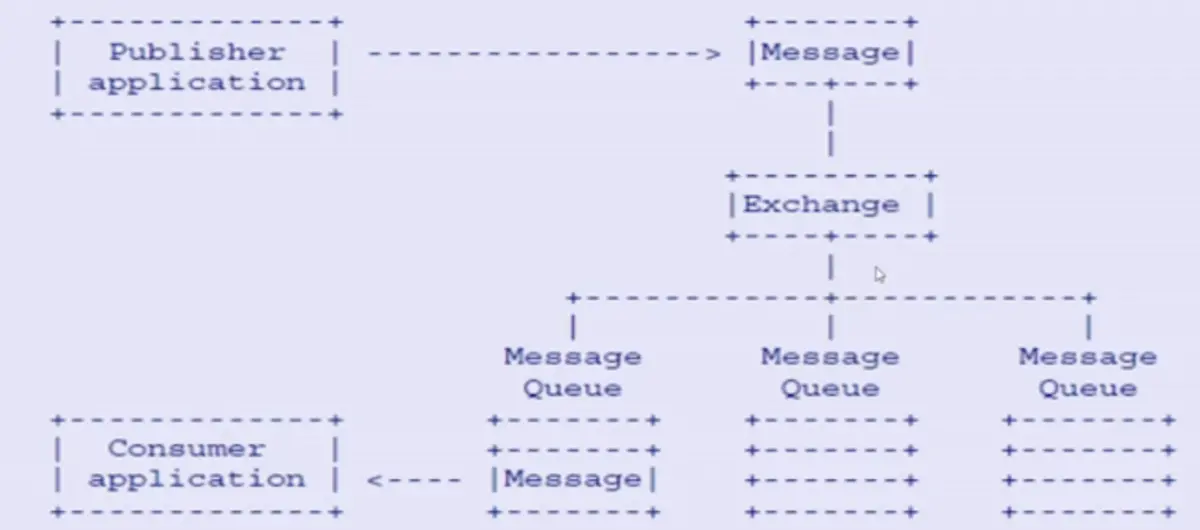
RabbitMQ各组件功能
RabbitMQ 多种Exchange 类型
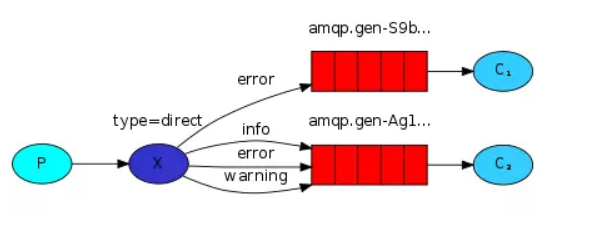
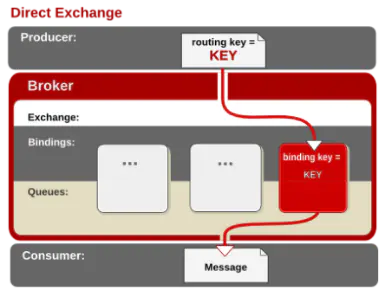
- direct:直接连接交换机。消息中的路由键(routing key )如果和Binding中的binding key 一致,交换机就将信息从exchange发送到对应的队列中。路由键和队列名完全匹配。
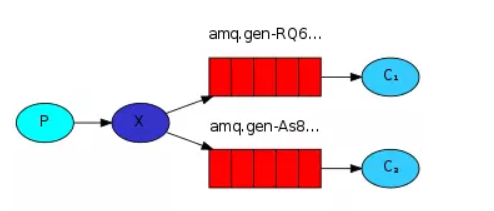
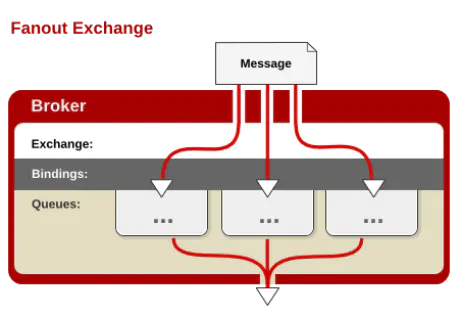
- fanout:无路由交换机。每个发到fanout类型交换器的消息都会分发到所有的与它绑定的队列中去。fanout不处理路由键,只是简单的将队列绑定到交换机上。fanout转发消息是最快的。
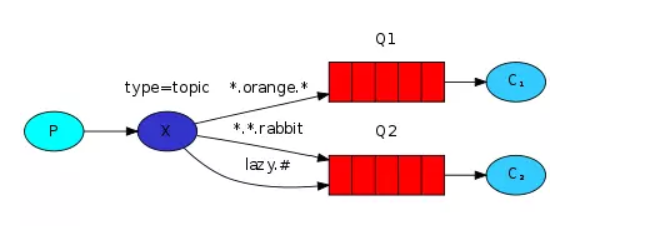
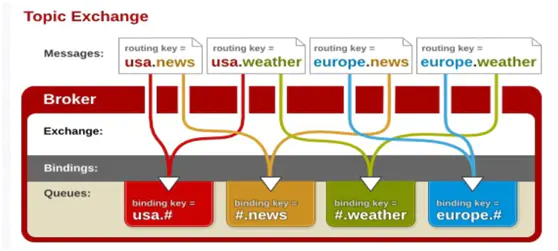
- topic:主题路由匹配交换机。topic 通过模式匹配分配消息的路由键属性。将队列绑定到某个模式上,然后路由键和模式进行匹配。
- routing key为一个句点号“. ”分隔的字符串(我们将被句点号“. ”分隔开的每一段独立的字符串称为一个单词),如“stock.usd.nyse”、“nyse.vmw”、“quick.orange.rabbit”
- binding key与routing key一样也是句点号“. ”分隔的字符
- binding key中可以存在两种特殊字符“”与“#”,用于做模糊匹配,其中“”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)
TTL
TTL:time to live. 生存时间。可以在消息发送的时候,指定过期时间。也可以在创建Exchange时指定。从消息进入队列开始算起,超过指定的时间,则将过期的队列数据清除。
DLX
- DLX: dead letter exchange . 死信队列。当一个队列中的信息变成死信,则会自动发送到另一个Exchange.这个Exchange就是死信队列。
还可以设置一个死信路由键x-dead-letter-routing-key.设置queue的arguments,spring amqp和客户端的设置基本类似,无非是在生成队列时,一个是调用Queue的构造器传入arguments,一个是channel.declareQueue传入arguments。 - 消息变成死信的几种情况:
- 消息被拒绝
- 消息TTL过期
- 队列达到最大长度
- 设置TTL(TTL存在两种)
- 每个队列中消息的TTL在queue的arguments中设置arguments.put(“x-message-ttl”, 6000);
- 每个消息的TTL,在消息头中设置
//spring amqpMessage expirationMsg=new Message(message.getBytes(),MessagePropertiesBuilder.newInstance().setExpiration(originalExpiration).build());rabbitTemplate.send(exchange, key, expirationMsg, correlationId);//客户端:AMQP.BasicProperties properties = new AMQP.BasicProperties();properties.setExpiration("60000");channel.basicPublish(exchangeName,routingKey,mandatory,properties,"ttlTestMessage".getBytes());
两种TTL的区别在于,判断是否过期的时候,在queue上设置的ttl只需要判断queue头信息即可,在message上设置的ttl需要判断每个消息头。
生产者端数据丢失
生产者Confirm机制
生产者如何判断消息投递成功?amqp本身有事务,可以控制数据回滚。其次,还可以使用confirm机制进行应答。
- 在channel上开启channel.confirmSelect();
- 在channel上开启监听:addConfirmListener
/*** @version V1.0* @Description: https://blog.csdn.net/qq_35387940/article/details/100514134* @Auther: ly* @Date: 2020/7/15 16:03*/@Configurationpublic class RabbitConfig {/*** 推送消息存在四种情况:①消息推送到server,但是在server里找不到交换机结论: ①这种情况触发的是 ConfirmCallback 回调函数。exchange 错误,queue 正确,confirm被回调, ack=false②消息推送到server,找到交换机了,但是没找到队列结论:②这种情况触发的是 ConfirmCallback和RetrunCallback两个回调函数。exchange 正确,queue 错误 ,confirm被回调, ack=true; return被回调 replyText:NO_ROUTE③消息推送到sever,交换机和队列啥都没找到结论: ③这种情况触发的是 ConfirmCallback 回调函数。exchange 错误,queue 错误,confirm被回调, ack=false④消息推送成功结论: ④这种情况触发的是 ConfirmCallback 回调函数。ack=true*/@Beanpublic RabbitTemplate createRabbitTemolate(ConnectionFactory connectionFactory){RabbitTemplate rabbitTemplate = new RabbitTemplate();rabbitTemplate.setConnectionFactory(connectionFactory);//设置开启mandatory,才能触发回调函数,无论消息推送结果怎么样,都强制调用回调函数rabbitTemplate.setMandatory(true);rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {@Overridepublic void confirm(CorrelationData correlationData, boolean ack, String cause) {System.out.println("ConfirmCallback: "+"相关数据:"+correlationData);System.out.println("ConfirmCallback: "+"确认情况:"+ack);System.out.println("ConfirmCallback: "+"原因:"+cause);}});rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {@Overridepublic void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {System.out.println("ReturnCallback: "+"消息:"+message);System.out.println("ReturnCallback: "+"回应码:"+replyCode);System.out.println("ReturnCallback: "+"回应信息:"+replyText);System.out.println("ReturnCallback: "+"交换机:"+exchange);System.out.println("ReturnCallback: "+"路由键:"+routingKey);}});return rabbitTemplate;}}
Return 消息机制
Return listener 用于处理不可被路由的消息。既不能从Exchange到Queue的消息。基础API中有个关键的配置项Mandatory:如果为true,监听器会收到路由不可达的消息,然后进行处理。如果为false,broker端会自动删除该消息。
消息队列端数据丢失
处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。这个持久化配置可以和confirm机制配合使用,你可以在消息持久化磁盘后,再给生产者发送一个Ack信号。这样,如果消息持久化磁盘之前,rabbitMQ阵亡了,那么生产者收不到Ack信号,生产者会自动重发。
那么如何持久化呢,这里顺便说一下吧,其实也很容易,就下面两步
①、将queue的持久化标识durable设置为true,则代表是一个持久的队列
②、发送消息的时候将deliveryMode=2
这样设置以后,rabbitMQ就算挂了,重启后也能恢复数据。在消息还没有持久化到硬盘时,可能服务已经死掉,这种情况可以通过引入mirrored-queue即镜像队列,但也不能保证消息百分百不丢失(整个集群都挂掉)
/*** https://www.cnblogs.com/chongaizhen/p/11093489.html* 第二个参数:queue的持久化是通过durable=true来实现的。* 第三个参数:exclusive:排他队列,如果一个队列被声明为排他队列,该队列仅对首次申明它的连接可见,并在连接断开时自动删除。这里需要注意三点:1. 排他队列是基于连接可见的,同一连接的不同信道是可以同时访问同一连接创建的排他队列; 2.“首次”,如果一个连接已经声明了一个排他队列,其他连接是不允许建立同名的排他队列的,这个与普通队列不同; 3.即使该队列是持久化的,一旦连接关闭或者客户端退出,该排他队列都会被自动删除的,这种队列适用于一个客户端发送读取消息的应用场景。* 第四个参数:自动删除,如果该队列没有任何订阅的消费者的话,该队列会被自动删除。这种队列适用于临时队列。* @param* @return* @Author*/@Beanpublic Queue queue() {Map<String, Object> arguments = new HashMap<>();arguments.put("x-message-ttl", 25000);//25秒自动删除Queue queue = new Queue("topic.messages", true, false, true, arguments);return queue;}
MessageProperties properties=new MessageProperties();properties.setContentType(MessageProperties.DEFAULT_CONTENT_TYPE);properties.setDeliveryMode(MessageProperties.DEFAULT_DELIVERY_MODE);//持久化设置properties.setExpiration("2018-12-15 23:23:23");//设置到期时间Message message=new Message("hello".getBytes(),properties);this.rabbitTemplate.sendAndReceive("exchange","topic.message",message);
消费者端数据丢失
消费端确认消息的方式
当消费者消费数据的时候,没有办法保证一定会消费成功。AcknowledgeMode 有 NONE (不确认模式)、MANUAL (手动确认模式)和 AUTO(自动确认模式)。
①自动确认模式,消费者挂掉,待ack的消息回归到队列中。消费者抛出异常,消息会不断的被重发,直到处理成功。不会丢失消息,即便服务挂掉,没有处理完成的消息会重回队列,但是异常会让消息不断重试。
②手动确认模式,RabbitMQ手动应答方式有ACK(已经正确投递,且已经被正确处理)和NACK(已经正确投递,但没有被正确处理,批量处理)模式、Reject(已经正确投递,但没有被正确处理,单个处理)模式。
③不确认模式,acknowledge=”none” 不使用确认机制,只要消息发送完成会立即在队列移除,无论客户端异常还是断开,只要发送完就移除,不会重发。
/** 设置ack的两种方式 *///1. spring amqp :spring.rabbitmq.listener.simple.acknowledge-mode=autosimpleRabbitListenerContainerFactory.setAcknowledgeMode(AcknowledgeMode.AUTO);//2. 客户端:channel.basicConsumer中的参数//第二个参数设为true为自动应答,false为手动ackchannel.basicConsume("队列名", true, new DefaultConsumer(channel);
AcknowledgeMode MANUAL
确认消息 ACK
已经正确投递,且已经被正确处理。如果对数据完整性要求比较高,这个时候我们可以设置ACK为手动应答模式,既只有当消费端成功消费消息后,才将消息清除。
/** 消费端成功消费消息后,需要给 rabbitmq 确认消息. 只要开启手动确认模式,代码中就必须要有该语句。*///deliveryTag:消息在mq中的唯一标识//multiple:是否批量.true:将一次性ack所有小于deliveryTag的消息。public void basicAck(long deliveryTag, boolean multiple);long deliveryTag = message.getMessageProperties().getDeliveryTag();channel.basicAck(deliveryTag, true);
确认消息 NACK
Nack则可以一次性拒绝多个消息。这是RabbitMQ对AMQP规范的一个扩展。
通过RejectRequeuConsumer可以看到当requeue参数设置为true时(让未消费成功的数据重回队列头部),消息发生了重新投递(一般不建议使用该方式)。可以选择将requeue参数设置为false,让mq丢弃该消息。然后再将该消息重新发送到队尾。
//deliveryTag:消息在mq中的唯一标识//multiple:是否批量(和qos设置类似的参数)//requeue:是否需要重回队列。或者丢弃或者重回队首再次消费public void basicNack(long deliveryTag,boolean multiple,boolean requeue);
确认消息 Reject
Reject在拒绝消息时,可以使用requeue标识,告诉RabbitMQ是否需要重新发送给别的消费者。不重新发送,一般这个消息就会被RabbitMQ丢弃。Reject一次只能拒绝一条消息。
//deliveryTag:消息在mq中的唯一标识//requeue:是否需要重回队列。或者丢弃或者重回队首再次消费public void basicReject(long deliveryTag, boolean requeue);channel.basicReject(envelope.getDeliveryTag(),true);
AcknowledgeMode AUTO
AcknowledgeMode 除了 NONE 和 MANUAL 之外还有 AUTO ,它会根据方法的执行情况来决定是否确认还是拒绝(是否重新入queue)
如果消息成功被消费(成功的意思是在消费的过程中没有抛出异常),则自动确认
当抛出 AmqpRejectAndDontRequeueException 异常的时候,则消息会被拒绝,且 requeue = false(不重新入队列)
当抛出 ImmediateAcknowledgeAmqpException 异常,则消费者会被确认
其他的异常,则消息会被拒绝,且 requeue = true(如果此时只有一个消费者监听该队列,则有发生死循环的风险,多消费端也会造成资源的极大浪费,这个在开发过程中一定要避免的)。可以通过 setDefaultRequeueRejected(默认是true)去设置
@Beanpublic SimpleMessageListenerContainer messageListenerContainer(ConnectionFactory connectionFactory){SimpleMessageListenerContainer container = new SimpleMessageListenerContainer();container.setConnectionFactory(connectionFactory);container.setQueueNames("consumer_queue"); // 监听的队列container.setAcknowledgeMode(AcknowledgeMode.AUTO); // 根据情况确认消息container.setMessageListener((MessageListener) (message) -> {System.out.println("====接收到消息=====");System.out.println(new String(message.getBody())); //抛出NullPointerException异常则重新入队列//throw new NullPointerException("消息消费失败");//当抛出的异常是AmqpRejectAndDontRequeueException异常的时候,则消息会被拒绝,且requeue=false//throw new AmqpRejectAndDontRequeueException("消息消费失败");//当抛出ImmediateAcknowledgeAmqpException异常,则消费者会被确认throw new ImmediateAcknowledgeAmqpException("消息消费失败");});return container;}
消费端自定义监听
消费端消费消息可以分为两种方式,一种是pull(拉)消费端通过while循环调用consumer.nextDelivry()来获取数据。该种情况,死循环会消耗CPU资源。一种是push(推)是由mq将消息推送过来。
Basic.Consume将信道(Channel)置为接收模式,直到取消队列的订阅为止。在接受模式期间,RabbitMQ会不断的推送消息给消费者。当然推送消息的个数还是受Basic.Qos的限制。如果只想从队列获得单条消息而不是持续订阅,建议还是使用Basic.Get进行消费。但是不能将Basic.Get放在一个循环里来代替Basic.Consume,这样会严重影响RabbitMQ的性能。如果要实现高吞吐量,消费者理应使用Basic.Consume方法。
消费端限流
RabbitMQ提供了一种qos(服务质量保证)功能。即在非自动确认消息的前提下(非ACK),如果一定数目的消息(通过基于consume或者channel设置qos的值)未被确认前,不进行消费新的消息。
// prefetchSize:消息体大小限制;0为不限制// prefetchCount:RabbitMQ同时给一个消费者推送的消息个数。即一旦有N个消息还没有ack,则该consumer将block掉,直到有消息ack。默认是1.// global:限流策略的应用级别。consumer[false]、channel[true]。void BasicQos(unit prefetchSize, unshort prefetchCount, bool global);channel.basicQos(...);
参考:RabbitMQ (https://www.jianshu.com/p/78847c203b76)

若有收获,就点个赞吧
0 人点赞
