MongoDB 简介
MongoDB 背景
MongoDB 是一款非关系型数据库,也是非关系型数据库当中功能最丰富、最像关系型数据库的产品。
同时,它也是一款功能完善的分布式文档数据库,由 C++ 编写,它具备支撑今天主流 WEB 应用的关键功能:索引、复制、分片、丰富的查询语法,特别灵活的数据模型。
MongoDB 在高性能、动态扩缩容、高可用、易部署、易使用、海量数据存储等方面拥有很大优势。
近些年,MongoDB 在 DB-Engines 流行度排行榜稳居榜单 Top5 ,且历年得分是持续增长的,具体如下图所示:
DB-Engines 是一个对数据库管理系统受欢迎程度进行排名的网站。
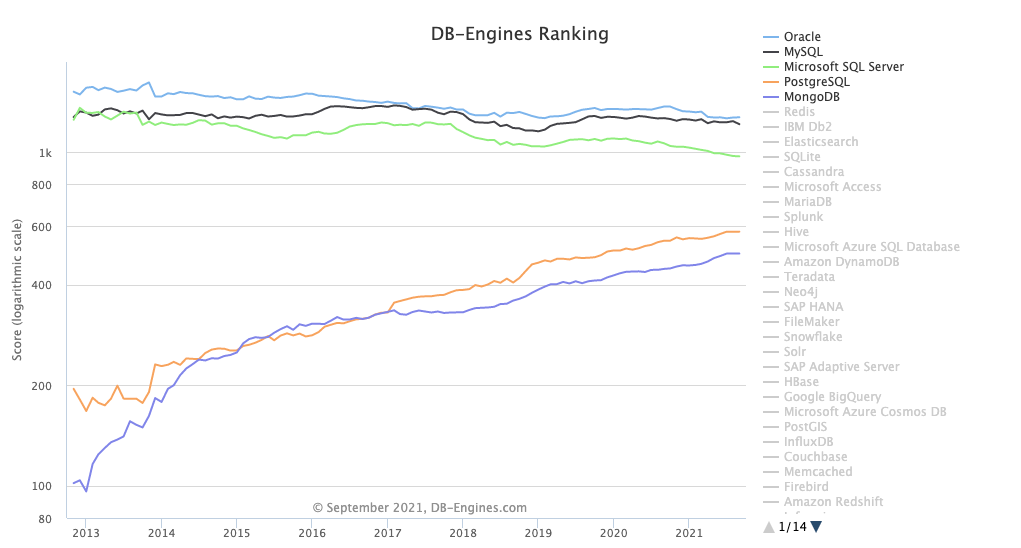
数据库流行度排名分数表:MongoDB 是非关系型数据库中排行最高的。
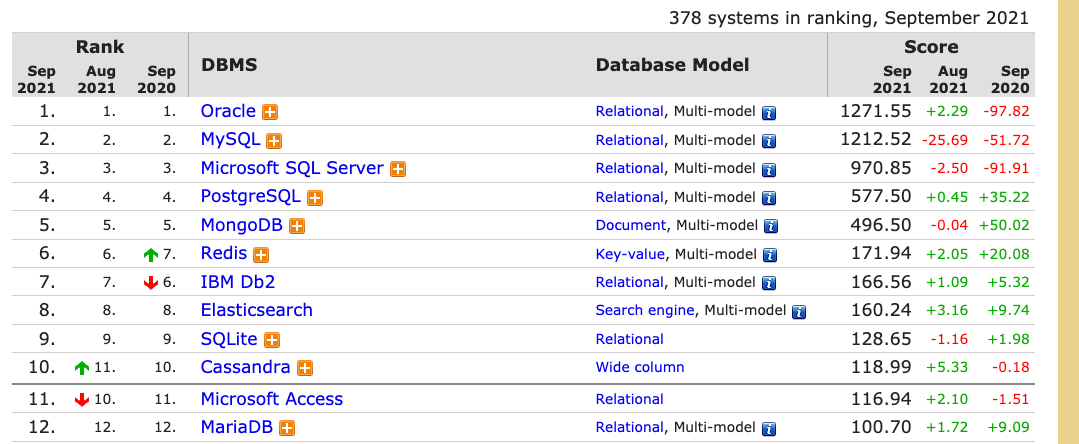
Mongodb 演化史
MongoDB 1.0 : 2009 年 2 月,提供了大部分基本的查询功能。
MongoDB 1.2 : 2009 年 12 月,引入了 map-reduce,支持大规模数据处理。
MongoDB 1.4 : 2010 年 3 月,引入了后台索引创建
MongoDB 1.6 : 2010 年 8 月, 引入了一些主要特性,比如用于水平伸缩的分片、具备自动故障转移能力的副本集以及对 IPv6 的支持。
MongoDB 2.2 : 2012 年 8 月, 引入了聚合管道,可以将多个数据处理步骤组合成一个操作链。
MongoDB 2.4 : 2013 年 3 月, 在 Mongo Shell 中引入了文本搜索和谷歌的 V8 JS 引擎等增强功能。
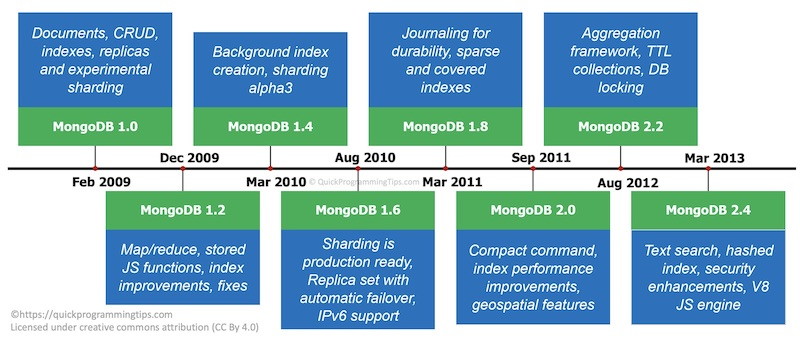
MongoDB 3.0 :2015 年 3 月,增加了新的 WiredTiger 存储引擎、可插拔存储引擎 API、增加了 50 个副本集限制和安全改进。
MongoDB 3.2 : 2016年12月,支持文档验证、部分索引和一些主要的聚合增强。
MongoDB 3.6 : 2017 年 11 月,为多集合连接查询、变更流和使用 JSON 模式进行文档验证提供了更好的支持。
MongoDB 3.6 : 是微软 Azure CosmosDB 截至 2020 年 8 月能够支持的最新版本。
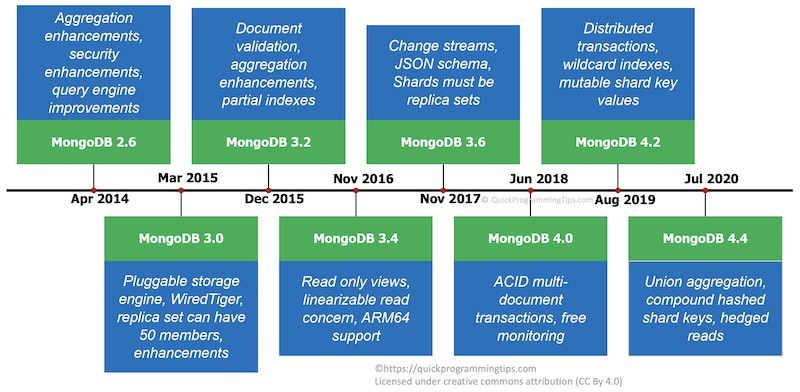
MongoDB 4.0 : 2018 年 6 月, 提供了跨文档事务处理能力。
MongoDB 4.2 : 2019年,提供了分布式事务支持。
MongoDB 4.4 : 2020 年 8 月,包含了一些主要的特性增强,比如多集合联合聚合、复合哈希分片键和对冲读(Hedged Read)/ 镜像读。
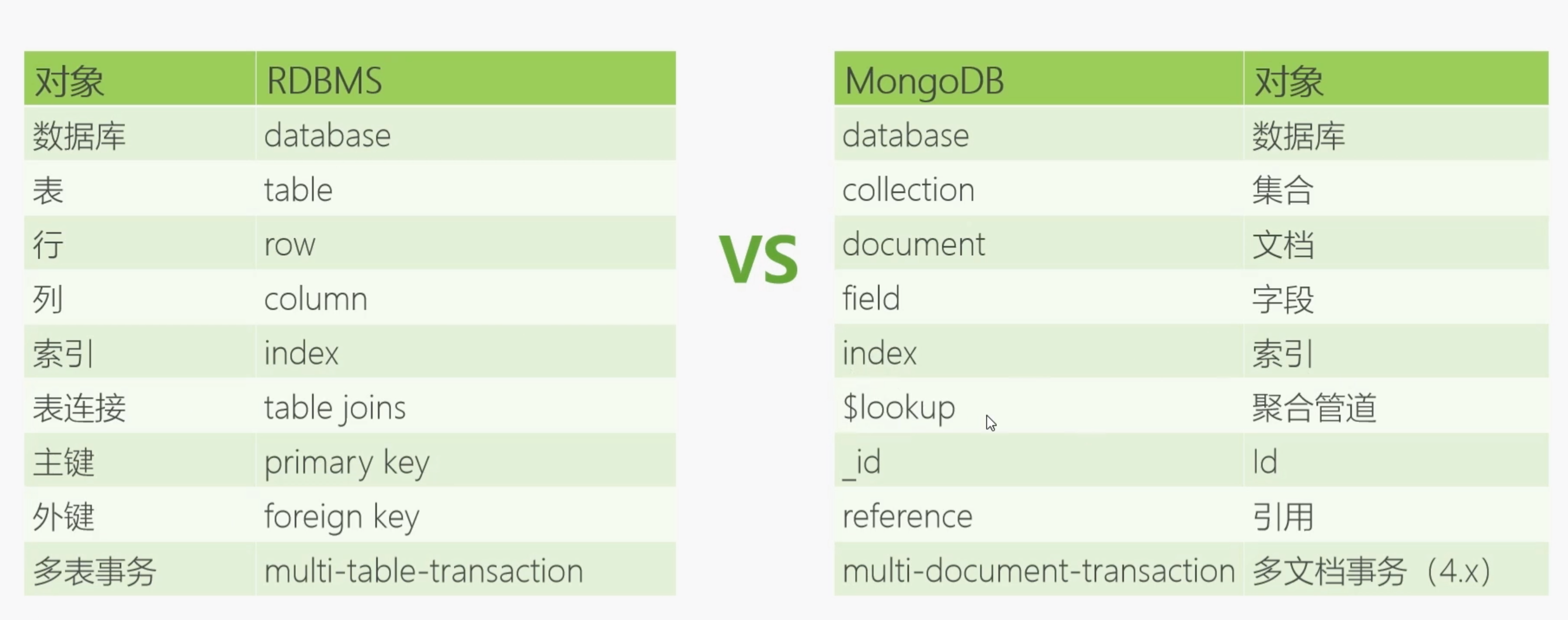
与关系型数据库的对应关系
MongoDB 和RDBMS(关系型数据库)对比
MongoDB 设计特点
易于使用
与关系型数据库相比,面向对象的数据库不在有行(row)的概念,取而代之的是更为灵活的“文档”(document)模型。通过在文档里嵌入文档和数组,面向文档的方法能够仅使用一条记录来表现复杂的层次关系。
另外,不再有预定义模式:文档的键和值不再是固定的类型和大小。由于没有固定的大小,所以需要添加和删除字段变得更容易了。有利于开发者能够快速迭代。
易于扩展
在日常的开发中,由于需要存储的数据量不断增长,开发者面临一个困难:应该如何选择数据库?实质上,这是纵向扩展和横向扩展之间的选择。纵向扩展就是使用计算能力更强的机器,而横向扩展就是通过分区将数据分散到更多的机器上。
MongoDB 的设计采用横向扩展。面向文档的数据模型使它能很容易的在多台服务器之间进行数据分割。MongoDB 能自动处理跨集群的数据和负载,自动重新分配文档,以及将用户请求路由到正确的机器上。这样,开发者能够集中精力编写应用程序,而不需要考虑如何扩展的问题。
丰富的功能
MongoDB作为一款通用型数据库,除了能够创建、读取、更新和删除数据之外,还提供一系列不断扩展的独特功能。
- 索引(indexing)
MongoDB支持通用二级索引,允许多种快速查询,且提供唯一索引、复合索引、地理空间索引,以及全文索引。 - 聚合(aggregation)
MongoDB支持“聚合管道”(aggregation pipeline)。用户能通过简单的片段创建复杂的聚合,并通过数据库自动优化。 - 特殊的集合类型
MongoDB支持存在时间有限的集合,适用于那些将在某个时刻过期的数据,如会话(session)。类似地,MongoDB也支持固定大小的集合,用于保存近期数据,如日志。 - 大文件存储(file storage)
MongoDB 中 BSON 对象最大不能超过 16 MB。对于大文件的存储,BSON 格式无法满足。GridFS 机制提供了一个存储大文件的机制,可以将一个大文件分割成为多个较小的文档进行存储。 - 复制集
通过复制机制,可以实现数据备份、故障恢复、读扩展等功能。基于复制集的复制机制提供了自动故障恢复的功能,确保了集群数据不会丢失。 - 分片
MongoDB 支持集群自动切分数据,可以使集群存储更多的数据,实现更大的负载,在数据插入和更新时,能够自动路由和存储。 - 分布式事务
主要功能介绍
MongoDB 文档
文档是MongoDB的核心概念,文档就是键值对的一个有序集,相当于关系型数据库中的一行。MongoDB 文档采用 BSON 格式进行存储。BSON是一种类json的一种二进制形式的存储格式,简称Binary JSON,BSON有三个特点:轻量性、可遍历性、高效性。
mongodb 文档示例:
{_id: ObjectId("5099803df3f4948bd2f98391"),name: { first: "Alan", last: "Turing" },birth: new Date('Jun 23, 1912'),death: new Date('Jun 07, 1954'),contribs: [ "Turing machine", "Turing test", "Turingery" ],views : NumberLong(1250000)}
它和JSON一样,支持内嵌的文档对象和数组对象。但BSON有JSON没有的一些数据类型,如下所示:
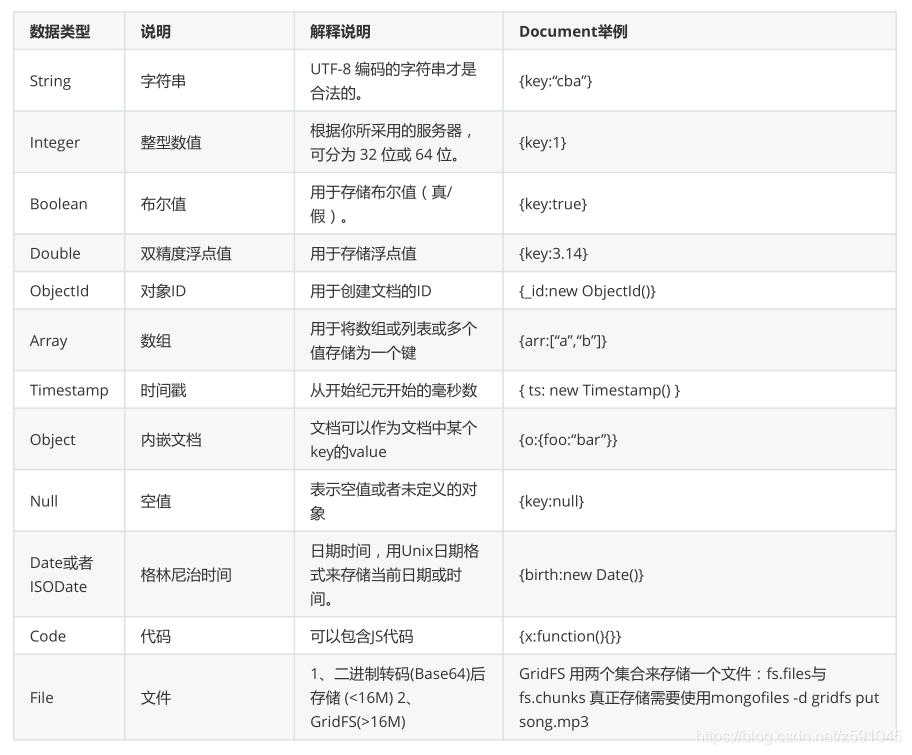
MongoDB ObjectId
ObjectId 可以快速生成并排序,长度为 12 个字节,包括:
- 一个 4 字节的时间戳,表示 unix 时间戳
- 5 字节随机值
- 3 字节递增计数器,初始化为随机值
在 MongoDB 中,存储在集合中的每个文档都需要一个唯一的 _id 字段作为主键。如果插入的文档省略了 _id 字段,则自动为文档生成一个 _id。

MongoDB 设计的初衷就是用作分布式数据库,所以能够在分片环境中生成唯一的标识符非常重要。
MongoDB 集合
集合就是一组文档,相当于关系型数据库的表。MongoDB 集合存在于数据库中,没有固定的结构,可以往集合插入不同格式和类型的数据。集合名必须以下划线或者字母符号开始,并且不能包含 $,不能为空字符串(比如 “”),不能包含空字符,且不能以 system. 为前缀。
普通集合:
- 普通集合是动态创建的,不需要事先创建。当第一个文档插入,或者第一个索引创建时,集合就会被创建。
固定集合:
- capped collection 是固定大小的集合,需要提前创建好,单位是字节。
- 它的工作方式与循环队列类似,当一个集合填满了被分配的空间,则通过覆盖最早的文档来为新的文档腾出空间。
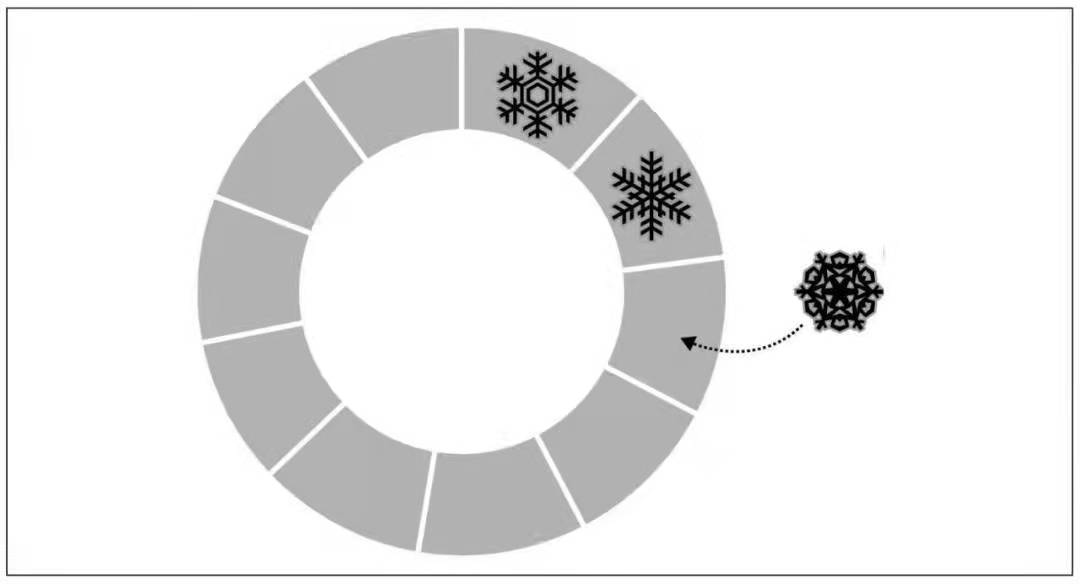
新文档被插入到队列末尾
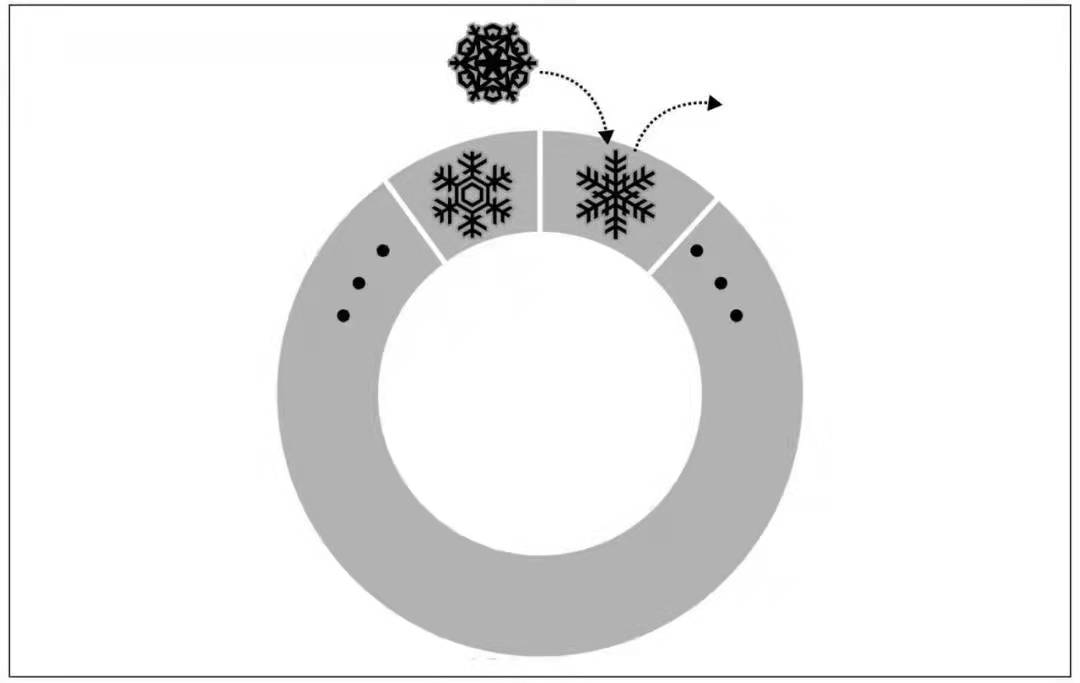
如果队列已经被占满,那么最老的文档会被之后插入的新文档覆盖
- 自然排序:和标准的 collection 不同,capped collection 可以按照文档的插入顺序保存到集合中,而且这些文档在磁盘上存放位置也是按照插入顺序来保存的,所以更新 capped collection 中的文档,不可以超过之前文档的大小,以便确保所有文档在磁盘上的位置一直保持不变。
MongoDB 索引
MongoDB 支持丰富的索引方式。如果没有索引,读操作就必须扫描集合中的每个文档并筛选符合查询条件的记录。索引能够在很大程度上提高查询速度。
单字段索引:有三种方式
- 在单个字段上创建索引;
- 在嵌入式字段上创建索引;
- 在内嵌文档上创建索引。
{"username" : "sid","loc" : {"ip" : "1.2.3.4","city" : "Springfield","state" : "NY"},"operate":[1,2,3]}
复合索引:基于多个字段的索引。对任何复合索引施加 32 个字段的限制。对于复合索引,MongoDB 可以使用索引来支持对索引前缀的查询。
- 多键索引:对于某个索引的键,如果这个键在某个文档中是一个数组,那么这个索引就会被标记为多键索引。对数组建立索引,实际上是对数据中的每个元素建立索引,而不是对数组本身建立索引。一个索引中的数组字段最多只能有一个。这是为了避免在多键索引中索引条目爆炸性增长。
// x和y都是数组——这是非法的!> db.multi.insert({"x" : [1, 2, 3], "y" : [4, 5, 6]})cannot index parallel arrays [y] [x]//如果MongoDB要为上面的例子创建索引,它必须要创建这么多索引条目:{"x" : 1, "y" : 4}{"x" : 1, "y" : 5}{"x" : 1, "y" : 6}{"x" : 2, "y" : 4}{"x" : 2, "y" : 5}{"x" : 2, "y" : 6}{"x" : 3, "y" : 4}{"x" : 3, "y" : 5}{"x" : 3, "y" : 6}
- 全文本索引:支持对字符串内容的文本搜索查询。文本索引可以包含任何值为字符串或字符串元素数组的字段。使用全文本索引可以非常快的进行文本搜索,就如同内置了多种语言分词机制的支持一样。但是创建全文本索引的成本很高。在一个操作频繁的集合上创建全文本索引可能导致MongoDB过载,所以应该是在离线状态下创建全文本索引,或者是在对性能没有要求时。一个集合最多可以有一个文本索引。
为了进行文本搜索,首先需要创建一个”text”索引:
> db.hn.ensureIndex({"title" : "text"})
现在,必须通过text命令才能使用这个索引:
test> db.runCommand({$text:{$search : "ask hn"}}){"queryDebugString" : "ask|hn||||||","language" : "english","results" : [{"score" : 2.25,"obj" : {"_id" : ObjectId("50dcab296803fa7e4f000011"),"title" : "Ask HN: Most valuable skills you have? ","url" : "/comments/4974230","id" : 4974230,"commentCount" : 37,"points" : 31,"postedAgo" : "2 hours ago","postedBy" : "bavidar"}},{"score" : 0.5625,"obj" : {"_id" : ObjectId("50dcab296803fa7e4f000001"),"title" : "Show HN: How I turned an old book...","url" : "http://www.howacarworks.com/about","id" : 4974055,"commentCount" : 44,"points" : 95,"postedAgo" : "2 hours ago","postedBy" : "AlexMuir"}},{"score" : 0.5555555555555556,"obj" : {"_id" : ObjectId("50dcab296803fa7e4f000010"),"title" : "Show HN: ShotBlocker - iOS Screenshot detector...","url" : "https://github.com/clayallsopp/ShotBlocker","id" : 4973909,"commentCount" : 10,"points" : 17,"postedAgo" : "3 hours ago","postedBy" : "10char"}}],"stats" : {"nscanned" : 4,"nscannedObjects" : 0,"n" : 3,"timeMicros" : 89},"ok" : 1}
匹配到的文档是按照相关性降序排列的:”Ask HN”位于第一位,然后是两个部分匹配的文档。每个对象前面的”score”字段描述了每个结果与查询的匹配程度。
与普通的多键索引不同,全文本索引中的字段顺序不重要:每个字段都被同等对待。同时,我们也可以为每个字段指定不同的权重来控制不同字段的相对重要性:
db.news.ensureIndex({"title":"text","context":"text"},{"weights":{"title":2,"context":1}})
- 地理空间索引:支持球体或平面上的地理空间查询,可以指定点、线和多边形。我们可以用此来查询包含当前经纬度、与当前经纬度相交和邻近当前经纬度的数据。如:可以使用该功能查询附近的人。
- ttl 索引:一种特殊的单字段索引(具有生命周期的索引),这种索引允许为每一个文档设置一个超时时间,一个文档到达预设值的老化程度之后就会被删除。这种类型的索引对于缓存问题(比如保存会话)非常有用。TTL 索引不能保证过期数据在过期时立即删除。默认每 60 秒运行一次删除过期文档的后台进程。capped collection 不支持 ttl 索引。
- 唯一索引:确保索引字段不会存储重复值。如果集合已经存在了违反索引的唯一约束的文档,则后台创建唯一索引会失败。
- 部分索引:只索引集合中满足指定筛选器表达式的文档。例如:
表示只对集合中 b 字段小于 100 的文档进行索引,大于等于 100 的文档不会被索引。这可以有效提高存储效率。db.collection.createIndex({ a:1 },{ partialFilterExpression: { b: { $lt: 100 } } })
MongoDB 聚合
MongoDB 聚合框架(Aggregation Framework)是一个计算框架,功能是:
- 作用在一个或几个集合上。
- 对集合中的数据进行的一系列运算。
- 将这些数据转化为期望的形式。
MongoDB 提供了三种执行聚合的方法:聚合管道,map-reduce 和单一目的聚合方法(如 count、distinct 等方法)。
1. 聚合管道
在聚合管道中,整个聚合运算过程称为管道(pipeline),它是由多个步骤(stage)组成的, 每个管道的工作流程是:
- 接受一系列原始数据文档
- 对这些文档进行一系列运算
- 结果文档输出给下一个 stage
聚合计算基本格式如下:
pipeline = [$stage1, $stage2, ...$stageN];db.collection.aggregate( pipeline, { options } )
2. map-reduce
MapReduce是聚合工具中的明星,它非常强大、非常灵活。有些问题过于复杂,无法使用聚合框架的查询语言来表达,这时可以使用MapReduce。MapReduce使用JavaScript作为“查询语言”,因此它能够表达任意复杂的逻辑。然而,这种强大是有代价的:MapReduce非常慢,不应该用在实时的数据分析中。
MapReduce能够在多台服务器之间并行执行。它会将一个大问题拆分为多个小问题,将各个小问题发送到不同的机器上,每台机器只负责完成一部分工作。所有机器都完成时,再将这些零碎的解决方案合并为一个完整的解决方案。
map-reduce 操作包括三个阶段:
- 最开始是映射(map),将操作映射到集合中的每个文档。这个操作要么“无作为”,要么“产生一些键和X个值”。
- 然后就是中间环节,称作洗牌(shuffle),按照键分组,并将产生的键值组成列表放到对应的键中。
- 化简(reduce)则把列表中的值化简成一个单值。这个值被返回,然后接着进行洗牌,直到每个键的列表只有一个值为止,这个值也就是最终结果。
3. 单一目的聚合方法
主要包括以下三个:
- db.collection.estimatedDocumentCount()
- db.collection.count()
- db.collection.distinct()
MongoDB WiredTiger 引擎
从 3.2 版本开始,默认使用 WiredTiger 存储引擎,每个被创建的表和索引,都对应各自独立的 WiredTiger 表。为了保证 MongoDB 中数据的持久性,使用 WiredTiger 的写操作会先写入 cache,并持久化到 WAL(write ahead log),每 60s 或日志文件达到 2 GB,就会做一次 checkpoint,定期将缓存数据刷到磁盘,将当前的数据持久化产生一个新的快照。
WiredTiger 数据结构
MongoDB 采用插件式存储引擎架构,实现了服务层和存储引擎层的解耦,可支持使用多种存储引擎。除此之外,底层的 WiredTiger 引擎还支持使用 B+ 树和 LSM 两种数据结构进行数据管理和存储,默认使用 B+ 树结构做存储。使用 B+ 树时,WiredTiger 以 page 为单位往磁盘读写数据,B+ 树的每个节点为一个 page,包含三种类型的 page,即 root page、internal page 和 leaf page。
以下是 B+ 树的结构示意图:
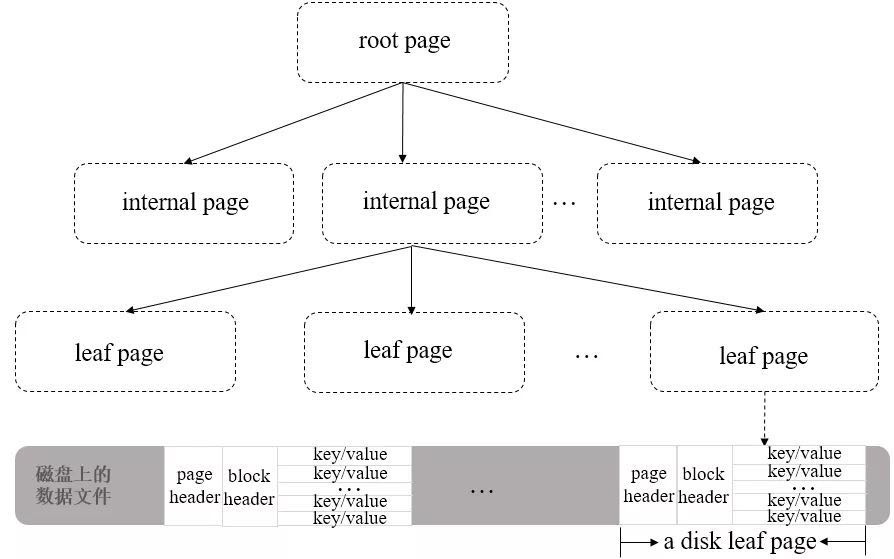
- root page 是 B+ 树的根节点。
- internal page 是不实际存储数据的中间索引节点。
- leaf page 是真正存储数据的叶子节点,包含页头(page header)、块头(block header)和真正的数据(key-value 对)。
MongoDB 的高可用架构
我们从 Mongo 的三种高可用模式逐一介绍,这三种模式也代表了通用分布式系统下高可用架构的进化史,分别是 Master-Slave,Replica Set,Sharding 模式。
1、Master-Slave 主从模式
Master-Slave 模式角色
Mongodb 提供的第一种冗余策略就是 Master-Slave 策略,这个也是分布式系统最开始的冗余策略,这种是一种热备策略。
Master-Slave 架构一般用于备份或者做读写分离,一般是一主一从设计和一主多从设计。
Master-Slave 由主从角色构成:
Master ( 主 )
可读可写,当数据有修改的时候,会将 Oplog 同步到所有连接的Salve 上去。
Slave ( 从 )
只读,所有的 Slave 从 Master 同步数据,从节点与从节点之间不感知。
如图:
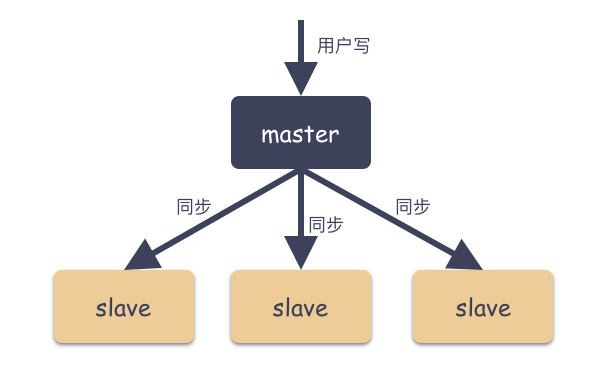
通过上面的图,这是一种典型的扇形结构。
Master-Slave 优缺点
优点:
- 读写分离,分摊主节点压力。Master 对外提供读写服务,有多个 Slave 节点的话,可以用 Slave 节点来提供读服务的节点。
缺点:
- 可用性差。
- Master-Slave 只区分两种角色:Master 节点,Slave 节点;且用户只能写 Master 节点,Slave 节点只能从 Master 拉数据;
- Master-Slave 的角色是静态配置的,不能自动切换角色,必须人为指定;
- 还有一个关键点:Slave 节点只和 Master 通信,Slave 之间相互不感知。
Master-Slave 的现状
MongoDB 3.6 起已不推荐使用主从模式,自 MongoDB 3.2 起,分片群集组件已弃用主从复制。因为 Master-Slave 其中 Master 宕机后不能自动恢复,只能靠人为操作,可靠性也差,操作不当就存在丢数据的风险。
怎么搭建 Master-Slave 模式?
启动 Master 节点:
mongod --master --dbpath /data/masterdb/
关键参数:
--master:指定为 Master 角色;
启动 Slave 节点:
mongod --slave --source <masterhostname><:<port>> --dbpath /data/slavedb/
关键参数:
--slave:指定为 Slave 角色;--source:指定数据的复制来源,也就是 Master 的地址;
2、Replica Set 副本集模式
Replica Set 模式角色
MongoDB 的复制集又称为副本集(Replica Set),是一组维护相同数据集合的 mongod 进程。
Primary( 主节点 )
只有 Primary 是可读可写的,Primary 接收所有的写请求,然后把数据同步到所有 Secondary 。一个 Replica Set 只有一个 Primary 节点,当 Primary 挂掉后,其他 Secondary 或者 Arbiter 节点会重新选举出来一个 Primary 节点,这样就又可以提供服务了。
读请求默认是发到 Primary 节点处理,如果需要故意转发到 Secondary 需要客户端修改一下配置(注意:是客户端配置,决策权在客户端)。
Secondary( 副本节点 )
通过复制主节点的操作来维护一个相同的数据集。数据副本节点,当主节点挂掉的时候,可以参与选主。
从节点有几个选配项:
- v 参数决定是否具有投票权;
- priority 参数决定节点选主过程时的优先级;
- hidden 参数决定是否对客户端可见;配置为隐藏复制集后,能防止应用程序从它读取数据,适用于在该节点上运行需要与正常流量分离的程序;
- slaveDelay 参数表示复制 n 秒之前的数据,保持与主节点的时间差。这样的配置可以保持一个历史快照,以便做按特定时间的故障恢复
- 从节点可以配置成 0 优先级,阻止它在选举中成为主节点,适用于将该节点部署在备用数据中心,或者将它作为一个冷节点;
Arbiter( 仲裁者 )
MongoDB 支持一种特殊类型的成员,成为仲裁者。
仲裁者并不保存数据,也不会为客户端提供服务:他只是为了帮助具有 两个成员的副本集能够满足“大多数”这个条件。使用 Arbiter 既可以减轻数据的冗余备份,又能提供高可用的能力。
如下图:
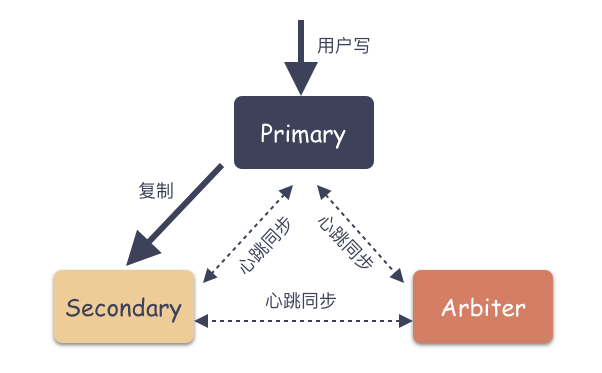
思考一个问题:Secondary 和 Master-Slave 模式的 Slave 角色有什么区别?
最根本的不同在于:
- Secondary 相互有心跳,Slave 之间没有心跳感知
- Secondary 可以作为复制源,其他从节点也可从当前副本节点复制数据。Slave 只能从主节点复制数据。
副本集选主
当一个备份节点无法与主节点连通时,它就会联系并请求其他的副本集成员将自己选举为主节点。其他成员会做几项理性的检查:
- 自身是否能够与主节点连通?
- 希望被选举为主节点的备份节点的数据是否最新?
- 有没有其他更高优先级的成员可以被选举为主节点?
如果要求被选举为主节点的成员能够得到副本集中“大多数”成员的投票,它就会成为主节点。即使“大多数”成员中只有一个否决了本次选举,选举就会取消。如果成员发现任何原因,表明当前希望成为主节点的成员不应该成为主节点,那么它就会否决此次选举。
在日志中可以看到得票数为比较大的负数的情况,因为一张否决票相当于10000张赞成票。如果某个成员投赞成票,另一个成员投否决票,那么就可以在消息中看到选举结果为-9999或者是比较相近的负数值。如果有两个成员投了否决票,一个成员投了赞成票,那么选举结果就是-19999,依次类推。
Wed Jun 20 17:44:02 [rsMgr] replSet info electSelf 1Wed Jun 20 17:44:02 [rsMgr] replSet couldn't elect self, only received -9999 votes
希望成为主节点的成员(候选人)必须使用复制将自己的数据更新为最新,副本集中的其他成员会对此进行检查。复制操作是严格按照时间排序的,所以候选人的最后一条操作要比它能连通的其他所有成员更晚(或者与其他成员相等)。
假设候选人执行的最后一个复制操作是123。它能连通的其他成员中有一个的最后复制操作是124,那么这个成员就会否决候选人的选举。这时候选人会继续进行数据同步,等它同步到124时,它会重新请求选举(如果那时整个副本集中仍然没有主节点的话)。在新一轮的选举中,假如候选人没有其他不合规之处,之前否决它的成员就会为它投赞成票。
假如候选人得到了“大多数”的赞成票,它就会成为主节点。
还有一点需要注意:每个成员都只能要求自己被选举为主节点。不能推荐其他成员被选举为主节点,只能为申请成为主节点的候选人投票。
复制集中最多可以有 50 个节点,但具有投票权的节点最多 7 个。
副本集模式特点
MongoDB 的 Replica Set 副本集模式主要有以下几个特点:
- 数据多副本,在故障的时候,可以使用完整的副本恢复服务。注意:这里是故障自动恢复;
- 读写分离,读的请求分流到副本上,减轻主(Primary)的读压力;
- 节点直接互有心跳,可以感知集群的整体状态;
副本集优缺点
优点:可用性大大增强
- 主节点发生故障时自动选举出一个新的主节点,以实现故障转移。
- 将数据从一个数据中心复制到另一个数据中心,减少另一个数据中心的读延迟。
- 实现读写分离。
- 实现容灾,可以在数据中心故障时快速切换到同城或异地的数据中心。
缺点:每两个节点之间互有心跳,这种模式会导致节点的心跳几何倍数增大,单个 Replica Set 集群规模不能太大,一般来讲最大不要超过 50 个节点。
3、Sharding 分片模式
MongoDB 的 Sharding 模式是 MongoDB 横向扩容的一个架构实现。是指将数据拆分,将其分散存放在不同的机器上的过程。MongoDB支持自动分片,可以使数据库架构对应用程序不可见,也可以简化系统管理。对应用程序而言,好像始终在使用一个单机的MongoDB服务器一样。
Sharding 模式角色
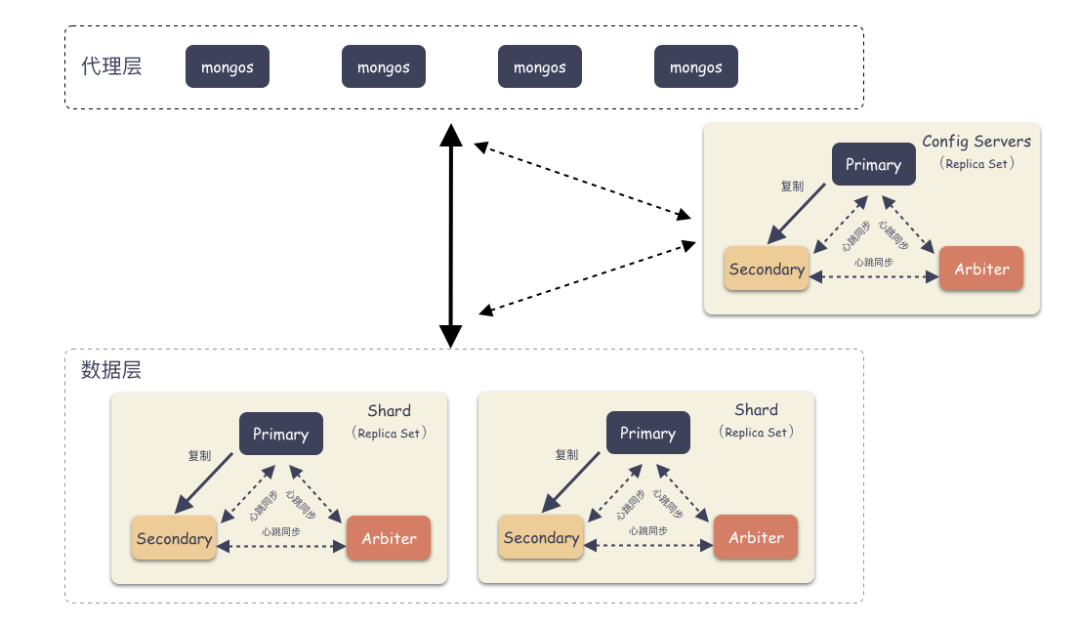
Sharding 模式下按照层次划分可以分为 3 个大模块:
- 代理层:mongos
- 配置中心:副本集群(mongod)
- 数据层:Shard 集群
简要如下图:
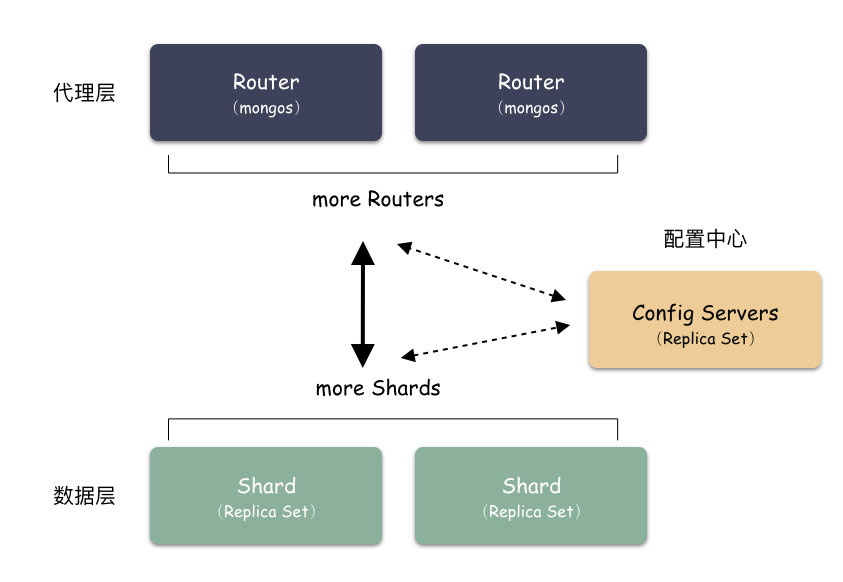
代理层:
代理层的组件也就是 mongos ,这是个无状态的组件,纯粹是路由功能。向上对接 Client ,收到 Client 写请求的时候,按照特定算法均衡散列到某一个 Shard 集群,然后数据就写到 Shard 集群了。收到读请求的时候,定位找到这个要读的对象在哪个 Shard 上,就把请求转发到这个 Shard 上,就能读到数据了。
数据层:
数据层是啥?就是存储数据的地方。你会惊奇的发现,其实数据层就是由一个个 Replica Set 集群组成。在前面我们说过,单个 Replica Set 是有极限的,怎么办?那就搞多个 Replica Set ,这样的一个 Replica Set 我们就叫做 Shard 。理论上,Replica Set 的集群的个数是可以无限增长的。
配置中心:
代理层是无状态的模块,数据层的每一个 Shard 是各自独立的,那总要有一个集群统配管理的地方,这个地方就是配置中心。里面记录的是什么呢?
比如:有多少个 Shard,每个 Shard 集群又是由哪些节点组成的。每个 Shard 里大概存储了多少数据量(以便做均衡)。这些东西就是在配置中心的。
配置中心存储的就是集群拓扑,管理的配置信息。这些信息也非常重要,所以也不能单点存储,怎么办?配置中心也是一个 Replica Set 集群,数据也是多副本的。
详细架构图:
Sharding 模式怎么存储数据?
我们说过,纵向优化是对硬件使用者最友好的,横向优化则对硬件使用者提出了更高的要求,也就是说软件架构要适配。
单 Shard 集群是有限的,但 Shard 数量是无限的,Mongo 理论上能够提供近乎无限的空间,能够不断的横向扩容。那么现在唯一要解决的就是怎么去把用户数据存到这些 Shard 里?MongDB 是怎么做的?
首先,要选一个字段(或者多个字段组合也可以)用来做 Key,这个 Key 可以是你任意指定的一个字段。我们现在就是要使用这个 Key 来,通过某种策略算出发往哪个 Shard 上。这个策略叫做:Sharding Strategy ,也就是分片策略。
我们把 Sharding Key 作为输入,按照特点的 Sharding Strategy 计算出一个值,值的集合形成了一个值域,我们按照固定步长去切分这个值域,每一个片叫做 Chunk ,每个 Chunk 出生的时候就和某个 Shard 绑定起来,这个绑定关系存储在配置中心里。
所以,我们看到 MongoDB 的用 Chunk 再做了一层抽象层,隔离了用户数据和 Shard 的位置,用户数据先按照分片策略算出落在哪个 Chunk 上,由于 Chunk 某一时刻只属于某一个 Shard,所以自然就知道用户数据存到哪个 Shard 了。
Sharding 模式下数据写入过程:
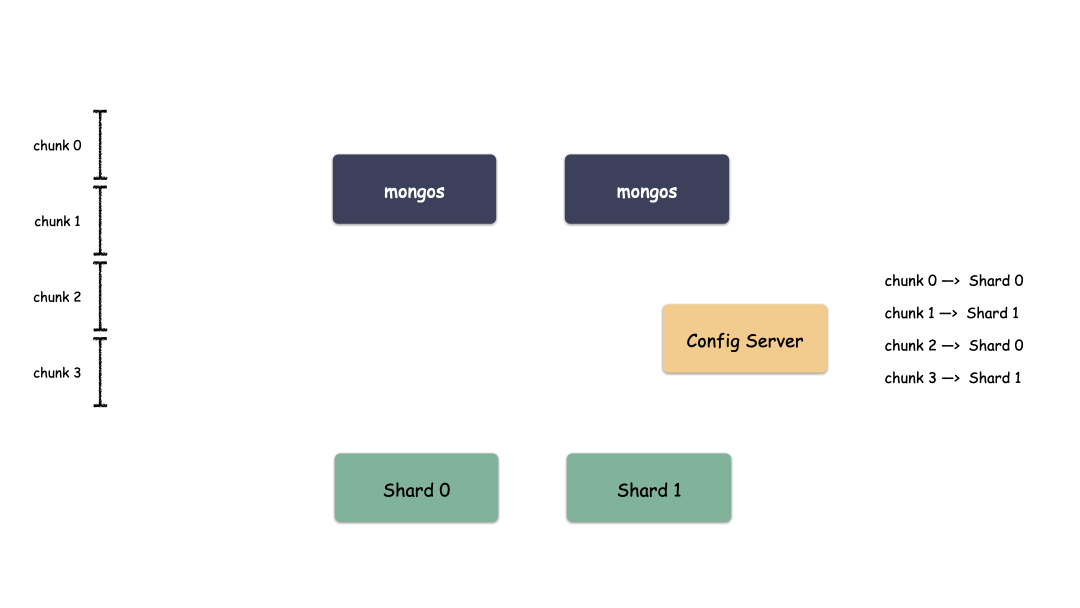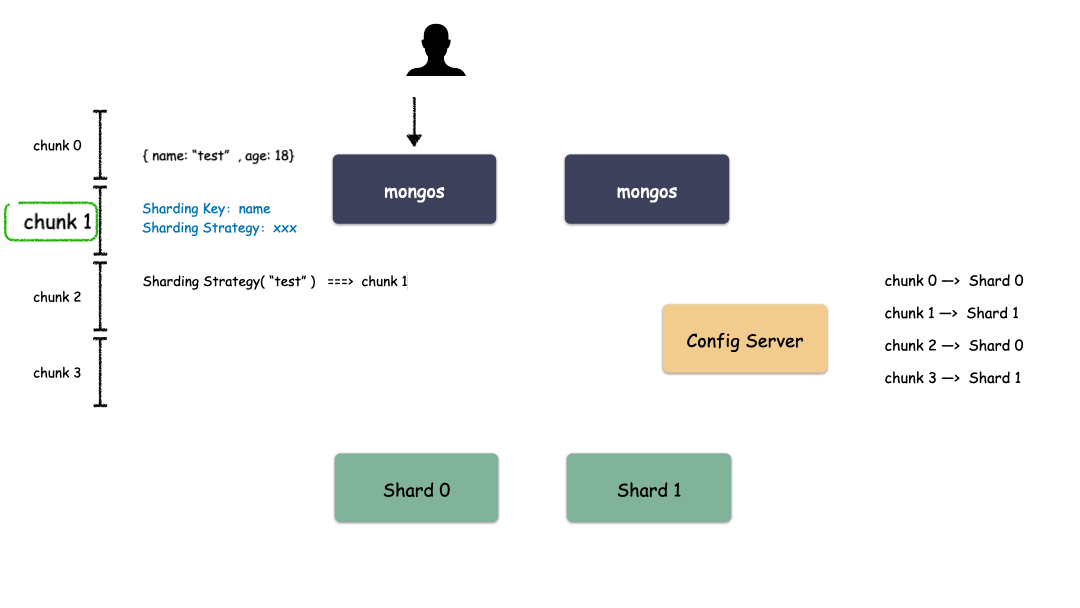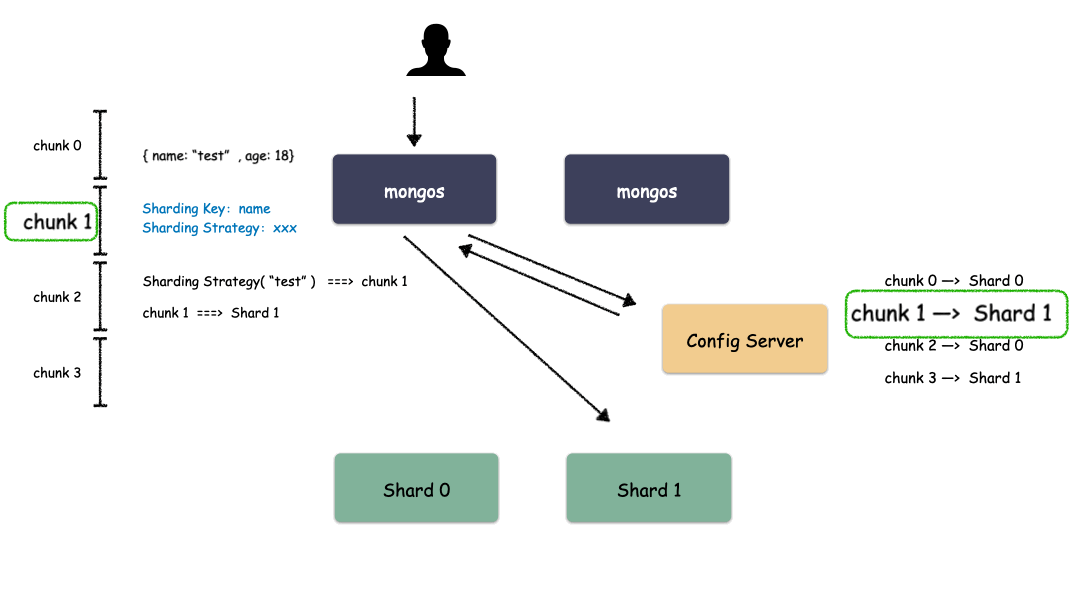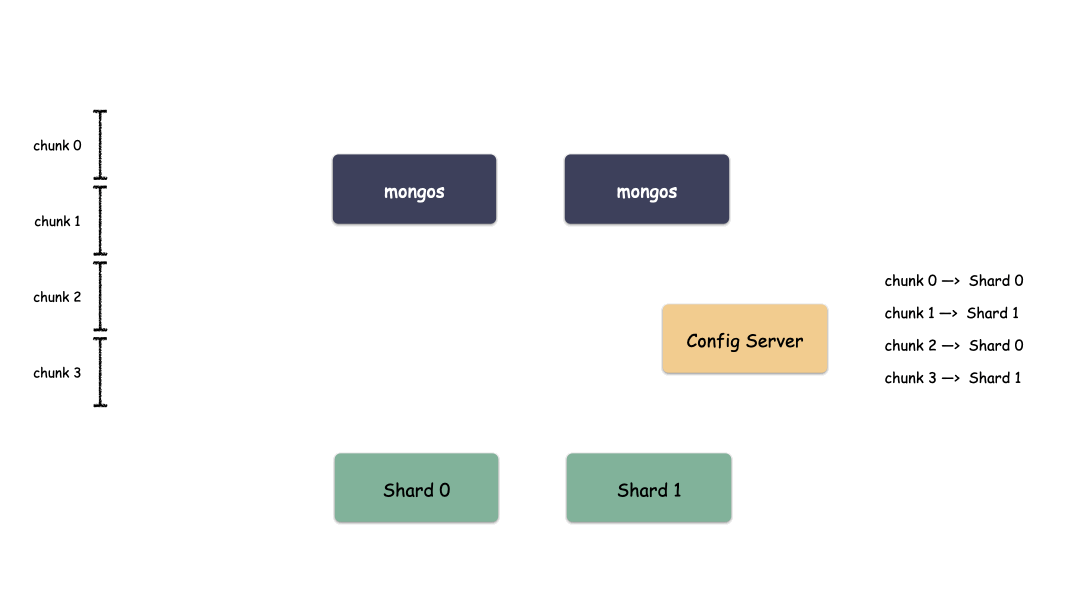
通过上图我们也看出来了,mongos 作为路由模块其实就是寻路的组件,写的时候先算出用户 key 属于哪个 Chunk,然后找出这个 Chunk 属于哪个 Shard,最后把请求发给这个 Shard ,就能把数据写下去。
Sharding 模式下数据读取过程:

读的时候也是类似,先算出用户 key 属于哪个 Chunk,然后找出这个 Chunk 属于哪个 Shard,最后把请求发给这个 Shard ,就能把数据读上来。
实际情况下,mongos 不需要每次都和 Config Server 交互,大部分情况下只需要把 Chunk 的映射表 cache 一份在 mongos 的内存,就能减少一次网络交互,提高性能。
讲回 Sharding Strategy 分片策略是什么?本质上 Sharding Strategy 是形成值域的策略而已
MongoDB 支持两种 Sharding Strategy:
- Hashed Sharding 的方式
- Range Sharding 的方式
Hashed Sharding
把 Key 作为输入,输入到一个 Hash 函数中,计算出一个整数值,值的集合形成了一个值域,我们按照固定步长去切分这个值域,每一个片叫做 Chunk ,这里的 Chunk 则就是整数的一段范围而已。
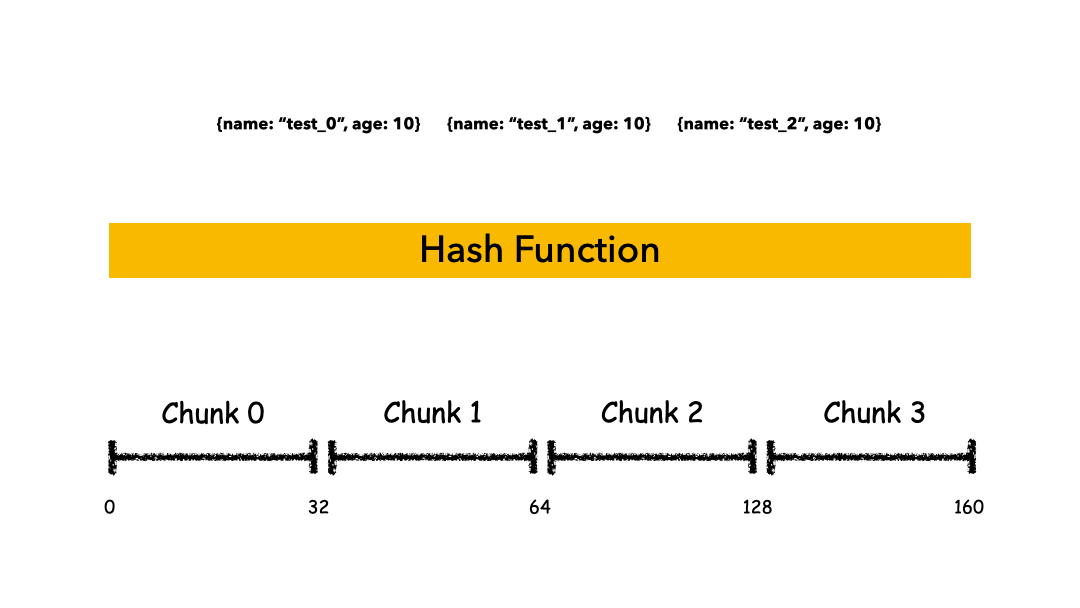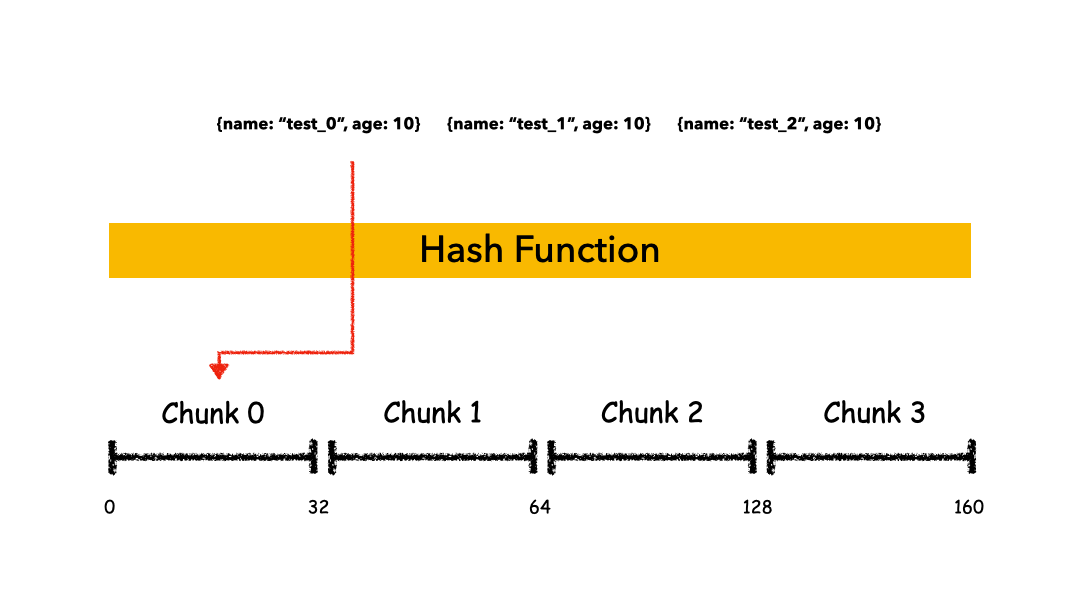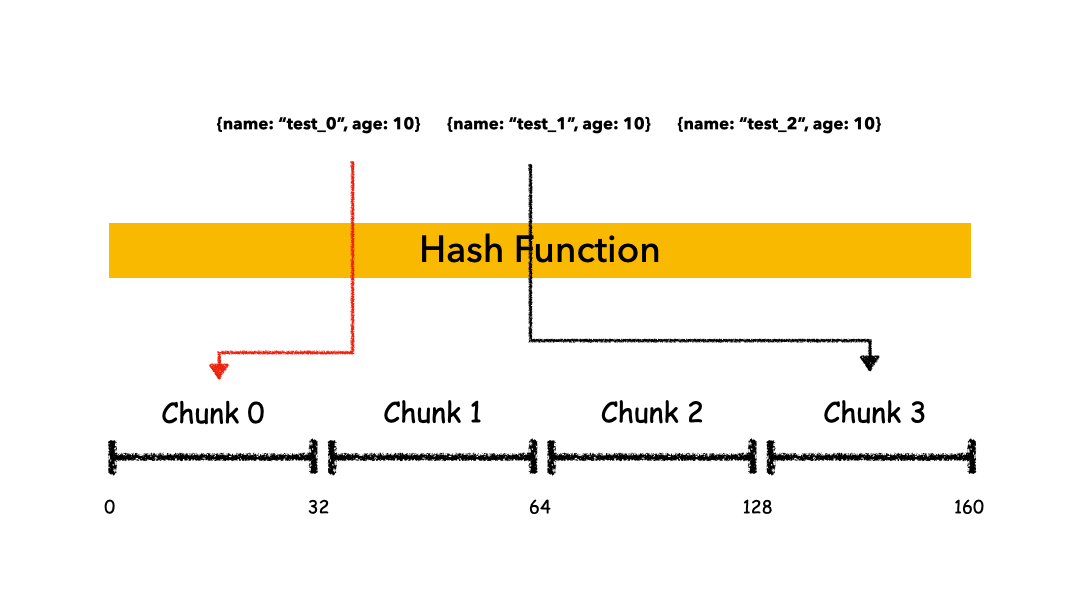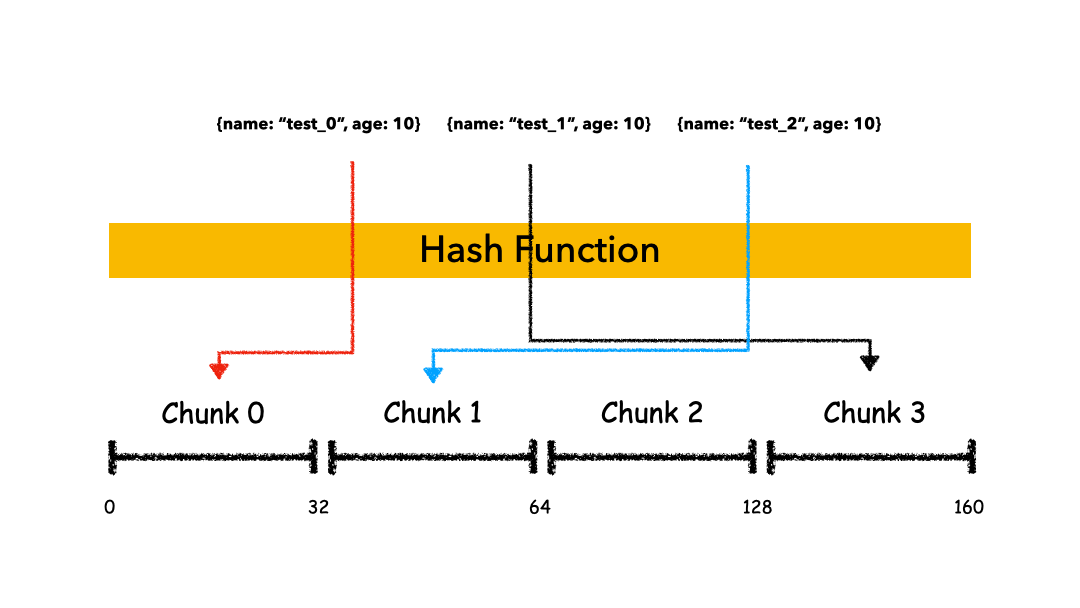
这种计算值域的方式有什么优缺点呢?
好处是:
- 计算速度快
- 均衡性好,纯随机
坏处是:
- 正因为纯随机,排序列举的性能极差,比如你如果按照 name 这个字段去列举数据,你会发现几乎所有的 Shard 都要参与进来;
Range Sharding
Range 的方式本质上是直接用 Key 本身来做值,形成的 Key Space 。
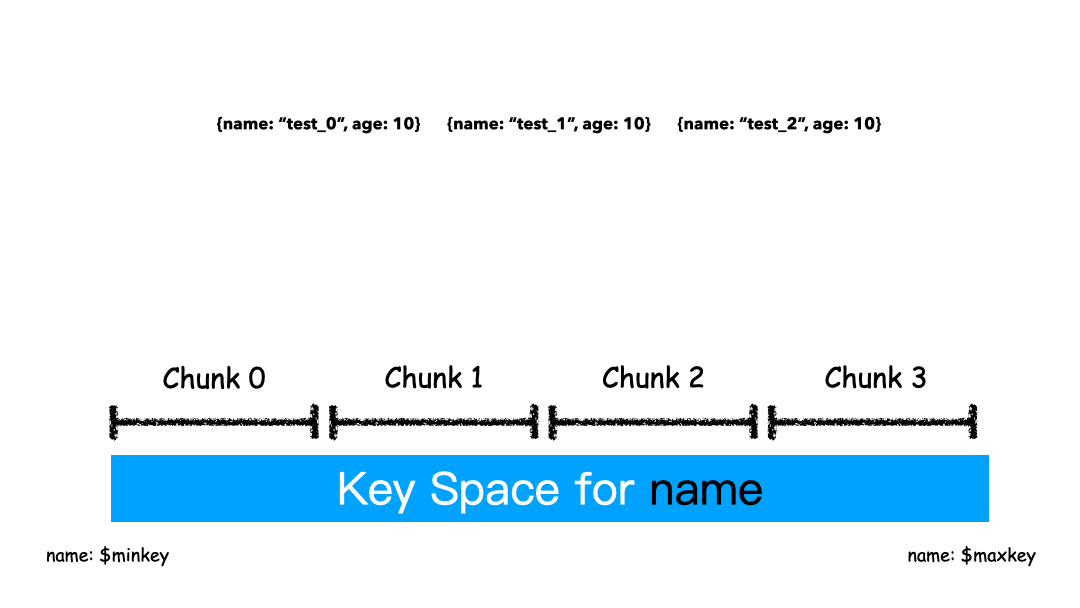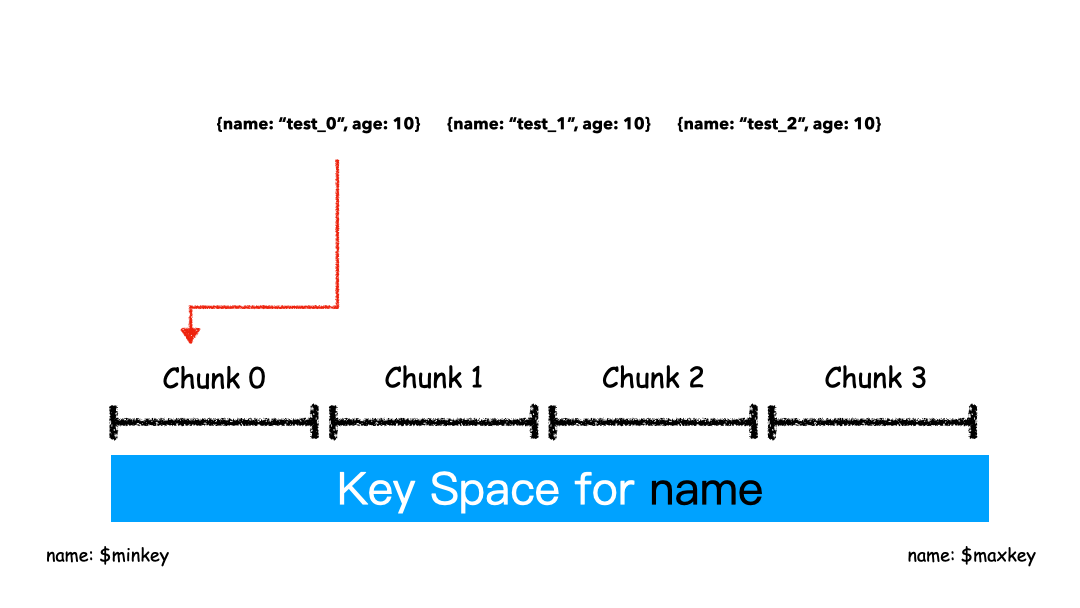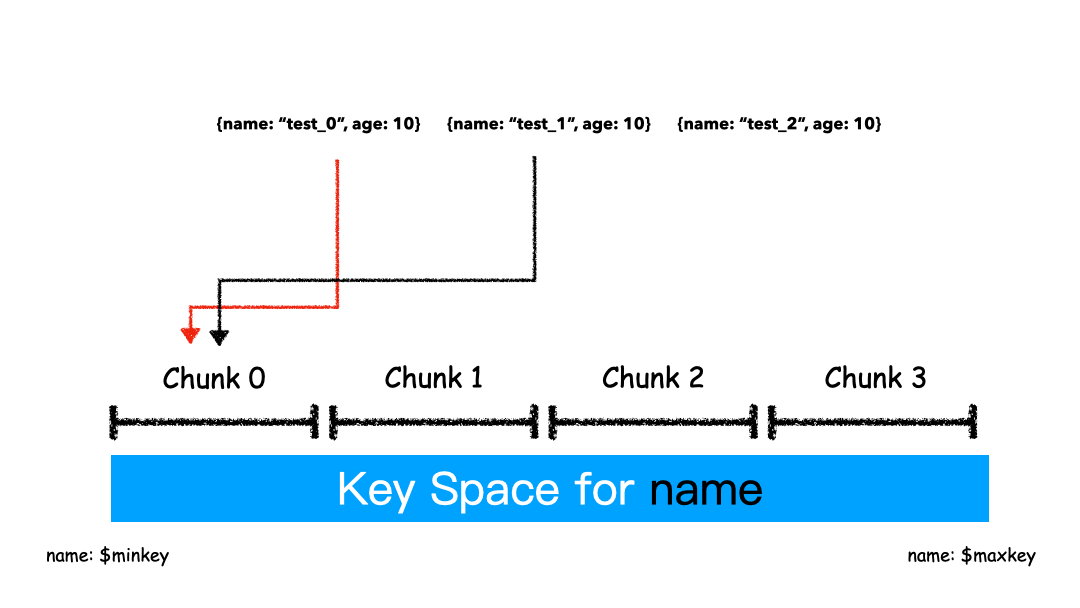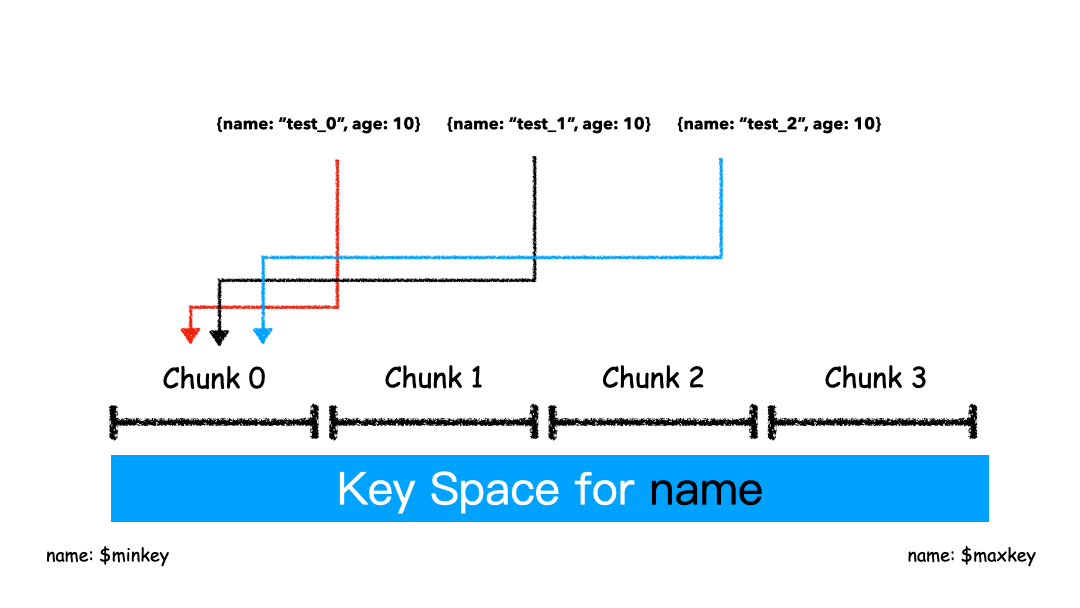
如上图例子,Sharding Key 选为 name 这个字段,对于 “test_0”,”test_1”,”test_2” 这样的 key 排序就是挨着的,所以就全都分配在一个 Chunk 里。
这 3 条 Docuement 大概率是在一个 Chunk 上,因为我们就是按照 Name 来排序的。这种方式有什么优缺点?
好处是:
- 对排序列举场景非常友好,因为数据本来就是按照顺序依次放在 Shard 上的,排序列举的时候,顺序读即可,非常快速;
坏处是:
- 容易导致热点,举个例子,如果 Sharding Key 都有相同前缀,那么大概率会分配到同一个 Shard 上,就盯着这个 Shard 写,其他 Shard 空闲的很,却帮不上忙;
可用性的进一步提升
为什么说 Sharding 模式不仅是容量问题得到解决,可用性也进一步提升?
因为 Shard(Replica Set)集群个数多了,即使一个或多个 Shard 不可用,Mongo 集群对外仍可以 提供读取和写入服务。因为每一个 Shard 都有一个 Primary 节点,都可以提供写服务,可用性进一步提升。
4、如何使用
上面已经介绍了历史演进的 3 种高可用模式,Master-Slave 模式已经在不推荐了,Relicate Set 和 Sharding 模式都可以保证数据的高可靠和高可用,但是在我们实践过程中,发现客户端存在非常大的配置权限,也就是说如果用户在使用 MongoDB 的时候使用姿势不对,可能会导致达不到你的预期。
使用姿势一:怎么保证高可用?
如果是 Replicate Set 模式,那么客户端要主动感知主从切换。以前用过 Go 语言某个版本的 MongoDB client SDK,发现在主从切换的时候,并没有主动感知,导致请求还一直发到已经故障的节点,从而导致服务不可用。
所以针对这种形式要怎么做?有两个方案:
- 用 Sharding 模式,因为 Sharding 模式下,用户打交道的是 mongos ,这个是一个代理,帮你屏蔽了底层 Replica Set 的细节,主从切换由它帮你做好;
- 客户端自己感知,定期刷新(这种就相对麻烦);
使用姿势二:怎么保证数据的高可靠?
客户端配置写多数成功才算成功。没错,这个权限交由由客户端配置。如果没有配置写多数成功,那么很可能写一份数据成功就成功了,这个时候如果发生故障,或者切主,那么数据可能丢失或者被主节点 rollback ,也等同用户数据丢失。
mongodb 有完善的 rollback 及写入策略(WriteConcern)机制,但是也要使用得当。怎么保证高可靠?一定要写多数成功才算成功。
使用姿势三:怎么保证数据的强一致性?
客户端要配置两个东西:
- 写多数成功,才算成功;
- 读使用 strong 模式,也就是只从主节点读;
只有这两个配置一起上,才能保证用户数据的绝对安全,并且对外提供数据的强一致性。

若有收获,就点个赞吧
0 人点赞
