1. 作者简介
Mounica Maddela, Wei Xu1, Daniel Preot¸iuc-Pietro
Department of Computer Science and Engineering, The Ohio State University
2. 文献类型
ACL 2019
3. 存在问题
标签分割精度太低,对于标签的分割不能分割成一个有意义的单词序列
4. 主要工作
- 标签分割精度降低了24.6%的误差
- 利用新的神经方法将问题划分为两两排序,与以往忽略相对顺序的工作形成对比;
- 一种多任务学习方法,它使用不同的特性集来处理不同类型的标签;
- 建立了一个新的数据集,所有的工作都在这个数据集上完成
5. 方法概述
这部分写论文的实现方法,网络结构图
- .当前最新的方法是使用最大熵和CRF模型,采用语言模型和手工制作的特征相结合,以预测每个字符是否在标签中是一个新词的开头。
- 它使用一种波束搜索算法提取k个最佳分段,按n—gram语言模型概率排序:

- 其中[W1,w2]….W]是切分s的单词序列,N是窗口的大小。
- 不足之处:在以往的工作中,每个分段的排名分数都是独立计算的,忽略了前k个候选分段之间的相对顺序。为了解决这一限制,我们利用提出了一种新的两两排序策略,并提出了该任务的第一个神经模型。
改进的方法,也就是本文所提出来的方法:提出了一种多任务成对神经排序方法,以更好地融合和区分给定标签的候选片段之间的相对顺序。 举个例子:关于排序的问题

- 评估函数:Levenshtein距离
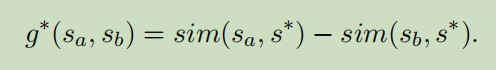
2.两两神经排序模型
训练过程:对于输入候选对sa,sb,我们将它们的特征向量SA和SB连接起来,并将它们送入生成器g(sa,sb)的前馈网络中。特征向量sa或sb由语言组成。模型概率使用良好图灵和修正的Kneser-Ney平滑,词汇和语言特征用于生成器g,我们以所有可能的对hsa,SBI的k候选作为输入,他们的“金”分数g∗(sa,sb)作为目标。培训的目标是最小化均方误差(MSE):
网络体系结构:
6. 实验
数据集:
构建了一个由12,594个散列标签组成的数据集
实验结果:
7. 下一步工作
这部分写论文的自身缺点/下一步工作
- 我们的模型通过实例级的选择性注意,将多实例学习与神经网络结合起来。它不仅可以用于远程监督关系的提取,还可以用于其他多实例学习任务。我们将在其他领域探索我们的模型,例如文本分类。
- CNN是神经关系提取的有效神经网络之一。研究人员还提出了许多其他的神经网络模型来进行关联提取。在未来,我们将把我们的实例级选择性注意技术与这些模型进行关联提取。
8. 原文及源码
这部分写论文的原文链接和开源代码链接

若有收获,就点个赞吧
0 人点赞
