1. 作者简介
Tong Guo1 Huilin Gao2
China Electronic Technology Group Corporation Information Science Academy,
Beijing, China
2. 文献类型
#
3. 主要工作
- 使用所有表格单元格的匹配信息和问题字符串来标记问题,并生成与问题长度相同的特征向量;
使用所有表列名称和问题字符串的match inf来标记列,并生成与表头长度相同的特指向量。
4. 方法概述
外部向量编码分为两步:问题特征向量和表头特征向量
- 算法1为问句向量的构造;
- 值1代表“开始”标签;
- 值2代表“中间”标签;
值3代表“结束”标签;
<br /> e. 算法2表头向量的构造(包含匹配单元格的列应该被标记)<br /> 
基于wikiSQL数据集,使用三个子模型来预测SELECT part、AGG part和WHERE part。模型图如下
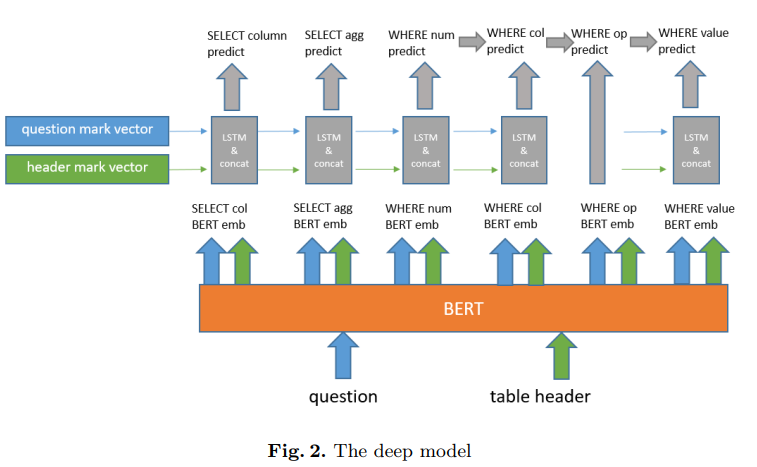
a. 问题和表头连接在一起作为bert的输入;
b. 将问题和表头的输出标记为Q和H;
c. bert层中:
问题列为 w1,w2,w3…wn;
表头为h1,h2,h3…hn;
即encoding [CLS]; w1; w2; :::; wn; [SEP]; h1; [SEP]; h2; [SEP]; :::; hn; [SEP]
d. SELECT column:
目标是预测表标题中的列名,输出的选择的列的可能性为计算公式1: (1)
(1)
其中QV,HV为外部特征表述向量
e. SELECT agg:
目标是预测AGG槽,输入为Q/QV,输出为计算公式2: (2)
(2)
f. WHERE number:
目标是预测数量槽,输入为Q/H/QV/HV,输出为计算公式3: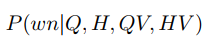 (3)
(3)
g. WHERE column:
目标是预测每个where条件子句中的列槽,输出为公式4: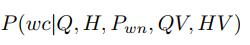 (4)
(4)
h. WHERE op:
目标是预测每个where条件子句中的列槽,输出为公式5: (5)
(5)
j. WHERE value:
目标是预测每个where条件子句中的列槽,输出为公式6: (6)
(6)
5. 实验
数据集: wikiSQL
实验结果:表头向量主要改善WHERE OP的结果,问题向量主要改善WHERE VALUE的结果。
6. 原文及源码

若有收获,就点个赞吧
0 人点赞
