语义解析(Semantic Parsing)是自然语言处理技术的核心任务之一,涉及语言学、计算语言学、机器学习以及认知语言等多个学科,在近几年中获得了广泛关注,语义解析任务有助于促进机器语言理解的快速发展。
本文重点介绍语义解析技术中的Text-to-SQL任务,让机器自动将用户输入的自然语言问题转成数据库可操作的SQL查询语句,实现基于数据库的自动问答能力。
任务介绍及研究动机
当前,大量信息存储在结构化和半结构化知识库中,如数据库。对于这类数据的分析和获取需要通过SQL等编程语言与数据库进行交互操作,SQL的使用难度限制了非技术用户,给数据分析和使用带来了较高的门槛。人们迫切需要技术或工具完成自然语言与数据库的交互,因此诞生了Text-to-SQL任务。
我们通过图1中的实例来介绍一下Text-to-SQL任务。该任务包含两部分:Text-to-SQL解析器和SQL执行器。
解析器的输入是给定的数据库和针对该数据库的问题,输出是问题对应的SQL查询语句,如图中红色箭头标示。SQL执行器在数据库上完成该查询语句的执行,及给出问题的最终答案,如图中绿色箭头标示。
SQL执行器有很多成熟的系统,如MySQL,SQLite等,该部分不是本文重点。本文主要介绍解析器,学术界中Text-to-SQL任务默认为Text-to-SQL解析模型。
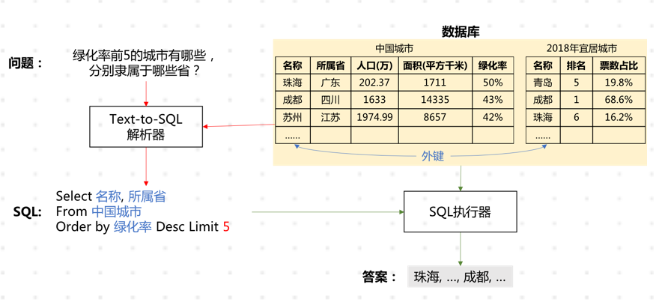
首先,我们介绍一下术语“数据库”和“SQL查询语句”:
1、数据库由一张或多张表格构成,表格之间的关系通过外键给出。在该实例中,数据库由表 “中国城市”和“2018年宜居城市” 构成,两张表通过外键:“中国城市”的“名称”列和“2018年宜居城市”的“名称”列关联;
2、SQL是数据库查询语言,其构成来自3部分:数据库(如实例SQL查询语句中蓝色标注的成分)、问题(如实例SQL查询语句红色标注的成分)、SQL关键词(如实例SQL查询语句中的Select、From、Where等)。
其次,我们介绍一下Text-to-SQL解析模型。根据SQL的构成,解析器需要完成两个任务,即“问题与数据库的映射”和“SQL生成”。
在问题与数据库的映射中,需要找出问题依赖的表格以及具体的列,如图1实例中,问题“绿化率前5的城市有哪些,分别隶属于哪些省?”依赖的数据库内容包括:表格“中国城市”,具体的列“名称”、“所属省”、“绿化率”(SQL查询语句蓝色标注成分)。
在SQL生成中,结合第一步识别结果以及问题包含信息,生成满足语法的SQL查询语句,如实例中的“Select 名称,所属省 From 中国城市 Where 绿化率 > 30%”。
Text-to-SQL研究进展
Text-to-SQL技术能够有效地辅助人们对海量的数据库进行查询,因其有实用的应用场景,引起了学术界和工业界的广泛关注。我们接下来将从相关数据集和模型两方面介绍该技术的研究进展。
1、数据集介绍
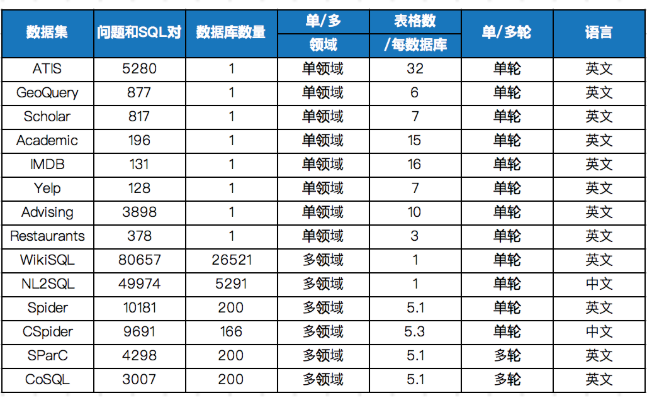
下图给出了Text-to-SQL数据集发展趋势,代表数据集参见表1。
其中术语介绍:
- 根据包含领域数量,数据集分为单领域和多领域。
- 根据每个数据库包含表的数量,数据集分为单表和多表模式。在多表模式中,SQL生成涉及到表格的选择。
- 根据问题复杂度,数据集分为简单问题和复杂问题模式,其中问题复杂度由SQL查询语句涉及到的关键词数量、嵌套层次、子句数量等确定。
- 根据完整SQL生成所需轮数,数据集分为单轮和多轮。
若SQL生成融进渐进式对话,则数据集增加“结合对话”标记。当前只有CoSQL数据集是融进对话的数据集。
<br />**2、模型介绍**<br />SQL查询语句是一个符合语法、有逻辑结构的序列,其构成来自三部分:**数据库、问题、SQL关键词**。
在当前深度学习研究背景下,Text-to-SQL任务可被看作是一个类似于神经机器翻译的序列到序列的生成任务,主要采用Seq2Seq模型框架。基线Seq2Seq模型加入注意力、拷贝等机制后,在单领域数据集上可以达到80%以上的准确率,但在多领域数据集上效果很差,准确率均低于25%。
从编码和解码两个方面进行原因分析。**
在编码阶段,问题与数据库之间需要形成很好的对齐或映射关系,即问题中涉及了哪些表格中的哪些元素(包含列名和表格元素值);同时,问题与SQL语法也需要进行映射,即问题中词语触发了哪些关键词操作(如Group、Order、Select、Where等)、聚合操作(如Min、Max、Count等)等;最后,问题表达的逻辑结构需要表示并反馈到生成的SQL查询语句上,逻辑结构包括嵌套、多子句等。
**
在解码阶段,SQL语言是一种有逻辑结构的语言,需要保证其语法合理性和可执行性。普通的Seq2Seq框架并不具备建模这些信息的能力。
当前基于Seq2Seq框架,主要有以下几种改进。
1)基于Pointer Network的改进
首先,SQL组成来自三部分:数据库中元素(如表名、列名、表格元素值)、问题中词汇、 SQL关键字。其次,当前公开的多领域数据集为了验证模型数据库无关,在划分训练集和测试集时要求数据库无交叉,这种划分方式导致测试集数据库中很大比例的元素属于未登录词。传统的Seq2Seq模型是解决不好这类问题的。
Pointer Network很好地解决了这一问题,其输出所用到的词表是随输入而变化的。具体做法是利用注意力机制,直接从输入序列中选取单词作为输出。在Text-to-SQL任务中,将问题中词汇、SQL关键词、对应数据库的所有元素作为输入序列,利用Pointer Network从输入序列中拷贝单词作为最终生成SQL的组成元素。
由于Pointer Network可以较好的满足具体数据库无关这一要求,在多领域数据集上的模型大多使用该网络,如Seq2SQL[1]、STAMP[8]、Coarse2Fine[9] 、IRNet[16]等模型。
2)基于Sequence-to-set的改进
在简单问题对应的数据集合上,其SQL查询语句形式简单(仅包含Select和Where关键词),为了解决Seq2Seq模型中顺序错误带来的影响(如“条件1 And 条件2”,预测为“条件2 And 条件1”,属于顺序错误,但对应的SQL是正确的),SQLNet[10]提出了Sequence-to-set模型,基于所有的列预测其属于哪个关键词(即属于Select还是Where,在SQLNet模型中仅预测是否属于Where),针对SQL 中每一个关键词选择概率最高的前K个列。
该模式适用于SQL形式简单的数据集,在WikiSQL和NL2SQL这两个数据集合上使用较多,且衍生出很多相关模型,如TypeSQL[11]、SQLova[12]、X-SQL[13]等。
3、评价方法
Text-to-SQL任务的评价方法主要包含两种:精确匹配率(Exact Match, Accqm)、执行正确率(Execution Accuracy, Accex)。
精确匹配率指,预测得到的SQL语句与标准SQL语句精确匹配成功的问题占比。为了处理由成分顺序带来的匹配错误,当前精确匹配评估将预测的SQL语句和标准SQL语句按着SQL关键词分成多个子句,每个子句中的成分表示为集合,当两个子句对应的集合相同则两个子句相同,当两个SQL所有子句相同则两个SQL精确匹配成功;
执行正确指,执行预测的SQL语句,数据库返回正确答案的问题占比。
目前仅WikiSQL数据集支持Accex,其他数据集仅支持Accqm。大部分数据集发布了对应的评估脚本,方便大家在同一个评估标准下进行算法研究。
参考:**https://mp.weixin.qq.com/s/FtsA4O_VTUqhhYS3Gq3G8Q
当前百度的研究
- 构建数据集DuSQL和模型DuParer的构建
百度从实际应用中随机抽取用户问题,就问题解决所需要的操作对问题类型进行了人工分析,结果如表2所示,可以看出涉及到计算、排序、比较等操作的问题有一定的占比。
为了更好的理解,列举了一些问题类型及对应的问题实例:
- 数据集的构建:
数据集构建主要分为两大步骤:数据库构建和<问题,SQL查询语句>构建。在数据库构建中,要保证数据库覆盖的领域足够广泛,在<问题, SQL查询语句>构建中,要保证覆盖实际应用中常见的问题类型。
数据库主要来自百科(包括三元组数据和百科页面中的表格)、权威网站(如国家统计局、天眼查、中国产业信息网、中关村在线等)、各行业年度报告以及论坛(如贴吧)等。
从这些网站挖掘到表格后,我们按表格的表头对同类表格进行了聚类,并根据表格中的实体链接等信息构建表格之间的关联,最终保留了813张表格,分为200个数据库。由于很多表格的内容较敏感,我们仅使用了表格的表头,对表格内容进行了随机填充,无法保证事实性。
基于一个半自动方案构建<问题, SQL查询语句>,首先需要基于SQL文法自动生成SQL查询语句和对应的伪语言问题描述,然后通过众包方式将伪语言问题描述改写为自然语言问题。在自动生成SQL查询语句时,我们设计了覆盖所有常见问题类型的SQL规约文法,最终构建了近2.4万的数据。
表4展示了DuSQL数据集与其他多领域数据集的对比情况。其中,时间计算属于常数计算,引入常量TIME_NOW(表示当前时间),比如数据库Schema为“{公司名称, 成立年份, 员工数, …}”,问题为“XX公司成立多少年了”, SQL查询语句为“Select TIME_NOW – 成立年份 Where 公司名称=XX”。在实际应用中,常数计算中的时间计算需求较大,因此我们构建了相关数据。

若有收获,就点个赞吧
0 人点赞
