1. 作者简介
Yibo Sunx∗ , Duyu Tangz, Nan Duanz, Jianshu Ji\, Guihong Cao\,
Xiaocheng Fengx, Bing Qinx, Ting Liux Ming Zhouz
xHarbin Institute of Technology, Harbin, ChinazMicrosoft Research Asia, Beijing, China\Microsoft AI and Research, Redmond WA, USA
2. 文献类型
3. 存在问题
此方法基于指针网络的方法,该方法通过一个由问题词、列名和sql关键字组成的词序进行复制,逐字生成一个sql查询。由于问题词和列名(或单元格)之间的不匹配生成的结果中,很大一部分是不正确或不可执行的,这也反应了用户并不总是使用完全相同的列名或单元格内容来表达问题
4. 主要工作
- 提出了一个生成式语义分析器;
- 基于指针网络,将问题编码成连续的向量,并通过三个通道综合sql查询;
- 模型学习何时生成列名、单元格或sql关键字;
- 进一步合并列关系,减少格式错误

5. 方法概述
- 使用Pointer Network模型来进行建模,这个模型在解码过程中使用了“拷贝”机制,即只从SQL的关键字和问句中的单词所组成的集合中选择每个时刻生成的单词,以达到减少预测空间大小的目的。在Pointer Network模型中,在每个时刻t,decoder选择问句中第i个单词xi的概率如公式1中所示:

(1)
a. htdec代表解码器中在第t个时间步长时的隐层状态
b. hienc代表编码器中第i个单词对应的隐层状态
- 但是由于自然语言表达的多变性,问句中对表中内容的表述可能与表中的真实表述不一致。于是提出了模型(STAMP)如下图:
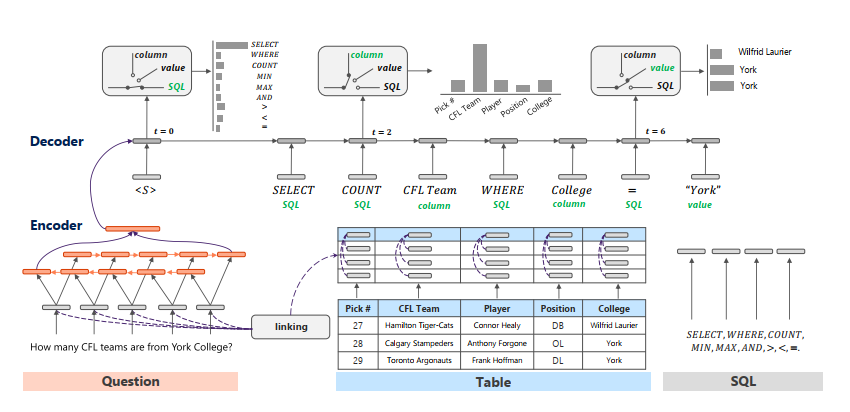
a. 这是一个序列到序列的模型,其编码器由双向的RNN组成,双向RNN的最终状态向量在首尾相连后作为解码器的初始状态。
b. 解码器则由三个通道和一个门单元组成。其中三个通道分别为Column、value、SQL通道,在每个频道中分别预测表中列名称、表中单元格名称和SQL语法关键字。三个通道中,column和value通道的候选由于由N个单词组成,所以用RNN建模,得到向量表示,而SQL通道的候选用对应的word embedding表示。在每个通道中,当前时刻生成元素的概率是由此时刻解码器RNN的状态向量和候选元素的向量表示之间通过计算相似度后归一化所得。
c. 门单元的概率输出则是直接由解码器RNN的状态向量经线性变化后经过softmax所得,其预测在每个时间节点应该选择哪个频道的预测结果作为输出。
d. 解码器在t时刻生成目标yt概率如公式2所示,其中zt代表由门单元选择的频道,pz(·)是选择频道的概率,而pw(·)类似于公式1,它是各自通道的概率输出。
 (2)
(2)
本质上每个通道都是一个注意力神经网络,对于value和SQL通道,注意力模块的输入只包含解码器的隐藏状态,计算公式如公式3

(3)
a. eisql是表示sql关键字
b. htdec是解码器的隐藏状态
- 在模型中加入了SQL语法和表结构的信息来提升性能。(主要是WHERE关键字)
a. 使用表中的单元格信息去帮助column通道的预测如公式4。将单元格的向量表示hjcell的加权求和与原列名称的向量表示hicol首尾相连,以此作为新的列名的向量表示。这个权重αjcell是由单元格中出现的单词在句子中复现的程度决定的。
(4)
b. 列名和单元格之间的关系也可以帮助value频道的预测如公式5。直观来看,要预测的单元格内容基本都出现在问句之中,所以进一步用上文中提到的由单词复现得到的权重αjcell和value通道预测的概率分布pˆwcell做一个加权求和,从而得到最终value通道道的预测概率。
(5)
6. 实验
数据集: wikisql,包含了61,297/9,145/17,284个训练/开发/测试样本。每个样本分别包含了一个问句、一张表、一个SQL表达式,以及问句在表中的答案。
实验结果:将精确度从69.0% 提升到74.4%
7. 下一步工作
8. 原文及源码

若有收获,就点个赞吧
0 人点赞
