非关系型数据库,搜索利器
Elasticsearch
https://www.jianshu.com/p/51acdca9756c
https://zhuanlan.zhihu.com/p/354761575
介绍
Elasticsearch(ES)是一个基于Lucene构建的开源、分布式、RESTful接口的全文搜索引擎。Elasticsearch还是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,ES能够横向扩展至数以百计的服务器存储以及处理PB级的数据。可以在极短的时间内存储、搜索和分析大量的数据。
常用端口:9200
查询语言:请求体搜索DSL查询
优势
- 分布式:横向扩展非常灵活
- 全文检索:基于lucene的强大的全文检索能力;
- 近实时搜索和分析:数据进入ES,可达到近实时搜索,还可进行聚合分析
- 高可用:容错机制,自动发现新的或失败的节点,重组和重新平衡数据
- 模式自由:ES的动态mapping机制可以自动检测数据的结构和类型,创建索引并使数据可搜索。
-
劣势
-
术语
基本概念有:Cluster 集群、Node节点、Index索引、Document文档、Shards & Replicas分片与副本等
Node: 装有一个 ES 服务器的节点。
Cluster: 有多个Node组成的集群
Document: 一个可被搜素的基础信息单元
Index: 拥有相似特征的文档的集合
Type: 一个索引中可以定义一种或多种类型
Filed: 是 ES 的最小单位,相当于数据的某一列
Shards: 索引的分片,每一个分片就是一个 Shard
Replicas: 索引的拷贝
DB -> Databases -> Tables -> Rows -> Columns
ES -> Indices -> Types -> Documents -> Fields索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
存储结构和算法
Term Dictionary -> Term Index -> FST 类似字典树
- posting list -> Frame Of Reference 差+最长长度
- Roaring bitmaps %65536商余
- 文档数量压缩(合并同类项)
-
Lucene
为了加速搜索,Lucene会将常用的查询过滤条件产生的结果集缓存到内存中,方便复用,称为filter cache。结果集其实就是文档ID(整形数)的集合。从Lucene 5开始,使用了RBM优化过的文档ID集合RoaringDocIdSet作为filter cache,详情可以参见《Frame of Reference and Roaring Bitmaps》。该文除了介绍RBM外,还介绍了压缩倒排索引的Frame of Reference(FOR)编码,值得一读。
分片<>集群
ES集群:ES Server进程,3个节点,主从架构,raft(奇数节点)
数据分片:lucene实例,分片和副本数不是根据节点数来的,即1个ES节点可以有多个lucene实例,可以指定一个索引的多个分片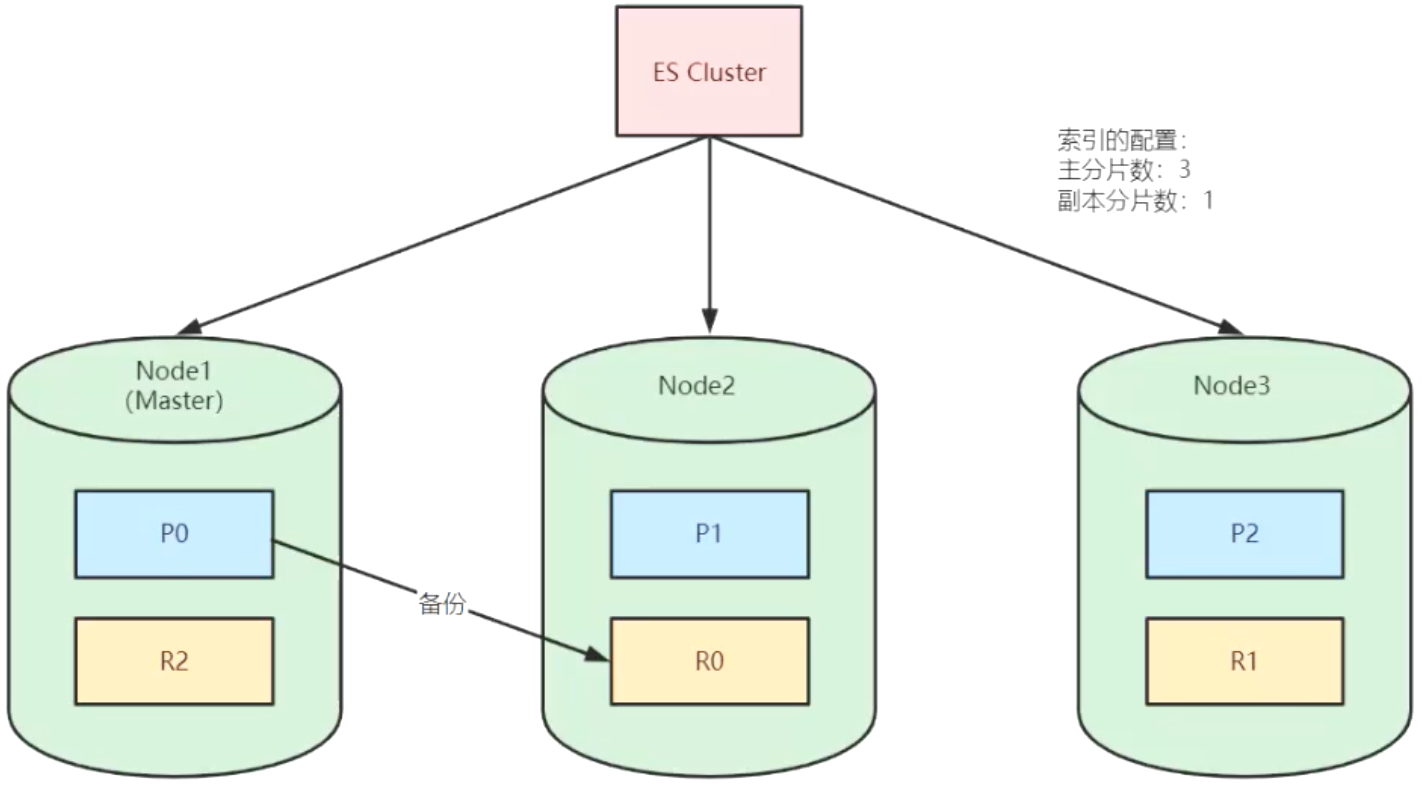
新版本
5.x 打分机制TF-IDF=>BM 25(优化性能)
- 6.x 跨集群复制CCR
-
和Solr比较
传统搜索应用里Solr表现好

若有收获,就点个赞吧
0 人点赞
