架构
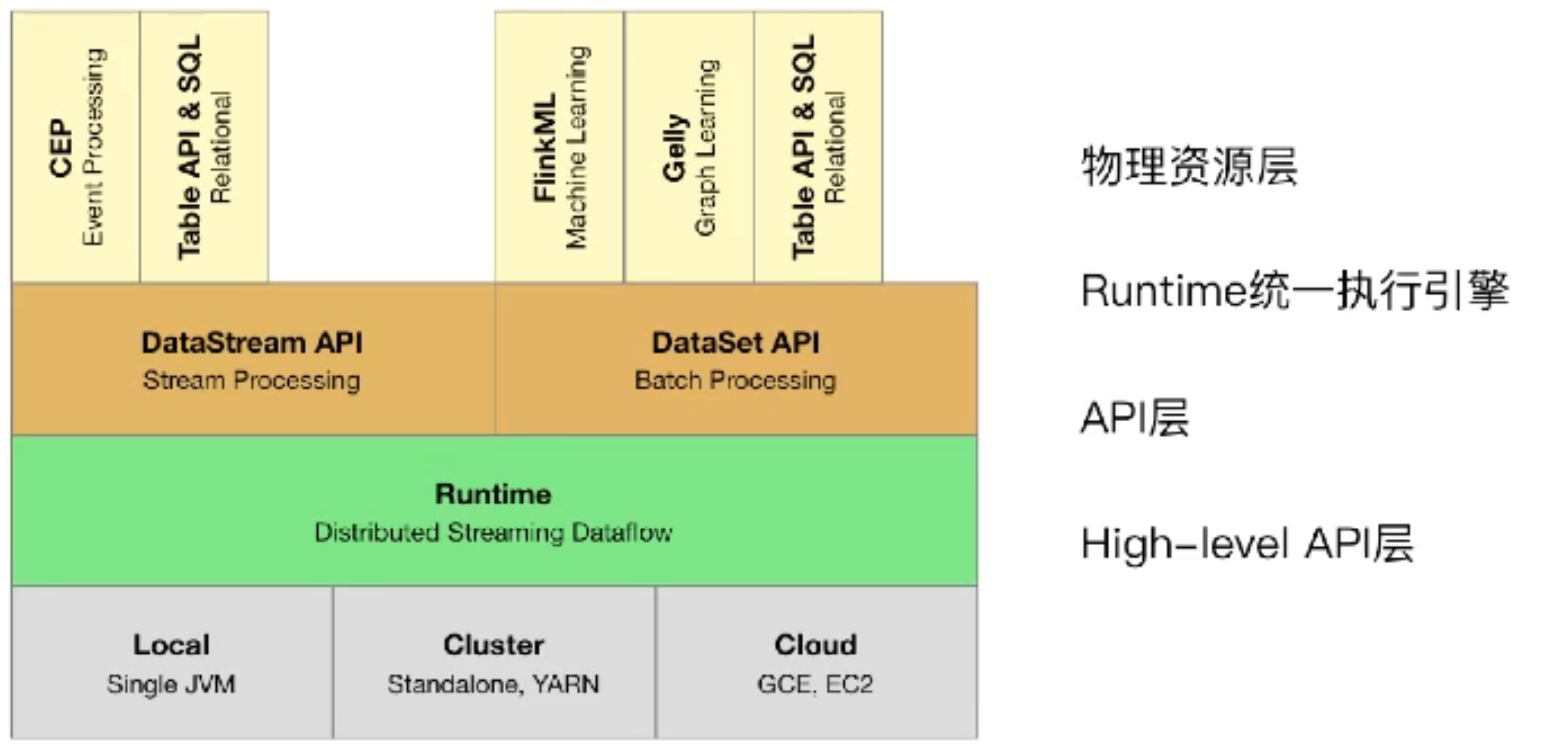
Runtime层

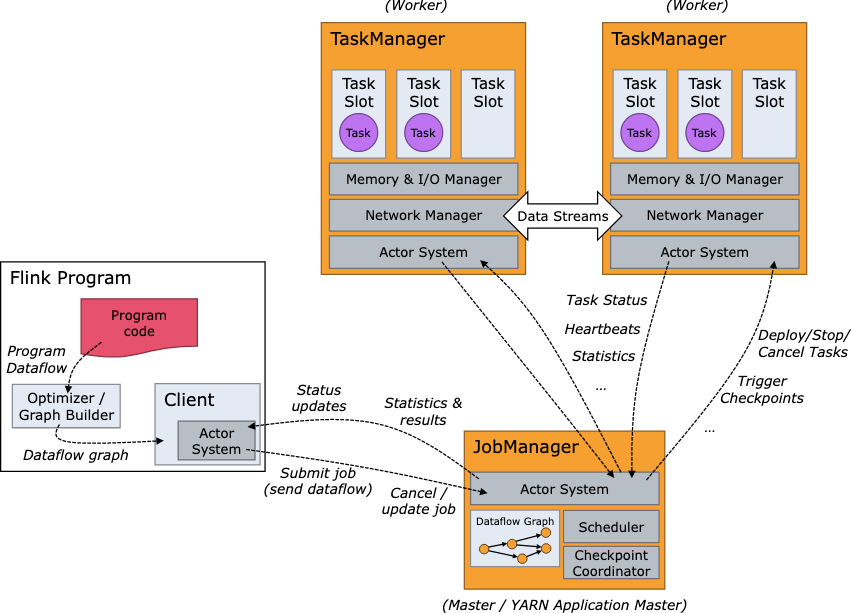
AM进程(Dispatcher唯一、RM唯一、JobManager可能有多个)
JobGraph是优化后的结果
两种运行模式
- Per-Job:独享Dispatcher和RM,按需申请TaskExcutor,适合执行时间较长的大作业
Session:共享Dispatcher和RM,JM独立,共享TaskExcutor,适合规模小执行时间较短的作业
资源和调度
目标:任务和资源匹配
资源:Slot(大小(社区版未启用),Location,每个TM包含1个或者多个Slots)
任务:大小(社区版未启用),CoLocation Constraint
管理:
RM(包含SlotManager,管理Slot状态,分配Slot资源)
TaskExcutor(实际持有Slot资源)
JM(SlotPool
用心跳避免slot丢失
默认一个task运行在一个slot上,但是slot sharing可以在单个slot中启动多个task(同vertex不可以,互补任务可以)作业DAG图结构
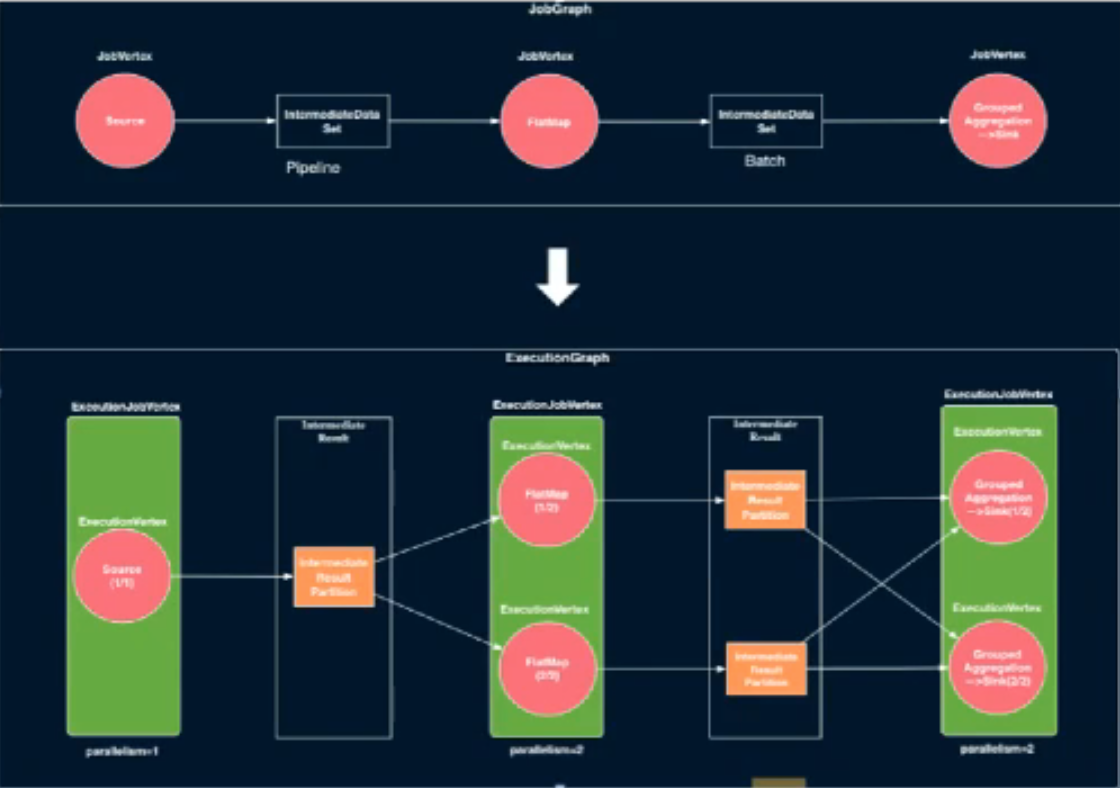
JobGraph
逻辑图(未考虑并发):JobVertex(Source-Pipeline边(流)->FlatMap->Blocking边(批)..)
实际图:ExcutionGraph,JM实际维护的数据结构,物理结构考虑并发
调度策略:Eager流作业(饿汉式)、LAZY_FROM_SOURCE批作业(懒汉式)错误恢复
Task Failover:Restart-all(所有Vertex从上一个checkpoint重新跑起)、Restart-individual(应用有限,可能不一致,只应用于task间没有连接的情况)、Restart-Region(重启Pipeline Region,如果自身执行失败->只找有pipeline相连的边的vertext给restart,如果读取失败->也要重启上游)


Master Failover
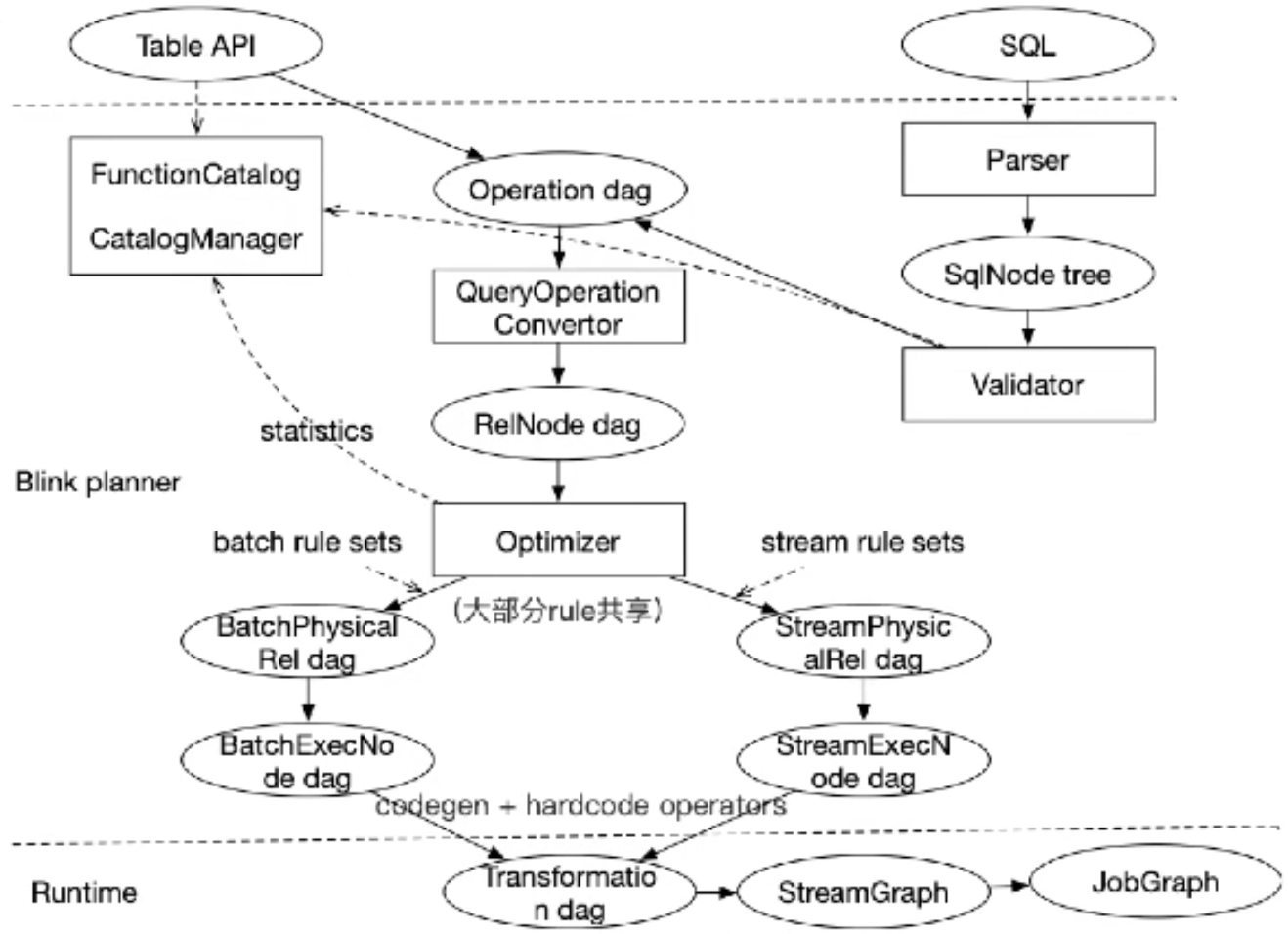
SQL API
- Table API:声明性DSL表
- DataSteam(有界无界流)/DataSet(有界数据集) API:转换,连接,聚合,窗口,状态
- Stateful Steam Processing:一个或多个流的事件,并使用一致的容错状态,注册事件时间和处理时间回调,允许程序实现复杂的计算
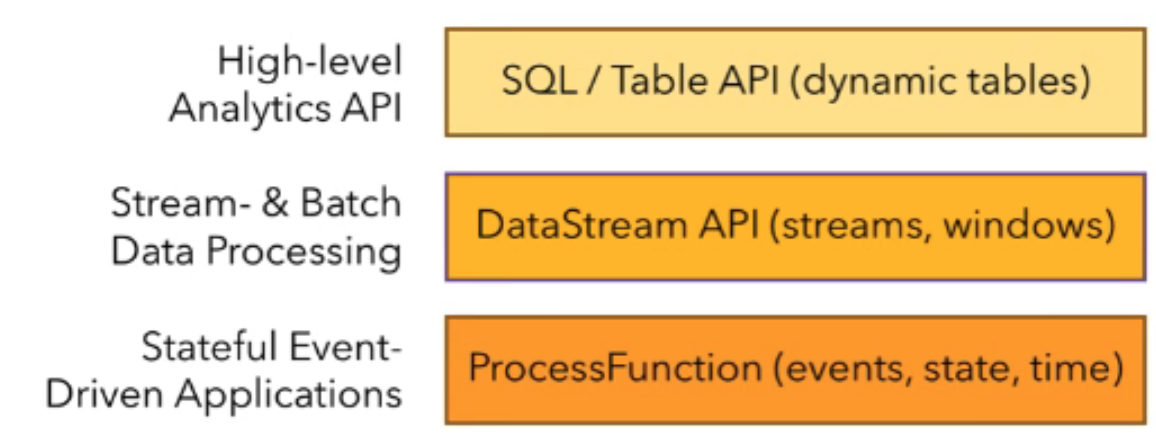
时间语义
- Processing Time 模拟真实世界时间,处理数据节点的本地时间,处理简单,结果不确定(无法重现),递增
Event(Row) Time 数据世界时间,记录携带的Timestamp,处理复杂,结果确定(可重现),一定程度乱序(Record Timestamp),为了保证有序插入watermark(以后到来的数据一定不会小于之前的)
Record Timestamp和watermark
产生:SourceFunction(collectionWithTimestamp/emitWatermark)、DataStream.assignTimestampsAndWatermarks()
生成器
- 传播:watermark广播形式在算子之间传播,Long.MAX_VALUE表示不会再有数据,多流(单输入取其大,多输入取其小->局限没有区分逻辑上的单流和多流,强制同步时钟)
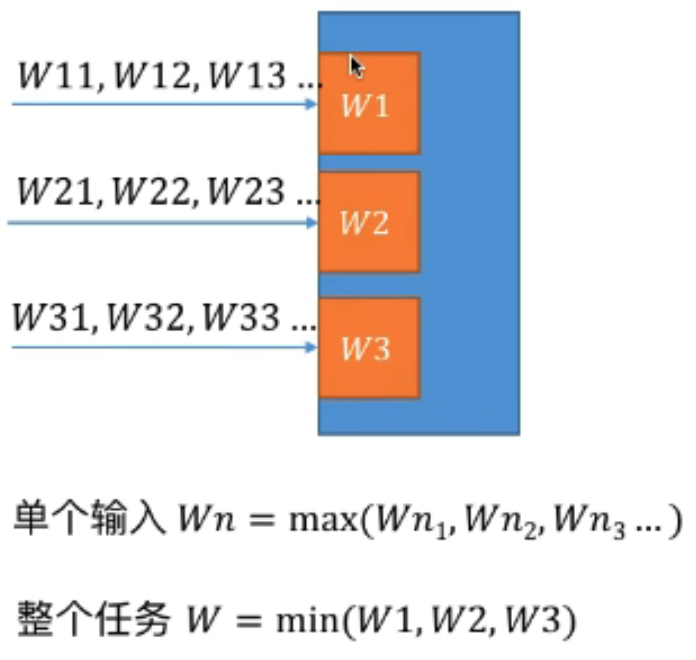
传播是幂等的
-
ProcessingFunction=>TimeServer
获取记录的Timestamp或当前ProcTime
- 获取算子时间(Watermark)
注册Timer并提供回调逻辑(registerEventTimeTimer()、registerProcessingTimeTimer()、onTimer())
Watermark处理
更新算子任务所在的时间
- 遍历计时器队列出发回调逻辑
-
Table中的时间列
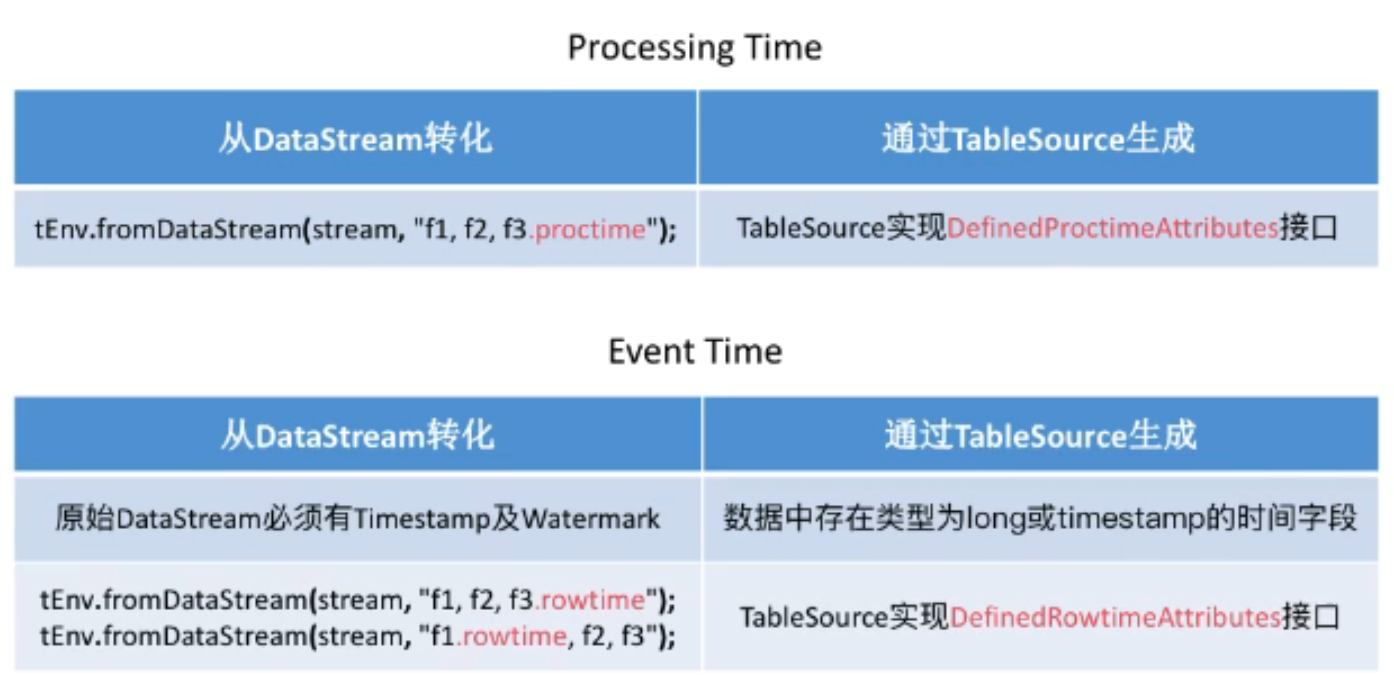
操作:Over窗口聚合、Group By窗口聚合、时间窗口连接、排序流程
source数据源->算子(transform[map()->keyBy()/window()/apply()])->sink数据汇
State&Checkpoint
state backend
- state语义:keyed state(不同task上不会出现相同的key)、Operator state(常见是source state)
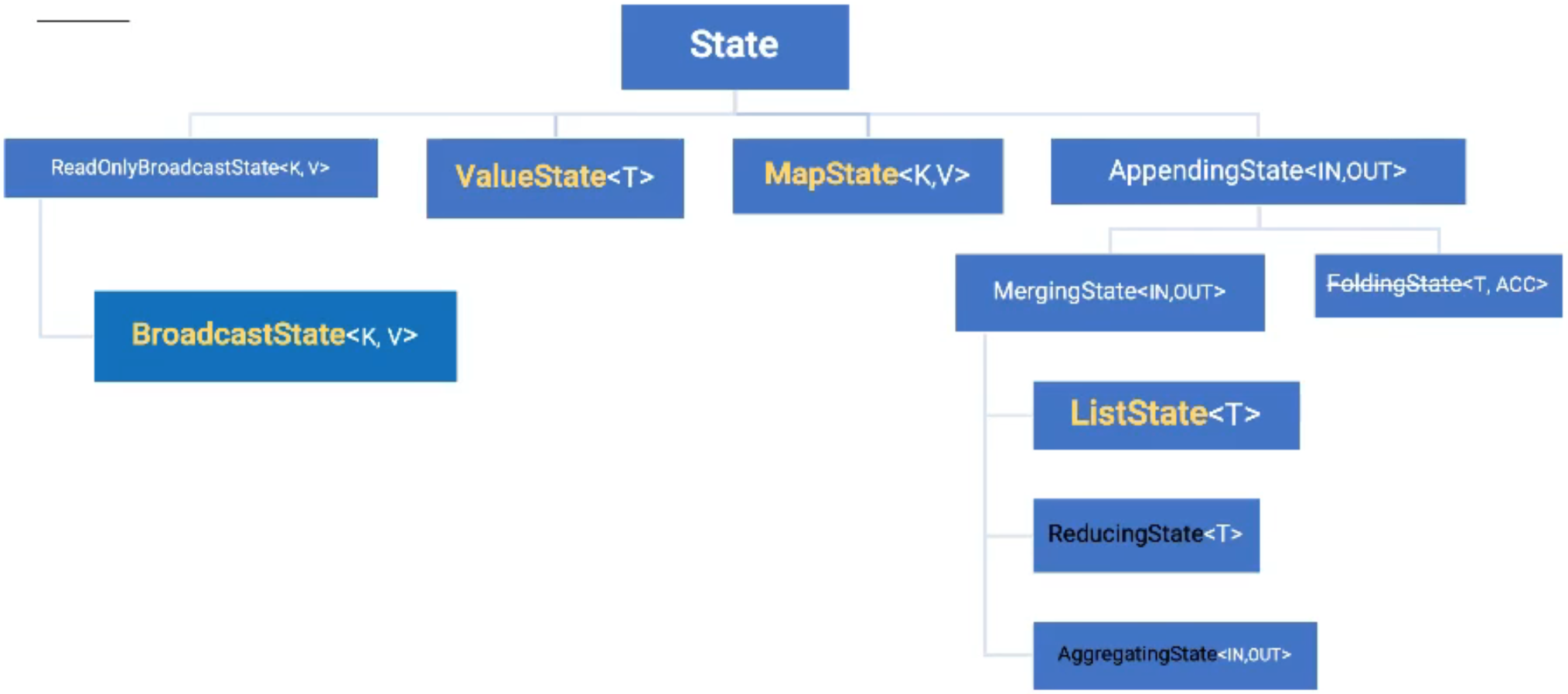
- managed state、raw state(本质bytes)
- backend
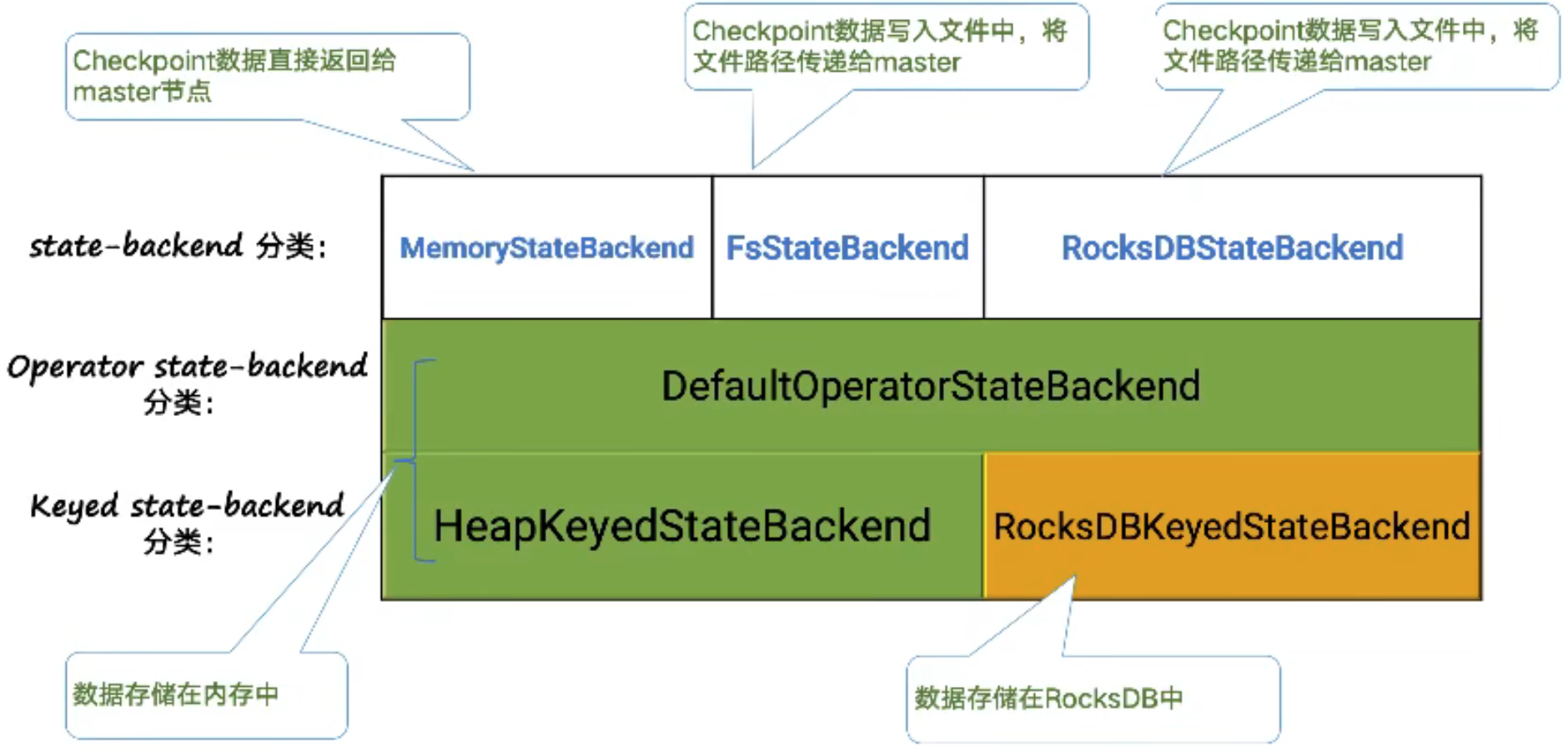
- 从已经停止的作业进行恢复:savepoint、externalized checkpoint
-
数据类型


获取序列化器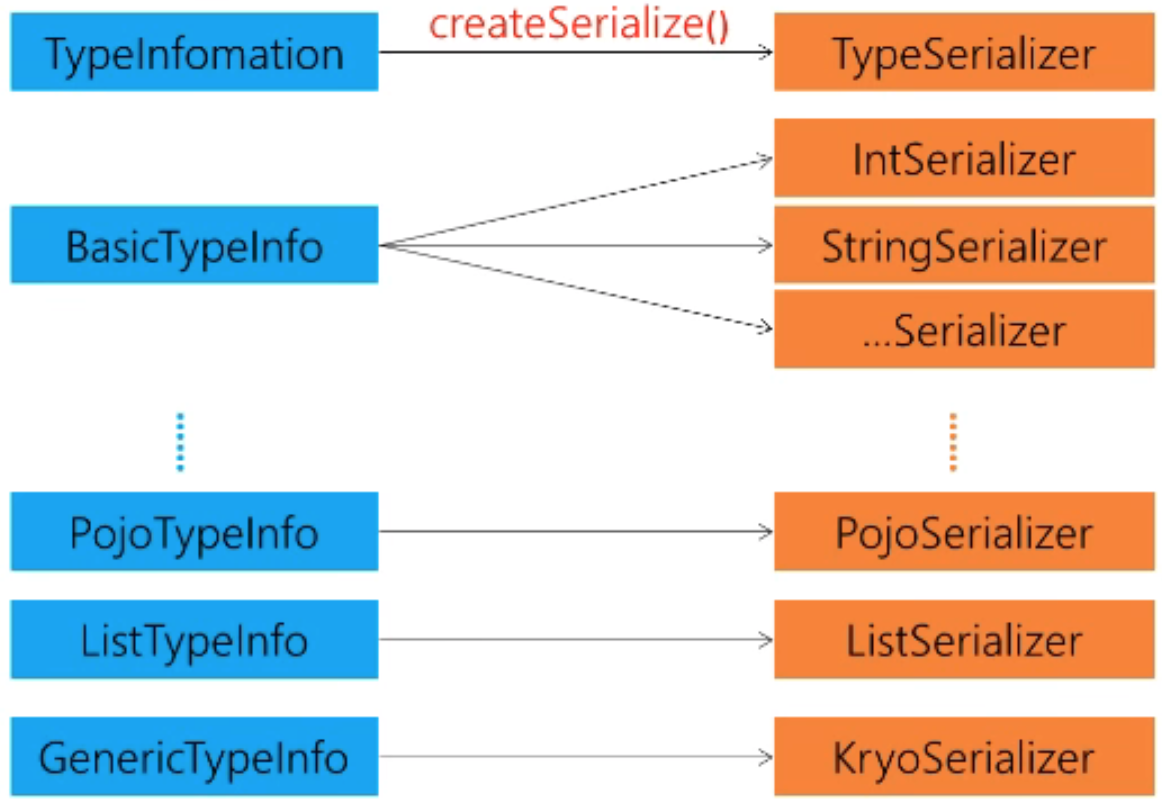

MemorySegment 最小内存分配单元byte[] 32KB
类型声明:TypeInformation.of、Types、自定义@TypeInfo、自定义TypeInfoFactory
注册子类型、kyro
通信层序列化:RecordSerializer、RecordDeserializer、EventSerializer、SerializerDelegate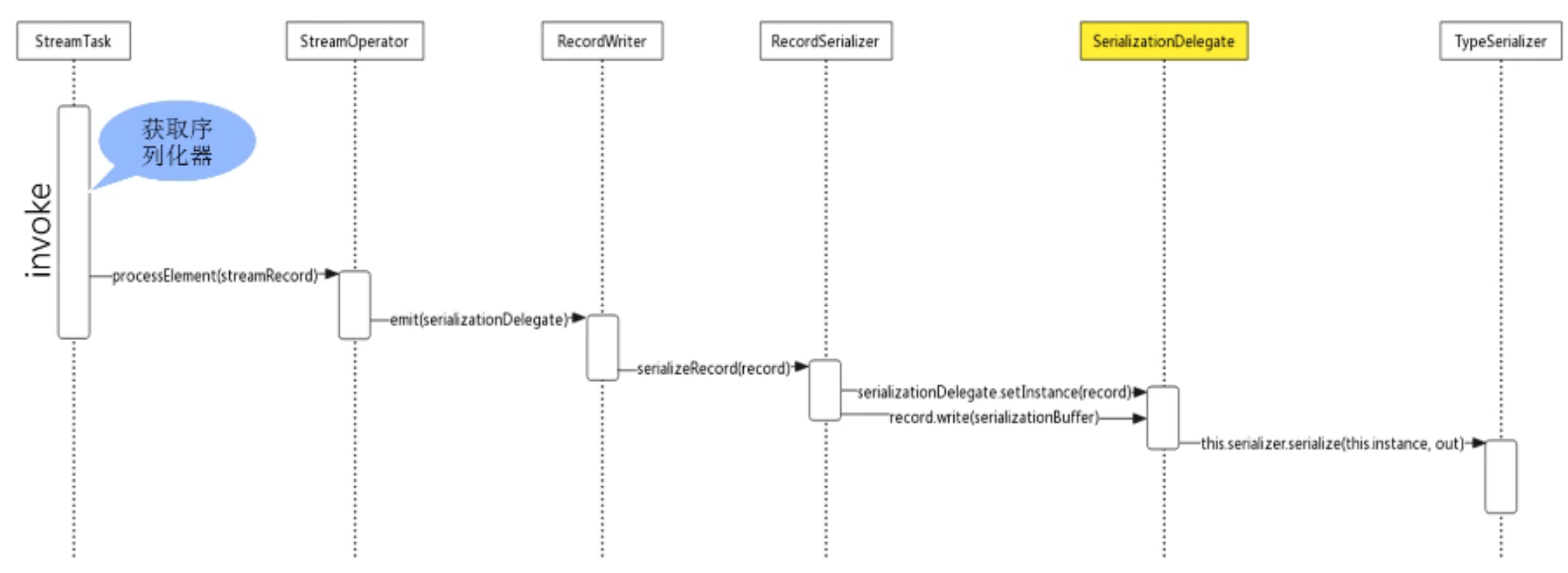
作业提交过程
网络
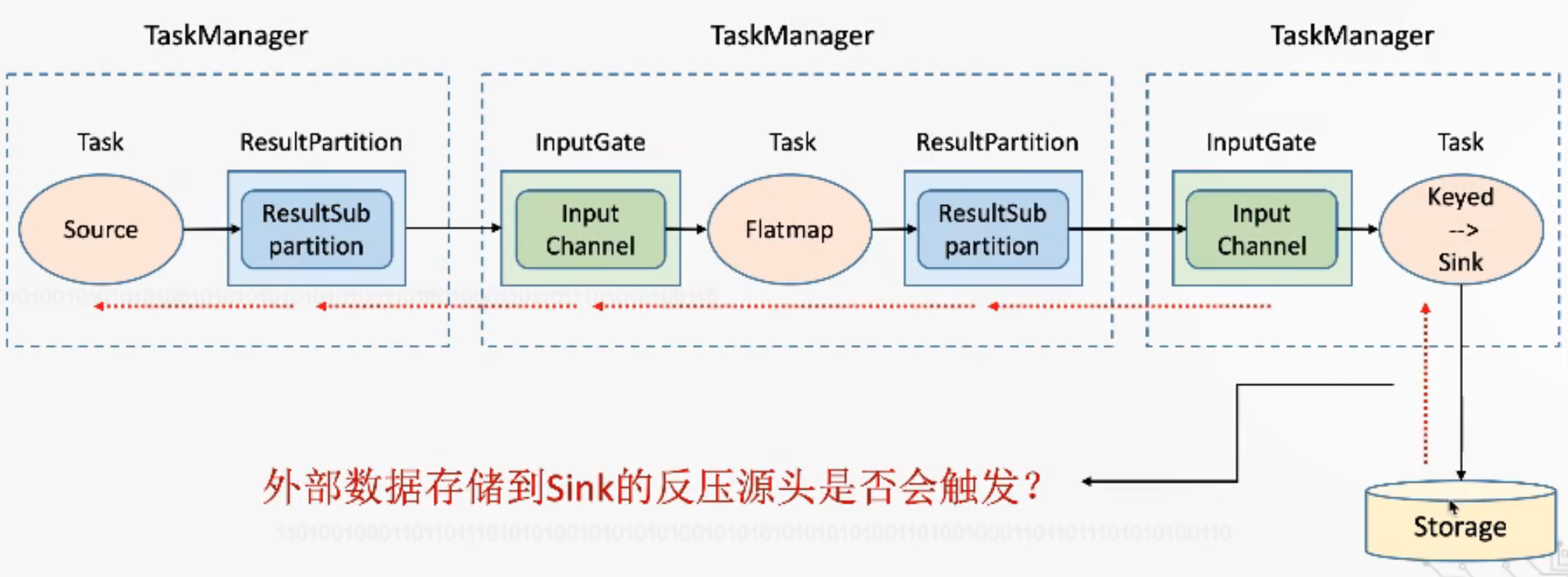

1.5之前,基于TCP反压机制——TaskManager反压过程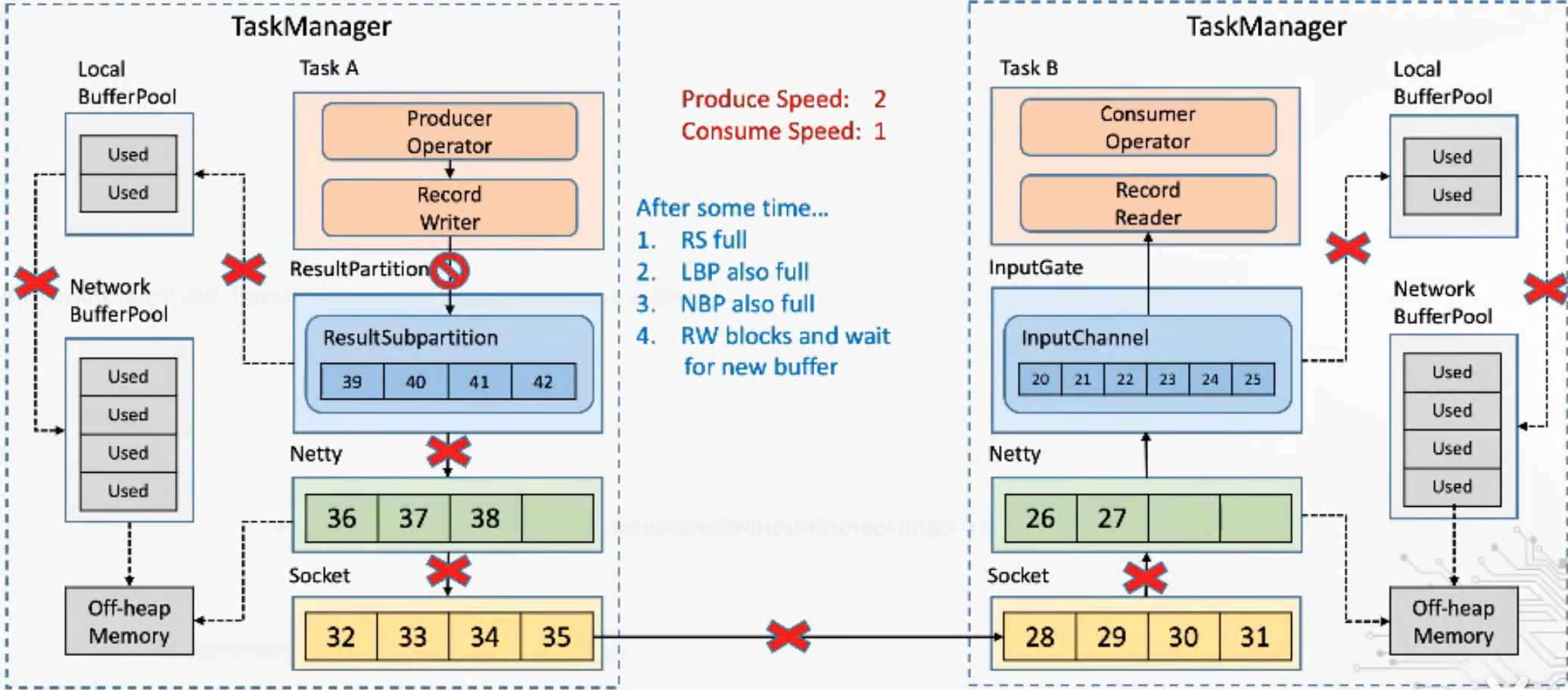
1.5之前,基于TCP反压机制——TaskManager内反压过程
缺点:单个Task导致反压阻断整个TM的socket(一般共享Socket),checkpoint barrier也无法发出,传播路径长延迟大
credit-based反压:flink层模仿tcp流控,backlog/creditConnector
预定义的Source和Sink
- Bunded Connectors
- Apache Bahir中的连接器
-
窗口
时间驱动、数据驱动
-
时间
-
如何保证消息不丢失、重复
end-to-end:开启checkpoint/开启exactly-once语义/手动savepoint/statebackend fs持久化
- source:保存消费offset(kafka)
- sink:2PC(两阶段提交,checkpoint全部完成后提交)/预写事务
- 外部应用幂等

Flink框架引擎把执行计划抽象为四个层次的数据结构,分别是API层、静态topology、JobGraph、ExecutionGraph等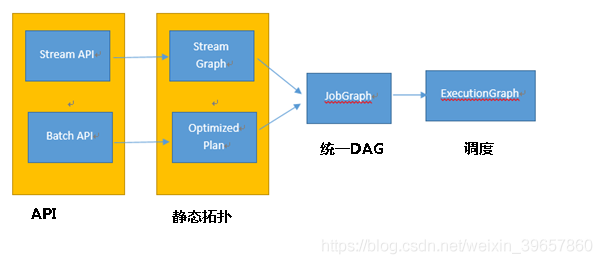
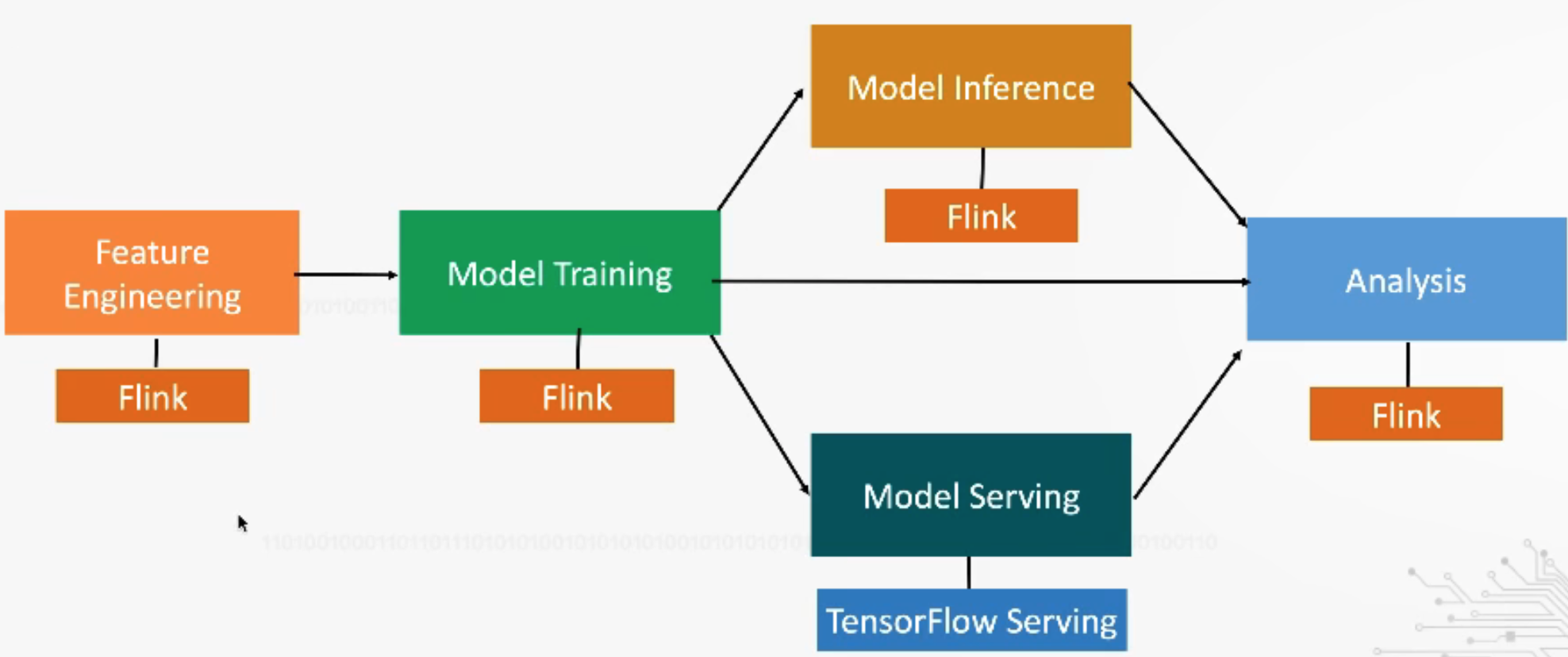
Flink+TF
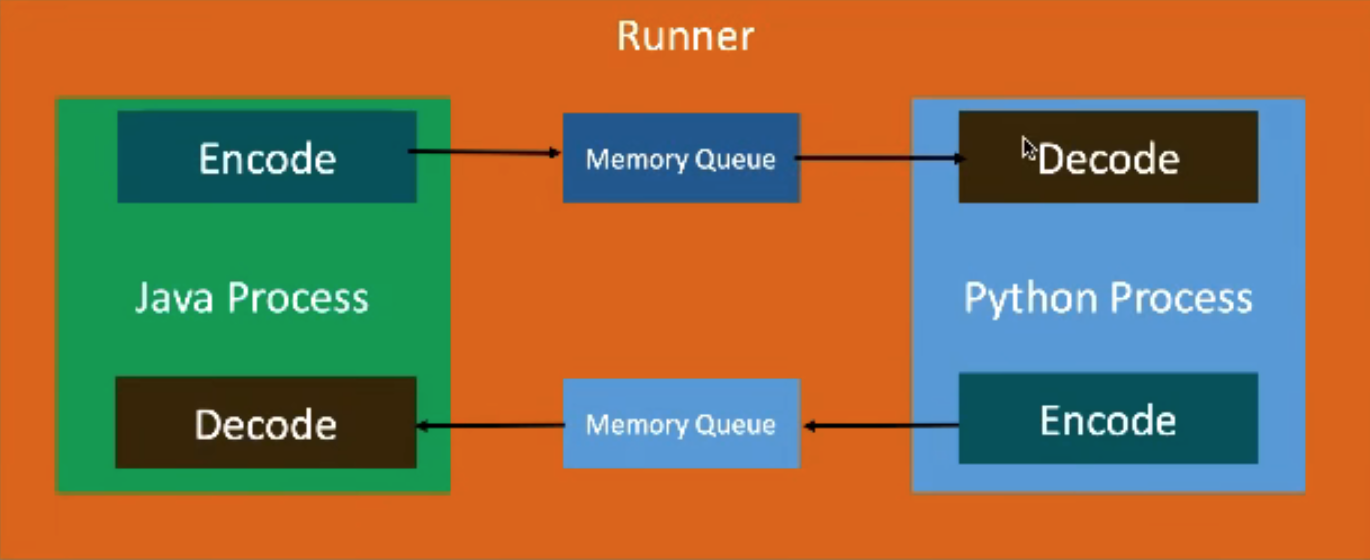
Flink SQL
Flink CDC 2.0
https://blog.csdn.net/tzs_1041218129/article/details/123243845
全增量快照读取算法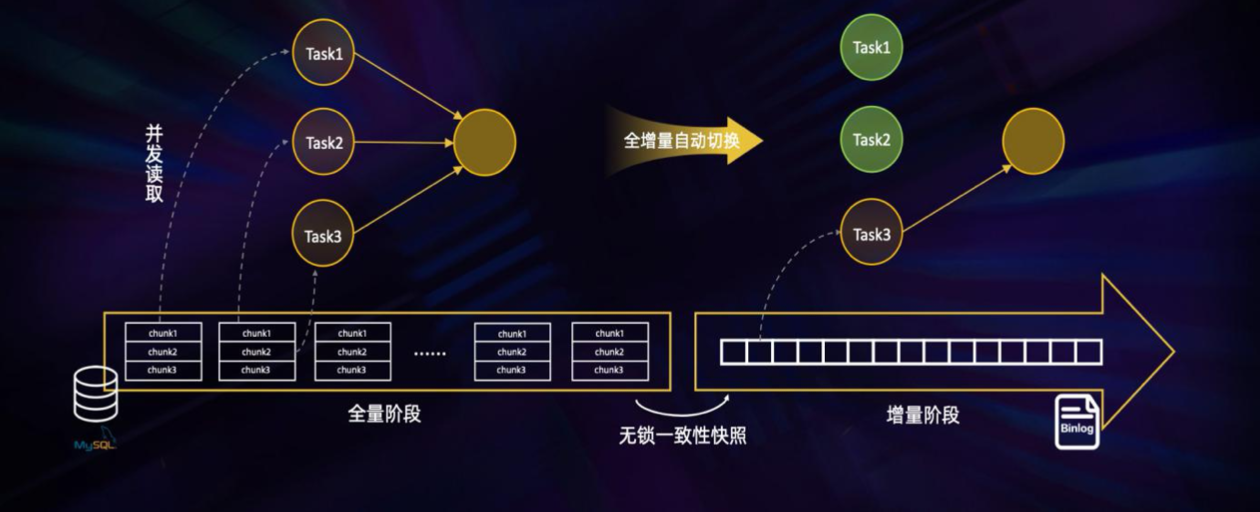

若有收获,就点个赞吧
0 人点赞
