索引应用最广的关系型数据库
MySQL逻辑架构
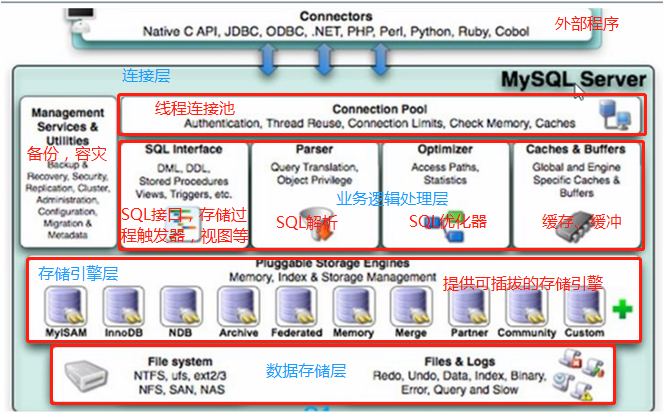
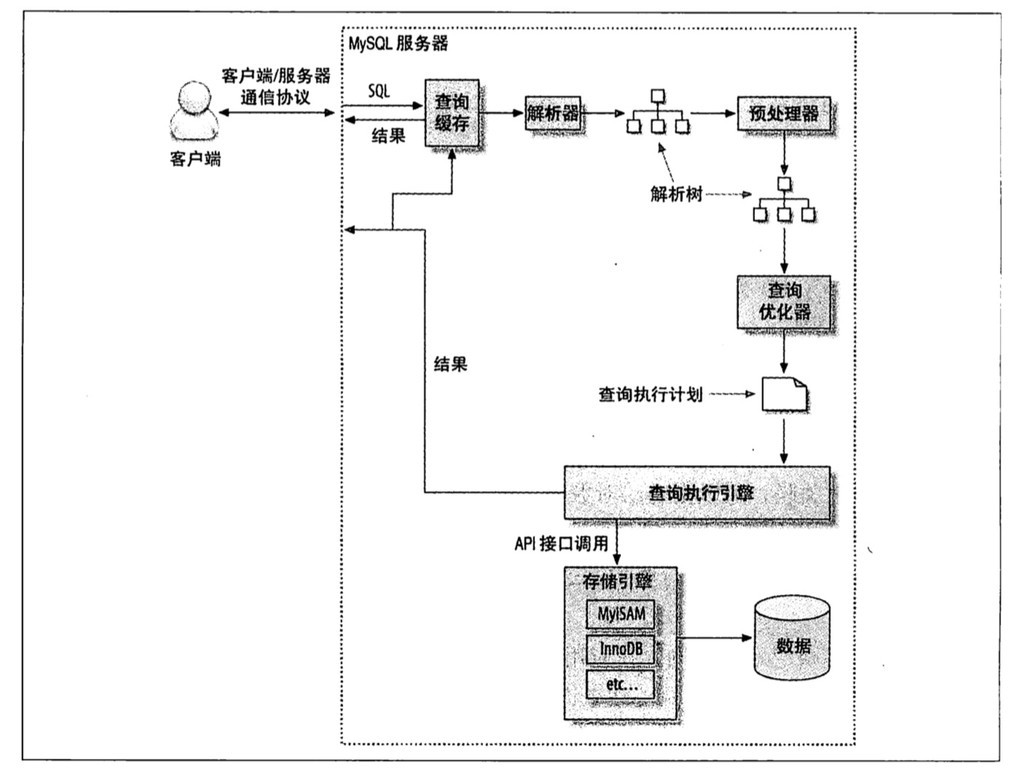
- 查询过程
- 逻辑存储结构
段(segment)、区(extent)、页(page)、行(row)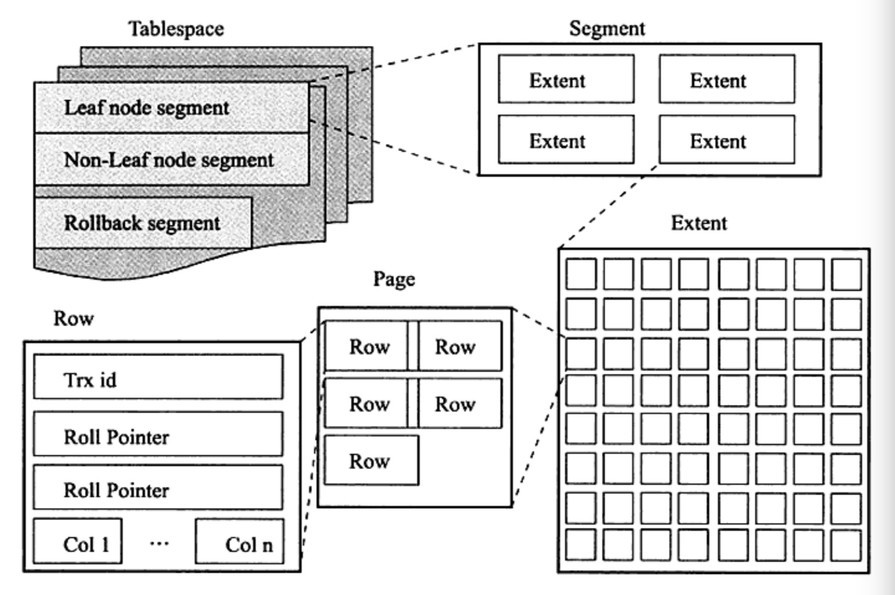
- 驱动表:JOIN
MySQL锁有哪些?
从并发控制角度分为:共享锁/读锁,排他锁/写锁
从锁粒度角度分为:表锁(Alter),行级锁
IX、IS、SIX(S+IX)
作用:加行锁时给表加上意向锁,以防止别的事务查询时判断是否加表锁需要遍历全表
https://www.jianshu.com/p/b312855d7d1bMySQL事务?
核心概念:ACID(原一隔持)
代码:
四种隔离级别:RU未提交读(脏读/不可重复读/幻读),RC提交读(不可重复读/幻读),RR可重复读(幻读(MVCC和间隙锁解决)),S可串行化。设置:set transaction isolation levelSTART TRANSACTION;...COMMIT;
并发性能由高到低,系统开销由少到多
https://developer.aliyun.com/article/743691
死锁:将持有最少行级排它锁的事务回滚
Innodb:两阶段锁定协议,根据隔离级别任何时候都可能自动加锁,只有在ROLLBACK和COMMIT才会同时释放锁
显式锁定
SELECT … FOR UPDATE
SELECT … LOCK IN SHARE MODE什么是MVCC?
多版本并发控制
行级锁的一个变种,多数情况下避免了加锁,非阻塞的读且写只锁必要的行
Innodb实现:每个行添加两个字段trx_id事务ID/roll_pointer回滚指针,代表行的创建时间系统版本号和过期/删除时间系统版本号,实现不加锁的事务隔离
InnoDB
表空间(每个表的数据/索引在不同文件中)
聚簇索引,主键尽可能小
可预测性预读
自动在内存中创建hash索引以加速读操作的自适应hash索引
加速插入操作的插入缓冲区(insert buffer->change buffer)物理页,慢慢合并回二级索引,只能用在非唯一索引上,只针对单个页
双写缓冲区(doublewrite)
支持热备
优化技巧
- 字段限制大小、简单内建类型
- 索引列尽可能NOT NULL
- DATETIME允许时间范围大,TIMESTAMP范围小,但是存储空间小,时区不敏感,可以自动更新
- 列不能太多(行缓冲)
- 关联表不能太多(12个一些)
- 表达式和函数会使索引失效
- 提高索引的选择性(唯一索引为1)不要有太多重复值
- 长VARCHAR、TEXT、BLOB要用前缀索引,长度选择参考上一条
- 不建议建多个单独索引(虽然再Union、Intersection等MySQL会做索引合并),改用多列索引
- 不考虑排序和分组时候,将选择性最高的列放到索引最前列,不确定就用索引选择性值来判断
- 建议用自增键,保证顺序插入,根据主键做关联操作性能也更好(高并发下可能会有auto_increment锁争用情况)
- LIKE “%xxx%”使索引失效
- 需要索引进行排序时尽可能用覆盖索引,负责回表随机IO会很慢,排序列顺序索引顺序一致且正序倒序一致才行
- 避免冗余索引(不绝对)和重复索引
- 范围查询的列一般在索引的最后
- 延迟关联(自关联覆盖索引子查询)
- 适当反范式化
- 避免使用SELECT *
- 行切分查询(尤其是删除更新等)
- 分解关联查询(可以利用缓存、减少锁竞争、应用层可扩展、查询效率提升、减少冗余查询、相当于应用层hash关联)
三大优化:
- 库表结构优化
- 索引优化的核心原则:避免单行查找防止随机IO、顺序读取避免排序、覆盖查询
查询优化核心:访问数据太多
选取最合适的的字段属性
- 选取合适的引擎
- 索引优化流程
- 预先跑sql explain
- 排除缓存sql nocache
- 看一下行数对不对,不对可以用analyze table t 纠正
- 添加索引,索引不一定是最优的,force index强制走索引,不建议用
- 存在回表的情况吗?
- 覆盖索引避免回表,不要*,主键索引
- 联合索引不能无限建,高频场景
- 最左前缀原则,按照索引定义的字段顺序写sql
- 合理安排联合索引的顺序
- 5.6之后,索引下推,减少回表次数
- 给字符串加索引:前缀索引、倒序存储、Hash
- 数据库的flush时机:redo log满了 修改checkpoint flush到磁盘,系统内存不足淘汰数据页 buffer pool(要知道磁盘io能力 设置innodb_io_capacity设置为磁盘的IOPS fio测试、innodb_io_capacity设置低了 会让innoDB错误估计系统能力 导致脏页累积),系统空闲的时候找间隙刷脏页,MySQL正常关闭 会把内存脏页flush到磁盘
- innoDB刷盘速度:脏页比例,redolog写盘速度,innodb_flush_neighbors 0(机械硬盘的随机io不太行 减少随机io性能大幅提升 设置为1最好、现在都是ssd了 设置为0就够了 8.0之后默认是0)
- 索引字段不要做函数操作,会破坏索引值的有序性,优化器会放弃走树结构:如果触发隐式转换,那也会走cast函数,会放弃走索引
- 字符集不同可能走不上索引:convert也是函数所以走不上
- 缓存、生成视图
- 读写分离
- 大表:分库、分表、分区
- SQL优化
- SQL语句中IN包含的值不应过多
- SELECT语句务必指明字段名称
- 当只需要一条数据的时候,使用limit 1
- 如果排序字段没有用到索引,就尽量少排序
- 如果限制条件中其他字段没有索引,尽量少用or
- 尽量用union all代替union
- 不使用ORDER BY RAND()
- 区分in和exists、not in和not exists
- 使用合理的分页方式以提高分页的效率
- 分段查询
- 避免在where子句中对字段进行null值判断
- 不建议使用%前缀模糊查询
- 避免在where子句中对字段进行表达式操作
- 避免隐式类型转换
- 对于联合索引来说,要遵守最左前缀法则
- 注意范围查询语句
- 关于JOIN优化
- Explain必要时可以使用force index来强制查询走某个索引

- type列,连接类型。一个好的SQL语句至少要达到range级别。杜绝出现all级别。
- key列,使用到的索引名。如果没有选择索引,值是NULL。可以采取强制索引方式。
- key_len列,索引长度。
- rows列,扫描行数。该值是个预估值。
- extra列,详细说明。注意,常见的不太友好的值,如下:Using filesort,Using temporary。
- 增加服务器内存、CPU及网络带宽
- id用完了:bigint、row_id没设置主键的时候、thread_id
- IO性能瓶颈:设置 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count参数,减少binlog的写盘次数。这个方法是基于“额外的故意等待”来实现的,因此可能会增加语句的响应时间,但没有丢失数据的风险。将sync_binlog 设置为大于1的值(比较常见是100~1000)。这样做的风险是,主机掉电时会丢binlog日志。将innodb_flush_log_at_trx_commit设置为2。这样做的风险是,主机掉电的时候会丢数据。
- 常用命令:
- show_processlist:查看空闲忙碌链接,wait_timeout 客户端空闲时间(定时断开链接、mysql_reset_connection恢复链接状态)
- innodb_flush_log_at_trx_commit:redolog事务持久化
- sync_binlog:binlog事务持久化
故障实战:数据库挂了 show processlist 一千个查询在等待 有个超长sql kill 但是不会引起flush table 周末 优化脚本 analyze 会导致 MySQL 监测到对应的table 做了修改 必须flush close reopen 就不会释放表的占用了
索引
BTREE结构,B+树一个叶子页16K(1页)
- 最左前缀
- 优点:减少扫描行数;避免排序和分组,避免创建临时表;将随机 I/O 变为顺序 I/O
- MySQL B+树
- Hash:等值查询
- 聚簇索引和非聚簇索引(多扫描一次减少回表)
- 覆盖索引:减少IO
- 联合索引与最左原则
- 索引下推:减少回表
- 索引维护:页满了 页分裂 页利用率下降、数据删除 页合并、自增 只追加可以不考虑 也分页、索引长度
索引选择:
- 普通索引:找到第一个之后,直到碰到不满足的
- 唯一索引:找到第一个不满足就停止了
- 覆盖索引:包含主键索引值
- 最左前缀原则:安排字段顺序
- 索引空间问题:hash
- 5.6之后索引下推:不需要多个回表,一边遍历,一边判断
- 页的概念
- 更新:change buffer、更新操作来了 如果数据页不在内存 就缓存下来 下次来了 更新 在就直接更新、唯一索引 需要判断 所以用不到change buffer、innodb处理流程(记录在页内存(唯一索引 判断没冲突插入、普通索引 插入)、记录不在页(数据页读入内存 插入、change buffer)、数据读是随机IO成本高、机械硬盘change buffer收益大 写多都少 marge)
Innodb的自适应哈希是什么?
某些索引值使用频繁,再创建一个哈希索引(全自动无法干预)
也可以自己造个伪哈希列,CRC32(),用触发器维护,匹配时必须带上原始值的等值匹配防止hash冲突
索引的优点有?
大大减少服务器需要扫描的数据量
- 帮助服务器避免排序和临时表
-
事务
四大特性:ACID——原子性、一致性、隔离性、持久性
- 并发事务问题:脏读(别人写没提交)、丢失修改(覆盖了别人写)、不可重复读(别人修改在两次读之间提交)、幻读(别人插入/删除在两次读之间提交)
- SQL隔离级别:读取未提交【没视图概念都是返回最新的】、读取已提交【阻止脏读/不同的read view】、可重复读(MySQL默认-Next-key Lock)【阻止脏+不可重复/用一个read view】、可串行化【都阻止了】
回滚日志:没更早的read view删除,5.5之前回滚段删了文件也不会变小
锁
MVCC
- 版本链:在聚簇索引中,有两个隐藏列trx_id roll_pointer
- 读未提交:直接读取最新版本
- 序列化:加锁
- Read View:读已提交 每次读取前生成一个、可重复读 每一次生成一个
- count 1* mvcc影响
- 全局锁:全库逻辑备份
- 表锁:
- lock table read/write
- MDL(metadata lock):5.5引入自动添加 读锁不互斥 写锁互斥、多个事务之前操作 如果查询的时候修改字段容易让线程池跑满(MySQL的information_scheme库的innodb_trx 表 找到对应长事务kill掉、alter table里面设定等待时间)
- MyISAM是不支持表锁的
- 行锁
- 需要的时候才加上,并不是马上释放,等事务结束才释放,两阶段锁协议
- 死锁:超时时间 innodb_lock_wait_timeout 默认是50s太久 但是如果设置太短会误判 一般采用死锁监测、死锁机制 事务回滚 innodb_deadlock_detect=on
- 热点行:死锁消耗CPU 临时关闭 关掉死锁会出现大量重试、控制并发度 更多的机器 开启比较少的线程 消耗就少了、分治
- 间隙锁
- 读写锁
- 读:lock in share mode、for update、行锁
- 写
innodb如何加锁
undo log:回滚MVCC
- redo log:物理日志 内存操作记录 sync_binlog可以优化日志写入时机
- binlog:组提交机制,可以大幅度降低磁盘的IOPS消耗
-
聚簇索引和Innodb实现?
Innodb中聚簇索引指同一结构同时保存了B-Tree索引和数据行(单表只能有唯一一个)
- Innodb选择主键索引(没有用唯一非空索引,没有则隐式创建)作为聚簇索引
- 优点
- 把相关数据保存在一起,减少磁盘I/O
- 数据访问更快
- 使用覆盖索引扫描的查询可以直接使用页节点中的主键值
缺点
概念:一个索引包含所有需要查询的字段的值(无需回表)
- 优点
- 极大减少数据访问量
- 范围查询磁盘IO少
- Innodb避免对于聚簇索引的二次查询
- 特点
尽可能最大化利用索引在引擎层完成筛选,减少核心服务层的WHERE筛选后的回表操作(即IO操作)
Extra:Using index condition
只适用于二级索引,有子查询/存储函数无法使用
如何查看MySQL线程状态
- SHOW FULL PROCESSLIST;
状态包括:sleep、query、locked、analyzing and statistics、copying to tmp table[on desk]、sorting result、sending data
Explain
id
- select_type:simple/primary/subquery/derived/union/union result
- table
- type: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
- possible_keys
- key
- key_len:索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前半部分的字符提取出来做索引
- ref:const(常量),func,NULL,字段名(例:film.id)
- rows
extra:distinct/Using index/Using where/Using temporary/Using filesort
Innodb和MyISAM的区别
https://blog.csdn.net/weixin_43415481/article/details/114896035
Innodb热备
https://blog.csdn.net/mingtiannihaoabc/article/details/120573596
PXB(Percona XtraBackup)唯一一款开源免费的,支持MySQL热备的,非阻塞备份工具。MySQL、PostgreSQL、MariaDB 区别
参考:https://zhuanlan.zhihu.com/p/362598819
PostgreSQL不支持嵌入式
PG更加适合严格的企业应用场景(比如金融、电信、ERP、CRM),而MySQL更加适合业务逻辑相对简单、数据可靠性要求较低的互联网场景(比如google、facebook、alibaba)
PostgreSQL相对于MySQL的优势在SQL的标准实现上要比MySQL完善,而且功能实现比较严谨;
- 存储过程的功能支持要比MySQL好,具备本地缓存执行计划的能力;
- 对表连接支持较完整,优化器的功能较完整,支持的索引类型很多,复杂查询能力较强;
- PG主表采用堆表存放,MySQL采用索引组织表,能够支持比MySQL更大的数据量。
- PG的主备复制属于物理复制,相对于MySQL基于binlog的逻辑复制,数据的一致性更加可靠,复制性能更高,对主机性能的影响也更小。
- MySQL的存储引擎插件化机制,存在锁机制复杂影响并发的问题,而PG不存在。
MySQL相对于PG的优势:
- innodb的基于回滚段实现的MVCC机制,相对PG新老数据一起存放的基于XID的MVCC机制,是占优的。新老数据一起存放,需要定时触发VACUUM,会带来多余的IO和数据库对象加锁开销,引起数据库整体的并发能力下降。而且VACUUM清理不及时,还可能会引发数据膨胀;
- MySQL采用索引组织表,这种存储方式非常适合基于主键匹配的查询、删改操作,但是对表结构设计存在约束;
- MySQL的优化器较简单,系统表、运算符、数据类型的实现都很精简,非常适合简单的查询操作;
- MySQL分区表的实现要优于PG的基于继承表的分区实现,主要体现在分区个数达到上千上万后的处理性能差异较大。
- MySQL的存储引擎插件化机制,使得它的应用场景更加广泛,比如除了innodb适合事务处理场景外,myisam适合静态数据的查询场景。
MariaDB是MySQL的一个开源分支,速度更快,提供更多存储引擎 (12),但功能有限,MariaDB 不支持数据屏蔽或动态列表
高可用
- 主备延迟:强制走主,sleep
- 分库分表:唯一主键

若有收获,就点个赞吧
0 人点赞
