内存区域
也叫运行时数据区/内存结构,即JVM内存区域/运行时数据区,共享和私有非绝对
JVM在运行Java程序时会将内存划分为若干区域,根据Java虚拟机规范规定,大体分为线程共享数据区和线程隔离数据区
线程共享数据区包括Heap堆,Method Area方法区(1.6以后逐步淘汰替换为MetaSpace元空间)
线程隔离区域包括虚拟机栈、本地方法栈、程序计数器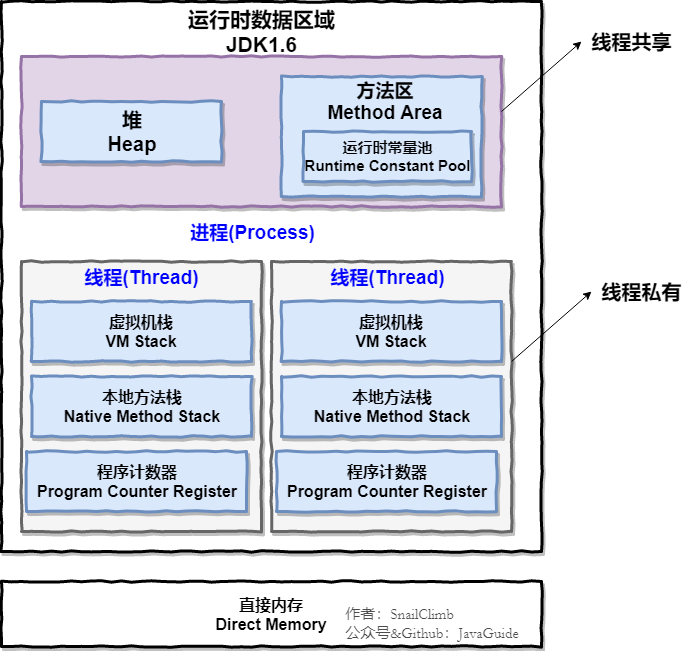
线程共享数据区
- 堆区
- 一般是最大的一块,绝大多数对象在这块区域分配内存(特例:栈上分配、标量替代)
- -Xmx/-Xms控制
非堆(方法区(运行时常量池))=>元空间【1.8】
虚拟机栈/本地方法栈
方法执行创建一个栈帧- 局部变量表bbcsilfdr【编译期确定大小】
- 操作数栈
- 动态链接
- 方法出口
程序计数器
- 当前程序所执行的字节码行号指示器/本地方法是为undefined
-
直接内存
mmap:FileChannel.map是java层的提供的文件映射方法,最终返回的是MappedByteBuffer类,MappedByteBuffer类是Java层提供给开发人员对文件映射内存访问和操作的统一视图,它封装了基地址addr、映射的数据size、文件描述符mfd、内存回收时的回调Unmapper,这种方式有两次DMA copy,和一次的CPU copy,但是用户态到内核态的切换(上下文切换)依旧有四次
- transferTo(带有DMA收集拷贝功能的sendfile)它与mmap的区别就是少了两次应用程序与内核之间上下文切换和1次CPU拷贝
- 对比
CAFEBABE、类的版本、常量池、类、接口、字段、方法
魔数(4)+次版本号(2)+主版本号(2)+常量池容量(2)+[字面量(文本字符串+final常量+基本数据类型的值等)+符号引用(类/接口全限定名、字段的名称和描述符、方法的名称和描述符)]n+访问标志(2)+类索引(2)+父类索引(2)+接口_interface计数器(2)+接口索引(2)_n+字段field表集合(访问标志2+简单名称索引2+描述符索引2+属性表集合可选)+方法method表集合(访问标志2+简单名称索引2+描述符索引2+属性表集合Code属性存方法代码)
属性attribute表集合=名称索引(2)+长度(4)+info
描述符:
String[][] ->[[Ljava/lang/String;
int[] -> [I
func() -> ()V
类的加载机制?
- 生命周期
- 加载:生成一个class对象
- 连接
- 验证:文件格式、元数据、字节码、符号引用
- 准备:默认值、static会分配内存
- 解析:具体类的信息,引用等
- 初始化:父类没初始化先初始化父类
- 使用
- 卸载
- 加载方式:main()、class.forName、ClassLoader.loadClass
- 类加载器:BootstrapClassLoader、ExtensionClassLoader、ApplicationClassLoader、User Defined ClassLoader
- 双亲委派原则(父类加载,避免重复加载、安全)
加验准解初使卸
(加验准解初使卸载)加载->连接(验证->准备->解析[可延后])->初始化->使用->卸载
加载:通过全限定名获取二进制流、静态结构转为运行时数据结构、生成Class对象
验证:文件格式、元数据、字节码、符号引用验证
准备:类变量分配内存、类变量初始化值
解析:常量池中符号引用转为直接引用
初始化:执行
https://blog.csdn.net/xiaoyami/article/details/109992002
什么是双亲委派模型?
BEAU
启动类加载器(Bootstrap ClassLoader)【虚拟机唯一自带】
扩展类加载器(Extension ClassLoader)
应用类加载器(Application ClassLoader)
自定义类加载器(User ClassLoader)
组合关系
破坏:Tomcat
Common
Catalina | Shared(WebApp、Jsper)
Java对象
普通对象创建过程
普通对象不包括数组和Class对象
一般指new的过程
- 类加载检查-分配内存-初始化零值-设置对象头-执行init方法
- 分配内存方法:指针碰撞(内存规整)、空闲列表(内存不规整)
- 内存分配并发问题:CAS+失败重试、TLAB
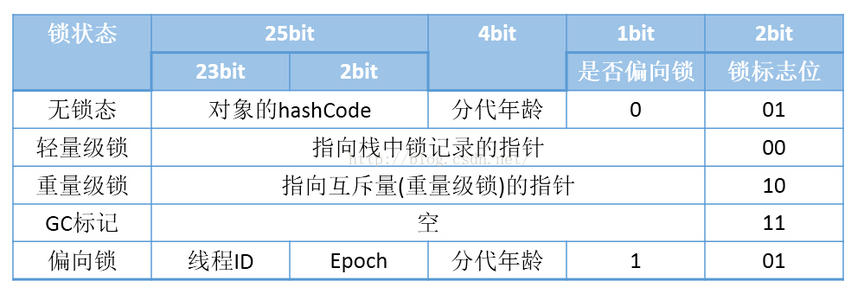
- 对象=对象头(Mark Word+KClass Pointer+数组长度(数组对象独有))+实例数据+对齐填充
- Mark Word
- 检查:new参数对应的常量池中的符号引用对应的类是否加载、解析、初始化(没有先执行加载)
- 分配内存:指针碰撞(CAS+失败重试防止并发问题;本地线程分配缓存TLAB)、空闲列表(GC是否带压缩整理决定)
- 初始化零值:可提前到TLAB中使用
- 必要的对象头设置
- 对象的初始化(
) 对象在内存如何布局?
对象=对象头+实例数据+对齐填充(可选)
- 对象头=Mark Word+类型指针(可选)+数组长度(数组对象)
Mark Word (TODO)
普通对象:hashcode(25)+age(4) - 实例数据:各种类型的字段,第一原则:相同宽度的数据放一起;第二原则:先父后子
-
对象如何访问?
句柄(单独空间存储实例数据指针和类型数据指针,移动修改简单)、直接指针(直接存实例对象地址,实例对象中有类型数据指针,速度快)
Object有哪些常用方法?
cfgehtnnw
Object clone() 创建与该对象的类相同的新对象
- void finalize() 当垃圾回收器确定不存在对该对象的更多引用时,对象垃圾回收器调用该方法
- Class getClass() 返回一个对象运行时的实例类
- boolean equals(Object) 比较两对象是否相等
- int hashCode() 返回该对象的散列码值
- String toString() 返回该对象的字符串表示
- void notify() 激活等待在该对象的监视器上的一个线程
- void notifyAll() 激活等待在该对象的监视器上的全部线程
- void wait() 在其他线程调用此对象的 notify() 方法或 notifyAll() 方法前,导致当前线程等待
JVM常用参数
《深入理解Java虚拟机》P90
堆
-Xms(堆初始)与-Xmx(堆最大)相等避免堆自动扩展
-Xmn(新生代)
-XX:NewRatio 设置新生代和老年代的比值
-XX:SurvivorRatio Eden和Survivor区的比例
-XX:MaxTenuringThreshold 设置转入老年代的存活次数。如果是0,则直接跳过新生代进入老年代
-XX:PretenureSizeThreshold 直接晋升老年代的对象大小
-XX:+UseAdaptiveSizePolicy 动态调整Java堆中各个区域的大小以及进入老年代的年龄
-XX:+HandlePromotionFailure 是否允许担保失败
-XX:PermSize、-XX:MaxPermSize 分别设置永久代最小大小与最大大小(Java8以前)
-XX:MetaspaceSize、-XX:MaxMetaspaceSize:分别设置元空间最小大小与最大大小(Java8以后)
栈
GC
收集器设置
-XX:+UseSerialGC 设置串行收集器
-XX:+UseParallelGC 设置并行收集器
-XX:+UseParalledlOldGC 设置并行老年代收集器
-XX:+UseConcMarkSweepGC 设置并发收集器
GC统计
-XX:+PrintGC
-XX:+PrintGCDetails 打印GC详情
-XX:+PrintGCTimeStamps
-Xloggc:filename
-XX:+HeapDumpOnOutOfMemoryError 开启OOM堆转储快照
并行收集器设置
-XX:ParallelGCThreads=n 设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n 设置并行收集最大暂停时间
-XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
并发收集器设置
-XX:+CMSIncrementalMode 设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n 设置并发收集器新生代收集方式为并行收集时,使用的CPU数。并行收集线程数
JVM垃圾回收
分代
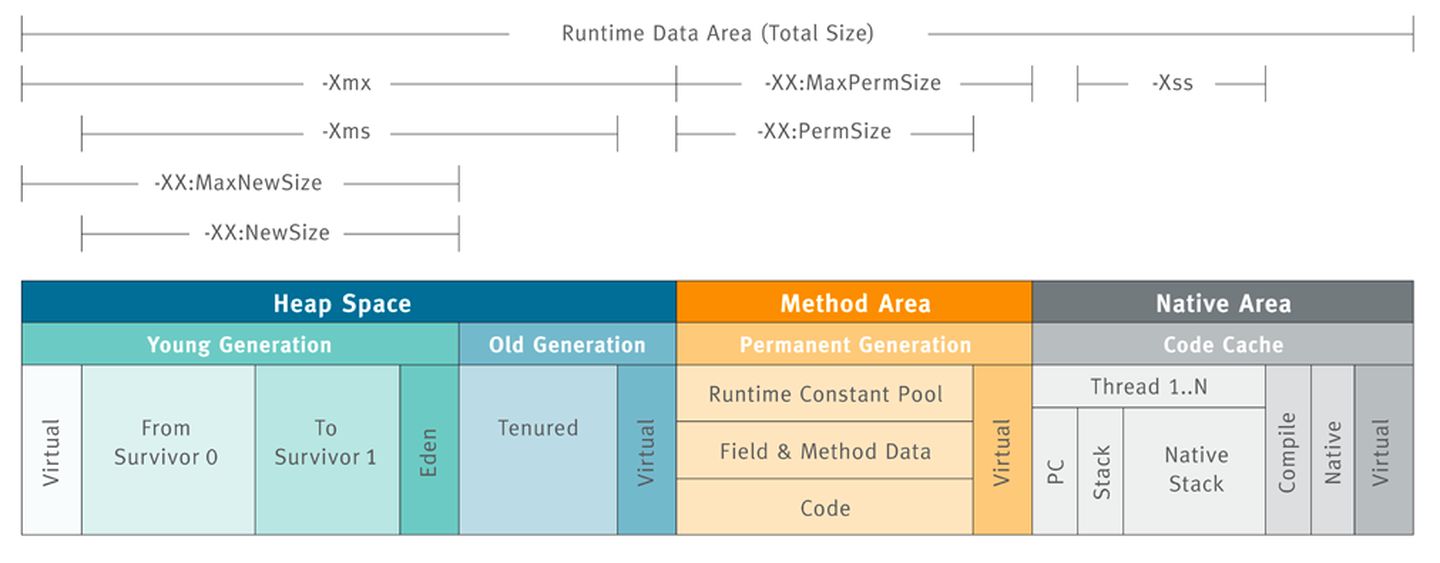
- 新生代(Eden、From/S0、To/S1)Minor GC
- 老年代 Major GC=Full GC
-
存活性判断
引用计数法(循环引用)
可达性分析(GCRoots:寄存器/活跃线程、虚拟机栈[栈帧的本地变量表]、全局变量空间[方法区类静态属性、方法区常量变量]、本地方法栈中JNI[Native方法])
Java使用的GC机制
标记清除(效率、空间):对象存活多、老年代;提前GC、碎片空间、扫描两次
- 标记复制:对象存活少、扫描整个空间、年轻代;需要空闲空间、需要复制移动对象
-
强软弱虚
Full GC发生的时机:老年代写满、system.gc()、持久代空间不够
- Hotspot垃圾回收器
- 新生代:Serial、ParNew、Parallel Scaveage
- 老年代:CMS(CPU敏感、浮动垃圾、空间碎片)、Serial Old(MSC)、Parallel Old
- 跨新老:G1(弱化分代、标记整理、预设停顿、利用多核减少STW;young gc、mixed gc;-XX:G1HeapRegionSize)、ZGC
标记算法
- 引用计数法:缺点难以解决相互引用问题
- 可达性分析
GC算法:
- 标记-清除算法(Mark-sweep):
适用:对象存活比较多,老年代
缺点:提前GC、扫描两次效率低、空间碎片 - 复制算法:
适用:存活对象少,扫描整个空间,年轻代
缺点:空间利用率低,复制移动效率低
优化:Eden(8)+Survivor(1+1),缺点时需要老年区进行分配担保 - 标记-整理算法:一般用在老年代
分代收集
GC Roots包括:
- 虚拟机栈本地变量表中引用对象
- 本地方法栈中JNI(Native方法)引用的对象
- 方法区类静态属性/常量引用的对象
四种引用:强软弱虚
finalize:可以完成自我拯救(只有一次机会),F-Queue
Hotspot GC算法优化
OopMap:记录哪些地方是引用,避免全局扫描
安全点:主动式中断(方法调用、循环跳转、异常跳转)
安全区域:线程睡眠或者挂起等情况下,引用关系不会变,随时可以GC,如果GC Roots遍历未完成得等待完成后才能离开安全区域
垃圾回收器种类
Young:Serial、ParNew、Parallel Scavenge(1.8):
Tenured:CMS、Serial Old(MSC)、Parallel Old(1.6之后1.8默认)
G1(9)、ZGC(11)、Shenandoah(12)-STW低于10ms,TB支持
Zing(Azul C4无STW)
Epsilon(11)
Serial/Serial Old:STW单线程运行GC
ParNew:多线程版Serial
CMS:
- 过程:最短回收停顿,初始标记(STW)-并发标记-重新标记(STW)-并发清除
- 缺点:CPU资源敏感、无法处理浮动垃圾、需要预留空间、碎片较多
- 默认线程数:(CPU数量+3)/4,老年代使用了68%就会被激活
Parallel Scavenge(PS):吞吐量优先,高效利用CPU时间,可开启GC自适应调节策略(复制)
Parallel Old:标记-整理
G1:
- 特点:
- 并发并行:缩短STW、高吞吐
- 空间整合:化整为零用分区进行分代收集没有内存碎片、分配大对象不会提前full gc
- 可预测的停顿
- 分区:自由分区、新生代分区(Eden和Survivor)、大对象分区(大对象头分区和大对象连续分区)、老年代分区
- 卡表(Card Table):512字节的卡设置标志位是否脏(存在新生代对象引用)脏卡放入GC Roots(截获引用型实例变量写操作),是记忆集合(RSet)的具体实现
- 步骤:初始标记(STW)-并发标记-最终标记(STW)-筛选回收(STW)
- 回收模式:young gc/mixed gc
- +UserG1GC/G1HeapRegionSize
Remember Set避免全堆扫描CardTable。
ZGC:染色指针
动态对象年龄判断:相同年龄的所有对象大小总和大于Survivor空间的一半,年龄大于等于该年龄都进老年代
什么情况下会full gc
- 老年代写满
- system.gc()
- 持久代空间不足
- 通过Minor GC后进入老年代的平均大小大于老年代的可用内存
由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
JVM性能调优
常见场景
问题现象分类->根据分类猜想原因->通过工具/实验验证猜想->问题方案
- StackOverflow
- 无限递归->添加返回条件
- 栈过深->是否可以修改成非递归,改栈的大小
- OOM几种情况
- 内存泄漏(GC后不能回到原来水平)
- 大对象不断产生且生命周期过长
- OOM解决方案
- help dump、生产机dump、mat、jmap、-helpdump
- 优化代码
- JVM调优
- 加内存
- CPU过高的几种情况
- 线程死锁
- 锁争用/活锁
- 死循环
- CPU过高解决方案
- 查看是否是Java导致的
- 看日志是否有报错
- Java进程消耗CPU过高(topc -c、top -Hp pid、jstack进制转换、cat)
- 卡顿
- 锁争用
- 垃圾回收频繁(调整JVM参数Ratio等)
- 服务器网络磁盘硬件性能
- 其他框架(数据库、中间件)
- 卡顿解决方案
- 查看CPU、内存、网络带宽占用等参数状态,猜想问题在哪里
- 系统层面优化,比如加大fd
- 从前端->后端->数据库查找性能瓶颈在哪里
- 针对OOM和内存泄漏问题
- 基本原则:减少gc次数和stw时间
- 可能情况:
- 长时间失去响应(GC停顿)
- 大对象多->64位JDK大内存
- 内存溢出
- 长时间失去响应(GC停顿)
- 线程死锁/锁争用导致Java进程CPU过高
方法一- top
- 查看进程内最耗费CPU的线程
top -Hp pid - 该进程id是10进制的,需要转为16进制
printf “%x” PID - jstack PID | grep 54ee或者导出到文件jstack PID > xxx.log
- 4、分析栈文件,查询文件中线程状态:
java.lang.Thread.State:
BLOCKED过多:表示程序中有死锁的代码
RUNNABLE过多:表示程序一直在处理,检查是否有死循环
WAITING:无限等待另一个线程执行一个特定动作
关注WAITING ,BLOCKED的地方 可以初步定位到问题所在
方法二 - jmap导出top中cpu最高PID 的dump文件
注意点:JVM 生成 Heap Dump 的时候,虚拟机是暂停一切服务的。如果是线上系统执行 Heap Dump 时需要注意
导出整个JVM 中内存信息
jmap -dump:live,format=b,file=/文件路径/heap-dump.bin PID - 分析dump文件
使用JDK下的jvisualvm.exe工具分析。 排查非基本数据类型 实例数和内存占用较高的包。定位到业务代码
【建议每次间隔一段时间,便导出dump文件,多个文件对比分析,单次的dump文件参考意义不大】
方法:
- 设置堆的最大最小值:Xms Xmx
- 调整老年和年轻代比例:newSize
- 查看是否存在更多持久对象和临时对象
- 观察一段时间 看峰值老年代如何,不影响GC就加大年轻代
- 配置好的机器可以用并发收集算法
-
调优技巧
设置堆:-xms、-xmx
- 调整老年代和新生代比例:-XX:newSize设置绝对大小
- 是否存在很多持久对象和临时对象
- 峰值老年代情况,不影响GC就加大年轻代
- 配置好的机器可以用并发收集算法
- 每个线程默认会开启1M的堆栈存放栈帧 调用参数 局部变量太大了 500k够了
-
性能检测工具
常用:dump、自动dump、dump分析
- jps、jinfo、jstat、jstack、jmap、jhat
- jconsole,jvisualvm、jprofiler、MAT
阿里Arthas
《深入理解Java虚拟机》P103
jps
- jstat
- jinfo
- jmap
- jhat
- jstack
- HSDIS
- JConsole
- VisualVM
- javap
内存映像分析工具 Eclipse Memory Analyzer 判断是内存泄漏还是内存溢出
内存溢出或泄漏的检查工具
jasvism??
dump
java.lang.OutOfMemoryError: Java heap space java堆内存溢出。此种情况最常见,一般由于内存泄露或者堆的大小设置不当引起。对于内存泄露,需要通过内存监控软件查找程序中的泄露代码,而堆大小可以通过虚拟机参数-Xms,-Xmx等修改
- java.lang.OutOfMemoryError: PermGen space 永久代溢出。即方法区溢出了,一般出现于大量Class或者jsp页面,或者采用cglib等反射机制的情况,因为上述情况会产生大量的Class信息存储于方法区。此种情况可以通过更改方法区的大小来解决,使用类似-XX:PermSize=64m -XX:MaxPermSize=256m的形式修改。另外,过多的常量尤其是字符串也会导致方法区溢出
java.lang.StackOverflowError ———> 不会抛OOM error,但也是比较常见的Java内存溢出。JAVA虚拟机栈溢出,一般是由于程序中存在死循环或者深度递归调用造成的,栈大小设置太小也会出现此种溢出。可以通过虚拟机参数-Xss来设置栈的大小
逃逸分析
子程序分配一个对象并返回一个该对象的指针,该对象可能在程序中被访问到的地方无法确定,这样指针就成功“逃逸”了
发生在JIT时候
https://www.cnblogs.com/dengchengchao/p/13255714.html
不能逃逸可做如下优化:对象栈上分配
- 分离对象或者标量替代(-XX:+DoEscapeAnalysis表示开启逃逸分析,JDK8是默认开启的)
- 同步锁粗化、锁消除

若有收获,就点个赞吧
0 人点赞
