配置
- centos7
- jdk8
- zookeeper3.5.5
- hadoop2.8.5
角色规划
| 服务器名称 | 服务器ip | 角色 |
|---|---|---|
| bigdata01 | 192.168.0.105 | namenode\datanode\zookeeper |
| bigdata02 | 192.168.0.106 | namenode\datanode\zookeeper |
| bigdata03 | 192.168.0.107 | datanode\zookeeper |
一、环境准备
1.1 物理环境
- 3台或以上服务器
- 给服务器配置静态ip(动态ip也行)
vim /etc/sysconfig/network-scripts/ifcfg-eth0
BOOTPROTO=staticONBOOT=yesIPADDR=192.168.0.105NETMASK=255.255.255.0GATEWAY=192.168.0.1
- 配置hostname
vim /etc/hostname
- 配置hosts
vim /etc/hosts
192.168.0.105 bigdata01192.168.0.106 bigdata02192.168.0.107 bigdata03
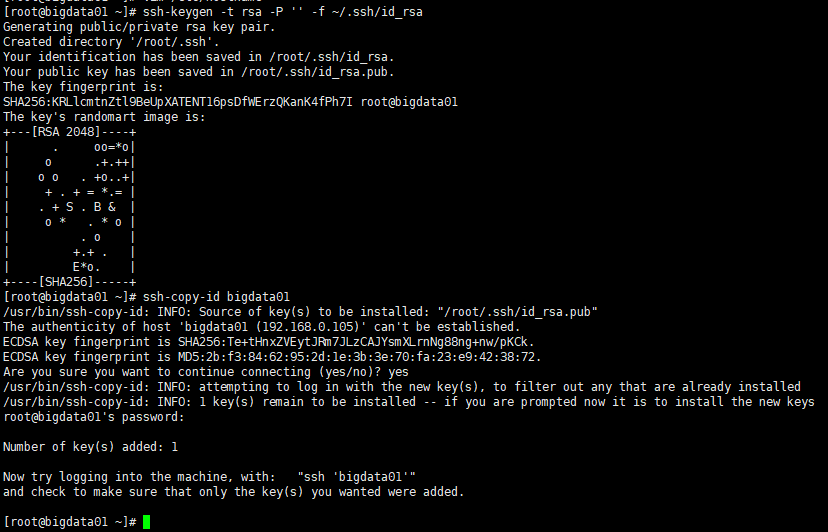
- 节点间ssh免密钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsassh-copy-id + 主机名
- 时间同步
# 检查是否安装ntprpm -q ntp# 安装yum -y install ntp# 开机自启systemctl enable ntpd# 启动systemctl start ntpd# 同步服务器ntpdate -u ntp1.aliyun.com# 配置# 主节点vim /etc/ntp.conf
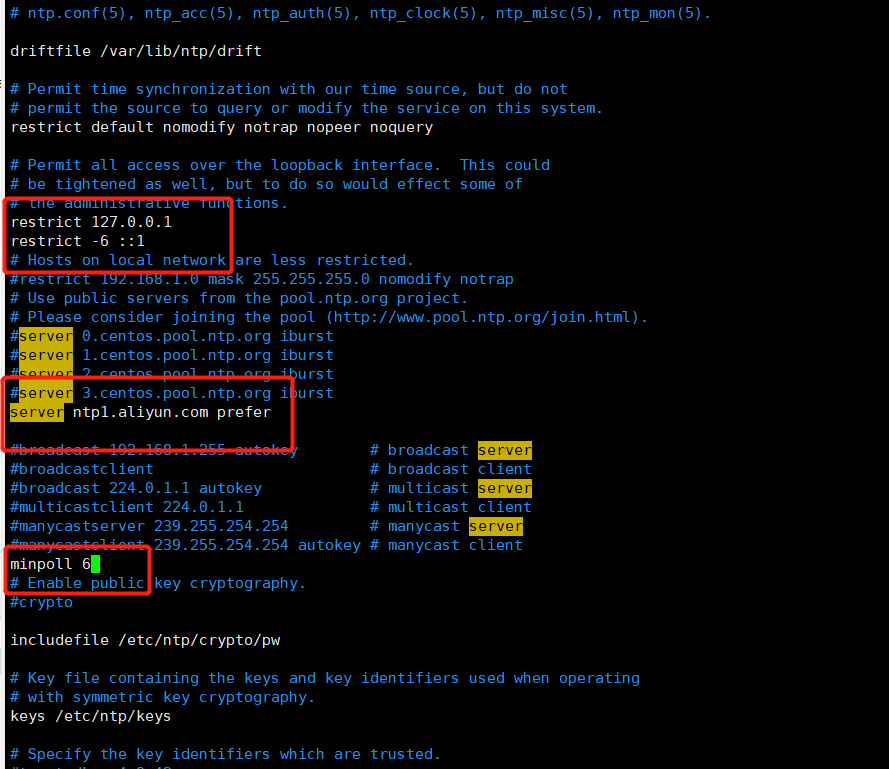
从节点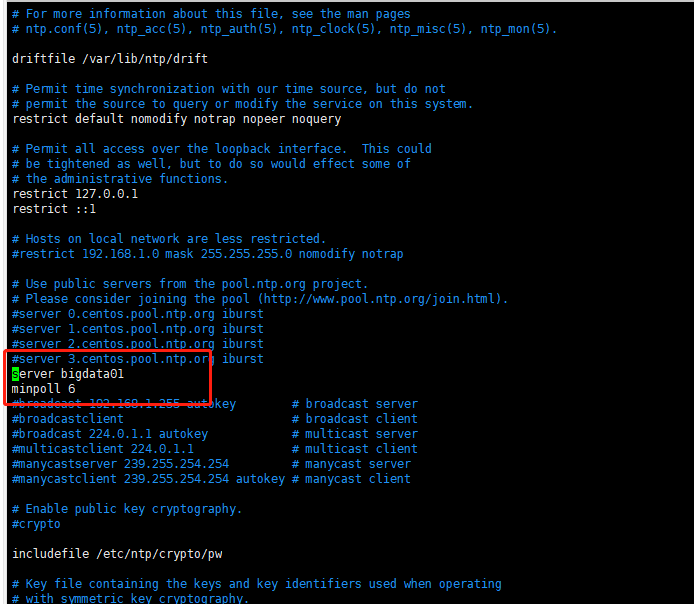
# 重新启动service ntpd restart# 开机启动chkconfig ntpd on查看时间同步情况ntpq -p
**
1.2 软件环境
- jdk8+
# 安装步骤不会的自行百度# 配置环境变量export JAVA_HOME=/usr/java/jdk1.8export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jarexport PATH=$PATH:${JAVA_HOME}/bin
- zookeeper
安装
# 下载解压tar zxvf apache-zookeeper-3.5.5-bin.tar.gz -C /optcd /opt# 重命名mv apache-zookeeper-3.5.5-bin zookeeper
配置
# 1、zoo.cfgcp zoo_sample.cfg zoo.cfgvim zoo.cfg
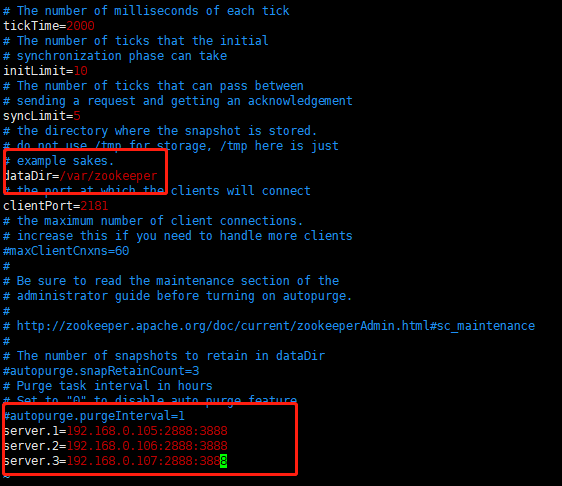
# 2、myidmkdir -p /var/zookeeperecho 1 > /var/zookeeper/myid
配置环境变量
配置环境变量vim /etc/profileexport ZOOKEEPER_HOME=/opt/zookeeperexport PATH=$PATH:$ZOOKEEPER_HOME/binsource /etc/profile# 启动zkServer.sh start# 查看状态zkServer.sh status
二、开始安装hadoop
2.1 解压安装
tar zxvf hadoop-2.8.5.tar.gz -C /opt
2.2 配置
2.2.1 hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8
2.2.2 mapred-env.sh
export JAVA_HOME=/usr/java/jdk1.8
2.2.3 yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8
2.2.4 hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.nameservices</name><value>mycluster</value></property><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>bigdata01:8020</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>bigdata02:8020</value></property><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>bigdata01:50070</value></property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>bigdata02:50070</value></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://bigdata01:8485;bigdata02:8485;bigdata03:8485/mycluster</value></property><property><name>dfs.journalnode.edits.dir</name><value>/var/hadoop/ha/jn</value></property><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property></configuration>
2.2.5 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/ha</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>bigdata01:2181,bigdata02:2181,bigdata03:2181</value>
</property>
</configuration>
2.2.6 mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2.2.7 yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>bigdata02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>bigdata03</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>bigdata01:2181,bigdata02:2181,bigdata03:2181</value>
</property>
2.2.8 slaves
bigdata01
bigdata02
bigdata03
2.3 分发到各节点
scp -r hadoop-2.8.5 bigdata02:/opt
scp -r hadoop-2.8.5 bigdata03:/opt
2.4 启动zookeeper(所有节点)
zkServer.sh start
2.5 启动journalnode(所有节点)
/opt/hadoop-2.8.5/sbin/hadoop-daemon.sh start journalnode
2.6 格式化(主节点)
/opt/hadoop-2.8.5/bin/hdfs namenode -format
格式化完成后主节点启动namenode
/opt/hadoop-2.8.5/sbin/hadoop-daemon.sh start namenode
2.7 备节点同步主节点元数据(备节点)
/opt/hadoop-2.8.5/bin/hdfs namenode -bootstrapStandby
2.8 格式化zookeeper(主节点)
/opt/hadoop-2.8.5/bin/hdfs zkfc -formatZK
2.9 配置环境变量(所有节点)
vim /etc/profile
export HADOOP_HOME=/opt/hadoop-2.8.5
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
2.10 启动
# 启动hdfs
start-dfs.sh
# 启动resourcemanager(2、3节点)
yarn-daemon.sh start resourcemanager
之后每次的启动顺序
启动zookeeper
zkServer.sh start(node01 node02 node03)
启动hdfs
start-dfs.sh
启动yarn
start-yarn.sh
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start resourcemanager
hdfs-namenodeweb界面
http://192.168.0.105:50070/
yarn-resourcemanagerweb界面
http://192.168.0.106:8088/cluster

若有收获,就点个赞吧
0 人点赞
