一、大数据基础
1.1 基本概念
1.1.1 数据分析
数据分析是基于商业目的,有目的的进行收集、整理、加工和分析数据,提炼有价值信息的过程。
1.1.2 数据仓库
数据仓库是一个面向主题的( Subject Oriented)、集成的( ntegrated)、非易失的( Non -Volatil e)、时变的( Time variant)数据集合,用于支持管理决策。
数据仓库解决的问题:
1、为业务部门提供准确及时的报表
2、为管理人员提供更强的分析能力
3、为数据挖掘和知识发现奠定基础
1.1.3 大数据
大数据( Big Data),指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据的特点
1.1.4 云计算与大数据
云计算提供存储和计算的基础设施,大数据则是运用在其上的应用。
1.1.5 大数据的处理思路
减治:将问题化简成一个更简单的能处理的问题
分治:将问题拆分成多个可以简单求解的小问题
1.1.6 大数据计算技术
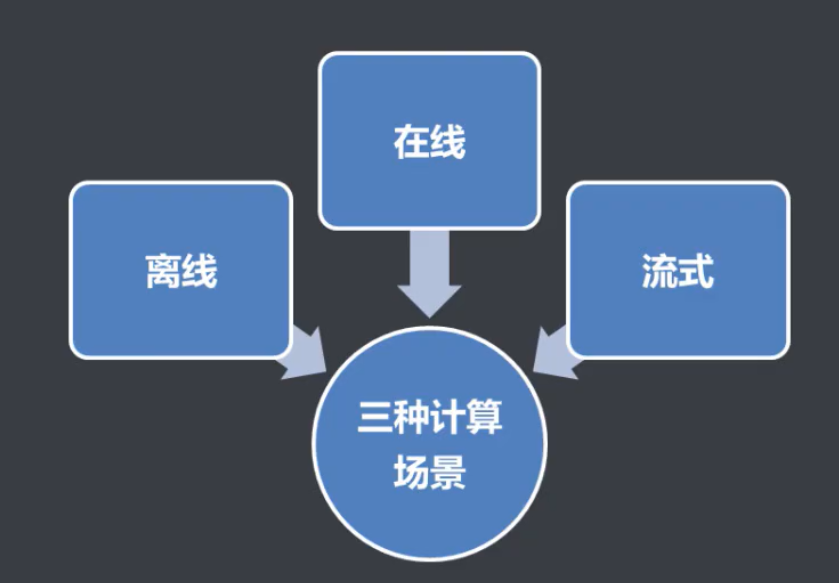
1.1.7 大数据应用常见场景

1.2 阿里云大数据产品
1.2.1 产品体系概况
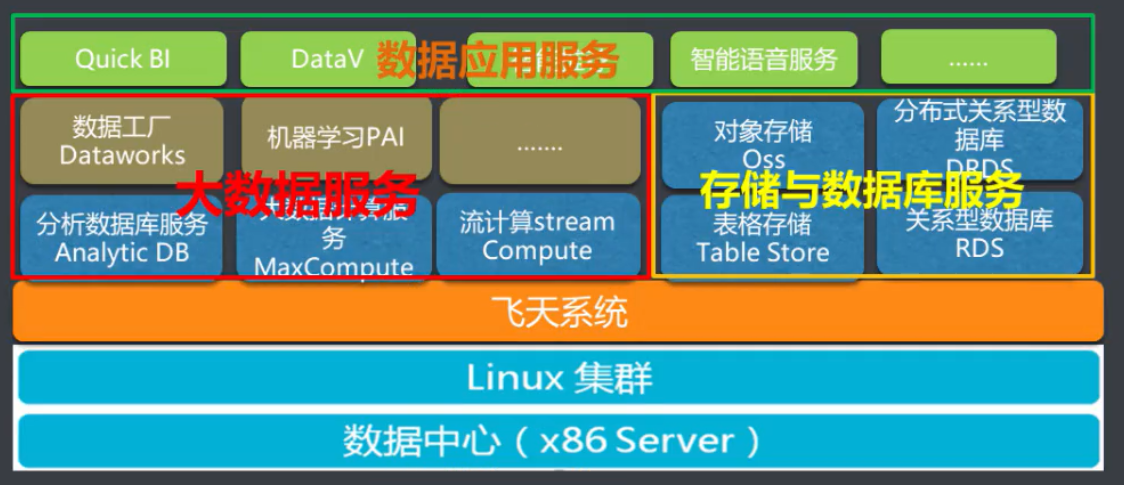
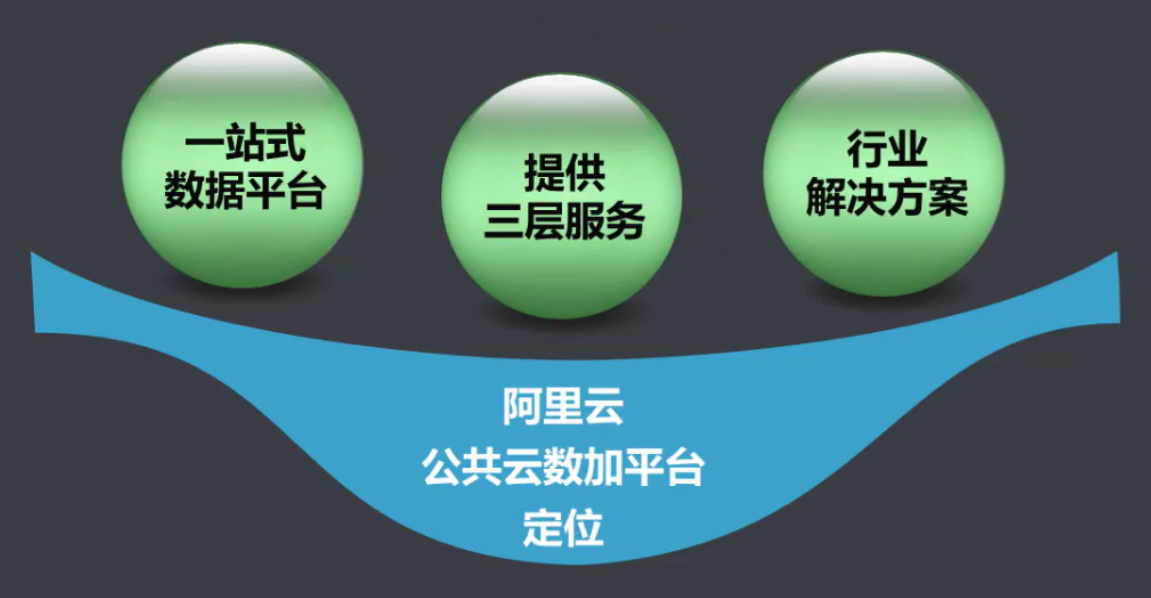
1.2.2 公共云数加平台
1.2.3 基础产品
1.2.3.1 云数据库RDS
ApsaraDB for RDS(简称RDS):
- 稳定可靠、可弹性伸缩的在线数据库服务
- 即开即用,DMS可视化界面
- 兼容 MySQL、 SQL Server、PG等关系型数据库
- 提供数据库在线扩容、备份回滚、性能监控及分析等功能
- 只读实例和临时实例
优势:
- 双机热备:秒级切换,服务可用性达9995%
- 安全防护:防DDoS攻击,SQL注入告警,数据多重备份
-
1.2.3.2 分布式关系型数据库DRDS
Distribute Relational Database Service, 简称DRDS:
基于RDS的分布式数据存储和检索产品
- 水平拆分,可平滑扩容
- 解决用户单RDS无法支撑业务的苦难
- 降低用户使用分布式数据库的难度
优势:
- 简单易用:兼容 MySQL(交互协议、SQL)
- 稳定可靠:共享阿里TDDL、 CORBA组件
- 分布式:水平拆分,容量达单节点百倍
-
1.2.3.3 表格存储TS
Table store(简称TS)
构建在阿里云飞天分布式系统之上的 NOSQL数据存储服务
- 海量结构化数据的存储和实时访问
- 弹性资源预留
- 实时监控显示
优势:
- 稳定:自动故障检测与恢复,系统可用性99.9%
- 安全:用户级别的数据隔离、访问控制和权限管理,数据冗余备份
- 大规模:单表百TB级数据存储
-
1.2.3.4 分析型数据库
Analytic DB
海量数据实时高并发在线分析云计算服务
- 自由的计算和查询能力
- 高可用性和高安全性
- 全面兼容 MySQL协议
优势:
- 高度的计算自由:通过SQL灵活进行多维分析、数据透视数据筛选等
- 极速的响应时间:毫秒级的千亿级数据透视,毫秒级的大表关联计算
- 简单的使用方式:标准SQL,支持标准 MySQL协议,内置多种云产品的数据输入/输出
-
1.2.3.5 大数据计算服务
Max Compute原名ODPS:
针对TB/PB级数据、实时性要求不高的分布式处理能力
- 大数据运算能力
- 开箱即用
- 数据安全
优势:
- 分布式:分布式集群架构,可灵活扩展
- 安全性:自动存储容错机制,所有计算都在沙箱中迸行
- 易用性:全面支持基于Sα的数据处理,提供标准APl,高并发高吞吐量的数据上传下载
管理与授权:多用户管理协同分析数据,多种方式对用户权限管理,灵活的数据访问控制策略
1.2.3.6 数据集成
Data Integration:
是阿里集团对外提供的稳定高效、弹性伸缩的数据同步平台,为阿里云大数据计算引擎提供的离线(批量)数据进出通道。
优势:
多:支持数据源种类多,多样数据通道、齐全的数据传输方式、丰富数据处理插件
快:高效的调用方式、强劲的传输速度、强大的吞吐力
好:健壮的传输通道、智能的错误检测、自动的传输恢复
省:开箱即用、动态分配、弹性伸缩、按霈申请、按量付费1.2.3.7 对象存储
Object Storage Service(简称OSS):
提供海量、安全、低成本、高可靠的云存储服务
- 一个即开即用,无限大空间的存储集群
- 通过API/SDK接口或OSS迁移工具方便将海量数据移入或移出
- 存储对象操作具有原子性、强致性
优势:
- 可靠:服务可用性99.99%,数据持久性99.99999999%,多重备份,规模自动扩展
- 安全:用户级别的资源隔离、异地容灾,企业级多层安全防护,多种授权机制
- 低成本:多线GBP骨干网络,无带宽限制,上行流量免费
多种类数据处理能力:图片处理、音视频转码、内容加速分发、鉴黄服务、归档服务等
1.2.3.8 大数据开放平台
DataWorks(原名称 Data IDE):
数据工场 DataWorks(原大数据开发套件 Data IDE)是基于MaxCompute作为计算和存储引擎的用于工作流可视化开发和托管调度运维的海量数据离线加工分析平台
优势:专业:阿里多年DW/Bl经验沉淀,全链路解决方案,高效率低成本
- 功能强大:集成式组件服务,多种异构数据源攴持,多人协同代码开发,完善的版本管理、分钟、小时级调度、拖拽式数据分析、拖拽式可视化算法建模
- 大数据处理能力:完美融合 MaxCompute,支持十万级任务的有序运行与管理
1.2.3.9 Quick Bl:
Quick BI提供海量数据实时在线分析服务,支持拖拽式操作、提供了丰富的可视化效果,可以帮助您轻松自如地完成数据分析、业务数据探査、报表制作等工作。
优势:
- 门槛低:拖拽操作,简单易用
- 功能强:多样的解决方案,丰富的展现手段
- 大数据处理能力:数据分析、处理能力强大
1.2.3.10 阿里云机器学习简称PAl:
基于 MaxCompute、GPU集群,支持MR、MPl、SQL、BSP SPARK等计算类型内置阿里、蚂蚁多年沉淀的分布式算法,支持百亿级数据量训练WEB界面,通过拖、拉、拽等方式即可完成复杂数据挖掘流程
优势

若有收获,就点个赞吧
0 人点赞
