一、基本概念
1、Flink简介
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
Flink是一个有状态的分布式计算框架,处理对象是有界的和无界的数据流
任何数据都可以转化为有界流或无界流来处理
- 有界流(流处理):有始无终
- 2.无界流(批处理):有始有终
2、Flink Application
了解 Flink 应用开发需要先理解 Flink 的 Streams、State、Time 等基础处理语义以及 Flink 兼顾灵活性和方便性的多层次 API。
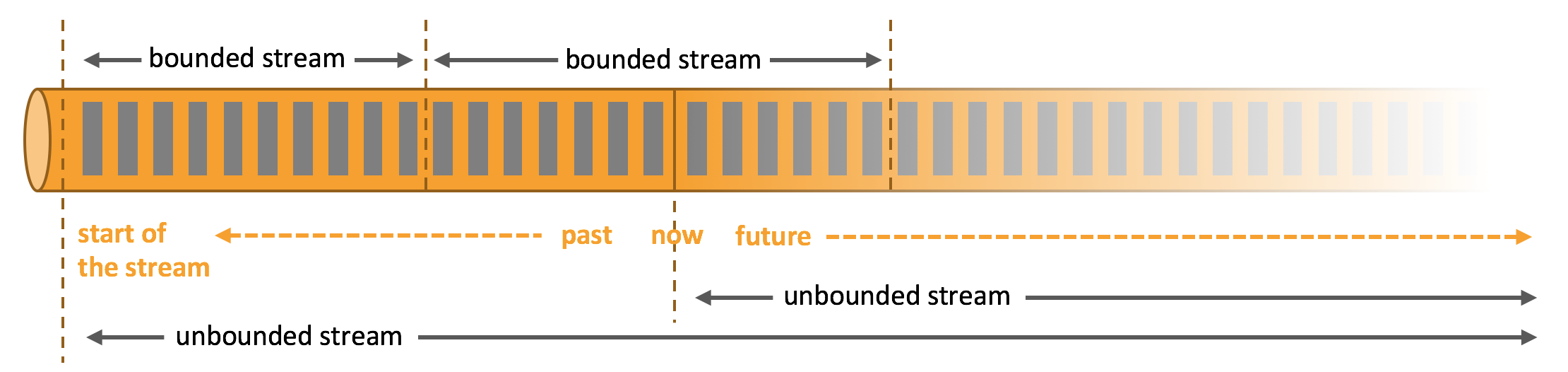
- Streams:流,分为有限数据流与无限数据流,unbounded stream 是有始无终的数据流,即无限数据流;而 bounded stream 是限定大小的有始有终的数据集合,即有限数据流,二者的区别在于无限数据流的数据会随时间的推演而持续增加,计算持续进行且不存在结束的状态,相对的有限数据流数据大小固定,计算最终会完成并处于结束的状态。
- State,状态是计算过程中的数据信息,在容错恢复和 Checkpoint 中有重要的作用,流计算在本质上是 Incremental Processing,因此需要不断查询保持状态;另外,为了确保 Exactly- once 语义,需要数据能够写入到状态中;而持久化存储,能够保证在整个分布式系统运行失败或者挂掉的情况下做到 Exactly- once,这是状态的另外一个价值。
- Time,分为 Event time、Ingestion time、Processing time,Flink 的无限数据流是一个持续的过程,时间是我们判断业务状态是否滞后,数据处理是否及时的重要依据。
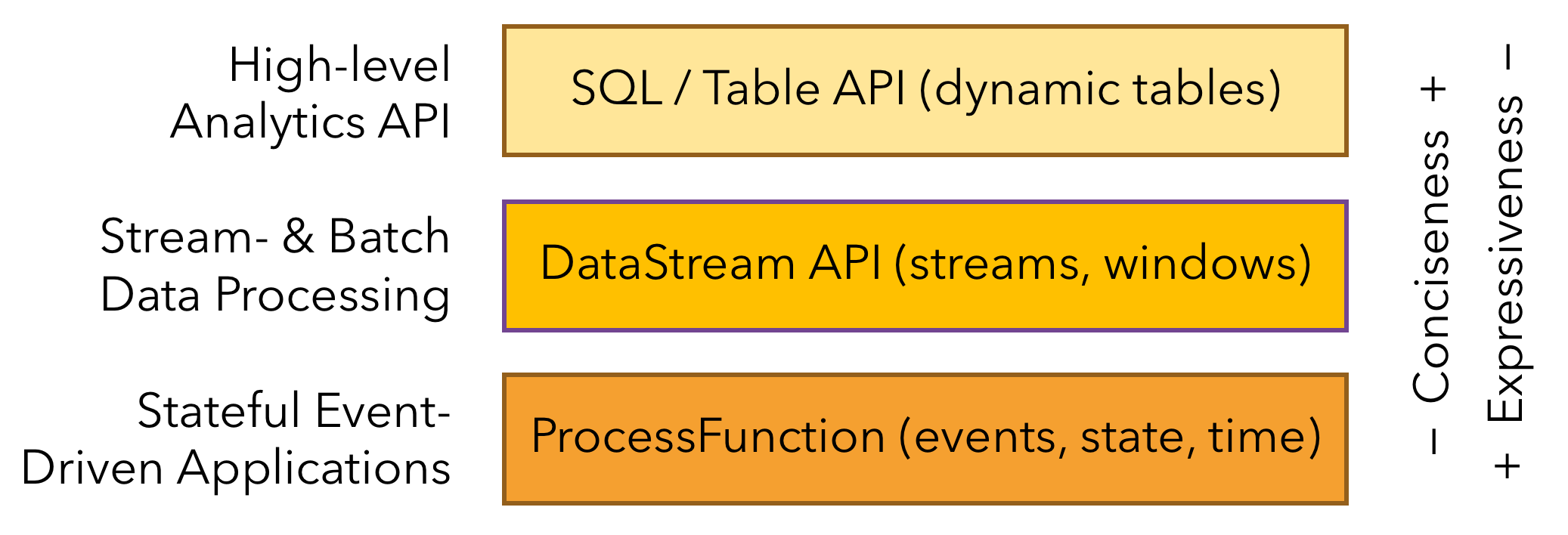
- API,API 通常分为三层,由上而下可分为 SQL / Table API、DataStream API、ProcessFunction 三层,API 的表达能力及业务抽象能力都非常强大,但越接近 SQL 层,表达能力会逐步减弱,抽象能力会增强,反之,ProcessFunction 层 API 的表达能力非常强,可以进行多种灵活方便的操作,但抽象能力也相对越小。
二、架构
- 分层API
三、使用
3.1 flink程序编程步骤
- 设置运行环境
- 配置数据源,获取数据
- 一系列操作转换数据
- 配置数据输出,保存数据
- 提交执行
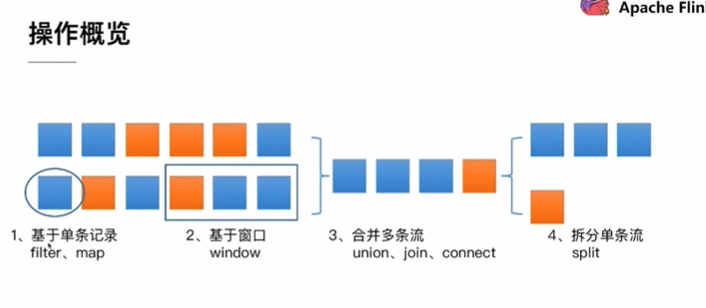
3.2 数据的操作概览
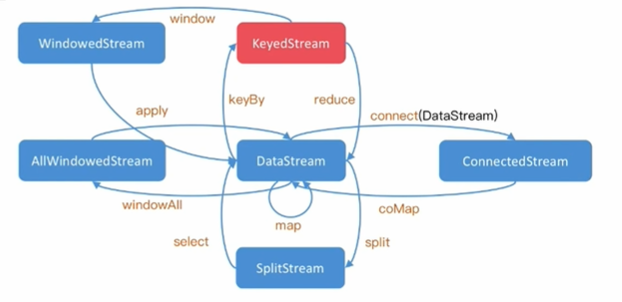
3.3 DataSream的基本转换
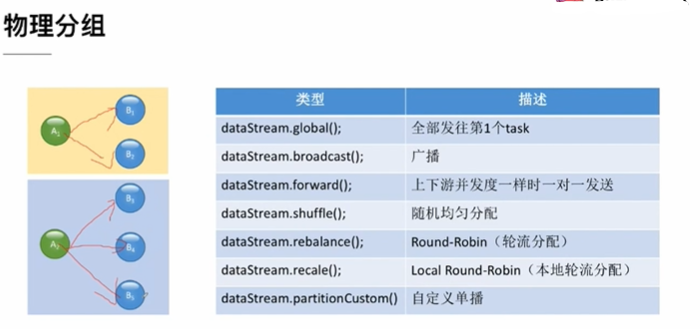
3.4 基本分组策略
3.5 数据类型
- 类型系统

- Flink支持的数据类型
- Java Tuple
Java API 提供了从Tuple1到Tuple25的类
DataStream<Tuple2<String, Integer>> wordCounts = env.fromElements(new Tuple2<String, Integer>("hello", 1),new Tuple2<String, Integer>("world", 2));wordCounts.map(new MapFunction<Tuple2<String, Integer>, Integer>() {@Overridepublic Integer map(Tuple2<String, Integer> value) throws Exception {return value.f1;}});wordCounts.keyBy(0); // also valid .keyBy("f0")
- Java POJOs
java的类在满足以下条件的时候会被Flink视为特殊的POJO数据类型:
- 这个类必须是公有的
- 它必须有一个公有的无参构造函数
- 所有参数都需要是公有的或提供get/set方法
- 参数的数据类型必须是Flink支持的
public class WordWithCount {
public String word;
public int count;
public WordWithCount() {}
public WordWithCount(String word, int count) {
this.word = word;
this.count = count;
}
}
DataStream<WordWithCount> wordCounts = env.fromElements(
new WordWithCount("hello", 1),
new WordWithCount("world", 2));
wordCounts.keyBy("word"); // key by field expression "word"
- Primitive Types
Flink支持Java所有的基本数据类型,例如Integer、String、Double
- values
Flink 支持大部分的Java类
- Hadoop Writables
- Special Types
3.6 批处理(DataSet)-有界流数据(bounded)
小例子-worldcount
//1、创建有界流(批处理)的执行环境 val env = ExecutionEnvironment.getExecutionEnvironment val params = ParameterTool.fromArgs(args) //2、配置数据源 val inputPath = params.get("D:\\workspace\\idea\\flinkdemo\\src\\main\\resources\\wc.txt") //3、获取数据并转换数据 val result = env.readTextFile(inputPath) .flatMap(_.split(" ")) .map((_,1)) .groupBy(0) .sum(1) //4、配置数据输出 // result.print() // result.print //数据转换+数据输出(打印到控制台) result.setParallelism(1).sortPartition(_._2,Order.DESCENDING).print //提交执行 //env.execute("wordcount")懒执行(Lazy Evaluation)
当Flink程序主方法执行的时候,数据加载和数据转换并没有立即执行,当execute()触发后执行
3.7 流处理(DataStream) - 无界流数据(unbounded)
- worldcount
//1、创建无界流(流处理)的执行环境 val env = StreamExecutionEnvironment.getExecutionEnvironment // 从外部接收参数 val params = ParameterTool.fromArgs(args) if(args.length <= 2){ println("输入参数 [host] [port]") println("--host 监听ip地址") println("--port 监听端口号") }else{ //2、配置输入源 val host = params.get("host") val port = params.getInt("port") //获取数据 val textDataStream = env.socketTextStream(host,port) //3、操作数据 val wcStream = textDataStream.flatMap(_.split("\\s")).filter(_.nonEmpty).map((_, 1)).keyBy(0).sum(1) //4、配置数据输出 wcStream.print //5、提交执行 env.execute("wc")
3.8 Table API & SQL、
1、Create a TableEnvironment
- 方式一:FLINK STREAMING QUERY ```scala import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.table.api.EnvironmentSettings import org.apache.flink.table.api.scala.StreamTableEnvironment
val fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build() val fsEnv = StreamExecutionEnvironment.getExecutionEnvironment val fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings) // or val fsTableEnv = TableEnvironment.create(fsSettings)
- 方式二:FLINK BATCH QUERY
```scala
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.table.api.scala.BatchTableEnvironment
val fbEnv = ExecutionEnvironment.getExecutionEnvironment
val fbTableEnv = BatchTableEnvironment.create(fbEnv)
- 方式三:BLINK STREAMING QUERY ```scala import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.table.api.EnvironmentSettings import org.apache.flink.table.api.scala.StreamTableEnvironment
val bsEnv = StreamExecutionEnvironment.getExecutionEnvironment val bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build() val bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings) // or val bsTableEnv = TableEnvironment.create(bsSettings)
- 方法四:BLINK BATCH QUERY
```scala
import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment}
val bbSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build()
val bbTableEnv = TableEnvironment.create(bbSettings)
如果/ lib目录中只有一个规划器jar,则可以使用useAnyPlanner(用于python的use_any_planner)来创建特定的EnvironmentSettings。
2、Register Tables in the Catalog
- Register a Table
//扫描内存中/应用中已注册的表
// table is the result of a simple projection query
val projTable: Table = tableEnv.scan("X").select(...)
// register the Table projTable as table "projectedTable"
tableEnv.registerTable("projectedTable", projTable)
- Register a TableSource
//创建数据源,可以为文本(CSV, Apache [Parquet, Avro, ORC], …)、数据库(MySQL, HBase, …)、消息队列(Apache Kafka, RabbitMQ, …)
// create a TableSource
val csvSource: TableSource = new CsvTableSource("/path/to/file", ...)
// register the TableSource as table "CsvTable"
tableEnv.registerTableSource("CsvTable", csvSource)
四、部署
4.1 Standalone
环境要求:
链接:https://share.weiyun.com/5WPXMUQ
- 上传服务器并安装
# 安装,默认安装目录/usr/local/java
rpm -iv jdk-8u221-linux-x64.rpm
- 配置环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
4.1.2 安装flink
- 下载
wget http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.9.1/flink-1.9.1-bin-scala_2.11.tgz
- 解压
tar xzf flink-1.9.1-bin-scala_2.11.tgz
- 配置(默认配置即可)
配置在flink-1.9.1/conf下面修改,
cd flink-1.9.1/conf
4.1.3 启动和停止集群
- 启动
bin/start-cluster.sh
启动集群后可以在webui上看到flink监控平台
url为ip:8081
- 停止
bin/stop-cluster.sh
4.1.4 提交任务
- webui提交
- shell命令提交
./flink run -c com.atguigu.flink.app.BatchWcApp /ext/flink0503-1.0-SNAPSHOT.jar
--input /applog/flink/input.txt --output /applog/flink/output.csv
4.1.5 添加JobManager/TaskManager到正在运行的集群中
- Adding a JobManager
bin/jobmanager.sh ((start|start-foreground) [host] [webui-port])|stop|stop-all
- Adding a TaskManager
bin/taskmanager.sh start|start-foreground|stop|stop-all
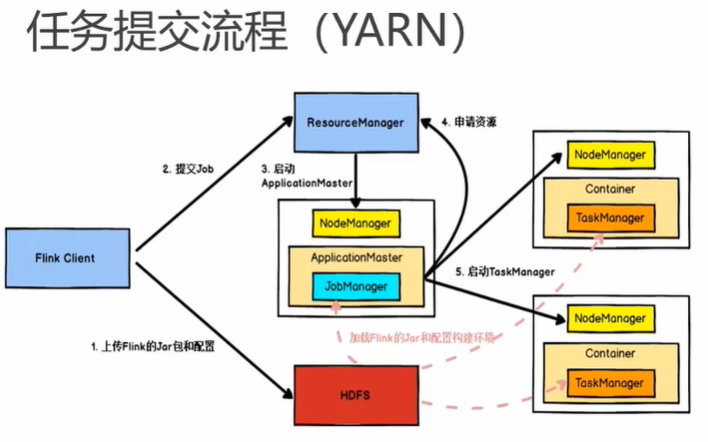
4.2 Flink cluster on YARN
4.3 on Mesos
4.4 on Doker
4.5 on Kubernetes
五、运行时架构
5.1 flink运行时的组件
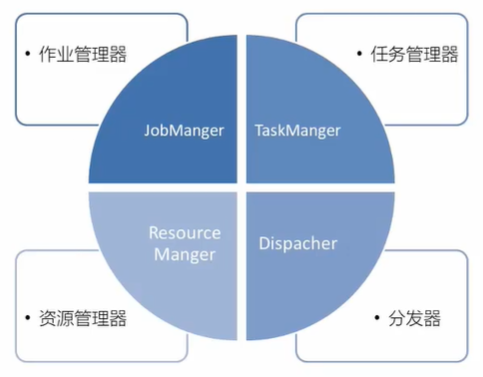
5.1.1 任务管理器

5.1.2 资源管理器

5.1.3 分发器

5.2 作业提交流程
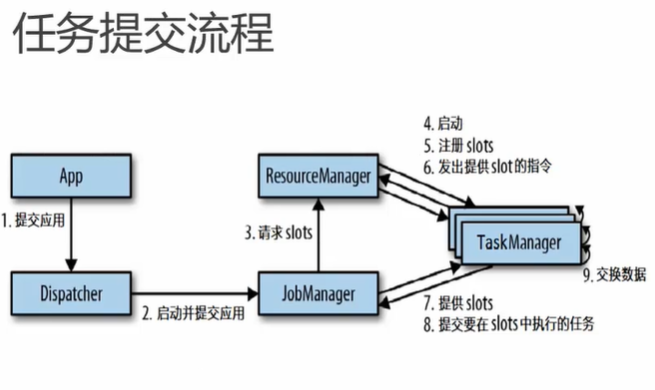
5.3 任务调度原理
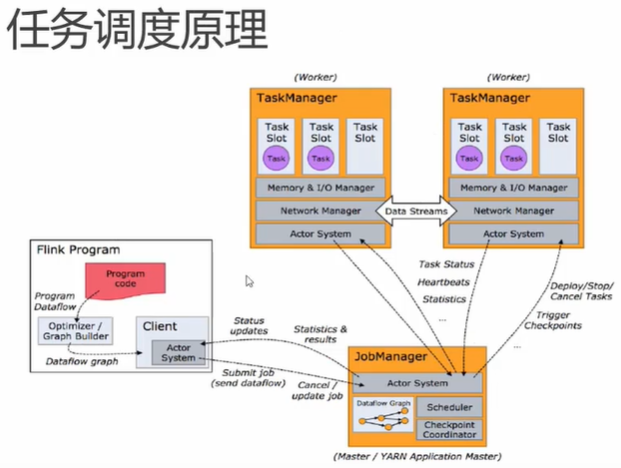
- TaskManager和Slot

- 执行图


若有收获,就点个赞吧
0 人点赞
