一 背景
1.1 架构中的问题识别
需求分析,架构实现,(新需求,架构改动)* n = 推倒重来。
这个过程是一个循环往复的过程,有的产品每年都会推倒重来一次。
而这个过程是如何造成的呢?原因之一是每次迭代过程中都没有用正确的架构方法来进行迭代造成的,就像在歪楼上继续加盖楼层一样,最终还是会倒塌(不过这个原因并不是唯一的原因,其他原因留到后续文章中阐述)。
这真是一个悲伤的故事,但是又是一个时常发生的故事。或者说我们大多数人都经历过的场景。
要解决这个问题,那就需要在每次迭代中,都需要用正确的姿势对不对?要用对姿势其中有一个重要的原因是架构。就像一幢大楼,架构设计得越有问题,这幢大楼被重造的可能性就越大。
这里正确的姿势到底是什么姿势?接下来本文会阐述一整套架构方法论,该方法论中包含了详细的架构推导逻辑,帮助我们在工作中在各个粒度,各个层次做好架构工作。
我们后续的文章中将会着重阐述如何通过自底向上以及自顶向下的两种架构思考方式来解决这些问题,但是在那之前,我们还是先来聊聊什么叫“架构”。
1.2 什么是架构?
大概是在 11 年前左右,在土豆网做广告平台,同时也做视频 CDN 的相关事情,当时做一个服务,基础架构是 lighttpd + squid + tomcat,将静态资源分离到 httpd,get 请求使用 squid 缓存,智能路由使用 HTTP post 请求,并让 tomcat 提供服务,当时就觉得这就是架构。再后来,做了视频 CDN 相关的基础建设的工作,就觉得这就是做架构,关键那个时候也没有人告诉我们什么架构,自己不知道自己不知道。
再后来慢慢成长,又去做了几年中间件(包括高性能 RPC 和 JSR-170),然后就觉得这也是做架构。当时也没有前辈跟我讲什么是架构,那个时候的我对架构是没有体系化认知的,都是凭着感觉做的,是不知道自己不知道。
再后来,来到了阿里做应用研发和架构了,发现业务开发中也包含了各种方法论,而以前看过的建模相关的资料,在中间件等基础设施上也没有太大的感觉,反而在业务技术领域发挥出了巨大的光芒。也发现越靠近用户的架构,随着企业的慢慢壮大会变得越来越重要。这个时候的我对架构认知是知道自己不知道了。
既然知道自己不知道了,那么就是要追寻它,曾经我和不少业务的研发同学讨论过架构是什么,撇去基础设施架构和物理架构等视角不谈(这些视角聊起来也是篇幅很长的),我挑应用逻辑架构并从几个角度来尝试描述一下:
1)从架构的总原则的角度:尽可能简单(在当前场景下要尽可能简单便于扩展和维护),但是不能太简单(相对而言太过于简单可能在场景上有所遗漏).
2)从架构的目的角度来考虑:既要解决过去的问题,也要解决现在的问题,还能适度解决未来的问题,这些问题既包含技术问题,更包含业务问题。
3)从形态之 2 维的角度来考虑:架构就是横的问题,和竖的问题。横就是分层,竖就是分区,横竖都有抽象的事情要做。
4)从形态之 3 维的角度来考虑:架构是三维的,在 x 轴和 y 轴上有横竖的问题,在z轴上还有粒度的问题。
5)从时间轴的角度来考虑:架构不是一层不变的,是随着业务的发展在不断变化的。
可以看出,虽然我试图从以上几个视角对架构进行了描述,但是显然这些描述都是见仁见智的观点,是从某个角度来看架构。内心里我觉得自己提炼的高度是不够的,实践中的总结必须和业界的知识结合起来,我必须学习前人已经总结的体系。于是在不断的搜集资料的过程中,我发现在 ISO/IEC 42010:20072 中对架构有如下定义:
The fundamental organization of a system, embodied in its components, their relationships to each other and the environment, and the principles governing its design and evolution.

这个最顶层抽象我个人觉得非常到位,根据这个定义,显然,我们在架构中需要:
- 职责明确的模块或者组件
- 组件直接的关联关系非常明确
- 需要有约束和指导原则
这个架构的定义很简练,很实在。小到一个玩具,大到一个国家的运作都可以隐含着这样的内容。
但这是一个广义上定义的架构,经过一些总结思考,我觉得实际上具体到我们日常的工作中,在不同的层次,会有更加精细化的架构分类。
1.3 架构有哪些分类
在工作中我遇到不同职位的人从不同的角度来描述架构,但是我们鲜有能达成共识的,刚开始我也不知道为啥讨论不到一块去,后来经过一段时间的纠结和深入仔细的思考后,我发现很多时候大家描述的架构都不是同一个角度的东西,于是我尝试从如下几个角度划分架构的类别,以帮助我们在不同的场景和不同的人聊天时大家可以聚焦,明确我们到底是在讨论哪种架构,以提升沟通效率,并尽快达成共识,目前这个划分已经在我们团队基本达成共识。
值得注意的是,不管下面哪种分类的架构,都符合上一节总的架构的定义:模块(组件)+ 关系 + 约束 & 原则。
1. 产品功能架构
这个是产品经理最喜欢讲的架构,一般来说,讲我们有什么功能的时候,产品功能架构描述的是能做什么,受众群体一般是使用产品的同学。如果我们做软件设计时,不应该产出这玩意,而是应该产出应用逻辑架构和应用物理架构。但是一旦我们要对外宣讲我们的产品,比如我们的接口有啥用,应该怎么用,这个时候我们讲的应该是产品功能架构。
- 目的:指导用户使用产品,所以模块的聚合是从用户视角出发的
- 受众:使用产品的人
- 包含的内容:阐述产品功能模块的能力:比如一辆汽车,方向盘有什么功能,方向盘的按钮上各区域的功能是什么,仪表盘分成哪些功能模块,每个功能模块有什么作用,油门踏板有什么作用,刹车踏板有什么作用。但是也不排除有些高阶用户需要明确知道变速箱的齿比等信息,所以在产品功能架构图上也可以描绘出来。
- 命名:这里命名需要考虑如何取一个吸引人的名字(同时又能表达产品的能力)来吸引我们的用户前来使用,比如说以前经常有产品套用“纳米”,又有产品套用“绿色”等等。
2. 业务能力架构
用来分析业务,业务概念架构是指拥有哪些业务模块,且各自的能力是什么,这张图有助于我们分析和理解业务需求,也有利于产品经理分析业务。所以业务概念架构和业务概念模型都是用在分析阶段。
- 目的:研发人员和业务人员理解业务内在的概念和联系。
- 受众:研发人员和业务人员,主要是给规划业务的人使用。
- 包含的内容:业务能力,能力中的子能力。
3. 应用逻辑架构
软件设计本身,模块,粒度,职责,复用,等等,在讲解软件设计的时候,使用的是这个架构图,这个架构图是通过系统模型和业务概念架构推导而来。所以系统模型和应用逻辑架构都是用在软件设计阶段。
- 目的:指导软件的研发。
- 受众:研发人员,各层级架构师,各层级技术管理者。
- 包含的内容:阐述架构中各模块的职责:如系统模型,技术模块,技术模块的关系,技术模块的核心抽象,如何用设计模式来让架构符合软件设计原则,等等。如果拿汽车举例,那就是发动机模块中包含了哪些子模块(活塞,曲轴,连杆,缸体,缸盖,等等)发动机模块和变速箱模块之间的关联关系是什么,如何协同工作,和底盘的关联关系是什么,如何协同工作。发动机,底盘,变速箱,电子系统在整辆汽车中的职责,关系,约束是什么。这些都是用来指导汽车研发的。而不是指导用户如何使用这辆汽车的。
- 命名:这里的命名需要朴实无华,精准的描述出职责,华而不实反而让技术的同学无法理解这到底是什么玩意,导致实施的时候职责放错地方,挖下大坑让后人来填。
4. 应用物理(部署)架构
软件部署时的架构,这张图推导自应用逻辑架构,推导时重点逻辑架构如何落地,比如使用何种微服务容器,逻辑架构的模块落地时应该是 package,还是应用,也有可能是一组应用,是不是要跨机房部署,甚至跨国部署等等。还需要考虑稳定性,性能,成本等话题。
5. 基础设施架构
选择什么样的中间件,存储,监控,报警,等等。
6. 等等
1.4 能力和职责的区别
在日常的架构讨论中,有的同学经常谈架构的能力,有的同学经常谈架构的职责,那么能力和职责有什么区别?跟产品的同学打交道多了之后,发现产品同学很多都是讲能力,后来技术的同学也开始讲能力,而通常我们架构的同学原来讲的都是职责,两者有什么区别呢,我说说自己的理解:
1. 能力(产品功能模块的能力)
是指一个产品能做什么,比如中台本身是一个产品,对使用中台的同学来说,我们应该讲中台的能力(其实是在讲中台这个产品的能力)。所以讲能力是讲给架构的使用者或者其他想了解的人来听的。
2. 职责(逻辑架构中各模块的职责)
是指架构内模块的职责,用来指导开发,比如中台研发的同学,应该讲架构的职责,依赖,约束。所以讲职责是讲给研发的同学,讲给域内的架构师,讲给域内的管理者来听的,总的来说就是讲给架构的实现者来说的。
简单来说就是:能力是指产品的能力,职责是指架构内部的职责。如果架构本身也是一个产品需对外输出(如中台,或者其他技术框架作为产品输出),则对外输出时,我们应该讲这个技术产品的能力(这个时候技术的同学也就开始讲能力了)。所以当我们讨论问题的时候,如果有的人在谈产品能力,有人在谈架构内部职责,那么显然已经不是在讨论同一个话题了,请大家务必注意区分这种情况,差之毫厘,谬以千里,鸡同鸭讲啊。
比如说两个模块 A 和 B,职责不一样,但是依赖了相同的二方库。那我们不能说某个职责在这个二方库里。这个二方库作为某个独立的技术小产品,提供了某些能力。但是履行职责的还是 A 模块或者 B 模块。
1.5 应用逻辑架构的地位
正如前面我们描述的架构分类所描述,有些架构和具体业务是无关的,有些架构是和具体业务息息相关的,比如说应用逻辑架构就是和业务息息相关,它来源于业务的抽象,甚至我们可以说:它是业务线技术架构设计中第一份产出。
既然他是首要的产出,我们就必须要考虑应用逻辑架构中应该包含的三类主题:
- 模块
- 依赖
- 约束
绝大部分的架构问题都可以归纳成这三类主题,这些主题包含哪些内容呢?这就是本文接下来要介绍的内容,应用逻辑架构的设计不需要拍脑袋,是通过科学的方法体系推导出来的。
二 架构的两种推导思路
架构的产出总的来说有两种方式,一种是自顶向下的方式来推导架构,一种是自底向上的推导方式,而且两种方式往往是相互结合来产出最合适的结果。而在业务线的同学,可能接触最多的是自底向上的推导的方式,自底向上的推导的方式也是本文中要重点讲解的架构推导方式。
2.1 自顶向下的架构推导
自顶向下的推导的关键问题在问题定义,如果问题没有被准确的定义,那么自顶向下就无法推导出正确的结果。假设问题被准确的定义了,如何自顶向下推导呢?
2.2 自底向上的架构推导
我们在业务线做开发的同学,每天肯定跟很多需求打交道,这些需求哪里来的?基本上有这三种产出:
- 有些是来自产品方一拍脑袋产生的灵感
- 有些是对数据进行了详细的分析产出的产品策略
- 有些是当前产品中暴露的一个个问题
产品方的这些详细的需求来了之后,我们是如何应对的呢?我们首先和产品方一起讨论产品方案的合理性,在产品方案合理的基础上,我们来开始识别用例,开始了一系列软件工程领域方面的措施。其整体过程如下图所示:
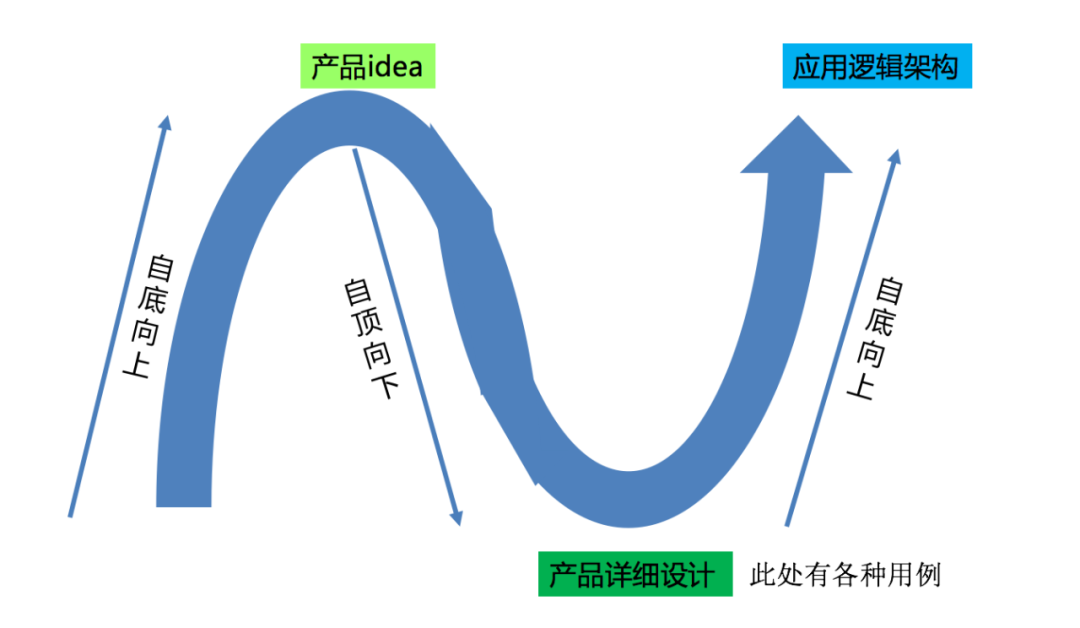
自底向上推导逻辑架构就是最右边代表的那条曲线。
这里基本上就是本文接下来要重点阐述的:如何自底向上推导应用逻辑架构,这个过程就是一个抽象和架构的过程。
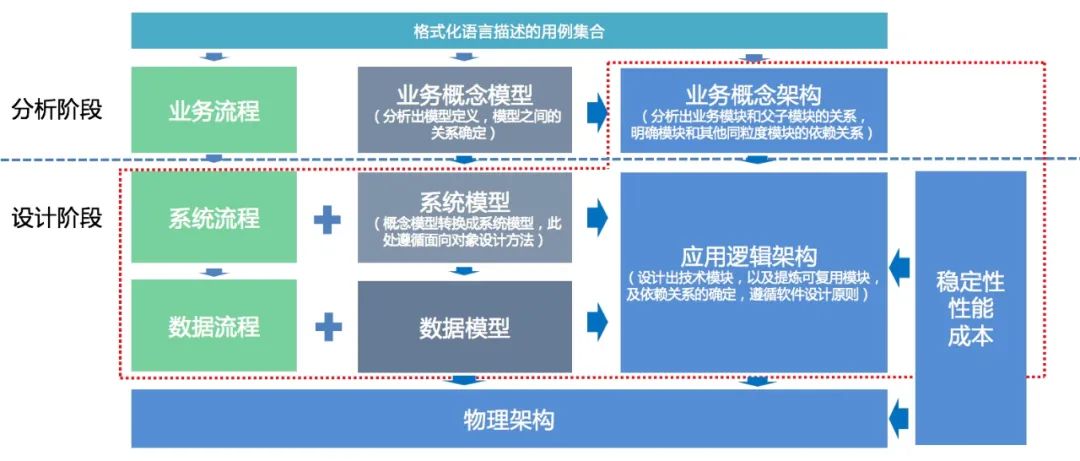
那么我们从整体方法论的介绍开始,采用总分总的结构,下面这张图就是应用逻辑架构自底向上的推导路径,这个推导路径是有序的,每个步骤都包含了大量的操作技巧,前一步做好,后一步才有可能得出正确的结果。
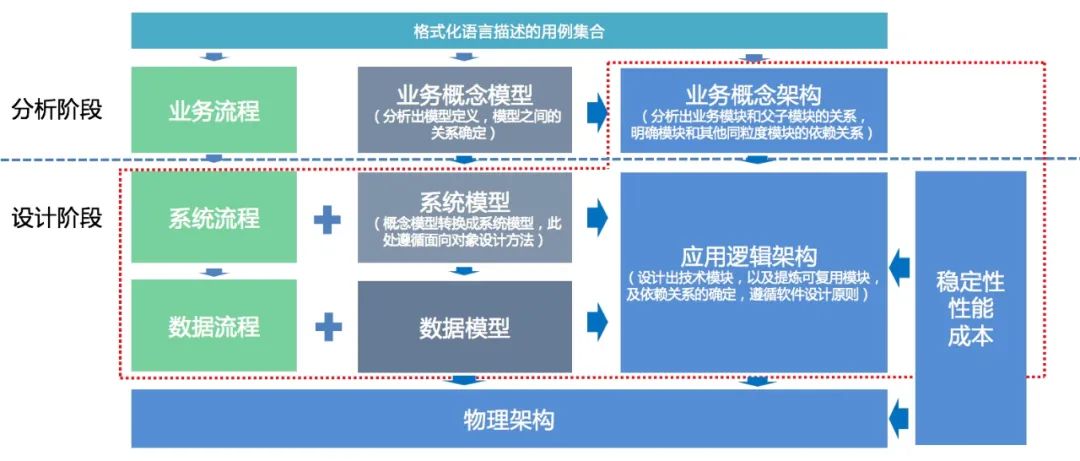
这张图中有几个重点:
1)软件研发分成了两个阶段:
- 分析阶段,也是我们常说的问题空间领域建模,关键的一步是业务概念模型的输出,而业务概念模型输出的前置条件是从需求中分解出合理的用例集合。
- 设计阶段,也是我们常说的解决方案空间建模,以及应用逻辑架构。
2)图中存在了箭头这个东西,说明了我们做架构推导的主要的思维路径,也说明做架构不需要拍脑袋,都是根据严密的逻辑推导出来的。
这个严密逻辑基本是一个自底向上的推导过程,底层的模型是通过建模方法演绎出来,逻辑架构中的各个模块是通过归纳的方法推导出来。那么:
- 什么地方应该用演绎,什么地方应该用归纳呢?
- 使用演绎的时候应该使用何种具体方法呢?
- 使用归纳的时候应该使用何种具体方法呢?
我们再留一个悬念,后面再讲。
不管是演绎还是归纳,都是抽象工作的一部分,而且都需要素材,这里的素材就是我们对需求,对业务的理解,以及对技术的深度广度的把握。没有素材,方法论掌握再好也得不出结果。
素材哪里来呢?
业务素材的来源大部分是你需要解决问题所在的领域,比如我们在电商领域,那么我们就要多搜集电商领域的业务知识。如果我们在数据领域,自然要多搜集数据业务的相关知识,以及我们前文中讲到的技术类的相关知识。
而技术素材是要求我们在技术领域不断的钻研,不断的扩展边界,深度不断增加,广度也不断增加。所以对于架构师来说计算机科学与技术是绝对要不断精进的。
2.3 两个方法的区别
自顶向下推导的一个前置条件就是你需要知道猪长什么样,在架构上就是你需要知道这个架构的原来是是什么样子的,解决什么问题的。如果都不知道猪长什么样,那么就无从判断猪是不是适合当宠物了。此处需要有一定的业务领域理解力和领域经验(包含:客户的问题和痛点是什么,怎么分析出来的,当前的架构方案是什么,当前的架构方案是如何解决这个问题的,未来的架构方案如何更好的解决这个问题)。
而自底向上推导则没有这个问题,因为是看着猪来做推导的,知道猪的细节,这个细节的特点如何演绎,如何归纳,最后得出结论。
所以当我们不熟悉一个大的业务的时候,我们自顶向下推导架构的难度是极大的,几乎不能完成。不了解业务或技术情况时定义出来的问题也未必是一个被正确定义的问题,容易给人造成一个印象:瞎指挥。
这个时候如何在没有知识背景的情况下快速落地就得自底向上的来推导架构。在自底向上的过程中慢慢熟悉业务。
但是如果工作中每每都是纯粹的自底向上的推导架构,是无法帮助我们来做技术的前瞻性布局的,此时架构师的成长就遇到的瓶颈,所以此时又要使用自顶向下的架构推导方式。
综上所述,不管是自底向上,还是自顶向下,都是架构师需要掌握的技能。
三 自底向上的架构方法:业务概念架构推导
这部分内容,我在 ICBU,村淘,一达通,菜鸟,AE 现场分享过。尤其是在 AE,一达通和菜鸟,相关的同学都拿出了当时的纠结大家很久的难题,我们一起使用了这样的方法很快就分析出了业务概念模型,并且对模块进行了简要的划分,形成概要的业务概念架构。经过大量的实战,效果是非常明显的。
3.1 模型的 3 个层次
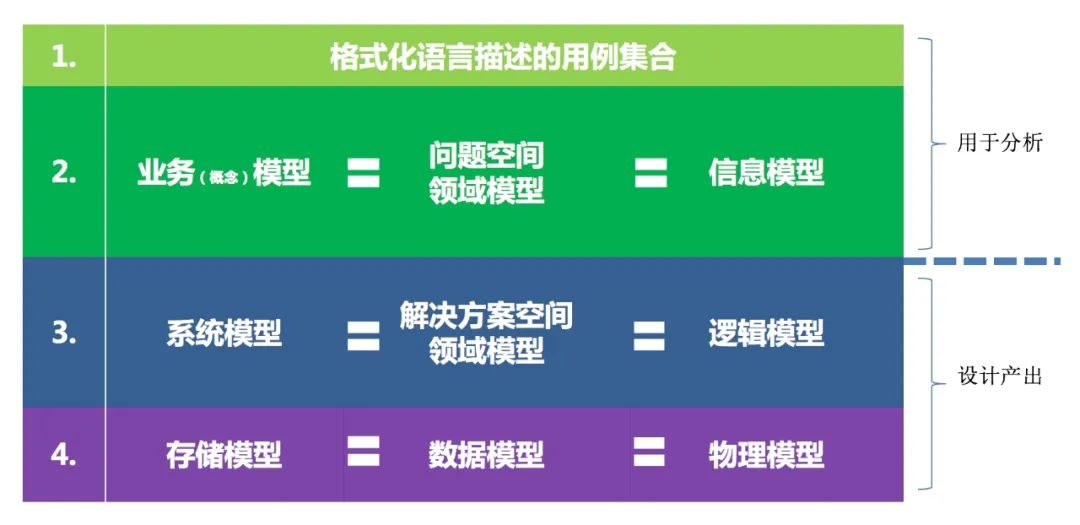
在这里,我把一些常见的概念集中起来,便于大家统一概念:
1)业务概念模型,问题空间领域模型,信息模型是同样的意思,这个层次上的实体我们称之为概念实体,这部分内容是用在需求和业务分析上的,讨论业务概念模型时完全不需要考虑软件的实现,这个过程是一个分析过程,即使不做软件研发,做其他的研发,类似的分析过程也应该是有的。
2)系统模型,解决方案空间领域模型,逻辑模型是同样的意思,这个层次上的实体,我们称之为系统实体,或者逻辑实体,就是各种类,这个是用在软件设计和软件研发上的。
3)存储模型,数据模型,物理模型,在这里也是同样的意思,这个层次上的实体,我们称之为数据实体,或者物理实体,也是用在软件设计上。
这 3 个层次其实是从 3 个角度在看待问题,他们之间是自上而下的转换的关系,这里尤其要注意的两个词是:逻辑的,顺序的推导。
这些不同层次的模型是应用逻辑架构的基础!!!
3.2 模型的推导
3.2.1 用例集合推导概念模型

- 根据用例集合推导业务概念模型
- 根据用例中的动词和量词推导业务概念模型的关联关系
- 在特定的边界内根据模型的职责归纳子域
重要!重要!重要!这里业务概念模型如果没有分析正确,那么下面要搞清楚是不容易的,这个分析部分是软件逻辑架构设计的基础。
这个环节需要我们理解业务,更需要我们掌握问题空间建模这一严谨的方法论,这样我们才能推导出合理的模型,整个过程是非常严谨的,非常符合逻辑的。
我在各 BU 分享现场做的多次实战演练之所以能成功的快速帮助同学们梳理出前面花一两个月都没有理出的模型,完全是因为于现场的同学对业务的理解(因为讨论之前我完全没有了解过对方的业务)和这套方法论(隐含在我的提问方式中)。所以说对业务的理解和方法论,两者缺一不可。
3.2.2 对业务概念模型进行归纳
在模型产出之后,我们要对模型进行归纳。
什么叫归纳?
归纳的意思是将所有的结果和想法合并,变成一种思维概念。或者让某个模型归属于某个已经存在的思维概念。且这些模型或者模块的职责不能超越这个高层次思维概念的边界。
为什么要归纳?
其实是为了保证相近的职责模型聚拢在一起从而保证职责的高内聚,同时明确出来的两个子域的边界,保证模块和模块之间的低耦合。
对业务概念模型的归纳有助于做业务需求分析时判断高内聚和低耦合,而且在系统模型上,对系统模型进行分类也有助于做应用逻辑架构中模块的高内聚和低耦合,但是应用逻辑架构的不止高内聚和低耦合,还有其他让职责单一的方法,这些后面的章节会做介绍。
3.2.3 按职责来进行归纳
接下来我们来讲讲业务概念模型到业务概念架构判断方法:
1)通过名词定义来进行归纳思维概念
如果多个模型都在围绕某个名词,那么我们倾向将这个名词提炼出来。产品在设计时,基本上我们已经能够得一个粗略的业务模块划分,但是这个粗略的划分是不一定是合理:
一是有可能我们的理解是不到位的,导致用错了名词,这个我们前面的文章中也提到过了。
二是这个结果也只是一个粗略的结果,需要进一步精化。
2)通过内聚的度量公式来进行归纳

业务模型图中,模型和模型连线(连线就是模型和模型连接线)数量除以模型的梳理得到的值比较大的,那么我们可以看做是内聚,这些连线比较紧密我们趋向将其放到一个模块中,连线不是那么密切的,我们趋向于将它们放置在不同的模块中。然后我们再观察 连线数 / 模型数 观察内聚度量是高了还是低了,通过这样的方式归纳完成之后,我们再来通过度量公式来度量各模块的内聚和耦合程度。
3)其他归纳方式
如果我们划分出了基本模块,发现还有一些模型不确定应该放到哪些模块中,我们还可以使用创建者原则和信息专家原则来判断应该将该模型归纳如哪个模块。
比如说,对存储系统进行系统建模,表和字段的关系在业务概念模型中是1对n的关系(在系统模型中是组合关系,强生命周期依赖,但是这里我们还没有到讨论应用逻辑架构的时候,只是在推导业务概念架构),此时将字段放到另外一个模块显然不合适,原因是根据创建者原则。
当我们不清楚把字段模型放到哪个模块的时候,我们可以看看字段这个模型是由谁创建的。
根据这条原则显然这里是表创建了字段,没有表对象,就没有字段对象,所以根据这条原则,我们就倾向于把字段模型放到表所在的模块中。
重点:失去了最底层合理且正确的演绎,上层的归纳掌握的再好,也很难得出合理的结果。
我们来看看归纳之后的效果示意图:
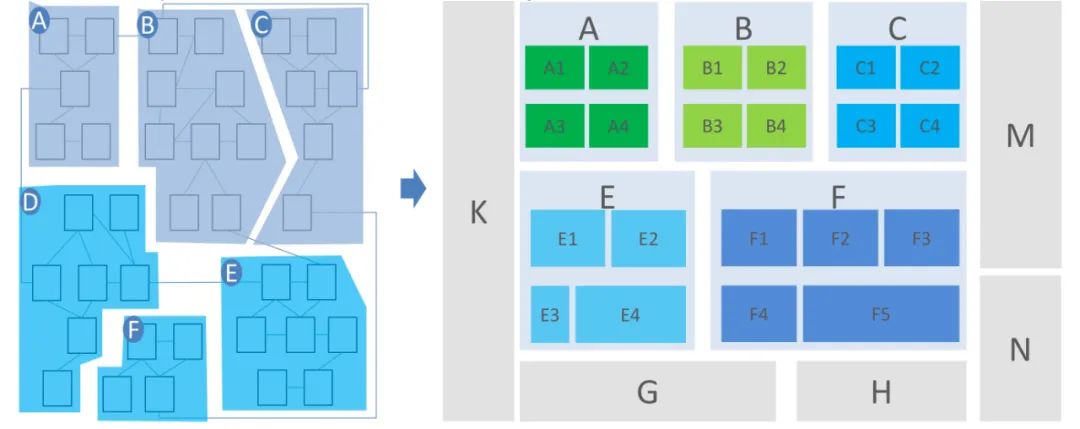
图中的 A1,A2,A3,A4 之类是示意图,表示 A 模块内部还存在子模块,当然我们其实是先推导出子模块,然后对子模块再次进行高级别归纳,形成父模块。
父模块层级再进行归纳,就形成了祖父模块,或者再向上形成曾祖父模块等等。粒度越大的模块,一般都对应更大的组织,越存在跨团队沟通,所以划清边界的要求就越高。
3.3 业务流程
除了业务模型之外,业务流程也是我们需要总结并明确的地方,这个地方主要明确的就是边界和异常分支等等,尤其是异常分支非常重要,很多业务方案的设计中对异常分支的考量是不重复的,这需要工程师对业务方案提出挑战,以明确业务方案中的各种流程的异常分支。
3.4 业务概念架构总结
我们工作中常见的推导有两种方式,一种是自顶向下推导,一种是自底向上推导,显然,两种推导使用的方法是不一样的。细心的读者会发现,其实我们刚刚说的问题空间领域模型和边界分析这套方法就是自底向上的演绎和归纳方法。
四 基础逻辑架构推导(软件设计阶段)
前面我们讲到了业务分析阶段,也是问题空间建模和问题空间业务概念架构梳理,业务分析阶段和软件没有任何关系。但本文中它是软件设计的前置条件,没有 get 到点的同学,请务必再把前一章仔细阅读。
接下来我们来讲讲软件设计阶段我们需要产出的应用逻辑架构。
4.1 再谈逻辑架构特性
文章开头讲到了逻辑架构的相关特点,我们回顾一下:
应用逻辑架构的作用:我们把前面那个例子再搬过来:如果拿汽车举例,那就是发动机模块中包含了哪些子模块(活塞,曲轴,连杆,缸体,缸盖,等等)发动机模块和变速箱模块之间的关联关系是什么,和底盘的关联关系是什么,发动机,底盘,变速箱,电子系统在整辆汽车中的职责,关系,约束是什么。这些都是用来指导汽车研发的。而不是指导用户如何使用这辆汽车的。
目的:所以系统模型和应用逻辑架构都是用在软件设计阶段,其目的是用来指导软件的研发。
受众:逻辑架构的受众有哪些呢?一般是这些人:研发人员,各层级架构师,各层级技术管理者,总的来说他们都是架构的设计者和实现者。
这里还是请大家务必要跟产品功能架构区分开来,它们的受众和目标是不一样的。
4.2 基础逻辑架构的推导概要
在文章开头的图中,我们讲到应用逻辑架构来源于系统模型,数据模型,业务概念架构,还有流程,如下图所示。

接下来,我们分别从三个角度来阐述逻辑架构的生成:
- 业务概念架构
- 模型(系统模型和数据模型)
- 流程(系统调用流和数据流)
看到很多同学画的图没有区分出调用流和数据流,经常造成误解,造成沟通效率下降,甚至不能够准确的说明问题。所以在画图的时候,一定要注意区分调用流和数据流。
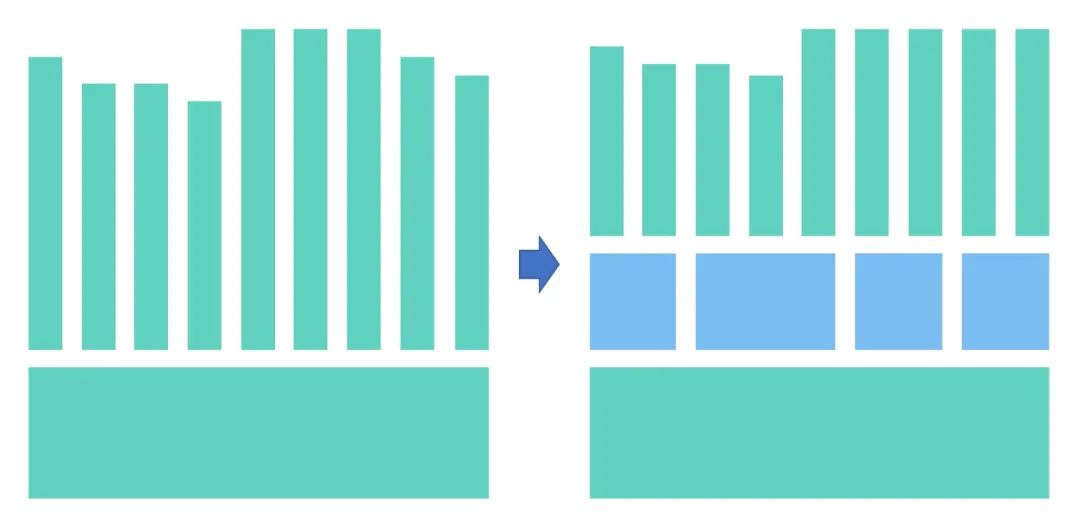
接下来就根据业务概念架构和系统模型及流程来推导一下应用架构(逻辑架构)。我们来看一下一个简单的逻辑架构构成的 gif 示意图:
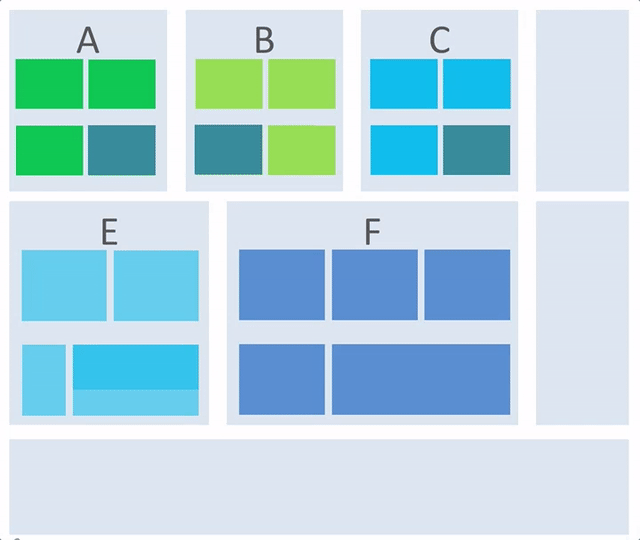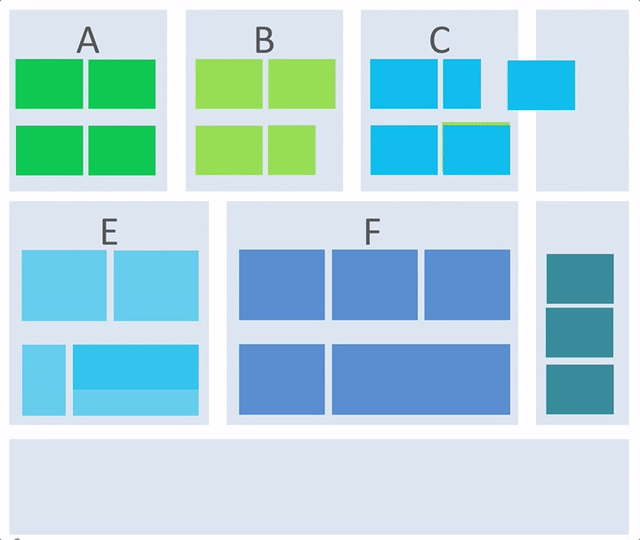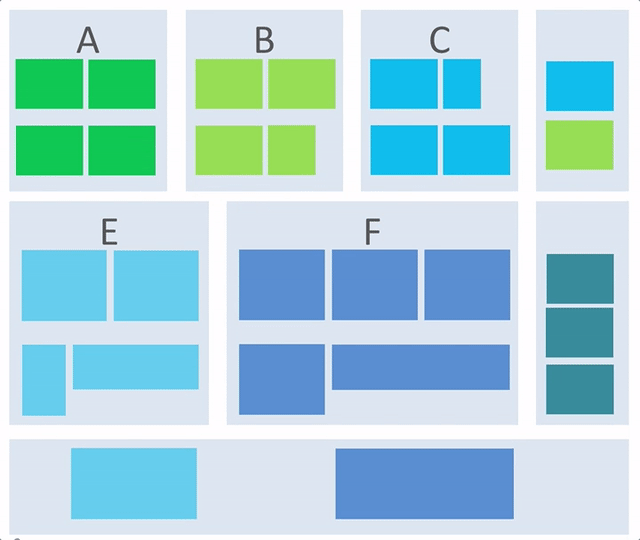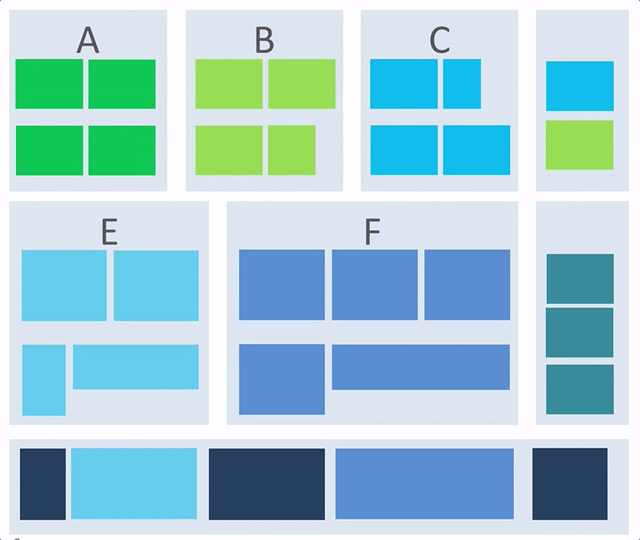
从这张图中,我们可以看出应用逻辑架构是如何一步步被构成的,整个过程存在以下关键点:
1)在业务概念架构的基础上推演应用逻辑架构。
2)根据流程和系统模型来完善应用逻辑架构。
3)横向提炼模块的问题:要实现业务模块,需要什么非业务模块的支撑,比如监控,报警,配置等等,而这部分内容往往还是可复用的。在上述动画中,可以理解成移动到最右侧的部分,当然可以移动到左侧,只是动画中没有体现出来。
4)纵向提炼模块问题:有类似职责的模块在技术实现上是否可以提炼成可复用内容,提炼的结果可能是:
- 独立的服务复用,在上述动画中,可以理解成最下方。
- 或者二方库复用,在上述动画中,可以理解成最左或者最右侧。
5)还有一些模块是为了支撑性能或者稳定性的,并非是从业务概念模型提炼而来,如图中深蓝色的模块。
最终,出现的逻辑架构是分层的和分片的逻辑架构,下面我们来一步步阐述这个过程。
4.3 根据业务概念架构推演
业务概念架构图产出之后,基本上,我们逻辑架构的初步模型就具备了。所以我们可以理解成,第一步就是把业务概念架构直接先搬到应用逻辑架构中来,此处就不用多阐述了。
啰嗦两句:尤其是较为顶层的粗粒度业务架构,一个是自顶向下分解得来,一个是自底向上演绎和归纳得来。而自顶向下分解尤其考验人对业务的理解能力,如果对业务理解不透彻,那很难产出合理的粗粒度业务概念架构。
4.4 根据系统流程进行推演模块
当业务概念架构产出之后,逻辑架构的骨架初成,接下来就是在这个框架上去填充内容。第一步就是根据流程来进行模块划分。
总结一下,这里的方法就是,先根据业务流程,分解出系统时序图,根据时序图开始对模块进行归纳,从而得到粒度更大的模块。
这是粒度比较细的根据流程划分模块的案例,在粒度更大的流程,此方法同样适用,看大家是工作在何种粒度上。
通过流程来进行推导是我们日常工作必不可少的一部分,尤其当很多场景的流程具有业务共同点时,那么可以考虑提炼出这些业务共同点,以提升研发的效率。
4.5 非业务线系统根据流程推导模块案例
除了对流程进行归纳之外,我们还可以对系统模型进行归纳。我们知道,业务概念模型一般可以直接转换为系统模型,但是系统模型并不只是业务领域相关的模型,比如查询模型是一个经常出现的,这在 OLTP 的场景十分常见,而在 OLAP 的场景简直就是顶梁柱。非常常见的就是 SQL parser 模块,下图是 spark 体系中 SQL SQL 的主要流程和对应的模型,根据这个模型我们基本上也可以梳理出模块:
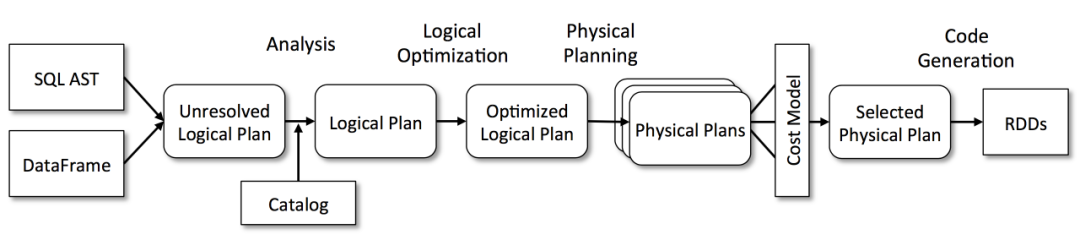
根据这个流程,我们发现了什么?我们发现了 spark 中是这样分模块的(这里面的模块已经落地成 package 了):
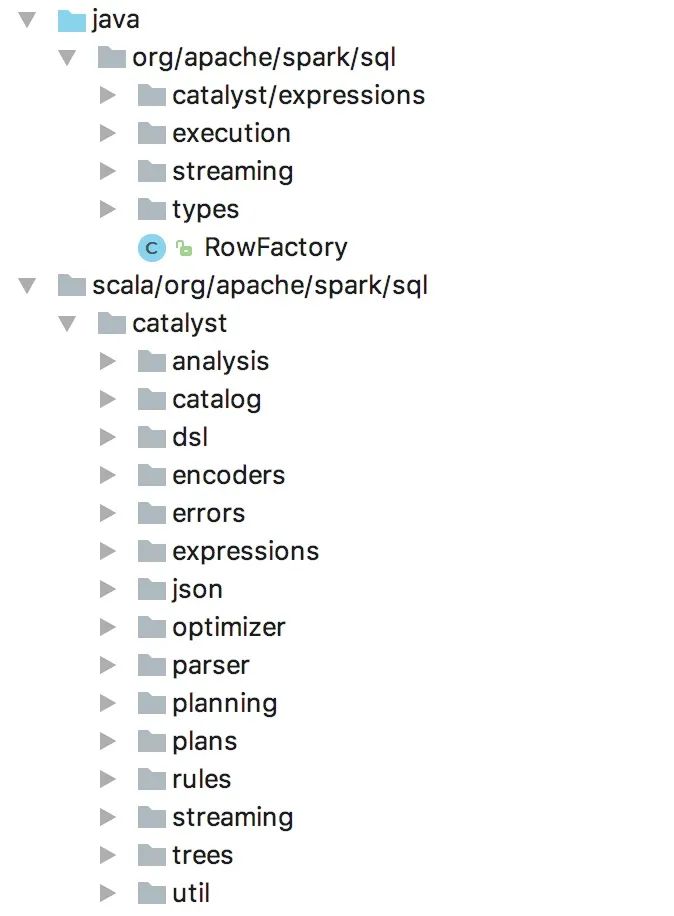
所以说按照业务流程转换成的系统流程来推导模块是非常重要的手段。
除此之外需要还需要强调的是,流程和模块一样,也是有粒度的,相同粒度的流程节点放在一起才更加容易推导出合理的架构模块。至于什么叫相同粒度,请参考一下《金字塔原理》。
流程的粒度很重要,粒度粒度粒度,请重视流程的粒度。
4.6 根据性能 & 稳定性 & 成本等进行提炼模块
前面讲的都是从业务的角度来阐述架构的推导,接下来我们从计算机科学与技术的角度来阐述一下这些非功能性模块的推导,这里拿性能来举个例子吧。
数据分析的报表场景降低 RT 的方案
在一些数据分析产品中,绩效监控及报表展示是一个非常重要的场景,这个场景下的数据量是比较大的,为了降低 RT,我们不得不通过 ETL 对数据进行预计算,将原有的大表清洗成聚合之后的小表,以加快查询的速度。这样做的缺点是每次进行报表的修改,就要进行相关的ETL逻辑,高时间和人力成本,高性能。
为了把高时间和人力成本 & 高性能转换成低成本&高性能,我们需要把人工操作转换成自动操作,把 ETL 的过程去除。
第一个选择是将一个大表的数据存储到另外一个支持大数据下高性能的查询引擎,这样就极大的减少了 ETL 的操作,但是这样就带来一个问题,就是大数据量下把数据从 ODPS 导入到某个 ROLAP 的查询引擎中是比较耗时的,而且每次查询需要进行在海量数据中进行大量的 scan,但实际上获取的数据量并不大。这样的查询的 RT 依然需要亚秒级。
第二个选择是根据报表的定义,自动的将判断出用户需要查询什么结果,将查询结果提前计算出来,然后只把这些少量的预计算后的结果导入到 ROLAP 引擎中(具体请参考 apache 开源项目 Kylin)。然后在报表的场景下,查询的 RT 下降到了百毫秒级。
显然我们要实现第二种方式,这个时候在业务功能没有增加的情况下,我们必须要增加一个模块,在我们的产品中,我们称之为 intelligent cube,因为我们这里引入了机器学习算法对 cube 的构建进行了预测,无需或者只需非常少量的人为参与。
最后导致逻辑架构中有部分是来自业务概念架构推导而来,有部分是系统流程推导而来,有部分是因为性能 & 成本的需要产生的设计。
注意:理论上来讲,逻辑架构上需要指出模块之间的依赖关系,只是如果这样,不是特别美观,所以就根据上下和左右的位置来大概描述模块之间的关系了。
这两个案例基本可以说明,根据性能 & 成本 & 稳定性推导出来的模块也是逻辑架构组成的重要部分。
但是这个还只是一个场景一个场景来解决 RT 问题,虽然 icube 自己内部是有个体系的,但是通过这样的方式来解决 RT 问题对于整个架构来说也是自底向上构建的一个环节。在下一篇文章中,我们将会阐述相同的案例,但是思路是自顶向下来构建性能领域的体系化架构。同样一个事情,用不同的思路来做,对总目标的帮助是不一样的,而且两个方法是互补的,谁都少不了。
这样的模块是如何得来的呢?
看上去我们都已经知道了系统中有不少类似的纯技术相关的模块,但是这些模块内部是如何设计出来的呢?
一般来说有如下方法帮助我们做这些模块的内部设计:
1)调查业界的开源技术类产品中是否有类似功能的,比如预计算在业界有 kylin,而星环等专业大数据公司也都有自己的 cube 预计算产品。
2)查阅业界相关的论文,比如说在预计算领域就已经研究了几十年,计算机发展的不同阶段有不同的论文,网上一搜一大堆,不断研究,必对工作有帮助。
3)多关注业界的牛人,看看他们在想什么,说什么,参加参加相关的会议。
4)自己通过逻辑和数据结构 & 算法推导出来。
如果每次都只通过自己的逻辑和自己已经掌握的知识来进行方案的推导是不够的,一个是我们的技能有时候和事情是不匹配的,但是我们往往不知道这样的事实的存在,所以此时一定要虚心学习,请教他人,扩展自己的知识边界,才能做出更好的方案和技术决策。
4.7 应用逻辑架构推导小结
根据上文所述,基本上应用逻辑架构的推导有 4 个子路径,他们分别是:
- 业务概念架构:业务概念架构来自于业务概念模型和业务流程
- 系统模型:来自于业务概念模型
- 系统流程:来自业务流程
- 非功能性的系统支撑:来自对性能,稳定性,成本的需要
每个子路径中都存在相关的具体方法。
如果真的要想学习东西,而且想学的更快更深入,就要关注自己如何集中注意力,要思考自己的思考方式,研究自己的研究方式。
说明:以上是本文的上篇,我们将继续推出本文的下篇,继续讨论架构的基本约束、逻辑架构的复用以及逻辑架构分层的问题。
五 架构的基本约束
架构约束分成了基本约束和业务约束:
- 逻辑架构基本约束:是软件工程领域常见的各种软件设计原则。
- 逻辑架构的职责约束:是模块,子模块,模型的职责相关约束,尤其是核心的模型和核心主模块是在一定时间内是比较稳定的,所以此时对其定义它的约束范围是有助于这段时间内的研发的效率的。
- 各种架构的非业务功能性约束,如稳定性,性能,成本等等。
而本文讲到的约束基本是逻辑架构上约束,如果考虑业务约束,我们还必须要考虑我们的面向的客户是什么群体之类的约束,如果缺少这样的约束,在设计产品时可能会走偏。
5.1 常见的软件设计原则
- 单一职责原则(SCP)(参考 grasp 原则)
- 开闭原则(OCP)
- 子类替换原则
- 依赖倒置原则(DIP)
- 接口隔离原则(ISP)
- 组合聚合复用原则(CARP)
- 迪米特法则(LoD)
以上这些原则都是判断标准,那么是用什么方法论来实现软件可以帮助我们的软件符合这些原则的呢?答:设计模式。
5.2 常见设计模式
这里有两个非常重要的关键词:判断标准 + 实现方法,这里判断标准是软件设计原则,实现方法设计模式。
作为一个常年在软件行业摸爬滚打的人,设计模式和设计原则应该是较为熟悉的,或者说常用的设计模式和设计原则都是比较熟悉的。但是大部分书籍讲到的是模块内部如何使用设计模式,并没有重点强调逻辑架构中模块之间如何使用设计模式来让逻辑架构遵循软件设计原则。
而我们设计或者推导逻辑架构时,主要就是用设计模式等方法来让逻辑架构中的各模块之间的关系,以及模块内部的子模块之间的关系符合软件设计原则。
5.3 关于模块
如何用设计模式来让模块间的集成符合软件设计原则,从而降低维护和扩展的成本。架构中的模块之间,模块和子模块,子模块和子模块要遵守软件设计的相关约束。如何遵守呢,领域建模和设计模式是两个具体的方法。
即使不考虑模块之间边界和约束,光考虑模块内部的设计,软件设计原则和设计模式就已然是我们软件工程师的必修课。再加上模块之间的依赖或者边界更加需要软件设计原则和设计模式,那它们的地位就更加神圣不可替代。值得不断的深入学习,实践,思考和总结,这也是为设计逻辑架构打基础,架构师必修课。
虽然我们一开始总是从滥用开始,不过没关系,一开始要做到不偏不倚总是很难的,慢慢的我们就可以窥见的其中的奥妙。
5.4 具体技术在某些特定场景下的约束
这是具体的技术在某个特定场景下的约束:
- Web 研发常见的规约,比如说重复提交,事务,多版本。
- MySQL 的在高并发场景下的使用规约,比如说各种分库分表的规则,索引规则等等。
- 高并发相关系统中的相关约束,比如说幂等控制,并发控制,缓存策略,线程使用,锁粒度,各种循环内调用远程接口或数据库等等。
- 其他。
总的来说,这里的这些约束更偏向于物理架构上的约束,这里还是提前描述一下。同时每个物理架构要解决的问题不一样,导致它们要遵守的计算机科学与技术上的约束是不一样的,这是架构师们要整理,并倡导执行的。
5.5 逻辑架构中的业务属性约束
前面讲到的是软件研发领域的基本约束,这些基本约束在高粒度模块中一般很少被提及,高粒度模块之间的约束关系是根据业务中的思维概念提炼而来,比如电商中提炼出订单,营销活动,商品等等核心概念和核心域,对这些核心概念进行定义,以确定它们之间的关系和边界,从而形成技术上的统一业务约束。
同理,任何一个领域应该都存在这样的约束,只是这样的约束并不是一层不变的,尤其是在业务系统中,业务理解发生了变化,这样的约束也会随之变化,而且业务中约束的目的是驱动业务更好的前进的重要保障。
我们拿国家这个架构来做简单的解读,读了十年历史,大概总结出的一个国家级别主要架构约束是这样的:
历史上不同时期的国家治理有不同的架构(三省是顶层模块,六部是二级模块,然后依次做模块分解,直到一村,一户,这户可以看最是领域模型)和规约。西周和东周的春秋时期靠的是周公旦制作的礼和乐作为国家架构的约束,到了战国时期,礼崩乐坏,百家争鸣,最终以统一国家为目标的法(这个法和保障民生的法是两回事)成为秦国的架构约束,得以让他成功统一六国,但是很快这种法的约束又带来了副作用,于是汉朝建立,确定孔子的儒家伦理道德作为国家架构的主要约束。
然而这种以伦理和道德为主的架构约束对王朝的前 100 年 - 150 年是非常有效的,但是随着时间的发展,这样的约束会越来越弱,约束变弱则利益集团会不断的让架构中的模块边界变的模糊,有些模块的利益变的更大,有些模块的利益更小了,而且依赖关系变的混乱,从而使整体架构的利益受到影响,同时由于利益牵绊太深很少有一个总架构师有能力扭转乾坤。最终于就会被另外一个王朝所洗牌,新的王朝会重新建立架构,重新设定模块间的边界和依赖,同时还是以道德和伦理作为主要的约束。这种局面从汉朝开始周而复始了 2000 年。
不管怎么说,一个符合时宜的架构约束是有利于架构向前发展的,而不符合时宜的约束反而是制约者架构发展的。各种内耗等情况应运而生,最终阻碍了业务向前拓展。
5.6 约束小结
纵上所述,模块间约束无处不在,技术上的约束是最最容易看懂的。越是细粒度模块的约束,我们越容易学习和理解,比如软件设计的原则等等,越是高粒度的模块的约束,越抽象。需要对业务有深刻理解,对组织有深刻的理解,甚至对社会有深刻的理解。
六 逻辑架构复用
6.1 复用
件复用包含很多内容,比如说设计的复用,文档的复用,代码的复用等等。在本章节中的复用特指代码的复用。
复用的收益
提炼的目的是实现复用,复用的目标收益是:
- 软件的研发效率的提升
- 研发成本下降
- 软件质量的提升
- 等等
复用的分类
对于复用,我从业务功能和非业务功能的角度来分了一下类,如下:
1)一种是跟业务无关的一些可复用的内容,这些内容存在于基础架构的每一个层次,但是还不能归属于逻辑架构,而且业务技术无关的复用不是本文讨论的重点,所以本文不会重点阐述 MVC 的设计思想是如何在不同的 Web 应用中得以复用的。
- 框架的复用,spring, mybatis 之类的,对于框架的研究,业界从来没有停止过脚步
- 数据结构,算法,网络,等封装库,比如 Apache 和 Google 的各种封装库
- 中间件(RPC,Queue,cache 等)及各种存储,监控报警等基础设施
- ORM,IOC,AOP,MVC,BPM,Rule Engine 等等对应的框架,这些都是和业务无关的复用
- 等等
2)还有一种是跟业务相关的可复用内容,它的产生取决于抽象能力和技术功底,比如:
- 系统模型复用:营销活动中存在各种规则,那么这些规则应该如何抽象以达到可以被复用的程度呢?比如我们将规则中的节点可以抽象成单独的算子,比如说满足某个条件,执行某个优惠动作,那么满足和某个优惠动作都可以抽象成算子(在 UMP 中被称为元数据,我们也沿袭了这一叫法)这些算子可以被复用且随意组合,以形成新的活动规则。
- 流程的复用,比如每种电商平台,都需要有交易流程,包括信息流,资金流,那么天猫,淘宝,聚划算等的交易流程是否可以复用,如果可以应该如何复用,是否可以将相同的和不同的环节区别对待,以实现可复用性。
- 计算模型 & 框架的复用,比如说营销中的叠加互斥计算模型,session 包的复用,特定业务中的测试框架的复用。
业务模块复用的形式(物理架构中要考虑的内容)
具体的复用形式本质上来说是物理架构中要考虑的内容,这里捎带提一下。
1)二方库形式
提炼成二方库,谁使用谁依赖这个二方库,这种情况又分成了两个子类:
纯逻辑,没有数据的存储等,其计算完全依靠调用者传入的数据,比如说某个业务场景的规则引擎,某个业务工具包等。
有负责数据的存储,比如说在二方库中直连另外一个服务(也可以看做胖客户端),或者直接连接数据库,这种方式在网站早期比较常见。
2)服务化形式
下沉成服务,通过接口对外暴露,技术手段多种多样,比如说 HSF,SOFA 对外暴露,或者 HTTP 对外暴露等,但是这里的重点不是在使用什么样的技术手段,而是暴露的服务中应该包含哪些内容(有多少客户,他们的需求的共性是什么,我们的业务本质是什么,根据这些内容来设计我们需要暴露的服务,然后在考虑我们接口的规范。至于使用什么样的服务容器之类的内容基础设施架构同学会重点来考量,我们需要需要学习和理解,但是我们的重点还是在前两个,即服务到底是什么,以及服务接口的规范是什么,在这两个上苦下功夫,对业务线的同学拿结果以及个人成长都有莫大的帮助)
3)展示组件
还有我们前端的各种可复用的展示组件的设计,比如说 TMF 的可复用组件等等。
逻辑架构中的可复用模块的落地表现形式优劣
跟业务无关的可以复用内容我们在本文中暂不讨论,本文中我们讨论一下跟业务相关的跨模块复用的两种情况,以及这两种情况之间的异同:
在跟业务相关的跨模块可复用情况中,慢慢的大家都以后者(下沉成服务)作为主要的表现形式,原因有便于发布,变更影响小,等等。虽然后者在调用时有一些远程开销,但是得益于 RPC 简洁的二进制协议(CPU Time 的下降)和日益变小的 RTT(RT 的下降)及日益增加的带宽,其远程开销的代价渐渐变得不那么显眼,甚至可以忽视。
那么是不是后者是不是可以代替前者呢?也并不是这样,有的场景下前者是不能用后者来代替的,比如说通过业务流程的提炼抽象而得来的业务二方库,这个是无法通过服务化来代替的,反而这种情况下,往往是服务化+二方库同时出现,起到一个很好的复用的作用。
所以在业务线的应用逻辑架构中,复用的重点即在提炼出共同的特性(模型上,流程上,计算模型上等),然后以二方库或者服务化应用的方式来进行落地。那么如何在逻辑架构中提炼出共同特性呢?
6.2 抽象和提炼
抽象和提炼基本上会从下面几个点出发:
- 有类似的模型或者属性
- 有类似的流程
- 有类似的数据结构和算法
我相信很多人都有过这样的经验。由此可见提炼就是阴阳调和:
- 抽象与架构:对业务的理解,根据领域建模的方法和设计模式产生领域模型抽象和流程抽象,或者计算模型的抽象等等,然后根据这些抽象设计出合理的架构,并让架构健康的向前迭代。
- 计算机科学与技术:对技术深度的把控,包括编程语言,各种框架,SDK,多线程,数据结构,各种网络编程包,各种 xx 引擎(如规则引擎,流程引擎等等)。
而这些都需要工程师们对领域建模和设计模式的抽象技术,以及对相对的技术特性等计算机技术的深入掌握。这里需要强调光知道领域建模和设计模式等是不够的,不同的技术选型特性不一样,会导致在抽象的实现时产生不同的差别。
在复用这件事情上,抽象技术和计算机技术两手抓,两手都要硬。如果用中国古代传统思想来比喻,那可能可以用阴来比喻抽象技术,阳来比喻计算机技术。
尤其是阴,总是给人捉摸不定的感觉,但是如何深入学习,坚持实践总结,我们就会发现阴原来也是有具体方法论的,但是这个具体方法又不是看看书就能学会的,它对知行合一的要求更高。
从学习的步骤来说,一般的过程都是先从阳(计算机科学与技术)开始,因为先从阴(抽象和架构技术)开始没有阳作为支撑是很难把阴融会贯通的。而且最终要达到的是阴阳调和。如果我们过于偏重阴或者过于偏重阳,都会导致阴阳失调,大概就是这个意思。
来到数据部门之后,我发现已经不能用阴阳来形容我们要学的领域了,现在我们搞的比较多的是统计分析和机器学习(统计分析和机器学习有交集,也有区别),所以目前对我们团队来说,我们的同学有三门学科是必须要掌握的:
- 计算机科学与技术
- 抽象与架构
- 统计分析与机器学习
我最近一年看的比较多的是统计分析,有同学钉钉我问道:怎么连你也放弃领域建模了。我没放弃,领域建模是抽象和架构的重要方法(但不是唯一的方法,演绎和归纳也是,自顶向下分解也是),工程技术同学是不能放弃的。学习统计分析及统计学习是因为统计学习 + 计算机科学与技术可以更好的解决工程领域遇到的问题,这也是各条线的工程师需要掌握的技能。
6.3 复用小结
复用是软件中一个非常重要的学问,里面结合了抽象技术和计算机技术,而抽象技术还依赖于对业务的理解程度,所以此非一日之功,需要长时间的锻炼才能有所小成。
当然,有时候即使在技术上可以抽象提炼,但是由于组织架构的问题也会让这样的提炼无法落地,或者这里并不是一个稳定的结构从而导致经常调整,带来的结果是提炼的投入产出比比较小,从而导致无法提炼,这些这里就不详细写了。
七 逻辑架构分层
7.1 分层的分类
工程骨架分层
分层几乎是从每个工程师入门的时候都会接触到的一个普世的概念,在一些书籍里,分层有的被称之为 tier,有的被称之为 layer,比如说 OSI 分层模型是用的 Layer 这个词。而在一些文章里讲到架构时用的是 tier 这个词,当你去查看 wiki 的时候,那就更晕了,因为 wiki 离 tier 和 layer 是混在一起讲的。
谈到分层,各种教科书中分层无不拿出景点的 3 个层次来阐述分层问题,如下:
- presentation layer
- business layer
- data layer
然后还有扩展出 service layer,这些在工程骨架中非常常见,我们几乎从来没有见过不分层的工程骨架,所以当我们讨论架构分层的时候,很多人脑海里第一映像就是工程骨架中的分层。
工程骨架的分层的一个重要目的是:成为代码组织结构的约束,防止代码混乱不堪。
逻辑架构分层
但是我们讲的逻辑架构分层不是指工程骨架分层,为什么不是?首先来看一下逻辑架构的特点:
- 源于业务概念架构(源于业务分析),保留了业务概念架构中大多数的业务功能模块,但是又会通过对技术的提炼从而比业务概念架构更加复杂。
- 逻辑架构中上下左右模块之间存在依赖关系,所以确定模块依赖关系是一个非常重要的话题。
- 逻辑架构是分片的,一般来说同一个层次会存在多个模块,像兄弟一样。
根据这个特点,我们可以模糊的看出逻辑架构的分层主要是逻辑架构中各模块的调用关系,甚至更偏向从模块职责的角度来进行归纳从而得出层次。
这种分层的目的是:对同一类职责的模块进行职责上的约束,此时还不一定有代码的存在。
两者的区别
这么看来这两个分层是有着本质的区别:
- 目的上:逻辑架构中的分层是逻辑架构中各模块间的依赖层次关系,以及模块的再抽象。而项目骨架中的分层是代码的组织形式的一种约束。
- 形式上:某个逻辑架构中某个层次上的应用内部依然是存在工程骨架分层的,比如说购物车模块依赖了营销模块和商品模块,他们在逻辑架构上可能是不同的层次,但是购物车,营销内部的工程骨架上依然进行presentation, business, repository 之类的分层。
也许有的同学会说了,再大的架构(就比如说某个 BU 的逻辑架构),我也可以将最靠近用户的模块划分成 presentation layer,中间的所有模块都划分为 business layer,最下面的我都划分成 presentation layer。没错,你可以这样做,但是这样做基本没有任何意义,不能带来指导作用,失去的分层的目的。
7.2 分层的案例
在文件系统或者网络协议上,也有各种层次的封装。如下图所示:
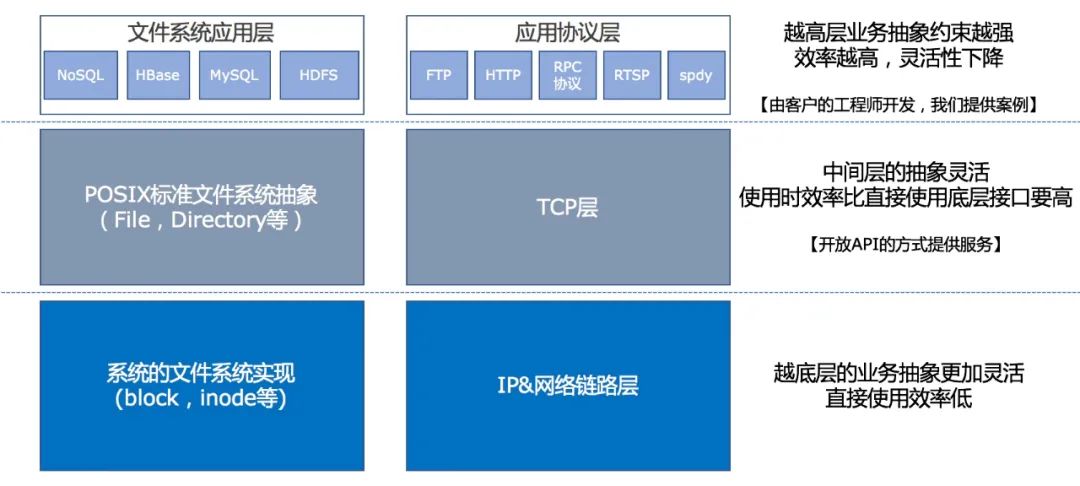
这个图中每个模块在不同阶段都有不同阶段要解决的问题,然后每个模块都可以分解,产生更细粒度的模块,这里重点是让大家了解到什么是逻辑架构中模块的分层。
- 宏观上来看,处于上层的模块会依赖处于下层的模块
- 同一层的模块有时候也会产生依赖关系
- 在层次上可以用箭头标注数据流或者调用流
不过这些都不是问题,问题是什么呢?
问题是我们必须时刻知道,目前我们在不同层次的这些模块存在哪些问题,以及不同层次在解决什么问题。比如说上述的操作系统中文件系统和协议分层中,最底层的是跟硬件打交道,能够精准的控制硬件,中间是对操作系统的用户暴露的,更简单易用,上层是针对应用来使用,解决特定领域的问题,不同的层次做了不同的抽象,也是在解决不同的问题。
7.3 某些领域建模书籍之中的分层
很多人及一些书中,谈分层必谈工程骨架的分层,这个分层和架构中的分层是两回事,如果我们在谈架构,那么我们要避免把重心放到项目骨架的分层上。
比如说领域建模的相关书籍中,经常会讲到 service, domain, repository 之流,这个些概念处于架构中的什么位置,我们应该什么时候去关心这些概念?
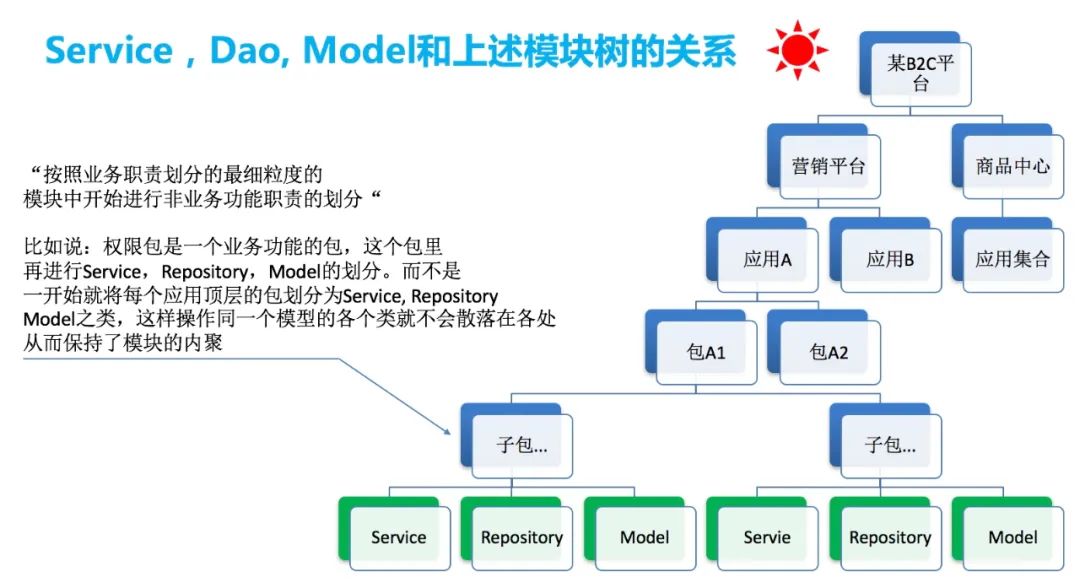
如图所示,在细粒度模块内部,按照纯技术职责来进行划分时,我们将之撸成 service, model, repository,integration 之流的工程骨架,值得注意的是工程骨架的划分层次和具体的业务逻辑架构是没有关系的,他更偏技术,他的职责是对代码做一个高层次的组织和管理。
按照正常流程,系统模型产出之后,应该紧接着考虑模块的设定,依赖,规约,但是很不幸,很多书籍和资料都把 service, model, repository,integration 这部分分层的内容作为了领域的建模的最重要的重点之一。
某些书里的这种观点是不符合实际工作流程的,实际工作时,在领域模型之后我们先考虑的是架构中的各个模块的位置和职责,以及模块内部的子模块,模块之间的关系,以及整体的约束等等(请参考文章开头对架构的定义)。具体表现就是我们在逻辑架构图中不会去画什么 service, model, repository, integration 之类的层。
工程骨架的分层在细粒度模块内部,这是基础设施架构的一部分,也许是你手头目前最重要的部分,但是对于整个应用逻辑架构来说不是最核心的部分也不是最需要先考虑的内容。也就是说,即使你不分 service, model 之类的,对应用逻辑架构中模块的职责划分也是没有影响的。
同时我也见过一些项目,应用逻辑架构比较明确了,但是在落地到物理架构时,把逻辑架构中的所有模块都放在 service 包里,而且没有再分包,这就不合适了,逻辑架构中的模块完全没有落地。
所以我现在在我们部门的项目中,坚决避免将 service, model, repository,integration 之类的放到最高层来考虑。而是将逻辑架构的设计切切实实的落地,这样根据逻辑架构,我们就能看到的我们具体的应用,和应用内包的组织情况。
再次强调:逻辑架构中的分层不是指 service, model,repository, integration 之流的分层,而是指功能模块的分层。如果不了解业务,如果不了解业务概念模块,如果没有业务概念架构,我们是很难做出合理的应用逻辑架构的(当然也包括逻辑架构中模块的分层),撇开业务特征直接谈逻辑架构的分层是不行的。
模块的职责确定之后,模块之间的依赖也必须要确定,然后模块对外暴露接口需要定义规范和技术实现的手段。比如,如果是 restful 接口,那么应该是什么样的规范对外定义,如果是内部的服务的接口,应该是什么样的规范。由于本文篇幅所限,此处不进行详述,前者可参考各大平台的开放接口,后者可参考各 BU 内部服务调用的相关规范,如果没有,那说需要制定一个统一的规范。
八 逻辑架构是分粒度的
8.1 逻辑架构颗粒度树
这里我引入了一个新概念:逻辑架构颗粒度树。
刚刚讲的都是 2 维上的架构,我们可以看到,架构推导是有方法的,而且如果对方法进行提炼,就是横和竖的问题,但是正如我们开始讲到的,架构也可以是 3 维的,那就是在二维的模块中存在各种粒度子模块或者父模块。
如果非要打个比喻的话,那么下面的宇宙星神合体是一个大的架构:

里面分成了很多小模块,比如物质飞船,探测器等等,而每个小模块又是有很多基础模块构成,宇宙星神合体中只有 3 个层次,及基础部件,模块,及最终的星神合体,它们代表着不同的粒度。而对于业务复杂的架构来说,粒度会更多,层次就会更多。这取决于N个研发资源投入在某个模块上的效率最高,而这个 N 在某个阶段的技术限制下应该是一个比较稳定的值!
抽象一下,模块在不同粒度上,可以整成这么一棵树:
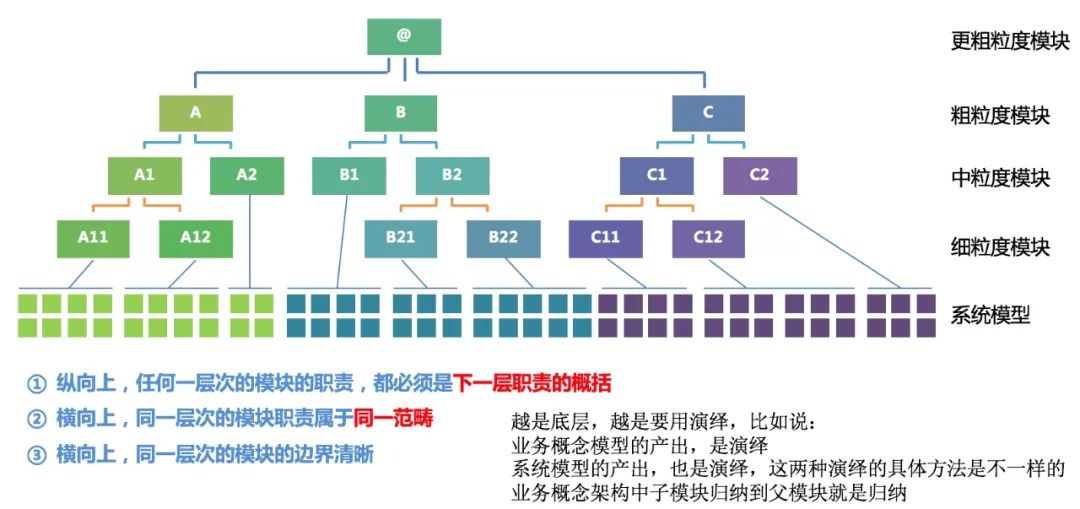
逻辑架构粒度树的 3 条原则:
- 纵向上,任何一层次的模块的职责,都必须是下一层职责的概括
- 横向上,同一层次的模块职责属于同一范畴
- 横向上,同一层次的模块的边界清晰
上述的树形结构,只能描绘出模块和父模块,子模块的关系,但是不能完整的描绘出模块之间的关系,是处于同一层次,还是处在不同层次(就是前面提到的应用逻辑架构中横的问题和竖的问题)。
那么用什么样的图形既可以生动的表达出模块和父模块,及子模块的关系,又能表达出不同模块之间的关系呢,我想了很久,也没有想到一个更容易理解的图形,最后产出了下面这么一幅图:

图中有三层,但是现实生活中可能超过三层,也可能低于三层。我们能归纳的层次越高,那可能我们接触的东西就越宽广,越精深。
这里有一个严肃的话题需要提一下:是不是一线工程师不用考虑逻辑架构问题?当然不是,任何一个同学,你手头的工作都是跟架构相关的,你负责模块可能也存在子模块,而且必定会存在父模块,出于工作,你必须要理解不断迭代你模块中的设计,同时随着能力的成长,你必须要关注你的父模块,父模块的父模块,日积月累,你可以 hold 住的模块粒度会越来越大,你的职责和能力要求会越来越大。
8.2 模块颗粒度树落地情况
在下述架构模块颗粒度树中,并没有模块和模块之间的依赖关系,这里只是为了概要的说明模块落地到物理架构中的一个演变过程,而具体的案例我们放在后面的文章中来进行阐述。
模块树上的这些不同粒度的模块,在具体落地成物理架构时,可以是不同的形式,如下:
- 可能是子包
- 可能是顶层的包
- 可能是应用
- 可能是一组应用的集合,负责某种职责
- 也可能是某个平台(如营销平台,商品中心等)
- 更有可能更大层次的平台,比如 B2C
为什么会出现这种情况呢,因为不同的模块在业务的发展的不同时期:
- 模块中的逻辑的复杂度不一样
- 模块的粒度本身也在发生变化
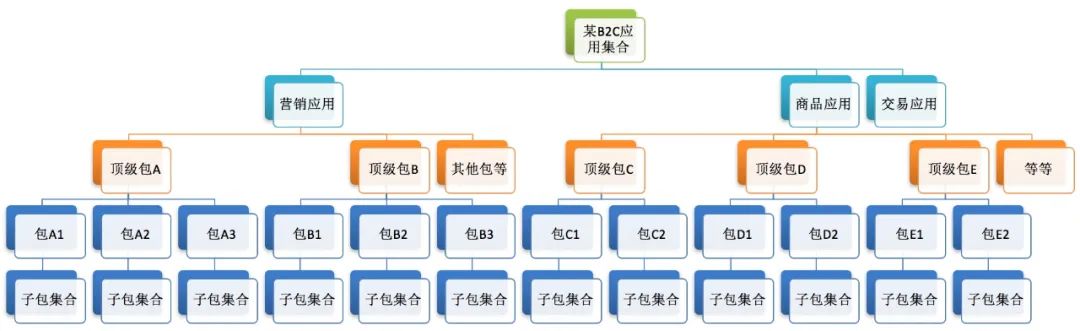
那么我们来看看一个网站从小到大的逻辑架构模块树落地的变化情况。
小型业务逻辑架构的模块树落地情况
很显然,这里是一个电商网站起步时候的样子,所有模块都有模有样,只是模块中的逻辑比较简单,这些模块都以包的形式存在于一个应用之中,这个应用是一个大泥球。但是由于模块的职责划分合理,粒度的治理也比较符合发展要求,所以这样的应用在分拆成分布式的时候阻力会比较小。而那些模块职责不合理的大泥球应用,随着业务的发展,要分拆成分布式应用,阻力就大很多。
中型业务逻辑架构的模块树落地情况
这是一个度过初期阶段的电商网站,营销,商品,交易模块等已经成型,而且得益之前的模块划分,架构师可以很快的将初期的多个顶级包,分拆出来,变成多个应用。
大型业务逻辑架构的模块树落地情况
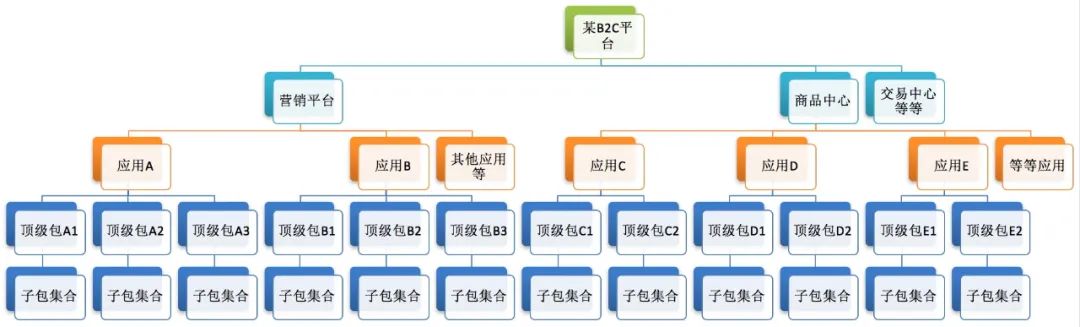
到了这个时期,已经是一个大型电商网站的样子了,营销平台内部已经分拆出了多个应用,得益于上一阶段中各模块职责的合理分配,所以架构师将在将物理架构进化成这个样子的时候,力气不需要花在逻辑架构的治理上,可以把精力集中投入到物理架构及基础设施架构的建设上,比如同城容灾,异地多活等等。
8.3 再发展成巨型的架构呢?
中台概念抽象
我不知道,比如中台是不是,要把电商业务中所有的相对稳定的核心抽象出来,可能是领域模型,可能是业务流程转换而成的系统流程,可能是一个计算模型或者算法等等。然后变化的内容(前台)可以依托于这个大的核心概念快速的迭代。如果需要图形化来做概要的理解,我想应该是这样的:
一旦要做一个中台,那么以为着这个中台对前台来说就是一个技术产品,则要考虑如下几个方面的内容:
稳定性性能的要求是极高的,需要有体系化稳定性和性能体系
产品运营是非常重要的,到售前,到售后有一个完整的流程
目的就是要提高客户的生产效率。
是否存在中台的判断依据是什么?
多个业务线有无重复的流程抽象,有无重复的领域模型抽象,有无重复的计算模型(数据结构和算法)等等,有无重复的辅助性设施。他们是否在重复建设,等等。
在演变的过程中变化是什么呢?需要的是学习能力,沟通能力,协调资源的能力,领导力,影响力,评估人的能力和用人的能力等等。这些能力需要涉及的范围都从一个小的组织向一个更大的组织前进。
大音希声,大象无形,不管如何发展,基础的规律都还是不变的。
8.4 逻辑模块落地的相关考量维度
当一个逻辑模块要落地时,我们如何判断一个模块落地成包,还是应用等等,有很多判断的维度,比如:
效率(多少人维护一个应用效率最高)
到底多少人的团队协作效率最高?作为一个应用,在技术不断进步的情况下(比如说新的容器之类的),或者要面对的业务的复杂度不同的情况下,同时可维护的人数也是不一样的,具体目前变化到多少,目前基本是靠经验,然后遇到问题再调整,根据主管的经验不断调整和优化,以达到一个适合当前阶段的最优值,目前我自己这边大概5人左右一个攻坚小组,遇到更大问题域,那就拆解。
稳定性
- 强弱依赖
- 核心与非核心分离
性能
QPS,包括模块内部的技术实现,是使用多线程还是协程,容量评估,到压测,等等,里面大量的内容。光是线程这一节就有需要研究很久最大 QPS 推导及同步异步问题:
RT,减少 wait time? 减少 cpu time?从浏览器,到网络,到服务器,到存储等每个环节,比如说网络上有一个重要的公式:BDP = BD * RTT,把这个公式背后的相关知识点搞清楚,那么网络优化的很多方法的理论依据我们就搞清楚了。
这里面,效率,稳定性,性能是最影响逻辑架构落地成物理架构的三大主要因素。
九 全文总结
9.1 架构的定义和价值
我们在文章的开头对架构两个字给出了一个官方定义,然后按照笔者自己对架构的理解又对架构进行了分类,在架构分类中,出现了产品功能架构,业务架构,应用逻辑架构,应用物理架构等等。
不同的架构都是在解释不同的问题,比如:
- 产品功能架构强调的是功能模块能力,受众是最终使用产品的用户等。
- 业务架构是对业务的一种分析和理解,用来如何更好的构建产品,受众是产品的同学和技术同学。
- 应用逻辑架构强调的是研发时,各逻辑模块的职责,受众是研发的同学及架构师。
正确分析出当前的场合(受众和目的)应该用什么样的架构来阐述我们的意图是非常重要的。
同时我们可以看到小到一个mis系统,大到整个阿里,都可以用架构的角度来解释,架构中出现的各种中台,后台,各种框架等等其实都是架构方法产出的结果。系统大小不一样,抽象的方法是类似的。
架构产生之后,随着业务的迭代,架构不治理,模块职责和依赖,层次不清晰,约束不明确。稳定性,性能,成本都受到影响。积弊越久,回头越难,有时候不得不重头来过。
9.2 自底向上重度依赖于演绎和归纳
为了避免推倒重造的问题发生,我们需要不断的自底向上的方式来修正架构,修正其实是在做局部的模块重构,谈到修正,具体的方法是由这里就不得正视归纳和演绎的重要性了,而这里的演绎和归纳是抽象的核心概括。
自底向上的推导的重点在于演绎和归纳,越是底层的越是要使用演绎的方法,越是高层的越是使用归纳。
这两种方法应该什么时候使用?显然当我们的目标(比如说业务目标)或者结论是非常高粒度的时候,需要分解,那么使用自顶向下的推导,在规划未来时一般会用到类似的自顶向下的方法,产出我们宏观结论。
而如果是产品方案已经明确,程序员需要理解这个业务需求,并根据产品方案推导出架构,此时一般使用自底向上的方法,而领域建模就是这种自底向上的分析方法。
对于自底向上的分析方法,如果提炼一下关键词,会得到如下两个关键词:
演绎
演绎就是逻辑推导,越是底层的,越需要演绎:
- 从用例到业务模型就属于演绎
- 从业务模型到系统模型也属于演绎
- 根据目前的问题,推导出要实施某种稳定性措施,这是也是演绎
归纳
这里的归纳是根据事物的某个维度来进行归类,越是高层的,越需要归纳:
- 问题空间模块划分属于归纳
- 逻辑架构中有部分也属于归纳
- 根据一堆稳定性问题,归纳出,事前,事中,事后都需要做对应的操作,是就是根据时间维度来进行归纳。
关于归纳,我们前面已经做了大量的讲解,所以这里我们重点阐述一下演绎:
1)我们从对业务的理解,演绎出用例,从用例演绎抽象出业务概念模型,从业务概念演绎抽象出系统模型,从系统模型演绎抽象出物理存储模型。这是一个从 A 推导出 B,从 B 推导出 C,从 C 推导出 D,从 D 推导出E的过程,而在 B,C,D 上又有很多逻辑分支。推导出的层次越深,逻辑分支越广(保障每层的准确度的基础上),一般来说实力越强。
2)我们从对业务的理解,演绎出用例,从用例演绎出业务流程,再从业务流程演绎抽象成系统流程,然后再演绎成数据流。这是也是一个从 A 推导出 B,从 B 推导出 C’,从 C’ 推导成 D’,从 D’ 推导出 E’ 的过程。这个推导过程比如有方法论辅助,否则逻辑的深度和广度都会受到影响。
总的来说:演绎推导的层次越深,分支逻辑越多,越能穿透迷雾,看问题就越透彻,说明功力越深厚。
打个比喻就是:对应相同品种的树来说,小树的根系和大树的根系在地下深入的长度和广度是完全不一样的,人的逻辑能力大抵也是如此。
其实我们工作中很多时候都在使用演绎和归纳,只是我们不知道我们在使用这类方法,看到这篇文章之后也许可以给大家带去一些思考,看清楚我们自己以前的工作到底是如何使用演绎和归纳的,以及如何改进以前的方法。
9.3 逻辑架构的自底向上推演
除了自底向上的通用思考方法之外,我们还必须要了解计算机领域的相关技能和套路才能产出合适的结果:
这张图是有严密的逻辑路径的,每个步骤的输入,都是上个步骤的输出。更关键的是这个张图是有顺序的,做架构要从上往下做,不可自顾自,不可撇开业务闭门造车。
为什么前面我们问题空间领域模型聊了这么多,原因就是问题空间的领域建模其实是分析阶段,如果分析阶段我们没有做正确,那么设计阶段我们能做正确的可能性是非常小的。
分析阶段,我们得出了正确的分析产出,那么我们在设计阶段,又根据合理正确的方法论,我们就可以得到合理正确的应用逻辑架构。
同时我们可以看出领域建模是抽象和架构的重要方法,但不是唯一的方法,因为归纳和演绎也是抽象及架构的重要方法,自顶向下推演也是架构的重要方法。
这套方法论的关键性总结应该是这样的:
- 架构问题是我们工作中常见的问题,我们要注意识别并定义架构中的问题
- 业务概念模型的产出是通过具体的方法演绎出来的
- 业务概念架构的产出是通过具体的方法归纳出来的
- 系统模型和数据模型的产出是通过具体的方法演绎出来的
- 应用逻辑架构的产出是通过对前面的产出归纳和演绎出来的
- 架构内模块的构建,模块的依赖关系,及约束
- 模块的粒度,父子模块的归纳
- 提炼可复用模块
- 纯技术模块的产生
- 逻辑架构的分层
- 物理架构的演进受逻辑架构的影响
- 研究业界现有的技术架构
- 应用逻辑架构推导所使用的归纳和演绎方法涉及到很多具体的知识
最重要的是这个过程是不断迭代的,这句话比什么都重要,只有运动着的架构,没有静止的架构。有的架构运动时进行不断的重构和调整,所以经久不衰,有的架构缺乏这样的自我否定机制,最终走向衰败。
PS:由于我架构水平,写作水平,及认知所限,有很多我自己都不知道自己不知道的规律和事实存在。所以文中整体思路和细节之处不免存在纰漏之处,还望大家不吝指出,谢谢。

若有收获,就点个赞吧
0 人点赞
