3D human pose estimation in video with temporal convolutions and semi-supervised training paper code project
原文链接:https://www.yuque.com/jinluzhang/researchblog/videopose3d
Summary
提出了一种针对视频的3D Pose估计方法,对时序信息进行处理的半监督方法,其中对时序信息的处理值得借鉴
Problem Statement
3D poses in video,即从2D video中估计3D skeleton pose
Research Objective
First, we present a simple and efficient approach for 3D human pose estimation in video based on dilated temporal convolutions on 2D keypoint trajectories
Second, we introduce a semi-supervised approach which exploits unlabeled video, and is effective when labeled data is scarce.
提出一种基于时序扩张卷积的3D pose模型,在video的2D keypoint检测基础上得到3D pose,在保证准确率的同时比RNN-based方法更有效率(可以同步处理多个frame);
并提出一种半监督方法,只要求相机参数
不利用extra labeled data,达到SOTA
Method
网络结构
算法: VideoPose3D
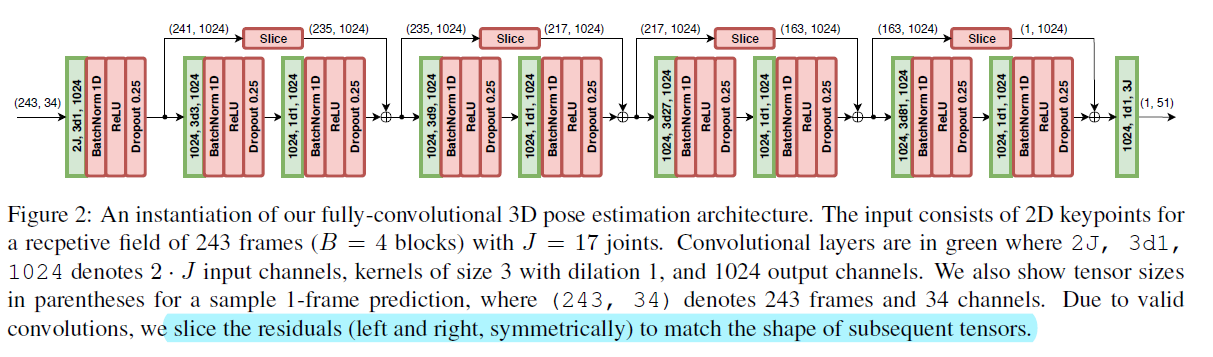
输入为J个joints的二维坐标,在第一层进行3*3卷积(注意这里是dilation=1的扩张卷积),BN,ReLU和dropout,参数为kernel=3,output=1024,dropout=0.25。之后用4个 Res Block进行跳跃连接,slice中进行的是1D卷积。
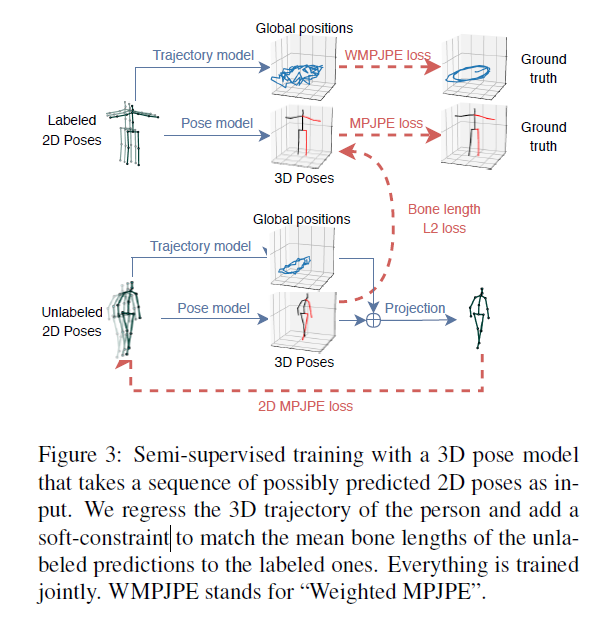
半监督方法
Keypoint
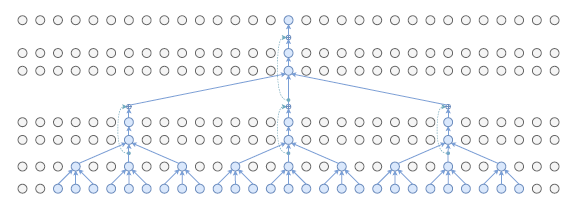
1. Dilated Convolution
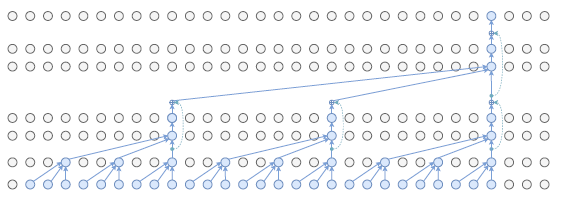
2. Causal Convolutions
3. Semi-supervised approach
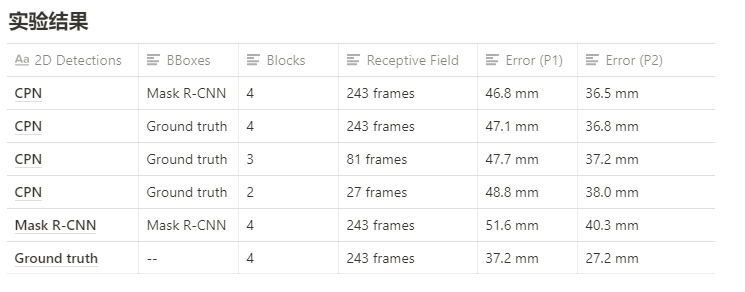
Evaluation
实验结果,作者如何评估自己的方法,实验的setup是什么样的,有没有问题或者可以借鉴的地方。
Conclusion
**
需改进的点
- 直接卷积 2DPose 估计3D Pose 太粗暴
- dilated conv尺度单一,不具有尺度不变性,对于too slow/too fast action不能很好的适应
- 遮挡问题没有解决
- 半监督方法中,没有很好的利用global position这个监督信息,只是回归了bone length loss
- 不如multi-view方法精准
**

若有收获,就点个赞吧
0 人点赞
