Learning Skeletal Graph Neural Networks for Hard 3D Pose Estimation
原文链接:https://www.yuque.com/jinluzhang/researchblog/d-hcsf
Summary🔖
写完笔记之后最后填,概述文章的内容,以后查阅笔记的时候先看这一段。
注:写文章summary切记需要通过自己的思考,用自己的语言描述。切忌直接Ctrl + c原文。
Motivation👓
试图提高具有深度模糊、自遮挡和复杂或罕见姿势的困难姿势(Hard Pose)上的表现,现有的方案往往在困难姿势(Hard Pose)上的精度很差,从而影响了整体精度,也影响了downstream task的表现(如skeleton action)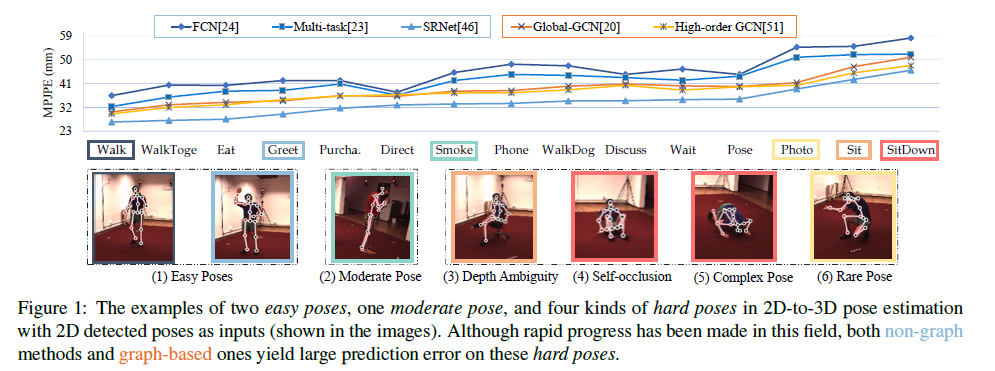
具体来说,现有的方法之所以没能解决hard pose的问题,主要在于:
- Existing works do not consider such signal-to-noise issues(GNN的邻接矩阵把噪声也同样学习了)
- It is rather difficult to capture such information with a static skeleton graph across all poses(静态图邻接矩阵带来的固定权重问题,不能适应所有的pose)
针对以上问题,作者又提出两点observation(Sec. 2.3):
- Distant neighbors pass not only valuable semantic in
formation
but also irrelevant noise
远距离节点在带来有用的语义信息的同时也会带来noise Dynamic graph construction is useful but should be delicately designed
动态网络结构有用但需要被精心设计Method💡
Overview
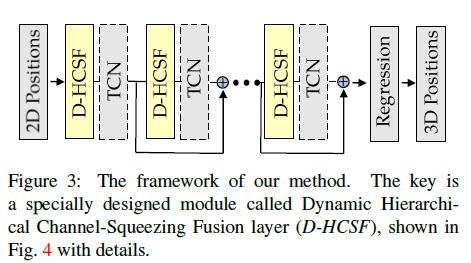
框架图
作者提出了一种基于图神经网络GNN的方案,主要创新点在于:We propose a hop-aware hierarchical channel squeezing fusion layer
- We propose a temporal-aware dynamic graph construction procedure
(起名起的好长。。)
第一点用来抑制噪声(对应上面第一点),第二点用来根据时序动作变化动态的改变邻接矩阵的权重,有些类似attention的思想(对应上面第二点)
Hierarchical Channel Squeezing
Fusion Layer (HCSF)
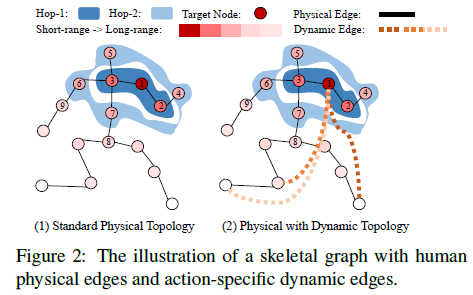
给skeleton中的nodes做了编号和分级,红色(编号1)为要学习的node,深蓝浅蓝是邻接和次邻接的nodes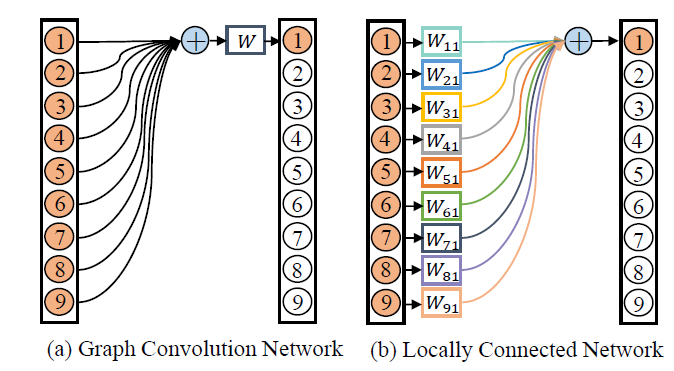
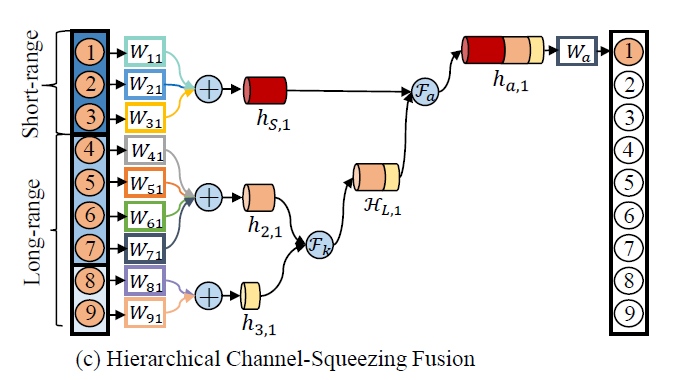
上图是两种baseline,下图是本为提出的方法。
这部分可以分成两点:长短范围分离融合和通道压缩
长短范围融合是给nodes划分了三个级别,先把长期两个特征的融合,再和短期的进行fusion;
通道压缩是基于之前的工作(light multi-order convolution and pooling for graph classification),设置了一个the
oretical
Information Gain (IG) analysis信息增益分析,IG遵从范围越远得到有用信息越少的规律,并呈指数型下降。因此这部分对三个级别的特征分别压缩(越远的压缩程度越大)。
Temporal-aware
Dynamic Graph Learning
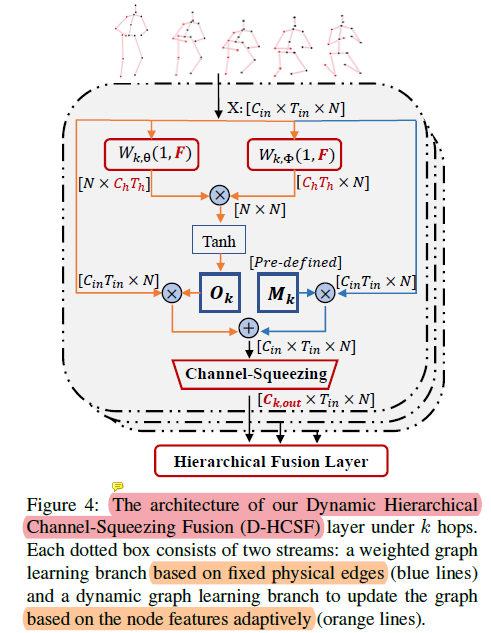
感觉这部分(橙色线)像是self-attention的操作,利用时序信息为邻接矩阵加权重
Evaluation🧪
Dataset
Metrics
Result
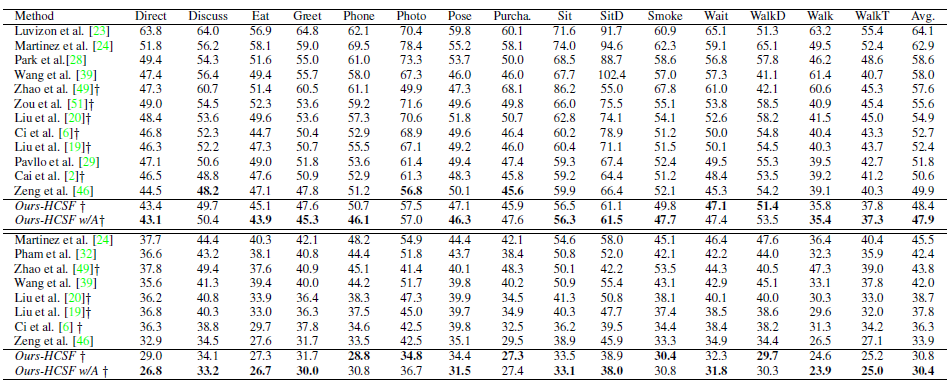

Rethink❓
亮点/可借鉴之处:
- 作者分级进行通道压缩是我之前没有想到过的,可以进一步看下相关文献(light multi-order convolution and pooling for graph classification)
- 文中使用attention的方式(个人理解)不是作为一个独立模块迁移过来,而是作为一个更新邻接矩阵权重的手段,这点比较好
局限性:
- HCSF跳跃分层融合需要设计地很精致,但如果放在一个全新的拓扑结构上是否又需要重新设定合理的分级?能不能把分级的过程也动态化?
- 模型压缩的比例怎么确定这部分,没有看太明白
- 最后就是code还没有release,希望作者加把力哈哈
- 写作方面,作者把常见的第二部分related work改为了Preliminaries and Motivation,尤其是在最后加入了Observation and Motivation章节描述自己的动机和观察到的现状,但这部分在introduction部分已经提到过,或许sec. 2.3放在intro里会好一些?不过写作本来就是见仁见智的事情
- 作者的图有点乱,比如fig2和fig5放在一起会更好,fig4和fig5调换一下位置也更符合文章的描述顺序
Track📚
- light multi-order convolution and pooling for graph classification
- Hop-aware dimension optimization for graph neural networks
- Srnet: Improving generalization in 3d human pose estimation with a split-and-recombine approach

若有收获,就点个赞吧
0 人点赞
