分组执行将准备执行阶段生成的执行单元分组下发至底层并发执行引擎,并针对执行过程中的每个关键步骤发送事件。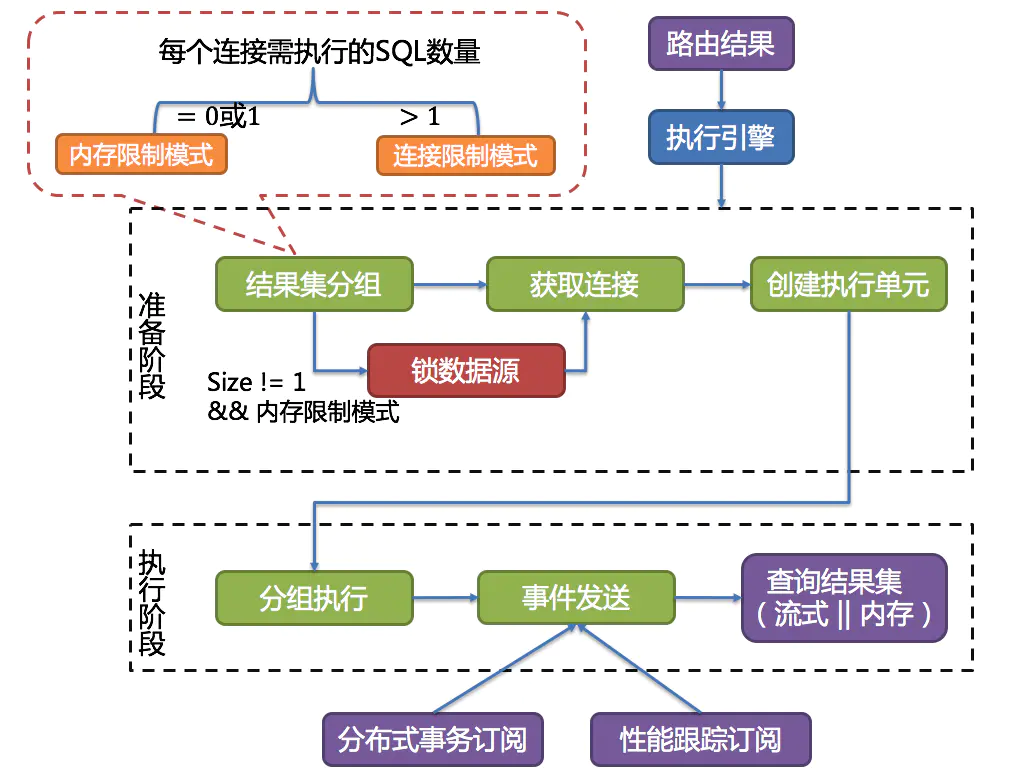
书接上文

结束完initPreparedStatementExecutor方法就该执行execute方法了,即真正的执行SQL语句,本节也将主要围绕该方法进行展开。
源码分析
execute源码如下:
public boolean execute() throws SQLException {boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();SQLExecuteCallback<Boolean> executeCallback = SQLExecuteCallbackFactory.getPreparedSQLExecuteCallback(this.getDatabaseType(), isExceptionThrown);List<Boolean> result = this.executeCallback(executeCallback);return null != result && !result.isEmpty() && null != result.get(0) ? (Boolean)result.get(0) : false;}
这块的逻辑即SQLExecuteCallback内部存放真正的SQL,executeCallback来执行并获得回调。
executeCallback:
protected final <T> List<T> executeCallback(SQLExecuteCallback<T> executeCallback) throws SQLException {List<T> result = this.sqlExecuteTemplate.execute(this.inputGroups, executeCallback);this.refreshMetaDataIfNeeded(this.connection.getRuntimeContext(), this.sqlStatementContext);return result;}
追踪execute:
public <I, O> List<O> execute(Collection<InputGroup<I>> inputGroups, GroupedCallback<I, O> firstCallback, GroupedCallback<I, O> callback, boolean serial) throws SQLException {if (inputGroups.isEmpty()) {return Collections.emptyList();} else {return serial ? this.serialExecute(inputGroups, firstCallback, callback) : this.parallelExecute(inputGroups, firstCallback, callback);}}
这里把执行分为了并发执行和串行执行,这里以parallelExecute为例进行分析。
parallelExecute
private <I, O> List<O> parallelExecute(Collection<InputGroup<I>> inputGroups, GroupedCallback<I, O> firstCallback, GroupedCallback<I, O> callback) throws SQLException {Iterator<InputGroup<I>> inputGroupsIterator = inputGroups.iterator();InputGroup<I> firstInputs = (InputGroup)inputGroupsIterator.next();Collection<ListenableFuture<Collection<O>>> restResultFutures = this.asyncExecute((List)Lists.newArrayList(inputGroupsIterator), callback);return this.getGroupResults(this.syncExecute(firstInputs, null == firstCallback ? callback : firstCallback), restResultFutures);}
inputGroupsIterator是准备阶段的结果,这段代码里,第一个同步执行,剩下的都异步执行。
asyncExecute
异步执行的源码如下:
private <I, O> Collection<ListenableFuture<Collection<O>>> asyncExecute(List<InputGroup<I>> inputGroups, GroupedCallback<I, O> callback) {Collection<ListenableFuture<Collection<O>>> result = new LinkedList();Iterator var4 = inputGroups.iterator();while(var4.hasNext()) {InputGroup<I> each = (InputGroup)var4.next();result.add(this.asyncExecute(each, callback));}return result;}
继续:
private <I, O> ListenableFuture<Collection<O>> asyncExecute(InputGroup<I> inputGroup, GroupedCallback<I, O> callback) {Map<String, Object> dataMap = ExecutorDataMap.getValue();return this.executorService.getExecutorService().submit(() -> {return callback.execute(inputGroup.getInputs(), false, dataMap);});}
继续:
public final Collection<T> execute(Collection<StatementExecuteUnit> statementExecuteUnits, boolean isTrunkThread, Map<String, Object> dataMap) throws SQLException {Collection<T> result = new LinkedList();Iterator var5 = statementExecuteUnits.iterator();while(var5.hasNext()) {StatementExecuteUnit each = (StatementExecuteUnit)var5.next();result.add(this.execute0(each, isTrunkThread, dataMap));}return result;}
继续:
private T execute0(StatementExecuteUnit statementExecuteUnit, boolean isTrunkThread, Map<String, Object> dataMap) throws SQLException {ExecutorExceptionHandler.setExceptionThrown(this.isExceptionThrown);DataSourceMetaData dataSourceMetaData = this.getDataSourceMetaData(statementExecuteUnit.getStatement().getConnection().getMetaData());SPISQLExecutionHook sqlExecutionHook = new SPISQLExecutionHook();try {ExecutionUnit executionUnit = statementExecuteUnit.getExecutionUnit();sqlExecutionHook.start(executionUnit.getDataSourceName(), executionUnit.getSqlUnit().getSql(), executionUnit.getSqlUnit().getParameters(), dataSourceMetaData, isTrunkThread, dataMap);T result = this.executeSQL(executionUnit.getSqlUnit().getSql(), statementExecuteUnit.getStatement(), statementExecuteUnit.getConnectionMode());sqlExecutionHook.finishSuccess();return result;} catch (SQLException var8) {sqlExecutionHook.finishFailure(var8);ExecutorExceptionHandler.handleException(var8);return null;}}
getGroupResults
异步执行完以后通过getGroupResults来获取结果,其源码如下:
private <O> List<O> getGroupResults(Collection<O> firstResults, Collection<ListenableFuture<Collection<O>>> restFutures) throws SQLException {List<O> result = new LinkedList(firstResults);Iterator var4 = restFutures.iterator();while(var4.hasNext()) {ListenableFuture each = (ListenableFuture)var4.next();try {result.addAll((Collection)each.get());} catch (ExecutionException | InterruptedException var7) {return this.throwException(var7);}}return result;}
回到Mybatis的query方法中:
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {PreparedStatement ps = (PreparedStatement)statement;ps.execute();return this.resultSetHandler.handleResultSets(ps);}
准备获取结果,即归并的过程。

若有收获,就点个赞吧
0 人点赞
