官方对于连接数据库有两种模式一种是内存限制模式,一种是连接限制模式,即限制连接数量和不限制连接数量的两种方式,无论哪种都不需要用户进行操作ShardingSphere都会自动去选择使用。
书接上文
经过路由和改写以后,代码行来到了initPreparedStatementExecutor,其源码如下:
这里显然进行了许多初始化工作,想必会有建立连接的步骤,因此定位于此,准备进行分析。
init
init方法是初始化的第一步,其源码如下:
这里先设置了SqlStatement的上下文,然后调用了obtainExecuteGroups方法,其源码如下:
private Collection<InputGroup<StatementExecuteUnit>> obtainExecuteGroups(Collection<ExecutionUnit> executionUnits) throws SQLException {return this.getSqlExecutePrepareTemplate().getExecuteUnitGroups(executionUnits, new SQLExecutePrepareCallback() {public List<Connection> getConnections(ConnectionMode connectionMode, String dataSourceName, int connectionSize) throws SQLException {return PreparedStatementExecutor.super.getConnection().getConnections(connectionMode, dataSourceName, connectionSize);}public StatementExecuteUnit createStatementExecuteUnit(Connection connection, ExecutionUnit executionUnit, ConnectionMode connectionMode) throws SQLException {return new StatementExecuteUnit(executionUnit, PreparedStatementExecutor.this.createPreparedStatement(connection, executionUnit.getSqlUnit().getSql()), connectionMode);}});}
这里创建了两个回调函数:getConnections、createStatementExecuteUnit,先不管是啥,后续有分析。
getExecuteUnitGroups方法以数据源为单位进行分组,其源码如下:
public Collection<InputGroup<StatementExecuteUnit>> getExecuteUnitGroups(Collection<ExecutionUnit> executionUnits, SQLExecutePrepareCallback callback) throws SQLException {return this.getSynchronizedExecuteUnitGroups(executionUnits, callback);}
getSynchronizedExecuteUnitGroups:
private Collection<InputGroup<StatementExecuteUnit>> getSynchronizedExecuteUnitGroups(Collection<ExecutionUnit> executionUnits, SQLExecutePrepareCallback callback) throws SQLException {Map<String, List<SQLUnit>> sqlUnitGroups = this.getSQLUnitGroups(executionUnits);Collection<InputGroup<StatementExecuteUnit>> result = new LinkedList();Iterator var5 = sqlUnitGroups.entrySet().iterator();while(var5.hasNext()) {Entry<String, List<SQLUnit>> entry = (Entry)var5.next();result.addAll(this.getSQLExecuteGroups((String)entry.getKey(), (List)entry.getValue(), callback));}return result;}
getSQLExecuteGroups:
private List<InputGroup<StatementExecuteUnit>> getSQLExecuteGroups(String dataSourceName, List<SQLUnit> sqlUnits, SQLExecutePrepareCallback callback) throws SQLException {List<InputGroup<StatementExecuteUnit>> result = new LinkedList();int desiredPartitionSize = Math.max(0 == sqlUnits.size() % this.maxConnectionsSizePerQuery ? sqlUnits.size() / this.maxConnectionsSizePerQuery : sqlUnits.size() / this.maxConnectionsSizePerQuery + 1, 1);List<List<SQLUnit>> sqlUnitPartitions = Lists.partition(sqlUnits, desiredPartitionSize);ConnectionMode connectionMode = this.maxConnectionsSizePerQuery < sqlUnits.size() ? ConnectionMode.CONNECTION_STRICTLY : ConnectionMode.MEMORY_STRICTLY;List<Connection> connections = callback.getConnections(connectionMode, dataSourceName, sqlUnitPartitions.size());int count = 0;Iterator var10 = sqlUnitPartitions.iterator();while(var10.hasNext()) {List<SQLUnit> each = (List)var10.next();result.add(this.getSQLExecuteGroup(connectionMode, (Connection)connections.get(count++), dataSourceName, each, callback));}return result;}
创建连接
sqlUnitPartitions根据执行的sql数量和desiredPartitionSize来给sql分组,计算规则如下图所示: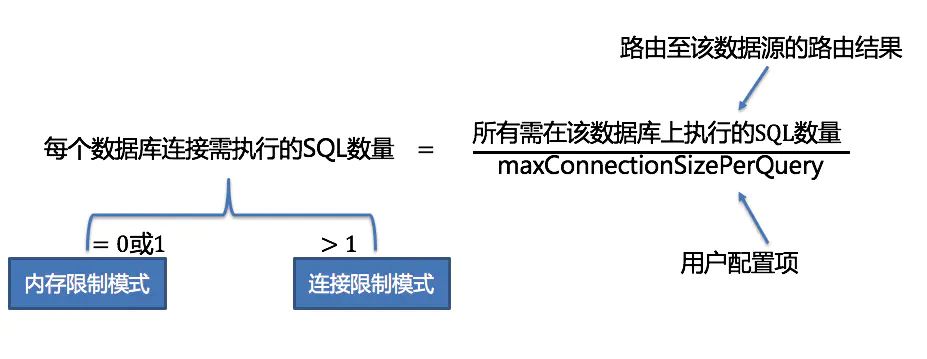 分组后通过回调函数getConnections将生成的连接放入到connections中,getConnection的源码如下:
分组后通过回调函数getConnections将生成的连接放入到connections中,getConnection的源码如下:
public final List<Connection> getConnections(ConnectionMode connectionMode, String dataSourceName, int connectionSize) throws SQLException {DataSource dataSource = (DataSource)this.getDataSourceMap().get(dataSourceName);Preconditions.checkState(null != dataSource, "Missing the data source name: '%s'", new Object[]{dataSourceName});Collection connections;synchronized(this.cachedConnections) {connections = this.cachedConnections.get(dataSourceName);}Object result;if (connections.size() >= connectionSize) {result = (new ArrayList(connections)).subList(0, connectionSize);} else if (!connections.isEmpty()) {result = new ArrayList(connectionSize);((List)result).addAll(connections);List<Connection> newConnections = this.createConnections(dataSourceName, connectionMode, dataSource, connectionSize - connections.size());((List)result).addAll(newConnections);synchronized(this.cachedConnections) {this.cachedConnections.putAll(dataSourceName, newConnections);}} else {result = new ArrayList(this.createConnections(dataSourceName, connectionMode, dataSource, connectionSize));synchronized(this.cachedConnections) {this.cachedConnections.putAll(dataSourceName, (Iterable)result);}}return (List)result;}
createConnections:
private List<Connection> createConnections(String dataSourceName, ConnectionMode connectionMode, DataSource dataSource, int connectionSize) throws SQLException {if (1 == connectionSize) {Connection connection = this.createConnection(dataSourceName, dataSource);this.replayMethodsInvocation(connection);return Collections.singletonList(connection);} else if (ConnectionMode.CONNECTION_STRICTLY == connectionMode) {return this.createConnections(dataSourceName, dataSource, connectionSize);} else {synchronized(dataSource) {return this.createConnections(dataSourceName, dataSource, connectionSize);}}}
存储连接
创建完连接后通过getSQLExecuteGroup方法存储并返回:
private InputGroup<StatementExecuteUnit> getSQLExecuteGroup(ConnectionMode connectionMode, Connection connection, String dataSourceName, List<SQLUnit> sqlUnitGroup, SQLExecutePrepareCallback callback) throws SQLException {List<StatementExecuteUnit> result = new LinkedList();Iterator var7 = sqlUnitGroup.iterator();while(var7.hasNext()) {SQLUnit each = (SQLUnit)var7.next();result.add(callback.createStatementExecuteUnit(connection, new ExecutionUnit(dataSourceName, each), connectionMode));}return new InputGroup(result);}
createStatementExecuteUnit调用了回调方法创建执行单元。
总结
创建完连接后,在通过initPreparedStatementExecutor的其他方法进行一些必要的初始化操作,准备执行SQL语句。

若有收获,就点个赞吧
0 人点赞
