与4.1.1不同,本次debug的项目没有使用mybatis,为了去除第三方框架带来的源码干扰,本次采用的原生JDBC操作原生ShardingSphereAPI的读写分离+分片。
以下的Debug会深刻的了解为啥ShardingJDBC是嵌入式代码,其究竟如何复写的JDBC代码。
设置断点
上一篇文章阐述了配置文件的读取过程,本次开始阅读运行过程,定位ShardingReplicaQueryAPITest的selectAllTest方法,从第一行开始设置断点进行调试。
跟随断点来到Connection connection = DATASOURCE.getConnection()方法,这里是ShardingSphere的入口方法,由此开始进行debug。
获取connection
其源码如下:
@Overridepublic ShardingSphereConnection getConnection() {return new ShardingSphereConnection(getDataSourceMap(), metaDataContexts, transactionContexts, TransactionTypeHolder.get());}
getDataSourceMap就是获取数据源的K-V值,这里不再赘述,transactionContexts、TransactionTypeHolder.get()为事务部分,这里不是重点故跳过,
这里的metaDataContexts信息如下:
显然这里存储的是一些逻辑信息,即逻辑数据库、逻辑数据表。
ShardingSphereConnection实现自Connection接口,因此其拥有Connection的所有功能,这里只需为该类初始化即可:
public ShardingSphereConnection(final Map<String, DataSource> dataSourceMap,final MetaDataContexts metaDataContexts, final TransactionContexts transactionContexts, final TransactionType transactionType) {this.dataSourceMap = dataSourceMap;this.metaDataContexts = metaDataContexts;this.transactionType = transactionType;shardingTransactionManager = transactionContexts.getDefaultTransactionManagerEngine().getTransactionManager(transactionType);}
获取PreparedStatement
调试来到了:reparedStatement preparedStatement = connection.prepareStatement(sql);
其调用了connection的prepareStatement方法,其源码如下:
@Overridepublic PreparedStatement prepareStatement(final String sql) throws SQLException {return new ShardingSpherePreparedStatement(this, sql);}
这里返回的是ShardingSpherePreparedStatement类的对象,显然ShardingSpherePreparedStatement也实现了PreparedStatement的接口且拥有其全部功能。其构造方法如下:
private ShardingSpherePreparedStatement(final ShardingSphereConnection connection, final String sql,final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability, final boolean returnGeneratedKeys) throws SQLException {if (Strings.isNullOrEmpty(sql)) {throw new SQLException(SQLExceptionConstant.SQL_STRING_NULL_OR_EMPTY);}this.connection = connection;metaDataContexts = connection.getMetaDataContexts();this.sql = sql;statements = new ArrayList<>();parameterSets = new ArrayList<>();ShardingSphereSQLParserEngine sqlParserEngine = new ShardingSphereSQLParserEngine(DatabaseTypeRegistry.getTrunkDatabaseTypeName(metaDataContexts.getDefaultMetaData().getResource().getDatabaseType()));sqlStatement = sqlParserEngine.parse(sql, true);parameterMetaData = new ShardingSphereParameterMetaData(sqlStatement);statementOption = returnGeneratedKeys ? new StatementOption(true) : new StatementOption(resultSetType, resultSetConcurrency, resultSetHoldability);JDBCExecutor jdbcExecutor = new JDBCExecutor(metaDataContexts.getExecutorEngine(), connection.isHoldTransaction());rawExecutor = new RawExecutor(metaDataContexts.getExecutorEngine(), connection.isHoldTransaction());driverJDBCExecutor = new DriverJDBCExecutor(connection.getDataSourceMap(), metaDataContexts, jdbcExecutor);batchPreparedStatementExecutor = new BatchPreparedStatementExecutor(metaDataContexts, jdbcExecutor);kernelProcessor = new KernelProcessor();}
前面的赋值操作暂且略过,重点放在ShardingSphereSQLParserEngine对象的生成上。
ShardingSphereSQLParserEngine
该类的定义为:ShardingSphere SQL parser engine. 即SQL解析引擎。
这段代码如下:ShardingSphereSQLParserEngine sqlParserEngine = new ShardingSphereSQLParserEngine( DatabaseTypeRegistry.getTrunkDatabaseTypeName(metaDataContexts.getDefaultMetaData().getResource().getDatabaseType()));
其中DatabaseTypeRegistry.getTrunkDatabaseTypeName(metaDataContexts.getDefaultMetaData().getResource().getDatabaseType()) 这一大串获得的是数据库类型:
构造方法:
public ShardingSphereSQLParserEngine(final String databaseTypeName) {sqlStatementParserEngine = SQLStatementParserEngineFactory.getSQLStatementParserEngine(databaseTypeName);distSQLStatementParserEngine = new DistSQLStatementParserEngine();parsingHookRegistry = ParsingHookRegistry.getInstance();}
这里根据数据库类型获得相应的Mysql sql解析引擎、分布式数据库引擎和解析钩子的注册。
解析SQL
语句执行到了sqlStatement = sqlParserEngine.parse(sql, true);
parse的源码如下:
public SQLStatement parse(final String sql, final boolean useCache) {parsingHookRegistry.start(sql);try {SQLStatement result = parse0(sql, useCache);parsingHookRegistry.finishSuccess(result);return result;// CHECKSTYLE:OFF// TODO check whether throw SQLParsingException only} catch (final Exception ex) {// CHECKSTYLE:ONparsingHookRegistry.finishFailure(ex);throw ex;}}
parse0:
private SQLStatement parse0(final String sql, final boolean useCache) {try {return sqlStatementParserEngine.parse(sql, useCache);} catch (final SQLParsingException | ParseCancellationException originalEx) {try {return distSQLStatementParserEngine.parse(sql);} catch (final SQLParsingException ignored) {throw originalEx;}}}
这里调用了引擎的parse方法,这里以mysql为例:
public SQLStatement parse(final String sql, final boolean useCache) {return useCache ? sqlStatementCache.getUnchecked(sql) : sqlStatementParserExecutor.parse(sql);}

执行语句
经过上述的一些列初始化操作后代码来到了:ResultSet resultSet = preparedStatement.executeQuery();
其源码如下:
@Overridepublic ResultSet executeQuery() throws SQLException {ResultSet result;try {clearPrevious();executionContext = createExecutionContext();List<QueryResult> queryResults = executeQuery0();MergedResult mergedResult = mergeQuery(queryResults);result = new ShardingSphereResultSet(statements.stream().map(this::getResultSet).collect(Collectors.toList()), mergedResult, this, executionContext);} finally {clearBatch();}currentResultSet = result;return result;}
这块是ShardingSphere的核心代码,稍后会在这里进行详尽分析,但目前的任务是找到路由信息如何获取。
清理完缓存后代码来到了:executionContext = createExecutionContext();
创建执行上下文
执行SQL必备的上下文信息就是在该方法中获取的,其源码如下:
private ExecutionContext createExecutionContext() throws SQLException {LogicSQL logicSQL = createLogicSQL();ExecutionContext result = kernelProcessor.generateExecutionContext(logicSQL, metaDataContexts.getDefaultMetaData(), metaDataContexts.getProps());findGeneratedKey(result).ifPresent(generatedKey -> generatedValues.addAll(generatedKey.getGeneratedValues()));return result;}
创建逻辑SQL
这里的逻辑SQL包装类是LogicSQL封装的,其通过createLogicSQL方法获取:
private LogicSQL createLogicSQL() {List<Object> parameters = new ArrayList<>(getParameters());ShardingSphereSchema schema = metaDataContexts.getDefaultMetaData().getSchema();SQLStatementContext<?> sqlStatementContext = SQLStatementContextFactory.newInstance(schema, parameters, sqlStatement);return new LogicSQL(sqlStatementContext, sql, parameters);}
先获取所有传入的参数存入到parameters中,然后获取schema,即逻辑表信息:
然后讲这些信息传入SQLStatementContext生成SQL语句的上下文信息。
最后连通上下文信息一同包装到LogicSQL中并返回。
解析路由信息
其主要通过kernelProcessor的generateExecutionContext方法来创建ExecutionContext对象,其源码如下:
public ExecutionContext generateExecutionContext(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ConfigurationProperties props) throws SQLException {audit(logicSQL, metaData);RouteContext routeContext = route(logicSQL, metaData, props);SQLRewriteResult rewriteResult = rewrite(logicSQL, metaData, props, routeContext);ExecutionContext result = createExecutionContext(logicSQL, metaData, routeContext, rewriteResult);logSQL(logicSQL, props, result);return result;}
这里把上述创建的逻辑SQL、逻辑表信息、props信息一同传入。
经过审计(audit)之后第一件要做的事情就是获取路由信息,这里就是本章重点相关语句如下:RouteContext routeContext = route(logicSQL, metaData, props);
追踪:
private RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ConfigurationProperties props) {return new SQLRouteEngine(metaData.getRuleMetaData().getRules(), props).route(logicSQL, metaData);}
显然,其是通过SQL的路由引擎来进行路由的。逻辑如下:
public RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData) {routingHook.start(logicSQL.getSql());try {SQLRouteExecutor executor = isNeedAllSchemas(logicSQL.getSqlStatementContext().getSqlStatement()) ? new AllSQLRouteExecutor() : new PartialSQLRouteExecutor(rules, props);RouteContext result = executor.route(logicSQL, metaData);routingHook.finishSuccess(result, metaData.getSchema());return result;// CHECKSTYLE:OFF} catch (final Exception ex) {// CHECKSTYLE:ONroutingHook.finishFailure(ex);throw ex;}}
首先根据路由信息获取相应的执行器,然后继续追踪路由方法:
public RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData) {RouteContext result = new RouteContext();for (Entry<ShardingSphereRule, SQLRouter> entry : routers.entrySet()) {if (result.getRouteUnits().isEmpty()) {result = entry.getValue().createRouteContext(logicSQL, metaData, entry.getKey(), props);} else {entry.getValue().decorateRouteContext(result, logicSQL, metaData, entry.getKey(), props);}}return result;}
封装路由条件
这里来遍历所有的路由信息然后创建路由上下文对象:
public RouteContext createRouteContext(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ShardingRule rule, final ConfigurationProperties props) {RouteContext result = new RouteContext();SQLStatement sqlStatement = logicSQL.getSqlStatementContext().getSqlStatement();Optional<ShardingStatementValidator> validator = ShardingStatementValidatorFactory.newInstance(sqlStatement);validator.ifPresent(optional -> optional.preValidate(rule, logicSQL.getSqlStatementContext(), logicSQL.getParameters(), metaData.getSchema()));ShardingConditions shardingConditions = createShardingConditions(logicSQL, metaData, rule);boolean needMergeShardingValues = isNeedMergeShardingValues(logicSQL.getSqlStatementContext(), rule);if (sqlStatement instanceof DMLStatement && needMergeShardingValues) {mergeShardingConditions(shardingConditions);}ShardingRouteEngineFactory.newInstance(rule, metaData, logicSQL.getSqlStatementContext(), shardingConditions, props).route(result, rule);validator.ifPresent(v -> v.postValidate(sqlStatement, result));return result;}
具体路由调条件的逻辑位于createShardingConditions:
private ShardingConditions createShardingConditions(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ShardingRule rule) {List<ShardingCondition> shardingConditions;if (logicSQL.getSqlStatementContext().getSqlStatement() instanceof DMLStatement) {ShardingConditionEngine shardingConditionEngine = ShardingConditionEngineFactory.createShardingConditionEngine(logicSQL, metaData, rule);shardingConditions = shardingConditionEngine.createShardingConditions(logicSQL.getSqlStatementContext(), logicSQL.getParameters());} else {shardingConditions = Collections.emptyList();}return new ShardingConditions(shardingConditions);}
其先获取对应的分片引擎,其内部存放着分片有关的信息:
然后通过createShardingConditions方法来获取其余属性:
public List<ShardingCondition> createShardingConditions(final SQLStatementContext<?> sqlStatementContext, final List<Object> parameters) {if (!(sqlStatementContext instanceof WhereAvailable)) {return Collections.emptyList();}List<ShardingCondition> result = new ArrayList<>();((WhereAvailable) sqlStatementContext).getWhere().ifPresent(segment -> result.addAll(createShardingConditions(sqlStatementContext, segment.getExpr(), parameters)));Collection<WhereSegment> subqueryWhereSegments = sqlStatementContext.getSqlStatement() instanceof SelectStatement? WhereSegmentExtractUtils.getSubqueryWhereSegments((SelectStatement) sqlStatementContext.getSqlStatement()) : Collections.emptyList();for (WhereSegment each : subqueryWhereSegments) {Collection<ShardingCondition> subqueryShardingConditions = createShardingConditions(sqlStatementContext, each.getExpr(), parameters);if (!result.containsAll(subqueryShardingConditions)) {result.addAll(subqueryShardingConditions);}}return result;}
获取全部路径
获取完各种信息后代码来到:ShardingRouteEngineFactory.newInstance(rule, metaData, logicSQL.getSqlStatementContext(), shardingConditions, props).route(result, rule);
路由源码如下:
public void route(final RouteContext routeContext, final ShardingRule shardingRule) {Collection<DataNode> dataNodes = getDataNodes(shardingRule, shardingRule.getTableRule(logicTableName));routeContext.getOriginalDataNodes().addAll(originalDataNodes);for (DataNode each : dataNodes) {routeContext.getRouteUnits().add(new RouteUnit(new RouteMapper(each.getDataSourceName(), each.getDataSourceName()), Collections.singletonList(new RouteMapper(logicTableName, each.getTableName()))));}}
获取分表的规则方法如下:
public TableRule getTableRule(final String logicTableName) {Optional<TableRule> tableRule = findTableRule(logicTableName);if (tableRule.isPresent()) {return tableRule.get();}if (isBroadcastTable(logicTableName)) {return new TableRule(dataSourceNames, logicTableName);}throw new ShardingSphereConfigurationException("Cannot find table rule with logic table: '%s'", logicTableName);}
然后根据分库分表规则获取数据节点:
private Collection<DataNode> getDataNodes(final ShardingRule shardingRule, final TableRule tableRule) {ShardingStrategy databaseShardingStrategy = createShardingStrategy(shardingRule.getDatabaseShardingStrategyConfiguration(tableRule), shardingRule.getShardingAlgorithms());ShardingStrategy tableShardingStrategy = createShardingStrategy(shardingRule.getTableShardingStrategyConfiguration(tableRule), shardingRule.getShardingAlgorithms());if (isRoutingByHint(shardingRule, tableRule)) {return routeByHint(tableRule, databaseShardingStrategy, tableShardingStrategy);}if (isRoutingByShardingConditions(shardingRule, tableRule)) {return routeByShardingConditions(shardingRule, tableRule, databaseShardingStrategy, tableShardingStrategy);}return routeByMixedConditions(shardingRule, tableRule, databaseShardingStrategy, tableShardingStrategy);}
首先先获取分库分表策略:
然后进入到routeByShardingConditions方法获取全部路径:
private Collection<DataNode> routeByShardingConditions(final ShardingRule shardingRule, final TableRule tableRule,final ShardingStrategy databaseShardingStrategy, final ShardingStrategy tableShardingStrategy) {return shardingConditions.getConditions().isEmpty()? route0(tableRule, databaseShardingStrategy, Collections.emptyList(), tableShardingStrategy, Collections.emptyList()): routeByShardingConditionsWithCondition(shardingRule, tableRule, databaseShardingStrategy, tableShardingStrategy);}
route0:
private Collection<DataNode> route0(final TableRule tableRule,final ShardingStrategy databaseShardingStrategy, final List<ShardingConditionValue> databaseShardingValues,final ShardingStrategy tableShardingStrategy, final List<ShardingConditionValue> tableShardingValues) {Collection<String> routedDataSources = routeDataSources(tableRule, databaseShardingStrategy, databaseShardingValues);Collection<DataNode> result = new LinkedList<>();for (String each : routedDataSources) {result.addAll(routeTables(tableRule, each, tableShardingStrategy, tableShardingValues));}return result;}
封装后的结果如下: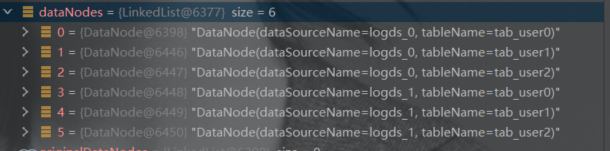
然后将路径存储到路由上下文中。
最后把这些消息放入到RouteUnit对象中:
调整路径信息
获取上下文后返回到result然后调用decorateRouteContext进行装饰:
public void decorateRouteContext(final RouteContext routeContext,final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ReplicaQueryRule rule, final ConfigurationProperties props) {Collection<RouteUnit> toBeRemoved = new LinkedList<>();Collection<RouteUnit> toBeAdded = new LinkedList<>();for (RouteUnit each : routeContext.getRouteUnits()) {String dataSourceName = each.getDataSourceMapper().getLogicName();Optional<ReplicaQueryDataSourceRule> dataSourceRule = rule.findDataSourceRule(dataSourceName);if (dataSourceRule.isPresent() && dataSourceRule.get().getName().equalsIgnoreCase(each.getDataSourceMapper().getActualName())) {toBeRemoved.add(each);String actualDataSourceName = new ReplicaQueryDataSourceRouter(dataSourceRule.get()).route(logicSQL.getSqlStatementContext().getSqlStatement());toBeAdded.add(new RouteUnit(new RouteMapper(each.getDataSourceMapper().getLogicName(), actualDataSourceName), each.getTableMappers()));}}routeContext.getRouteUnits().removeAll(toBeRemoved);routeContext.getRouteUnits().addAll(toBeAdded);}
这里分为两个集合,一个是需要被添加的,一个是需要被移除的。这里其实做的是容器里面的数据的筛选与调整。
到这里,路由信息就全部解析完成。下一步就是语句的改写,核心方法位于rewrite中,将在下节进行分析。

若有收获,就点个赞吧
0 人点赞
