今日内容:
- 1- HIVE的索引 (整理记录)
- 2- 如何解决数据倾斜的问题 (整理记录)
- 3- DWS层实现操作: 销售主题统计实现 (操作)
- 4- HIVE的其他参数优化 (整理记录)
1- HIVE的索引
索引有什么用呢? 用于提升查询的效率

1.1 HIVE的原始索引(废弃)
hive的原始索引可以针对某个列, 或者某几列构建索引信息, 构建后提升查询执行列的查询效率存在弊端:hive原始索引不会自动更新,每次表中数据发生变化后, 都是需要手动重建索引操作, 比较耗费时间和资源, 整体提升性能一般所以在HIVE3.x版本后, 已经直接将这种索引废弃掉了, 无法使用, 而且官方描述在hive1.x 和 hive2.x版本中, 也不建议优先使用原始索引
1.2 HIVE的row group index索引
row group index: 行组索引
条件:1) 要求表的存储类型为ORC存储格式2) 在创建表的时候, 必须开启 row group index 索引支持'orc.create.index'='true'3) 在插入数据的时候, 必须保证需求进行索引列, 按序插入数据适用于: 数值类型的, 并且对数值类型进行 > < = 操作思路:插入数据到ORC表后, 会自动进行划分为多个script片段, 每个片段内部, 会保存着每个字段的最小, 最大值, 这样, 当执行查询 > < = 的条件筛选操作的时候, 根据最小最大值锁定相关的script片段, 从而减少数据扫描量, 提升效率操作:CREATE TABLE lxw1234_orc2 (字段列表 ....) stored AS ORCTBLPROPERTIES ('orc.compress'='SNAPPY',-- 开启行组索引'orc.create.index'='true')插入数据的时候, 需要保证数据有序的insert overwrite table lxw1234_orc2SELECT id, pcid FROM lxw1234_text-- 插入的数据保持排序(可以使用全局排序, 也可以使用局部排序, 只需要保证一定有序即可, 建议使用局部排序 插入数据效率高一些, 因为全局排序只有一个reduce)DISTRIBUTE BY id sort BY id;使用:set hive.optimize.index.filter=true;SELECT COUNT(1) FROM lxw1234_orc1 WHERE id >= 1382 AND id <= 1399;

1.3 HIVE的bloom filter index索引
bloom filter index (布隆过滤索引):
条件:1) 要求表的存储类型为 ORC存储方案2) 在建表的饿时候, 必须设置为那些列构建布隆索引3) 仅能适合于等值过滤查询操作思路:在开启布隆过滤索引后, 可以针对某个列, 或者某几列来建立索引, 构建索引后, 会将这一列的数据的值存储在对应script片段的索引信息中, 这样当进行 等值查询的时候, 首先会到每一个script片段的索引中, 判断是否有这个值, 如果没有, 直接跳过script, 从而减少数据扫描量, 提升效率操作:CREATE TABLE lxw1234_orc2 (字段列表....)stored AS ORCTBLPROPERTIES ('orc.compress'='SNAPPY',-- 开启 行组索引 (可选的, 支持全部都打开, 也可以仅开启一个)'orc.create.index'='true',-- pcid字段开启BloomFilter索引'orc.bloom.filter.columns'='pcid,字段2,字段3...')插入数据: 没有要求, 当然如果开启行组索引, 可以将需要使用行组索引的字段, 进行有序插入即可使用:SET hive.optimize.index.filter=true;SELECT COUNT(1) FROM lxw1234_orc1 WHERE id >= 0 AND id <= 1000 AND pcid IN ('0005E26F0DCCDB56F9041C','A');
在什么时候可以使用呢?
1- 对于行组索引, 我们建议只要数据存储格式为ORC, 建议将这种索引全部打开, 至于导入数据的时候, 如果能保证有序, 那最好, 如果保证不了, 也无所谓, 大不了这个索引的效率不是特别好2- 对于布隆过滤索引: 建议将后续会大量的用于等值连接的操作字段, 建立成布隆索引, 比如说: JOIN的字段 经常在where后面出现的等值连接字段
2. 如何解决数据倾斜问题
何为数据倾斜呢?
在hive中, 执行一条SQL语句, 最终会被翻译为MR , MR中mapTask和reduceTask都可能存在多个, 数据倾斜主要指的整个MR中reduce阶段有多个, 每个reduce拿到的数据量并不均衡, 导致某一个或者某几个reduce拿到了比其他reduce更多的数据, 导致处理数据压力, 都集中在某几个reduce上, 形成数据倾斜问题, 导致执行时间变长, 影响执行效率
那么倾斜主要发送在执行SQL什么阶段呢? 执行JOIN操作 以及 执行 group by的时候
2.1 Join数据倾斜
在前序讲解reduce 端 JOIN的时候, 描述过reduce 端Join的问题, 其中就包含reduce端Join存在数据倾斜的问题
解决方案一:
可以通过 Map Join Bucket Map Join 以及 SMB Join 解决注意:通过 Map Join,Bucket Map Join,SMB Join 来解决数据倾斜, 但是 这种操作是存在使用条件的, 如果无法满足这些条件, 无法使用 这种处理方案
解决方案二: ```properties 思路: 将那些产生倾斜的key和对应v2的数据, 从当前这个MR中移出去, 单独找一个MR来处理即可, 处理后, 和之前的MR进行汇总结果即可
关键问题: 如何找到那些存在倾斜的key呢? 特点: 这个key数据有很多
运行期处理方案: 思路: 在执行MR的时候, 会动态统计每一个 k2的值出现重复的次数, 当这个重复的次数达到一定的阈值后, 认为当前这个k2的数据存在数据倾斜, 自动将其剔除, 交由给一个单独的MR来处理即可,两个MR处理完成后, 将结果基于union all 合并在一起即可
实操:set hive.optimize.skewjoin=true; -- 开启运行期处理倾斜参数set hive.skewjoin.key=100000; -- 阈值, 此参数在实际生产环境中, 需要调整在一个合理的值(否则极易导致大量的key都是倾斜的)判断依据: 查看 join的 字段 对应重复的数量有多少个, 然后选择一个合理值比如判断: id为 1 大概有 100w id为 2 88w id 为 3 大概有 500w 设置阈值为 大于500w次数据或者: 总数量大量1000w, 然后共有 1000个班级, 平均下来每个班级数量大概在 1w条, 设置阈值: 大于 3w条 ~5w条范围 (超过3~5倍才认为倾斜)适用于: 并不清楚那个key容易产生倾斜, 此时交由系统来动态检测
编译期处理方案: 思路: 在创建这个表的时候, 我们就可以预知到后续插入到这个表中数据, 那些key的值会产生倾斜, 在建表的时候, 将其提前配置设置好即可, 在后续运行的时候, 程序会自动将设置的key的数据单独找一个MR来进行处理即可, 处理完成后, 再和原有结果进行union all 合并操作
实操:set hive.optimize.skewjoin.compiletime=true; -- 开启编译期处理倾斜参数CREATE TABLE list_bucket_single (key STRING, value STRING)-- 倾斜的字段和需要拆分的key值SKEWED BY (key) ON (1,5,6)-- 为倾斜值创建子目录单独存放[STORED AS DIRECTORIES];适用于: 提前知道那些key存在倾斜
在实际生产环境中, 应该使用那种方式呢? 两种方式都会使用的 一般来说, 会将两个都开启, 编译期的明确在编译期将其设置好, 编译期不清楚, 通过运行期动态捕获即可
union all 优化方案```properties说明: 不管是运行期 还是编译期的join倾斜解决, 最终都会运行多个MR, 将多个MR结果通过union all 进行汇总, union all也是需要单独一个MR来处理解决方案:让每一个MR在运行完成后, 直接将结果输出到目的地即可, 默认 是各个MR将结果输出临时目录, 通过 union all 合并到最终目的地开启此参数即可:set hive.optimize.union.remove=true;
2.2 group by 数据倾斜
- 为什么在group by 的时候, 可能会出现倾斜的问题呢? ```properties 假设目前有这么一个表:
sid sname cid s01 张三 c01 s02 李四 c02 s03 王五 c01 s04 赵六 c03 s05 田七 c02 s06 周八 c01 s07 李九 c01 s08 老王 c04
需求: 请计算每个班级有多少个人 select cid,count(1) as total from stu group by cid;
翻译后MR是如何处理SQL呢?
MAP 阶段: 假设Map阶段跑了二个MapTask
mapTask1: k2 v2 c01 {s01 张三 c01} c02 {s02 李四 c02} c01 {s03 王五 c01} c03 {s04 赵六 c03} mapTask2: k2 v2 c02 {s05 田七 c02} c01 {s06 周八 c01} c01 {s07 李九 c01} c04 {s08 老王 c04}
reduce阶段: 假设reduceTask有二个
reduceTask1: 接收 c01 和 c02的数据 接收数据 k2 v2 c01 {s01 张三 c01} c02 {s02 李四 c02} c01 {s03 王五 c01} c02 {s05 田七 c02} c01 {s06 周八 c01} c01 {s07 李九 c01}
分组后: c01 [{s01 张三 c01},{s03 王五 c01},{s06 周八 c01},{s07 李九 c01}] c02 [{s02 李四 c02},{s05 田七 c02}]
结果数据: c01 4 c02 2
reduceTask2: 接收 c03 和 c04的数据 接收数据 k2 v2 c03 {s04 赵六 c03} c04 {s08 老王 c04}
分组后: c03 [{s04 赵六 c03}] c04 [{s08 老王 c04}]
结果数据: c03 1 c04 1
在以上整个计算流程中, 发现 其中一个reduce接收到的数据量比另一个reduce接收的数据量要多的多, 认为出现了数据倾斜的问题, 所以group by 也有可能产生数据倾斜
思考: 如何解决group by的数据倾斜呢?- 解决方案一: 基于MR的 combiner(规约, 提前聚合) 减少数据达到reduce数量, 从而减轻倾斜问题```properties假设目前有这么一个表:sid sname cids01 张三 c01s02 李四 c02s03 王五 c01s04 赵六 c03s05 田七 c02s06 周八 c01s07 李九 c01s08 老王 c04需求: 请计算每个班级有多少个人select cid,count(1) as total from stu group by cid;翻译后MR是如何处理SQL呢?MAP 阶段: 假设Map阶段跑了二个MapTaskmapTask1:k2 v2c01 {s01 张三 c01}c02 {s02 李四 c02}c01 {s03 王五 c01}c03 {s04 赵六 c03}规约(提前聚合)操作: 处理逻辑与reduce处理逻辑一直分组:c01 [{s01 张三 c01},{s03 王五 c01}]c02 [{s02 李四 c02}]c03 [{s04 赵六 c03}]聚合得出结果:c01 2c02 1c03 1mapTask2:k2 v2c02 {s05 田七 c02}c01 {s06 周八 c01}c01 {s07 李九 c01}c04 {s08 老王 c04}规约(提前聚合)操作: 处理逻辑与reduce处理逻辑一直分组:c01 [{s06 周八 c01},{s07 李九 c01}]c02 [{s05 田七 c02}]c04 [{s08 老王 c04}]聚合得出结果:c01 2c02 1c04 1reduce阶段: 假设reduceTask有二个reduceTask1: 接收 c01 和 c02的数据接收数据k2 v2c01 2c02 1c01 2c02 1分组后:c01 [2,2]c02 [1,1]结果数据:c01 4c02 2reduceTask2: 接收 c03 和 c04的数据接收数据k2 v2c03 1c04 1分组后:c03 [1]c04 [1]结果数据:c03 1c04 1通过规约来解决数据倾斜, 处理完成后, 发现 两个reduce中从原来相差 3倍, 变更为相差 2倍, 减轻了数据倾斜问题如何配置呢?只需要在HIVE中开启combiner提前聚合配置参数即可:set hive.map.aggr=true;
- 方案二: 负载均衡的解决方案(需要运行两个MR来处理) (大combiner方案) ```properties 假设目前有这么一个表:
sid sname cid s01 张三 c01 s02 李四 c02 s03 王五 c01 s04 赵六 c03 s05 田七 c02 s06 周八 c01 s07 李九 c01 s08 老王 c04
需求: 请计算每个班级有多少个人 select cid,count(1) as total from stu group by cid;
翻译后MR是如何处理SQL呢?
第一个MR的操作: 对数据进行打散
Map 阶段: 假设运行了两个MapTask
mapTask1: k2 v2 c01 {s01 张三 c01} c02 {s02 李四 c02} c01 {s03 王五 c01} c03 {s04 赵六 c03} mapTask2: k2 v2 c02 {s05 田七 c02} c01 {s06 周八 c01} c01 {s07 李九 c01} c04 {s08 老王 c04}
mapTask执行完成后, 在进行分发数据到达reduce, 默认情况下将相同k2的数据发往同一个reduce, 目前采用防范为随机分发, 保证每一个reduce拿到相等数量的数据信息(负载过程, 让每一个reduce接收到相同数量的数据)
reduce阶段: 假设有两个reduceTask
reduceTask1:
接收到数据:
c01 {s01 张三 c01}
c02 {s02 李四 c02}
c01 {s03 王五 c01}
c01 {s06 周八 c01}
分组操作:
c01 [{s01 张三 c01},{s03 王五 c01},{s06 周八 c01}]
c02 [{s02 李四 c02}]
输出结果:
c01 3
c02 1
reduceTask2: 接收到数据: c03 {s04 赵六 c03} c02 {s05 田七 c02} c01 {s07 李九 c01} c04 {s08 老王 c04}
分组操作:
c03 [{s04 赵六 c03}]
c02 [{s05 田七 c02}]
c01 [{s07 李九 c01}]
c04 [{s08 老王 c04}]
输出结果:
c01 1
c02 1
c03 1
c04 1
第一个MR执行完成了, 每个reduce都接收到四条数据, 自然也就不存在数据倾斜的问题了
第二个MR进行处理: 严格按照相同k2发往同一个reduce
Map 阶段: 假设有二个mapTask
mapTask1:
k2 v2
c01 3
c01 1
c02 1
mapTask2: k2 v2 c02 1 c03 1 c04 1
reduce阶段: 假设有两个reduce
reduceTask1: 接收 c01 和 c02 数据
接收数据:
k2 v2
c01 3
c01 1
c02 1
c02 1
结果:
c01 4
c02 2
reduceTask2: 接收 c03 和c04
接收数据:
k2 v2
c03 1
c04 1
结果: c03 1 c04 1
通过负载均衡方式来解决数据倾斜, 同样也可以减轻数据倾斜的压力
细细发现, 方案一 和 方案二, 是有类似之处的, 方案一, 让每一个mapTask内部进行提前聚合, 然后到达reduce进行汇总合并得出结构, 方案二: 让第一个MR进行打散并对数据进行聚合计算 得出局部结果, 然后让第二个MR进行最终聚合计算操作, 得出最终结果
说明: 方案二, 比方案一, 更能彻底解决数据倾斜问题, 因为其处理数据范围更大, 整个整个数据集来处理, 而方案一, 只是每个MapTask处理, 仅仅局部处理
如何使用方案二: 只需要开启负载均衡的HIVE参数配置即可: set hive.groupby.skewindata=true;
这两种方式: 建议在生产中, 优先使用第一种, 如果第一种无法解决, 尝试使用第二种解决
注意事项: 使用第二种负载均衡的解决group by 的数据倾斜, 一定要注意, SQL语句中不能出现多次 distinct操作, 否则 HIVE会直接报错的 错误信息: Error in semantic analysis: DISTINCT on different columns not supported with skew in data. 比如说: SELECT ip, count(DISTINCT uid), count(DISTINCT uname) FROMlog GROUP BY ip 此操作就直接报错了,只能使用方案一解决数据倾斜
倾斜的参数配置开启条件, 一定是出现了数据倾斜的问题, 如果没有出现 不需要开启的
思考: 如何才能知道发生了数据倾斜呢?
```properties
倾斜发生后, 出现的问题, 程序迟迟无法结束, 或者说翻译的MR中reduceTask有多个, 大部分的reduceTask都执行完成了, 只有其中一个或者几个没有执行完成, 此时认为发生了数据倾斜
关键点: 如何查看每一个reduceTask执行时间
- 方式一: 通过Yarn查看(运行过程中) 或者 jobhistory查看(已经结束的程序) (此操作, 只能在本地演示查看, 云端环境没有开启yarn端口, 无法查看的)
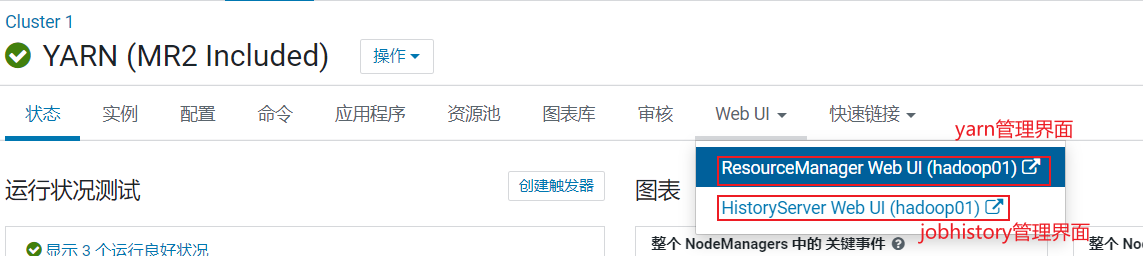
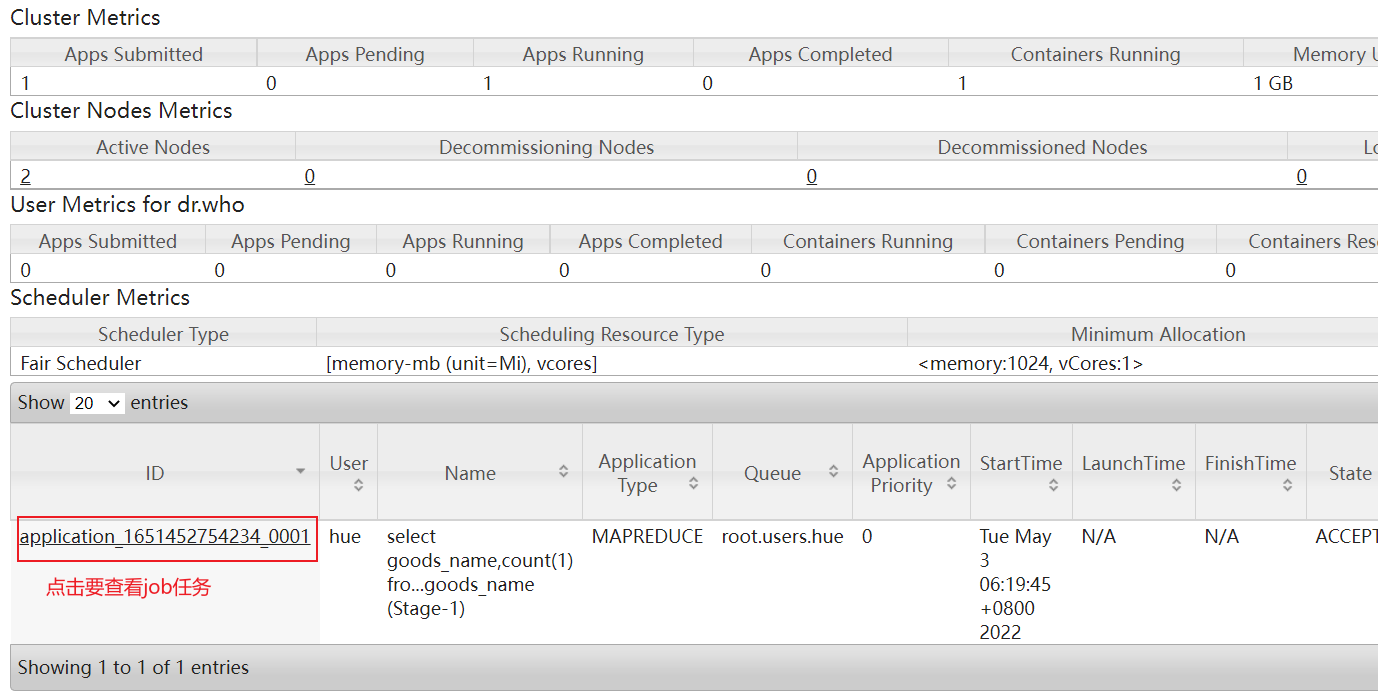
运行的时候点击: 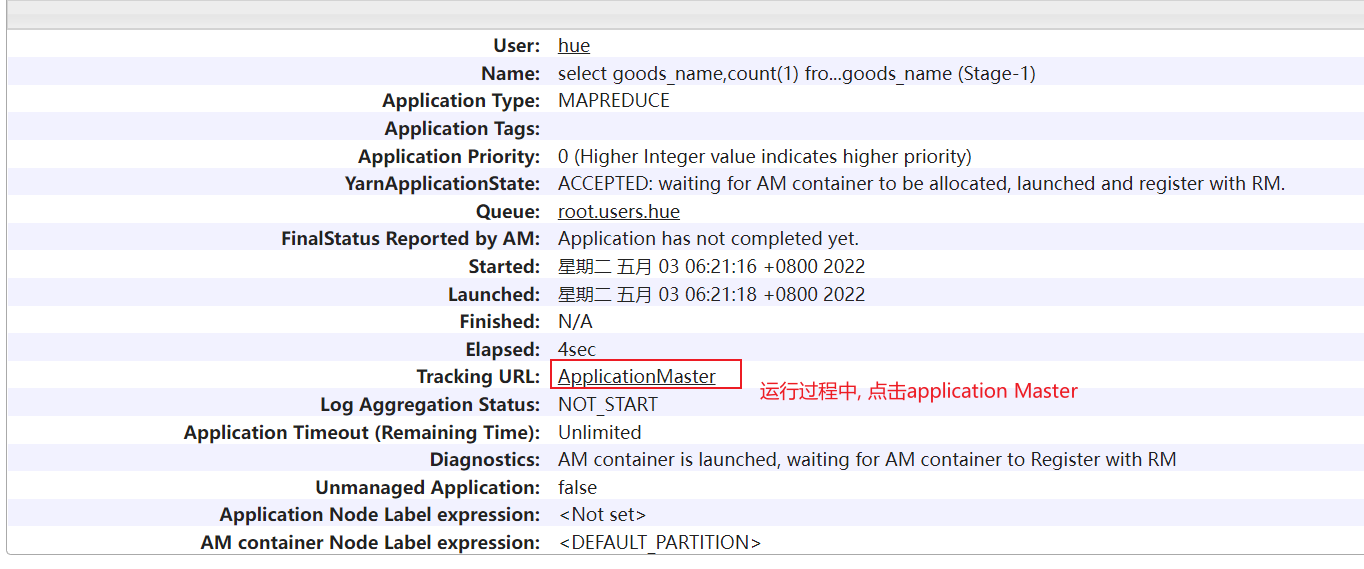
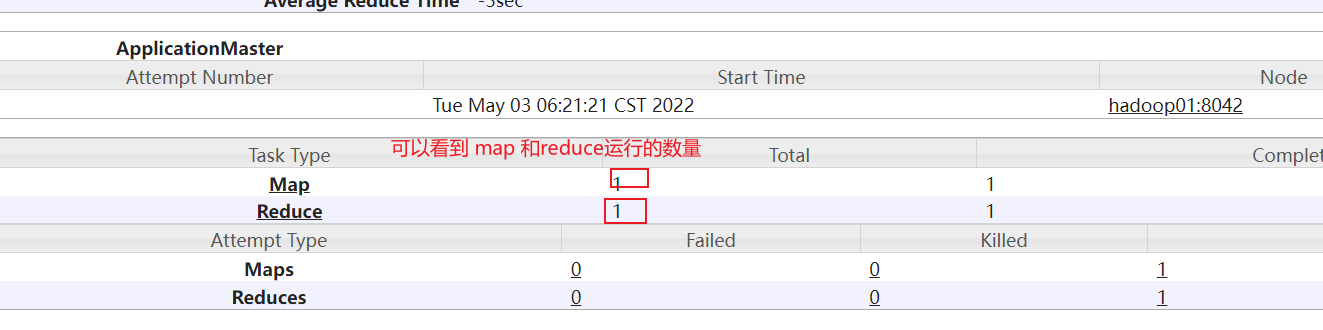
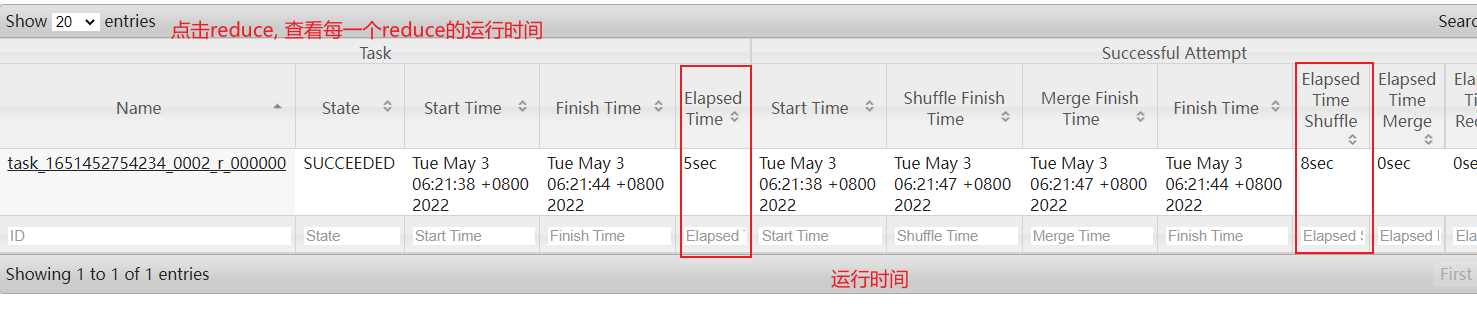
目前, 我们这里可能只有一个reduce, 但是实际上生产环境中, 此位置可能会有多个reduceTask, 我们需要观察每个reduceTask执行时间, 如果发现其中一个或者几个reduce执行时间, 远远大于其他的reduceTask执行时间, 那么说明存在数据倾斜的问题
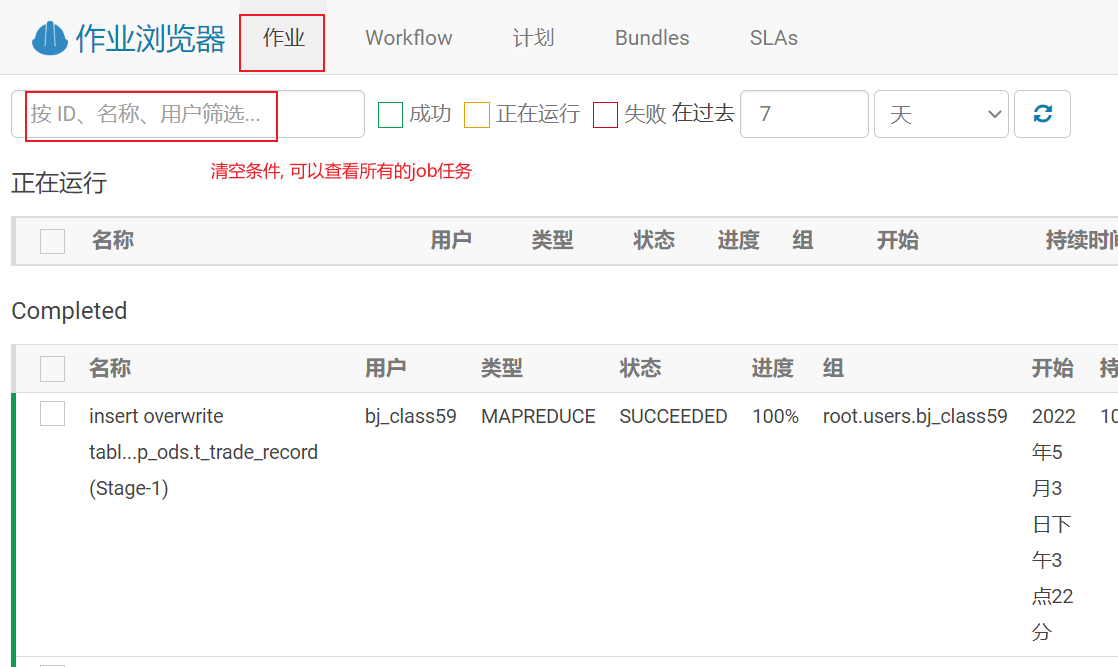
如果程序以及运行完成了, 想查看刚刚运行的各个reduceTask时间: 使用jobHistory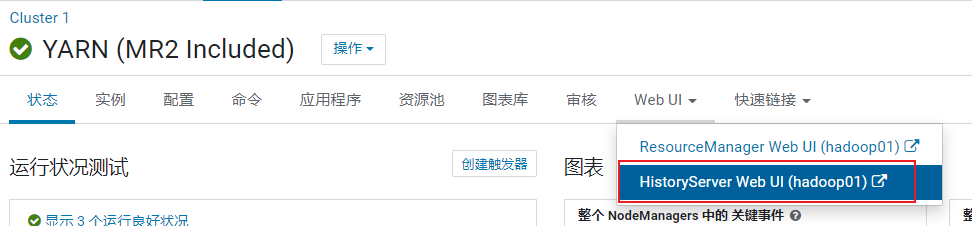

点击对应需要查看的任务: 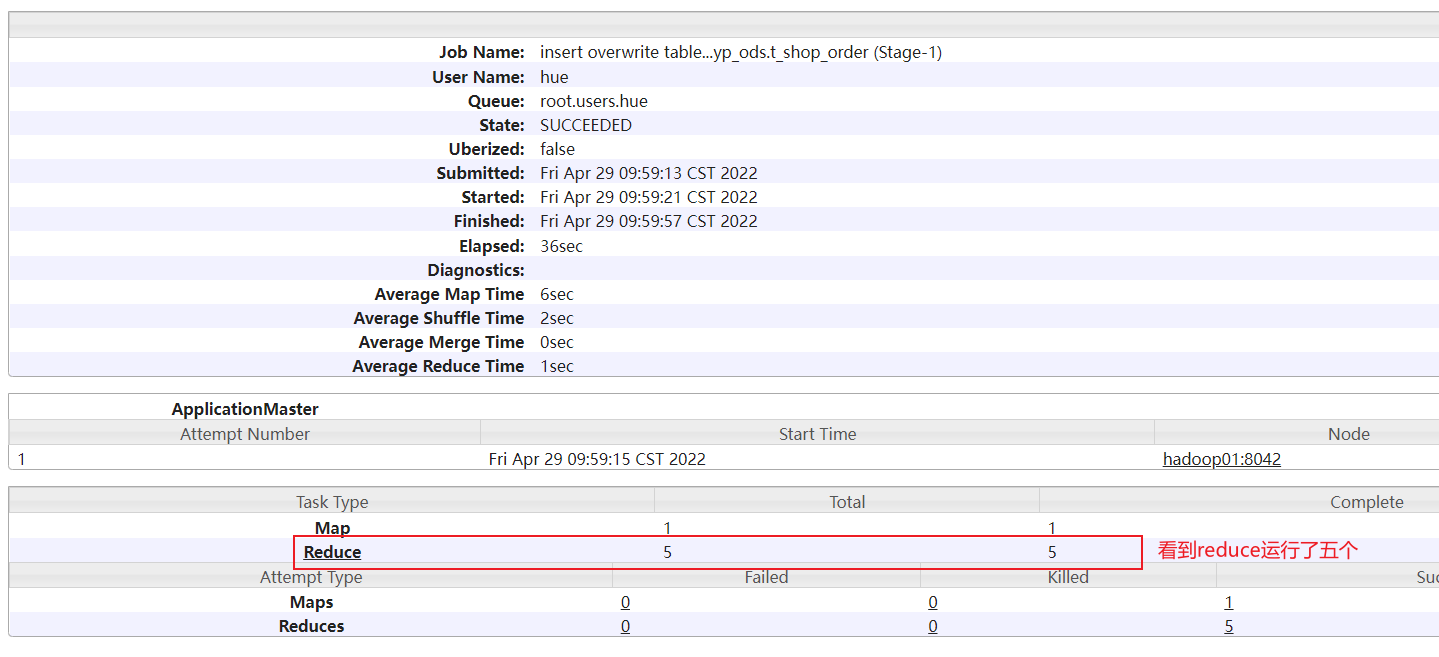
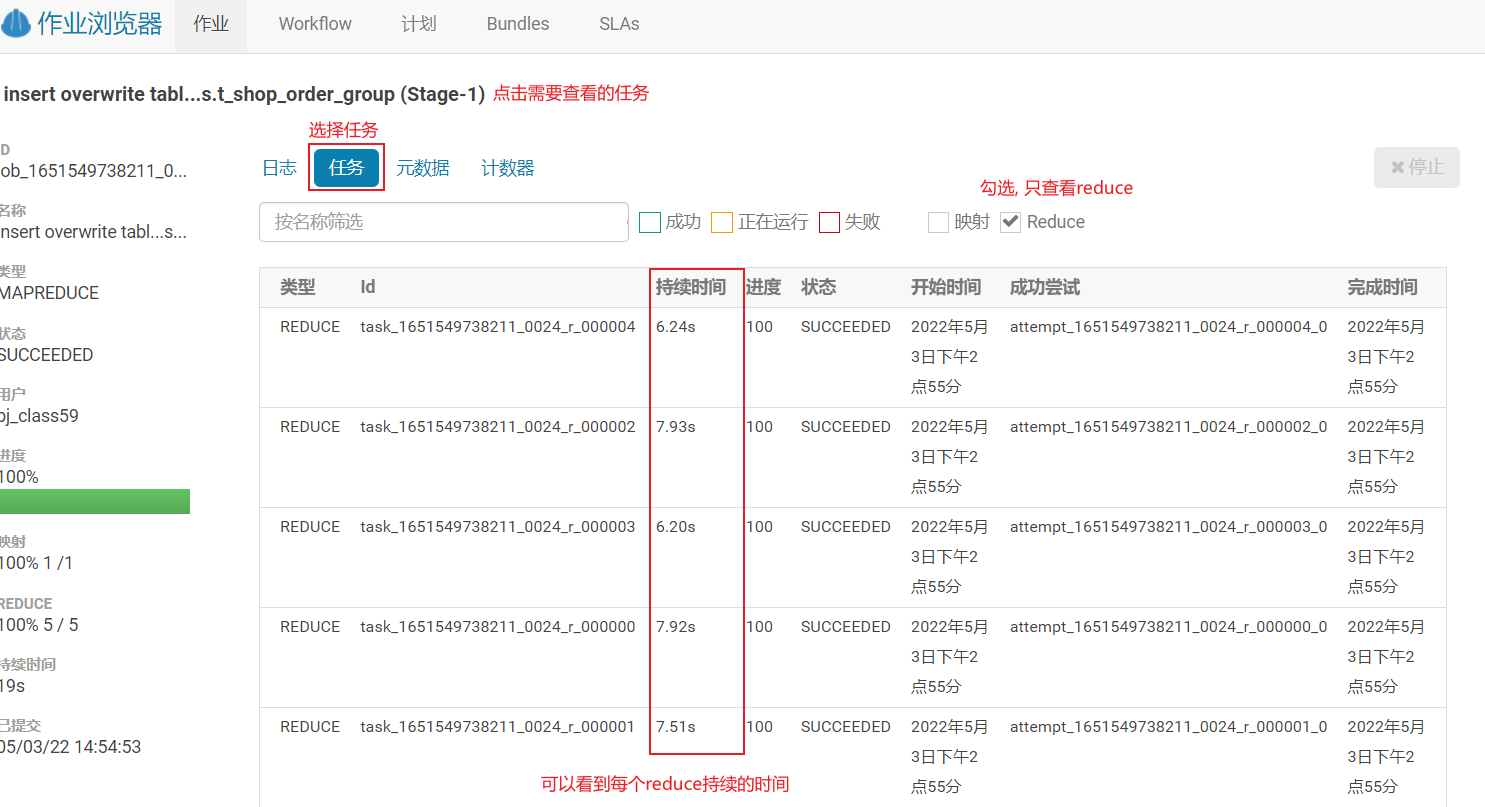
点击reduce进入: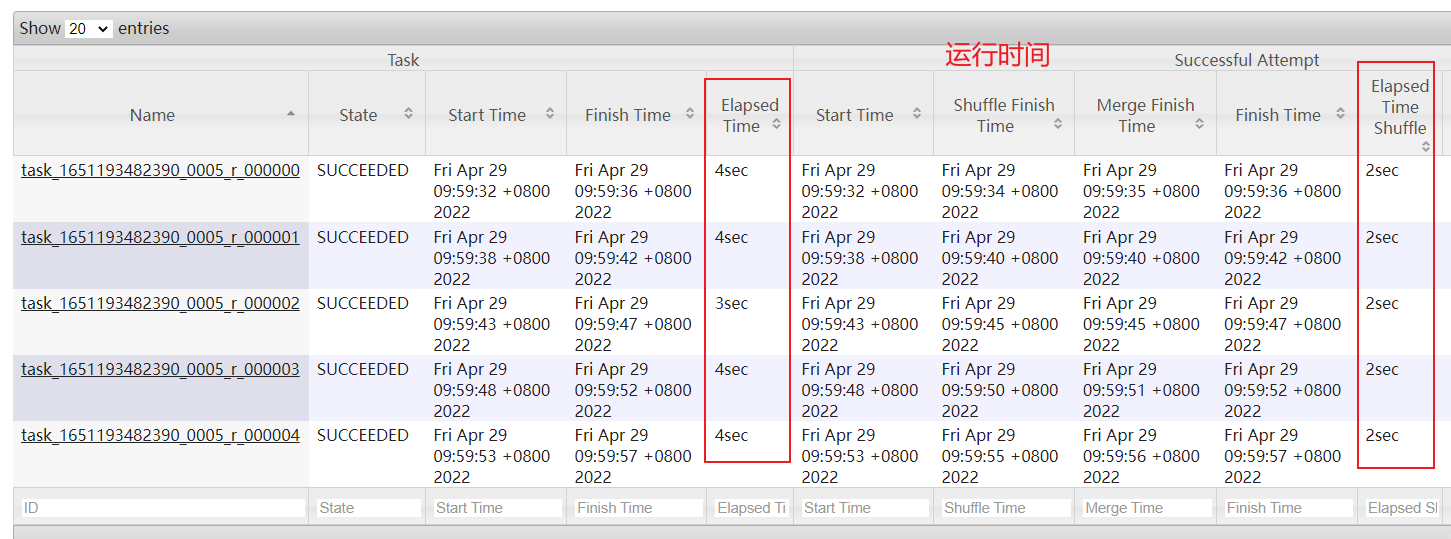
- 方案二: 通过 HUE方式也可以查看 (可以在云平台中查看)
3. DWS层实现
DWS层: 业务层
基于主题统计分析, 此层一般适用于进行细化粒度的聚合统计操作, 主要为了服务后续上卷统计过程 (提前聚合操作)
比如说:
以年 月 日 来统计操作, 在DWS层, 仅需要按照 日进行统计相关的指标即可, 进行提前聚合操作
后续在DM层, 进行上卷操作, 将 月 和 年 基于日统计宽表 计算得出
注意:
如果要进行提前聚合操作, 不能对数据进行去重统计 ,
比如说: 要统计用户量, 分别统计 每天 每月 每年的数据
对于用户, 可能今天购买, 明天也会, 这个月会购买, 下个月也会购买
如果先按照每天统计用户量, 得出一个结果, 比如说
2022-05-01: 用户量 100
2022-05-02: 用户量 160
此时统计五月份的数据: 如果直接将 100 + 160 = 260 用户 这是错误, 可能实际只有 180个用户
所以说: 如果需要去重计算指标, 不管计算日 月 年, 都需要针对原始数据来计算处理, 不能提前聚合
本次DWS层, 共计有三个主题需要进行统计: 销售主题, 商品主题, 和 用户主题, 在实际面试中, 可以只负责其中一个主题或者二个主题即可, 无需全部负责, 但是学习中, 希望三个主题都能全部搞定
对于DWS层以前的层次, 仅负责其中一个业务模块或者二个业务模块即可
3.1 销售主题的日统计宽表
可分析的主要指标有:销售收入、平台收入、配送成交额、小程序成交额、安卓APP成交额、 苹果APP成交额、PC商城成交额、订单量、参评单量、差评单量、配送单量、退款单量、小程序订单量、安卓APP订单量、苹果APP订单量、PC商城订单量。
维度有:日期、城市、商圈、店铺、品牌、大类、中类、小类
维度组合:
日期: 日
日期 + 城市
日期 + 城市 + 商圈
日期 + 城市 + 商圈 + 店铺
日期 + 品牌
日期 + 大类
日期 + 大类 + 中类
日期 + 大类 + 中类 + 小类
16 * 8 = 128 个需求指标结果
分析, 当前需求统计的这些维度 和 指标, 需要涉及到那些表, 以及涉及到那些字段呢?
维度字段:
日期: dwb_order_detail.dt
城市: dwb_shop_detail: city_id 和 city_name
商圈: dwb_shop_detail: trade_area_id 和 trade_area_name
店铺: dwb_shop_detail: id 和 store_name
品牌: dwb_goods_detail: brand_id 和 brand_name
大类: dwb_goods_detail: max_class_id 和 max_class_name
中类: dwb_goods_detail: mid_class_id 和 mid_class_name
小类: dwb_goods_detail: min_class_id 和 min_class_name
指标字段:
订单量相关指标: dwb_order_detail.order_id
订单销售收入(销售收入, 小程序, 安卓, 苹果, pc端):dwb_order_detail.order_amount
平台收入: dwb_order_detail.plat_fee
配送费: wb_order_detail.delivery_fee
涉及表:
订单明细宽表(当前主题的事实表): dwb_order_detail (事实表)
店铺明细宽表: dwb_shop_detail (维度表)
商品明细宽表: dwb_goods_detail (维度表)
关联条件:
订单表 和 店铺表:
订单明细宽表.store_id = 店铺明细宽表.id
订单表 和 商品表:
订单明细宽表.goods_id = 商品明细宽表.id
思考: 当前这个是三种数仓模型那一种呢? 星型模型
是否需要过滤一些操作呢?
1- 保证必须是支付状态: is_pay = 1
2- 保证订单状态: order_state 不能是 1(已下单, 没有付款) 和 7 (已取消)
首先, 先创建DWS层库 和 表(销售主题日统计宽表)
-- 创建库:
create database if not exists bj59_yp_dws_jiale;
-- 创建表(指标字段 + 维度字段 + 经验字段 ):
DROP TABLE IF EXISTS bj59_yp_dws_jiale.dws_sale_daycount;
CREATE TABLE bj59_yp_dws_jiale.dws_sale_daycount(
--dt STRING,
province_id string COMMENT '省份id',
province_name string COMMENT '省份名称',
city_id string COMMENT '城市id',
city_name string COMMENT '城市name',
trade_area_id string COMMENT '商圈id',
trade_area_name string COMMENT '商圈名称',
store_id string COMMENT '店铺的id',
store_name string COMMENT '店铺名称',
brand_id string COMMENT '品牌id',
brand_name string COMMENT '品牌名称',
max_class_id string COMMENT '商品大类id',
max_class_name string COMMENT '大类名称',
mid_class_id string COMMENT '中类id',
mid_class_name string COMMENT '中类名称',
min_class_id string COMMENT '小类id',
min_class_name string COMMENT '小类名称',
-- 用于标记数据结果是按照那个维度来统计的一个经验字段
group_type string COMMENT '分组类型:store,trade_area,city,brand,min_class,mid_class,max_class, all',
-- =======日统计=======
-- 销售收入
sale_amt DECIMAL(38,2) COMMENT '销售收入',
-- 平台收入
plat_amt DECIMAL(38,2) COMMENT '平台收入',
-- 配送成交额
deliver_sale_amt DECIMAL(38,2) COMMENT '配送成交额',
-- 小程序成交额
mini_app_sale_amt DECIMAL(38,2) COMMENT '小程序成交额',
-- 安卓APP成交额
android_sale_amt DECIMAL(38,2) COMMENT '安卓APP成交额',
-- 苹果APP成交额
ios_sale_amt DECIMAL(38,2) COMMENT '苹果APP成交额',
-- PC商城成交额
pcweb_sale_amt DECIMAL(38,2) COMMENT 'PC商城成交额',
-- 成交单量
order_cnt BIGINT COMMENT '成交单量',
-- 参评单量
eva_order_cnt BIGINT COMMENT '参评单量comment=>cmt',
-- 差评单量
bad_eva_order_cnt BIGINT COMMENT '差评单量negtive-comment=>ncmt',
-- 配送成交单量
deliver_order_cnt BIGINT COMMENT '配送单量',
-- 退款单量
refund_order_cnt BIGINT COMMENT '退款单量',
-- 小程序成交单量
miniapp_order_cnt BIGINT COMMENT '小程序成交单量',
-- 安卓APP订单量
android_order_cnt BIGINT COMMENT '安卓APP订单量',
-- 苹果APP订单量
ios_order_cnt BIGINT COMMENT '苹果APP订单量',
-- PC商城成交单量
pcweb_order_cnt BIGINT COMMENT 'PC商城成交单量'
)
COMMENT '销售主题日统计宽表'
PARTITIONED BY(dt STRING)
ROW format delimited fields terminated BY '\t'
stored AS orc tblproperties ('orc.compress' = 'SNAPPY');
- 根据 日期 + 城市, 统计相关的指标:
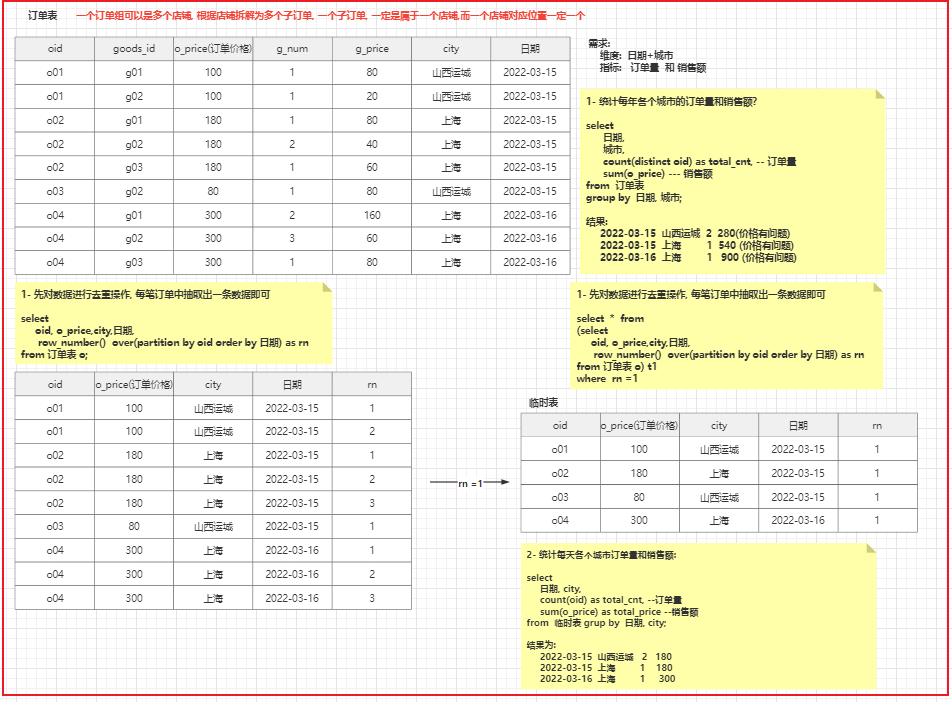
SQL实现:
留作作业, 思考如何做
- 日期+ 城市 + 商圈 (与上一个类型)
- 日期 + 品牌 : (需求思考, 处理逻辑是不一样的, 因为 一个订单中可以有多个品牌, 一个品牌可以有多个订单)
- 提供的分析图
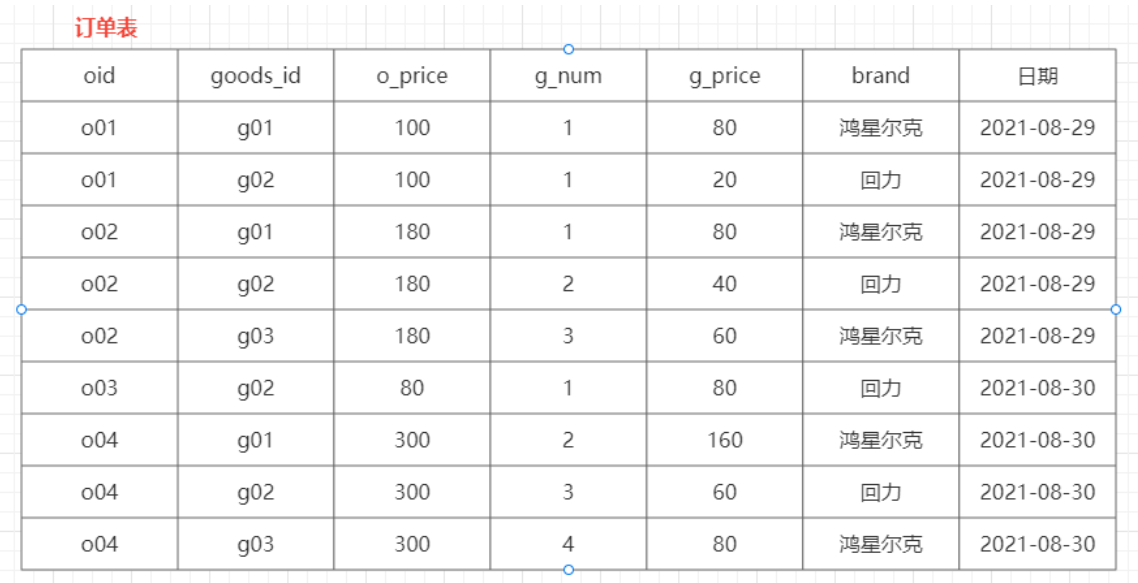
截图工具: 

若有收获,就点个赞吧
0 人点赞
