day01 新零售课程笔记
今日内容:
- 1- 新零售行业背景
- 2- 零售行业的相关业务讲解
- 3- 项目的架构介绍
- 4- cloudera manager 工具介绍
- 5- 项目环境的部署
- 6- 数仓的基本概念
- 7- 维度分析 和 数仓建模相关知识
- 8- 数仓分层
1. 新零售的行业背景
早期基本都是一些线下店铺:
阶段一: 百货商店阶段二: 超级市场(超市)阶段三: 连锁商店-----以上为线下的店铺------阶段四: 电子商务(网络销售 --- 网店) ---纯线上的销售方案阶段五: 新零售 (线上 + 线下 + 物流)
项目真实来源: 永辉超市
2. 业务模块介绍 (流程理解)
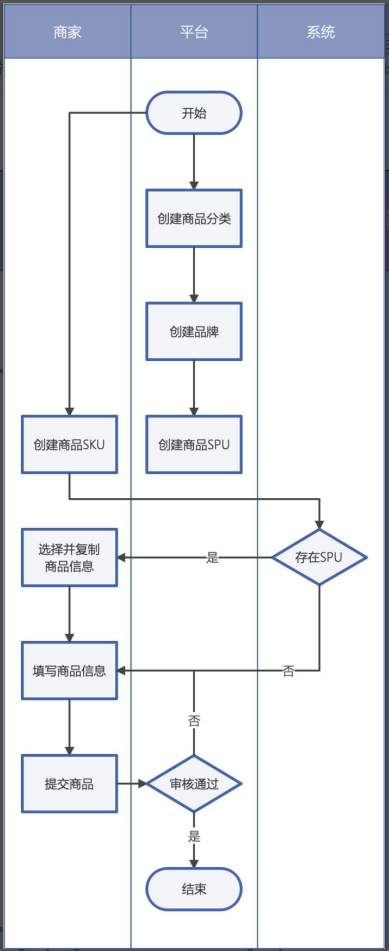
- 商品发布流程:
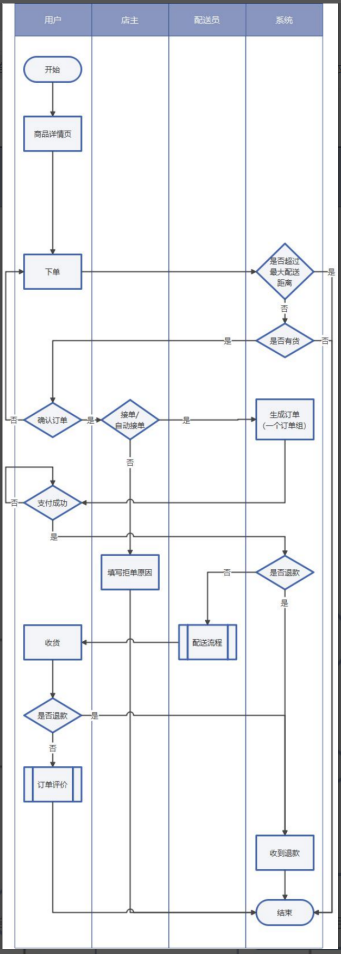
- 单店铺订单流程图
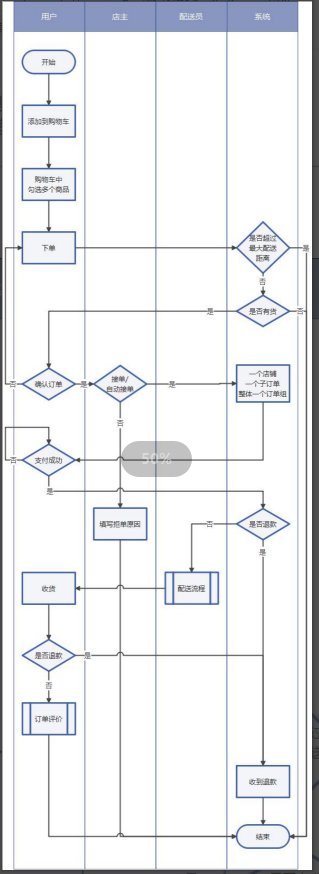
- 购物车流程
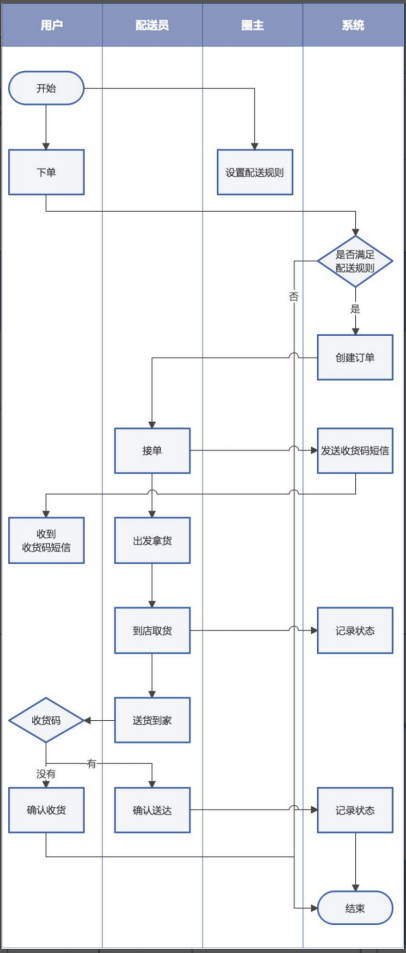
- 配送流程图
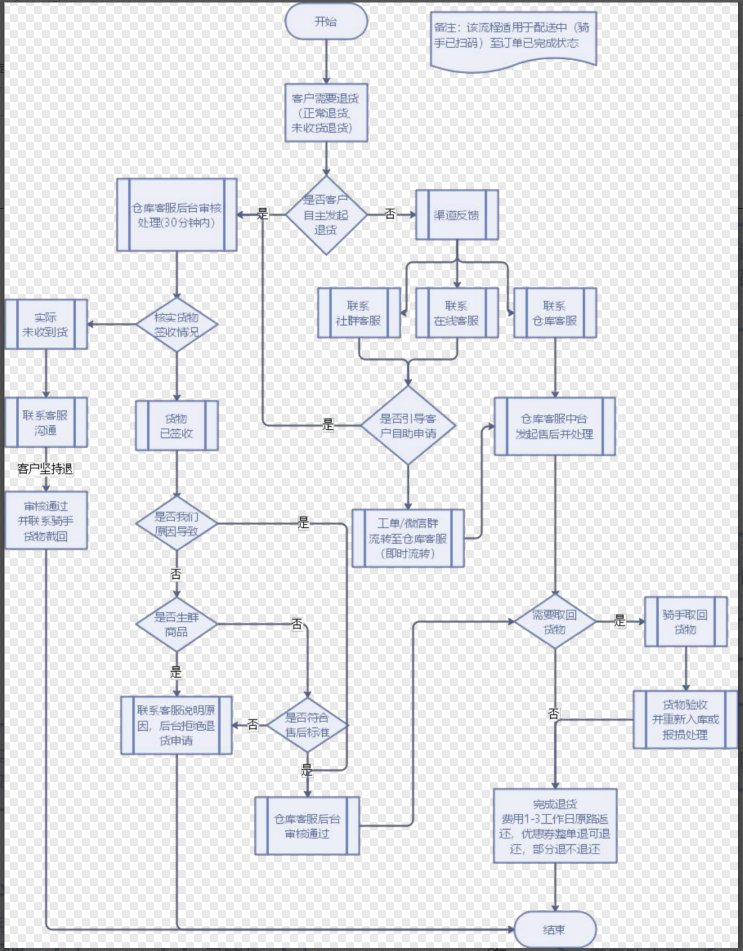
- 退货业务流程
3. 项目的架构介绍
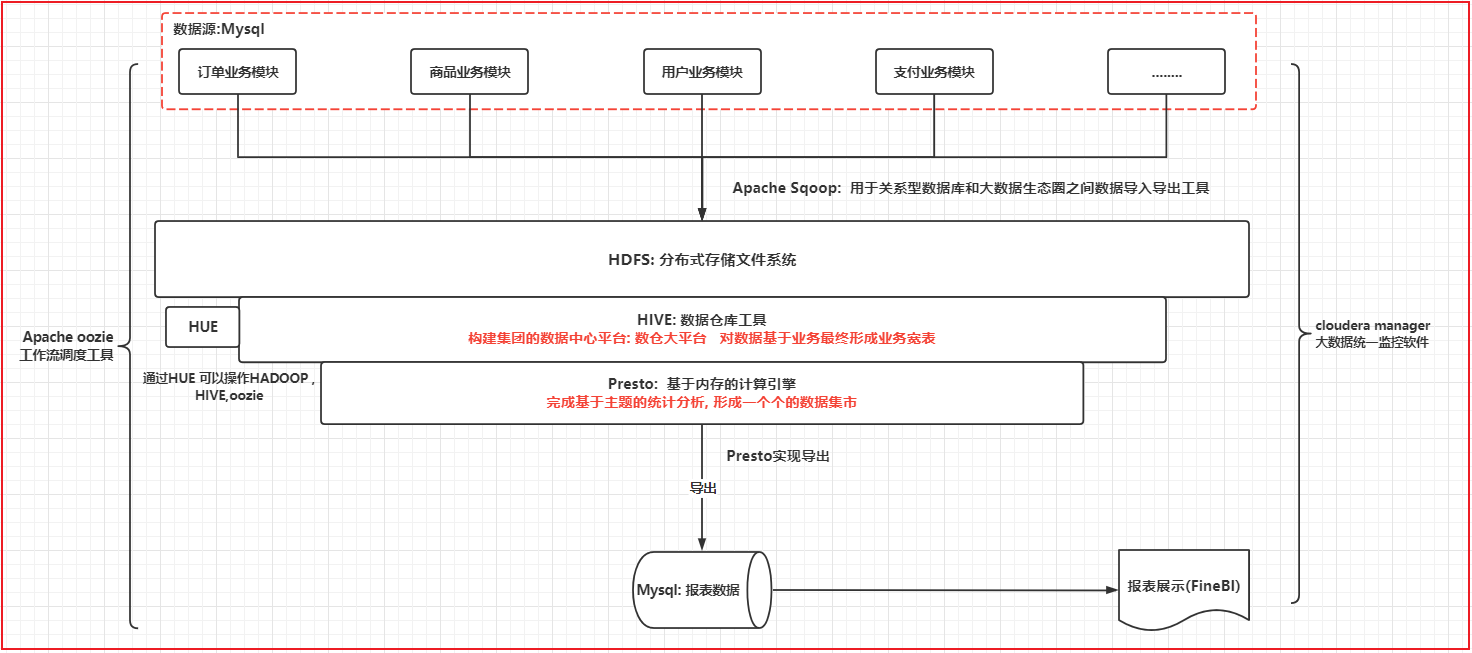
基于cloudera manager构建的大数据分析平台, 在此平台基础上, 构建有 HDFS, YARN, zookeeper, sqoop, oozie, HUE, HIVE 等相关的大数据组件, 同时为了提升分析的效率. 引入presto来进行分析处理操作, 使用FineBi实现图表展示操作, 整个分析工作是一个周而复始, 不断的干, 采用oozie完成任务的调度工作
数据流转的流程:
整个项目的数据源都是集中在MySQL中的, 通过sqoop完成数据的导入操作, 将数据导入到HDFS中, 使用HIVE构建相关的表, 建立数仓体系, 在HIVE进行分层处理, 在进行统计分析的时候, 采用presto提升分析的效率, 将分析的结果导出到Mysql中, 最后使用fineBi完成报表展示操作, 整个项目基于cloudera manager进行监控管理, 使用oozie完成工作流的调度操作
4. clouderamanager工具介绍
cloudera manager 是一款大数据的统一监控管理平台, 此平台主要是对cloudera公司旗下CDH版本软件进行管理工作, 提供的服务: 统一的监控, 自动化部署, 对CDH软件进行相关管理
产生原因:
apache版本软件所存在弊端:
部署过程极其复杂,超过20个节点的时候,手动部署已经超级累
各个组件部署完成后,各个为政,没有统一化管理界面
组件和组件之间的依赖关系很复杂,一环扣一环,部署过程心累
各个组件之间没有统一的metric可视化界面,比如说hdfs总共占用的磁盘空间、IO、运行状况等
优化等需要用户自己根据业务场景进行调整(需要手工的对每个节点添加更改配置,效率极低,我们希望的是一个配置能够自动的分发到所有的节点上)
市场需要有一款统一软件, 对大数据中各个组件进行统一化管理操作, 由此产生cloudera manager
另一个原因: cloudera 公司希望能够有更多客户使用CDH版本, 降低客户使用难度
5. 项目环境部署操作
- 将资料中提供虚拟机压缩包, 解压到一个没有中文没有空格, 以及磁盘空间相对充足的磁盘中(大于100GB)
- 修改VMware的网卡设置: 统一修改为 88网段, 网关为192.168.88.2
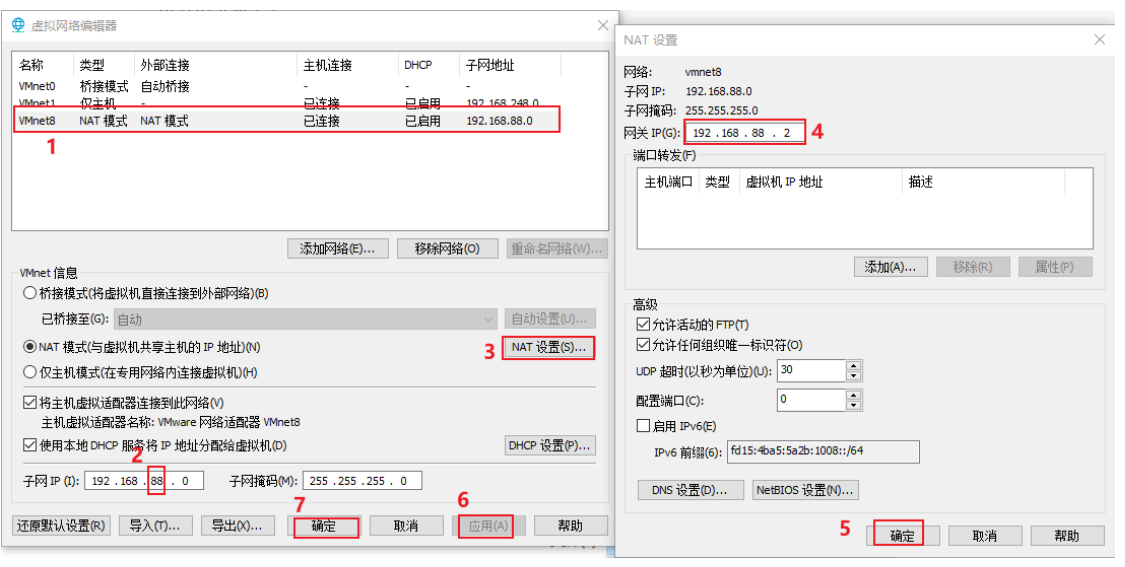
修改windows网络适配器:

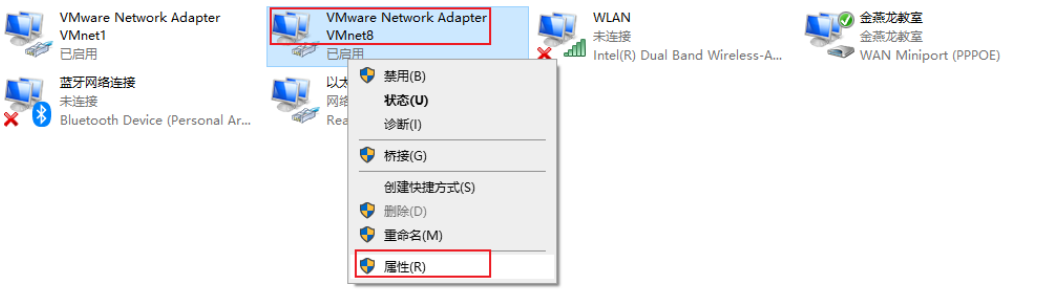
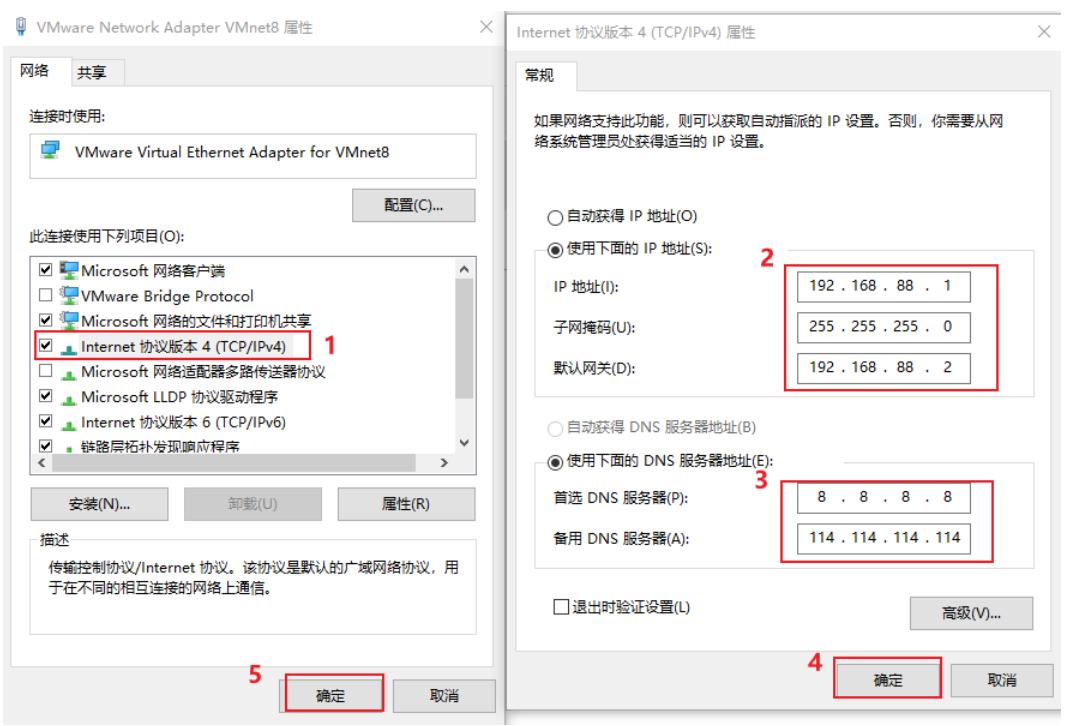
- 将两台项目虚拟机挂载到VMware上:
挂载第一台: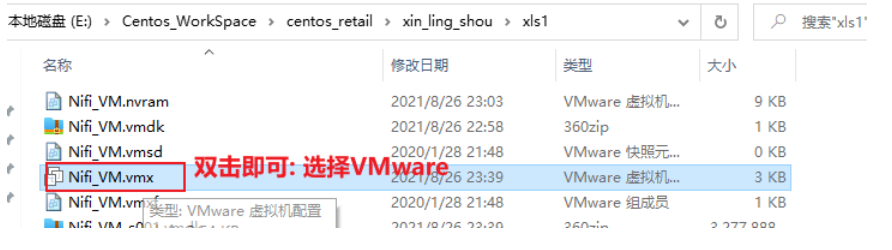
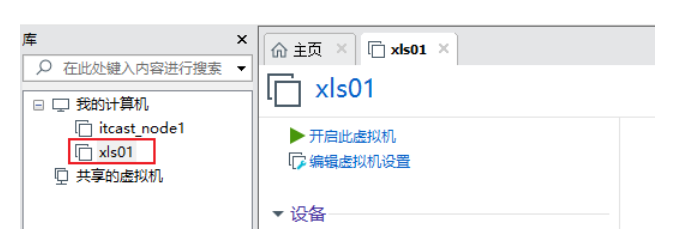
如果通过这种方式, 死活加载不进来, 建议将VMware关闭, 然后在重新双击即可
第二台与第一台类似, 也挂载中VMware上
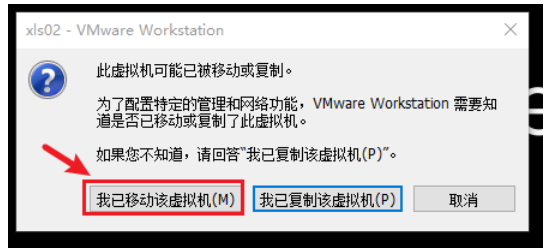
- 启动两台centos节点:
- 在启动的时候, 如果弹出一个选项, 让选择我已复制此虚拟机 和 我已移动此虚拟机, 这里一定一定一定要选择我已移动此虚拟机
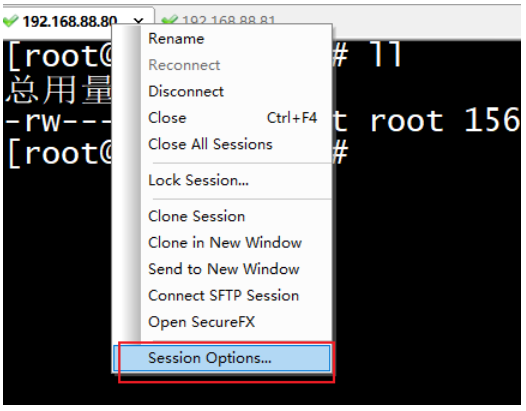
- 通过CRT连接虚拟机即可: ```properties hadoop01: 192.168.88.80 hadoop02: 192.168.88.81
用户名: root 密码: 123456
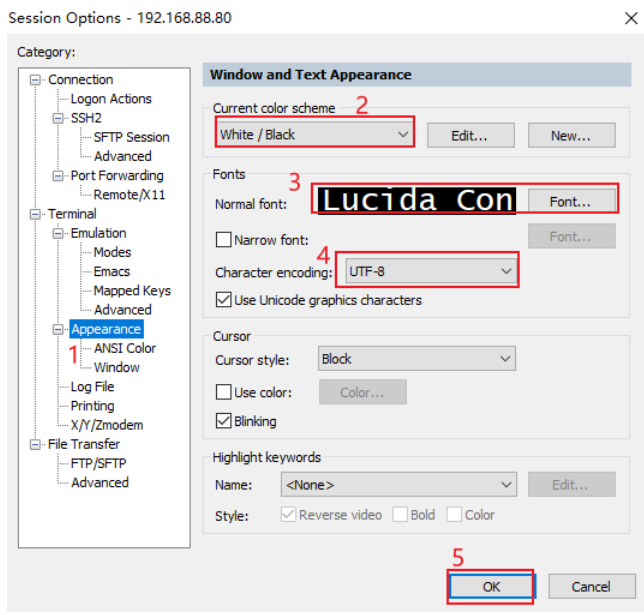
注意: 记得修改CRT的编码和 控制台的模式为linux
<br />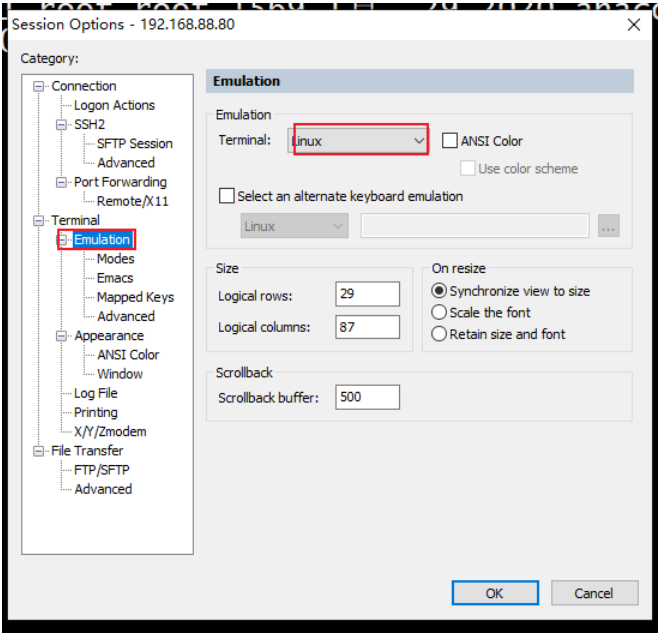
6. 在windows的hosts文件中, 添加映射信息: C:\Windows\System32\drivers\etc
```properties
添加以下内容:
192.168.88.80 hadoop01 hadoop01.itcast.cn
192.168.88.81 hadoop02 hadoop02.itcast.cn
更改方式: 将hosts文件拉到桌面上, 添加后, 将其拖回去即可
- 连接cloudera manager ``` http://hadoop01:7180
用户名: admin 密码: admin
注意: 后续关闭虚拟机: 务必使用shutdown -h now | init 0 万万不可直接强制关机 重启虚拟机: 使用reboot命令 长时间不使用虚拟机, 建议将其关机(尤其是使用机械硬盘的) 比如中午的时候
启动服务器后, 并不能立即访问, 需要等待大约 5~15分钟的时候后, 才可以正常访问 7180
<br />内存不足的同学, 看到以下界面, 即可认为环境安装完成
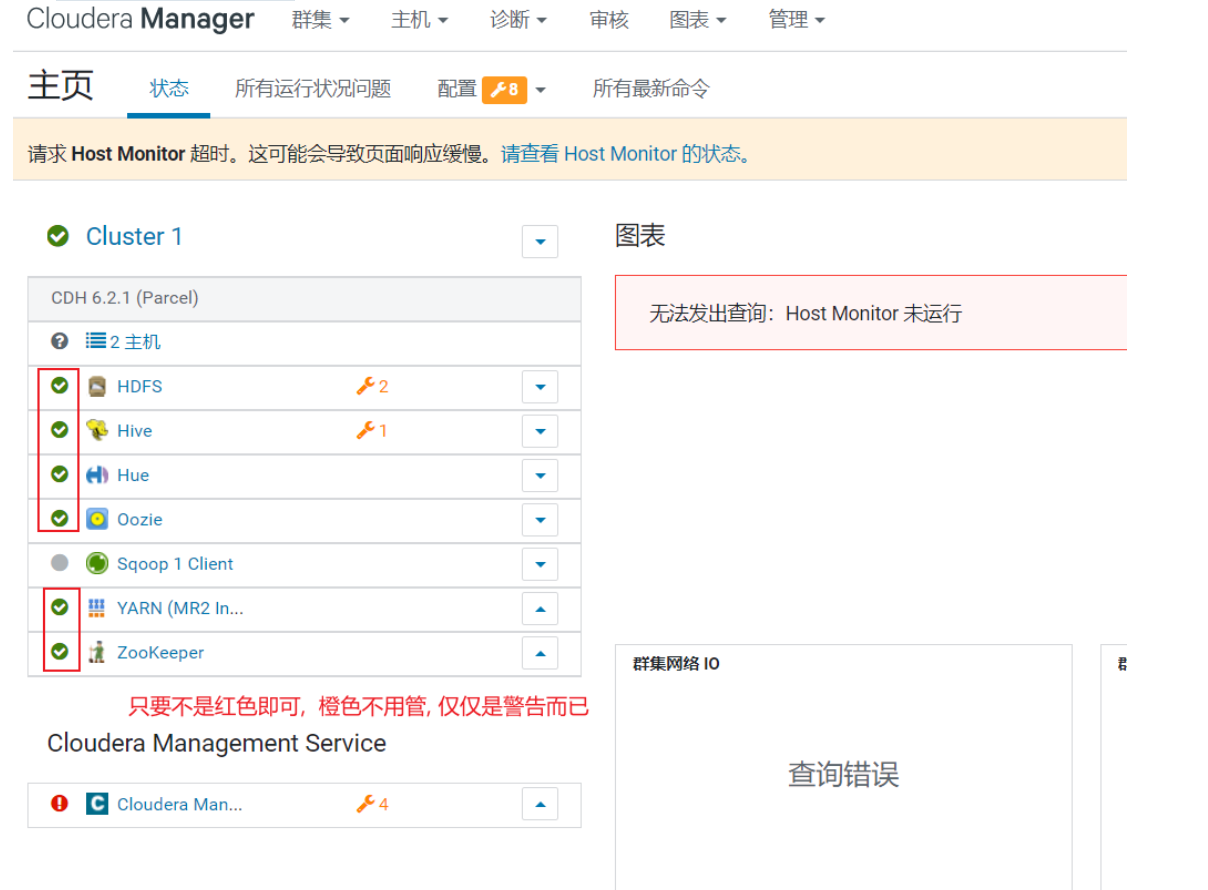<br />对于内存, 比较OK的同学, 可以将cloudera manager 所有服务全部开启:<br />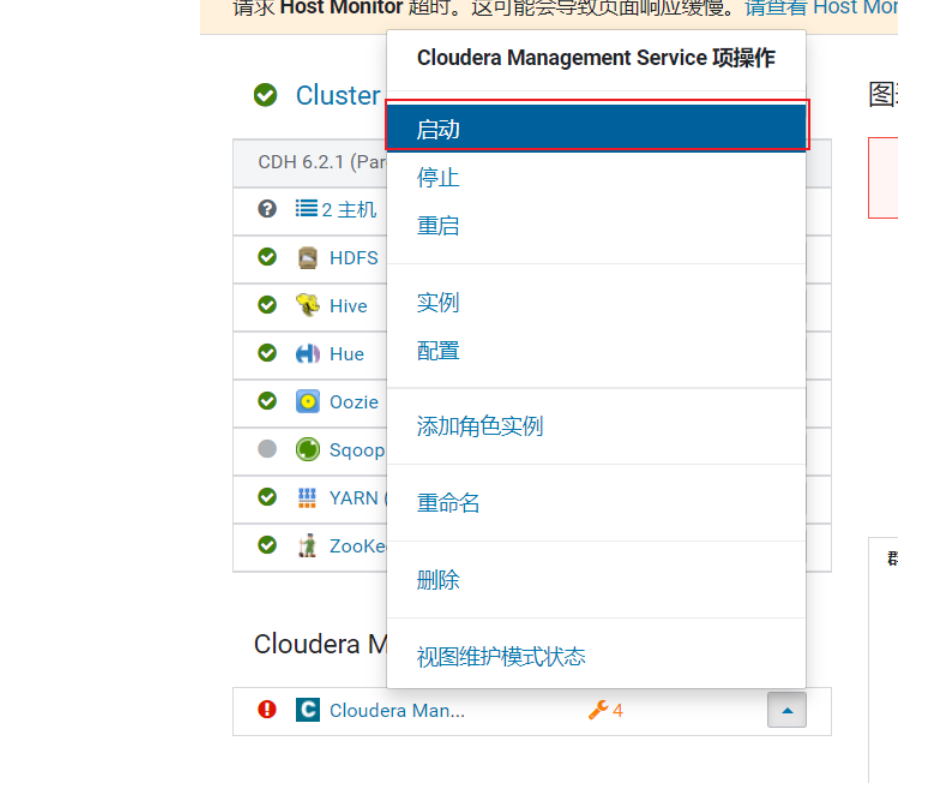<br />
如果内存完全不足, 比如内存只有 8GB, 或者 12GB同学
8GB: 后续程序运行的时候, 可能出现内存溢出问题, 后续所有SQL都需要分批次执行 node1内存配置: 5.5GB node2内存配置: 2GB
12GB:
node1: 内存配置 7GB
node2: 内存配置 5GB
然后, 需要关闭CM的所有监控服务, 不允许开启<br />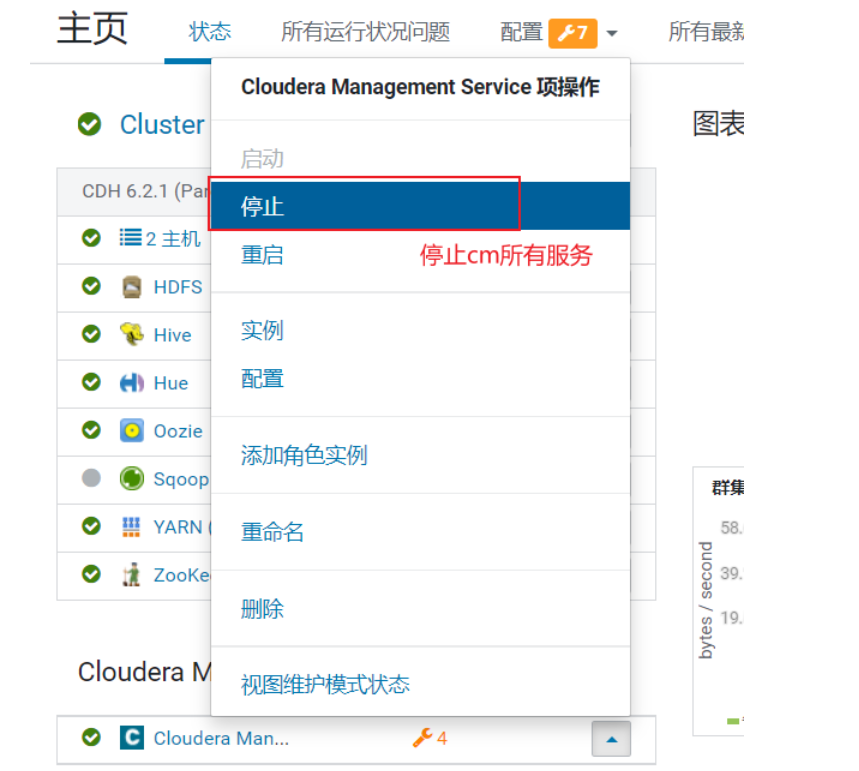<br />最后界面:<br />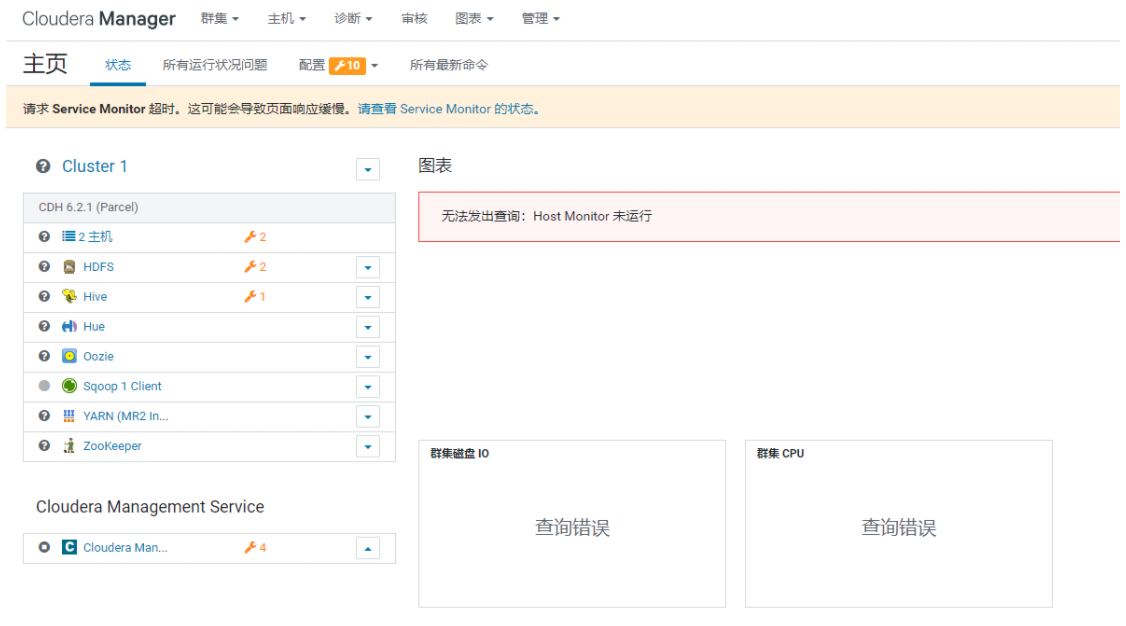<br />如果内存不足, 又想看监控状态, 可以只开启cloudera manager监控操作: (默认)
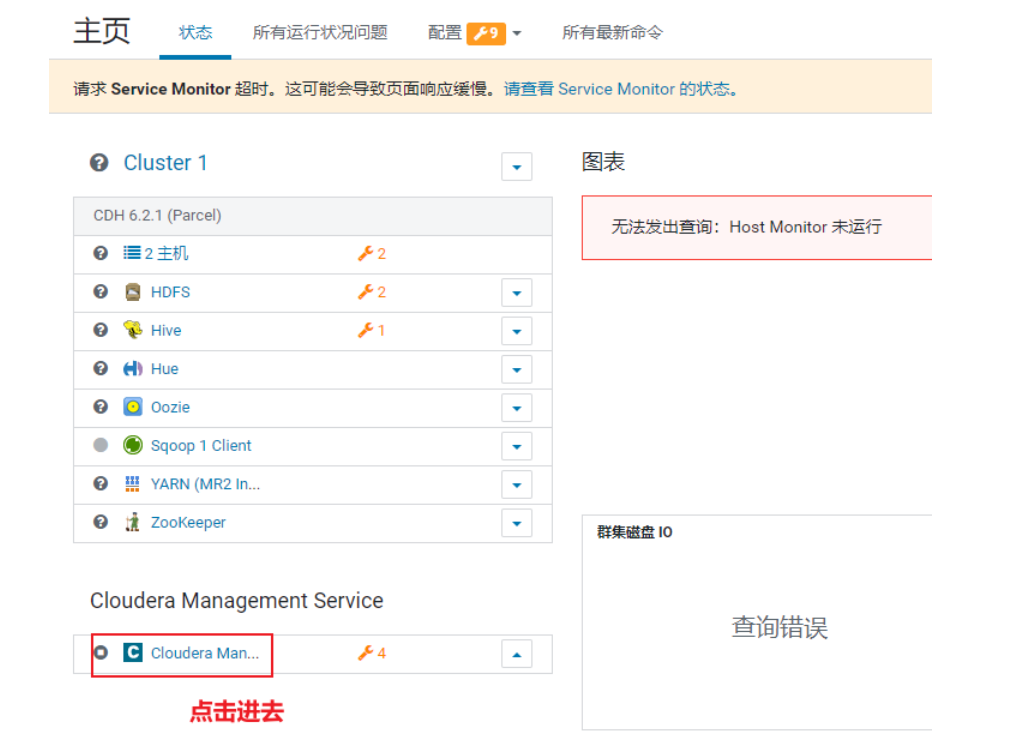<br />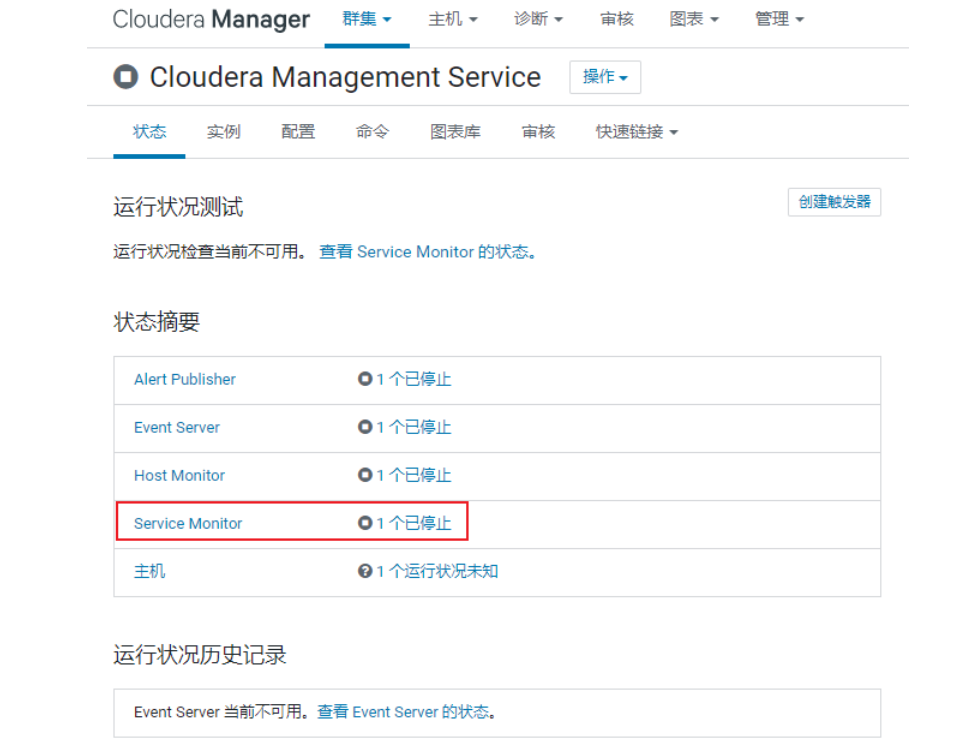<br />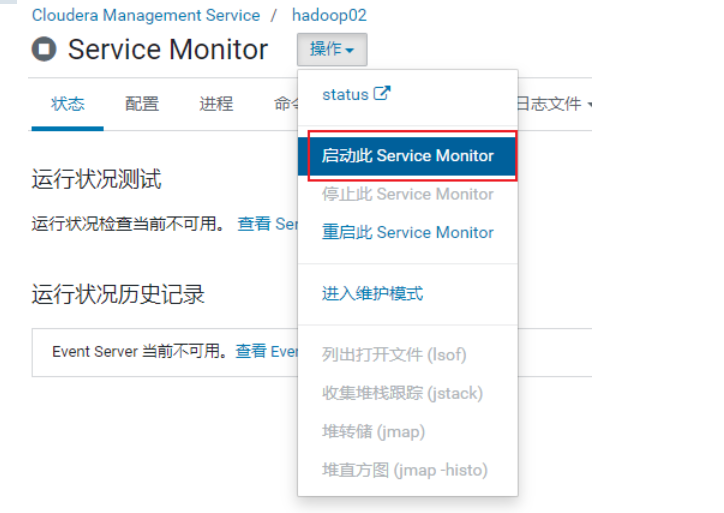<br />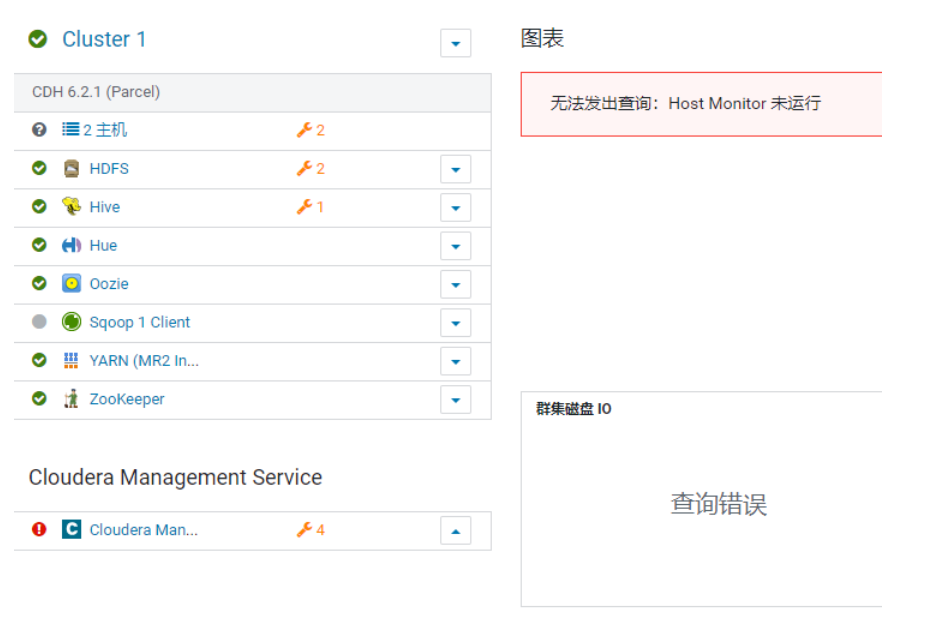
注意:
```properties
后续不使用虚拟机的时候, 一定要关闭, 不允许挂起, 否则可能导致服务器出现崩溃, 需要重新解压
在关闭的时候, 建议使用 shutdown -h now 或者 init 0 命令, 不要强关, 否则可能导致服务器出现崩溃, 需要重新解压
长时间不用的时候, 建议将服务器关闭....
6. 数据仓库的基本概念
- 1- 什么是数据仓库呢?
存储数据的仓库, 主要用于存储过去历史发生过的数据,面向主题, 对数据进行统计分析的操作, 从而能够对未来提供决策支持
- 2- 数据仓库最大的特点是什么呢?
数据仓库既不生产数据, 也不消耗数据, 数据来源于各个数据源
- 3- 数据仓库的四大特征:
1- 面向主题: 分析什么 什么就是我们的主题
2- 集成性: 数据从各个数据源汇聚而来, 数据的结构都不一定一样
3- 非易失性(稳定性): 存储都是过去历史的数据, 不会发送变更, 甚至某些数据仓库都不支持修改操作
4- 时变性: 随着时间推移, 将最近发生的数据也需要放置到数据仓库中, 同时分析的方案也无法满足当前需求, 需要变更分析的手段
- 4- OLAP 和 OLTP区别:
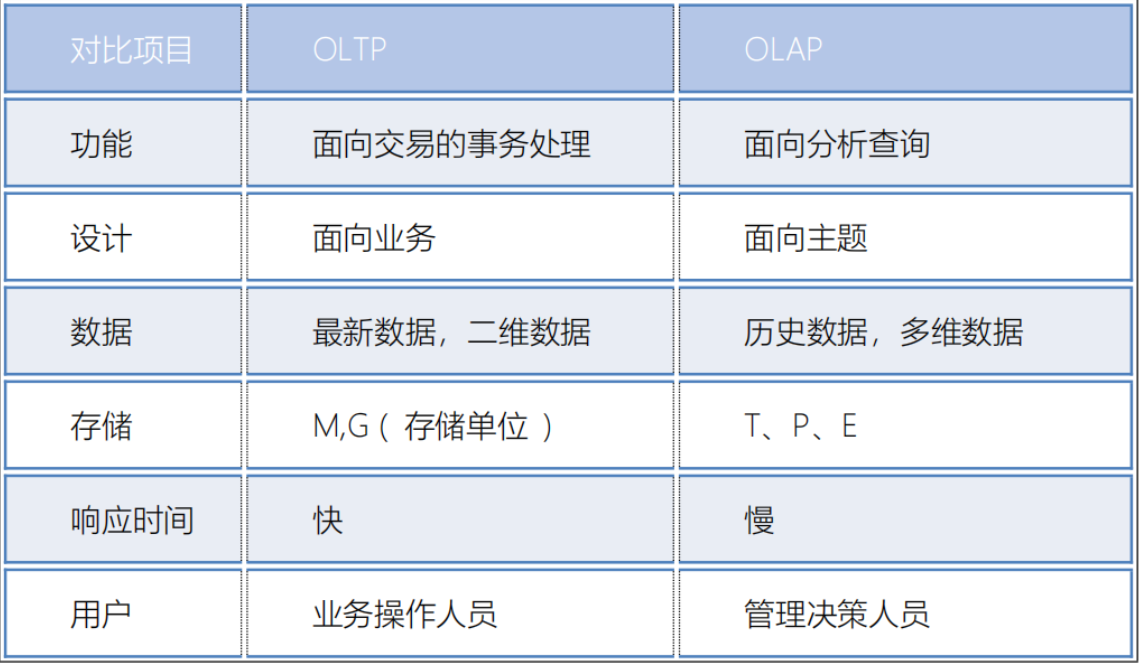
- 5- 什么是ETL:
ETL: 抽取 转换 加载
狭义上ETL:
指的数据从ODS层抽取出来, 对ODS层的数据进行清洗转换处理的操作, 将清洗转换后的数据加载到DW层过程
宽泛的ETL:
指的是数仓的全过程
- 6- 什么是数据仓库 和 数据集市
数据仓库是包含数据集市的, 在一个数据仓库中可以有多个数据集市
数据仓库: 一般指的构建集团数据中心, 基于业务形成各种业务的宽表或者统计宽表
数据集市: 基于部门或者基于主题, 形成主题或者部门相关的统计宽表
7. 维度分析的基本介绍
- 维度:
什么是维度?
看待问题角度, 当我们对一个主题进行分析的时候, 可以从不同的角度来分析, 这些角度就是维度
比如说: 对订单进行分析 可以从 用户, 时间, 地区, 商家, 商圈....
维度的分类:
定性维度: 一般指的统计 每个 各个 这种维度, 比如 统计每天 每小时 各个用户...
这种维度在编写SQL, 一般是放置在 group by
定量维度: 一般指的统计某个范围, 或者某个具体值的, 比如 统计年龄在18~60岁, 时间为2021年度
这种维度在编写 SQL, 一般是放置在 where条件
上卷 和 下钻:
比如说 我们以天作为标准, 上卷统计 周 月 年 下钻统计: 小时
分层或者分级:
比如说: 以地区为例, 将地区划分为 省份 市 县/区
从数仓分析的角度来看待, 指的多了分析的维度而已
- 指标:
什么是指标?
衡量事务发展的标准,也叫度量, 简单来说: 在根据维度进行分析的时候, 必然要分析出一些结果, 这个结果就是度量
常见的度量值有那些:
count(), sum(), min(),max(),avg()
指标的分类:
绝对指标: 指的统计计算一个具体的值, 比如说 销售额, 订单量
必须要对全部的数据进行统计处理
count(), sum(), min(),max(),avg()
相对指标: 指的统计相对的结果, 比如说 同比增长 环比增长 流失率 增长率...
这些指标在计算的时候, 是可以不需要对全部数据进行统计
可以通过抽样的方式来计算即可
例子:
需求:
请统计在2021年度, 来自于北京 女性 未婚, 年龄在 18 ~28 之间的每天的销售总额是多少?
分析:
涉及到维度: 时间维度, 地区维度, 性别, 婚姻状态, 年龄
定性维度: 每天
定量维度: 2021, 北京 女性 未婚 年龄
涉及指标: 销售额(绝对指标)
sum()
SQL:
select day, sum(price) from where 时间 = 2021 and address = '北京' and sex = '女性' and status = '未婚' and age between 18 and 28 group by day;

若有收获,就点个赞吧
0 人点赞
