今日内容:
- 1- DWS销售主题的日统计宽表(日期 + 城市, 日期+城市+商圈 , 日期+ 品牌) (操作)
- 2- HIVE的其他优化点 (记录)
- 3- Presto相关内容
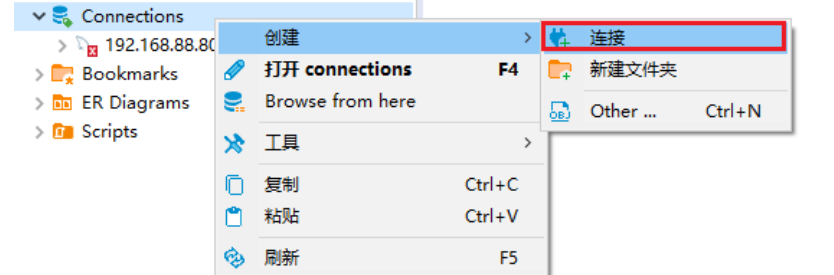
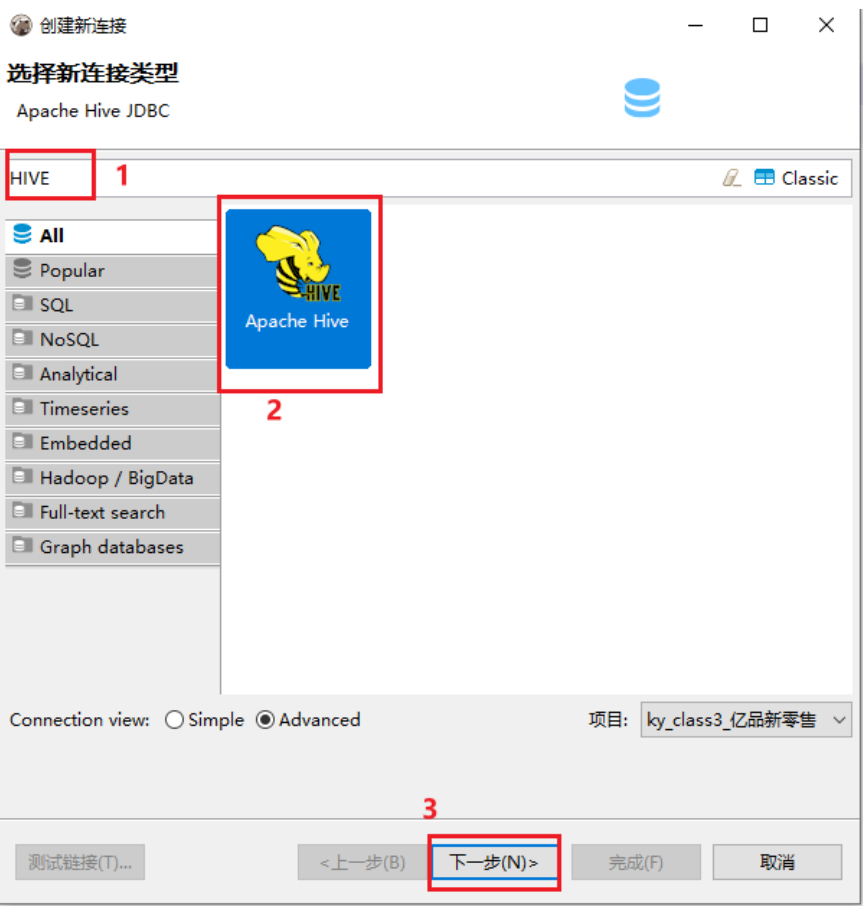
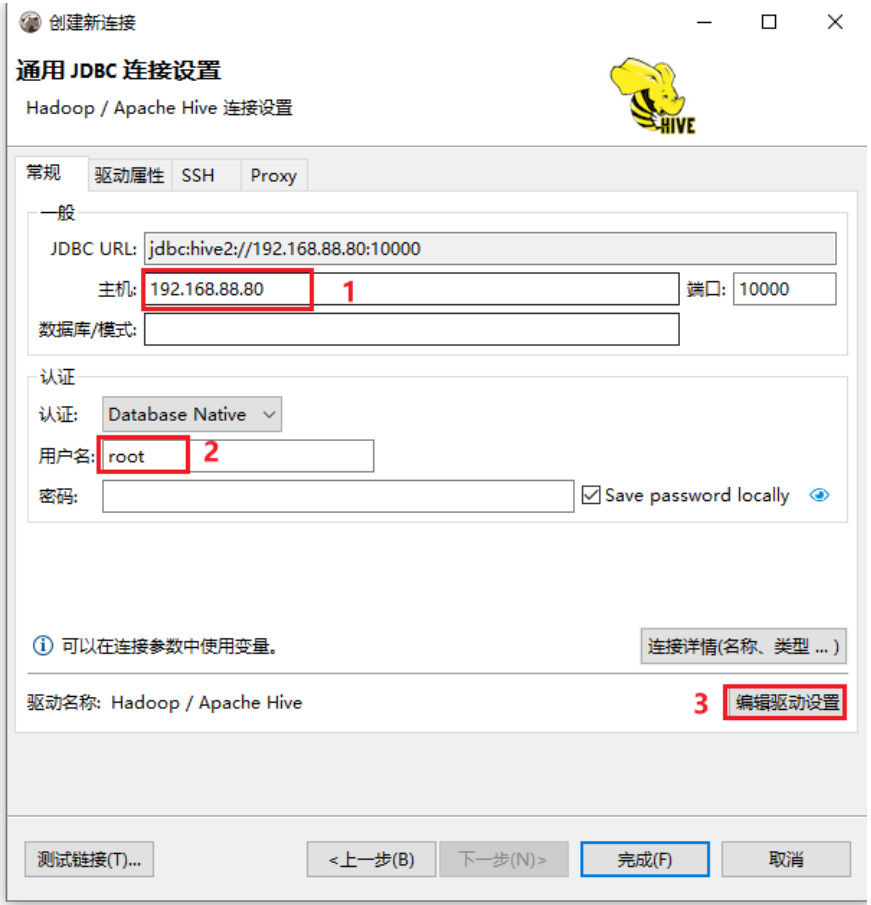
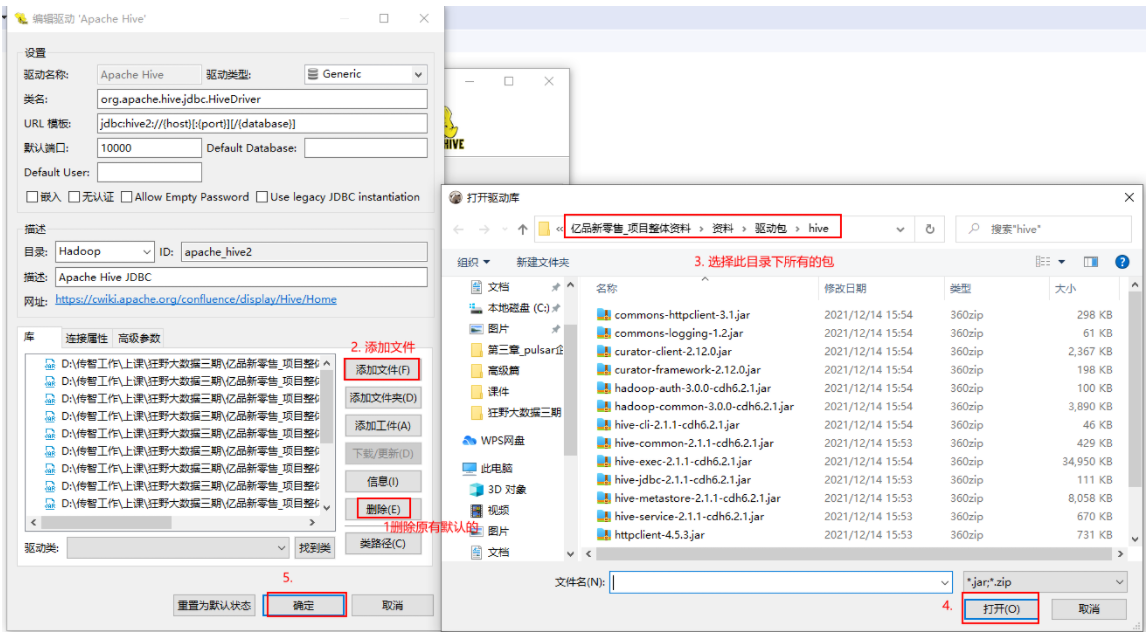
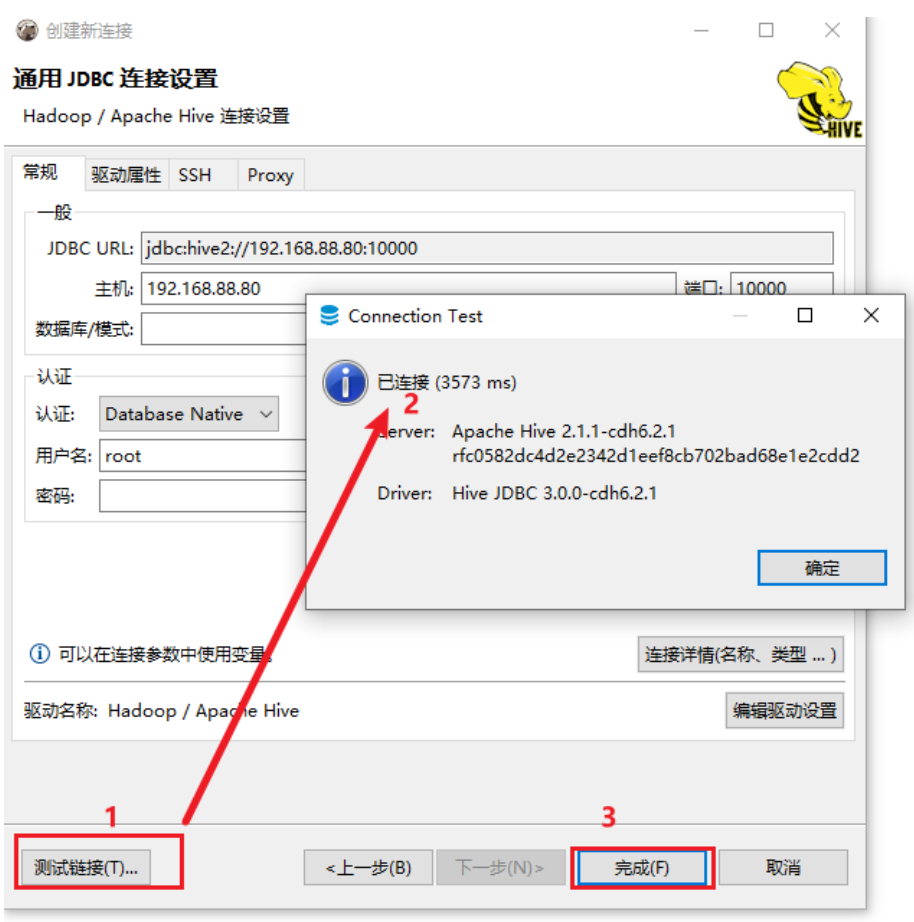
说明: ;连接云环境的时候, 目前可能报出 连接拒绝, 主要原因, 远端环境不允许连接10000端口号
后续开启后, 大家即可连接
1- DWS层实现
DWS层: 业务层
基于主题统计分析, 此层一般适用于进行细化粒度的聚合统计操作, 主要为了服务后续上卷统计过程 (提前聚合操作)
比如说:以年 月 日 来统计操作, 在DWS层, 仅需要按照 日进行统计相关的指标即可, 进行提前聚合操作后续在DM层, 进行上卷操作, 将 月 和 年 基于日统计宽表 计算得出注意:如果要进行提前聚合操作, 不能对数据进行去重统计 ,比如说: 要统计用户量, 分别统计 每天 每月 每年的数据对于用户, 可能今天购买, 明天也会, 这个月会购买, 下个月也会购买如果先按照每天统计用户量, 得出一个结果, 比如说2022-05-01: 用户量 1002022-05-02: 用户量 160此时统计五月份的数据: 如果直接将 100 + 160 = 260 用户 这是错误, 可能实际只有 180个用户所以说: 如果需要去重计算指标, 不管计算日 月 年, 都需要针对原始数据来计算处理, 不能提前聚合
本次DWS层, 共计有三个主题需要进行统计: 销售主题, 商品主题, 和 用户主题, 在实际面试中, 可以只负责其中一个主题或者二个主题即可, 无需全部负责, 但是学习中, 希望三个主题都能全部搞定
对于DWS层以前的层次, 仅负责其中一个业务模块或者二个业务模块即可
1.1 销售主题的日统计宽表
可分析的主要指标有:销售收入、平台收入、配送成交额、小程序成交额、安卓APP成交额、 苹果APP成交额、PC商城成交额、订单量、参评单量、差评单量、配送单量、退款单量、小程序订单量、安卓APP订单量、苹果APP订单量、PC商城订单量。
维度有:日期、城市、商圈、店铺、品牌、大类、中类、小类
维度组合:
日期: 日
日期 + 城市
日期 + 城市 + 商圈
日期 + 城市 + 商圈 + 店铺
日期 + 品牌
日期 + 大类
日期 + 大类 + 中类
日期 + 大类 + 中类 + 小类
16 * 8 = 128 个需求指标结果
分析, 当前需求统计的这些维度 和 指标, 需要涉及到那些表, 以及涉及到那些字段呢?
维度字段:
日期: dwb_order_detail.dt
城市: dwb_shop_detail: city_id 和 city_name
商圈: dwb_shop_detail: trade_area_id 和 trade_area_name
店铺: dwb_shop_detail: id 和 store_name
品牌: dwb_goods_detail: brand_id 和 brand_name
大类: dwb_goods_detail: max_class_id 和 max_class_name
中类: dwb_goods_detail: mid_class_id 和 mid_class_name
小类: dwb_goods_detail: min_class_id 和 min_class_name
指标字段:
订单量相关指标: dwb_order_detail.order_id
订单销售收入(销售收入, 小程序, 安卓, 苹果, pc端):dwb_order_detail.order_amount
平台收入: dwb_order_detail.plat_fee
配送费: wb_order_detail.delivery_fee
涉及表:
订单明细宽表(当前主题的事实表): dwb_order_detail (事实表)
店铺明细宽表: dwb_shop_detail (维度表)
商品明细宽表: dwb_goods_detail (维度表)
关联条件:
订单表 和 店铺表:
订单明细宽表.store_id = 店铺明细宽表.id
订单表 和 商品表:
订单明细宽表.goods_id = 商品明细宽表.id
思考: 当前这个是三种数仓模型那一种呢? 星型模型
是否需要过滤一些操作呢?
1- 保证必须是支付状态: is_pay = 1
2- 保证订单状态: order_state 不能是 1(已下单, 没有付款) 和 7 (已取消)
首先, 先创建DWS层库 和 表(销售主题日统计宽表)
-- 创建库:
create database if not exists bj59_yp_dws_jiale;
-- 创建表(指标字段 + 维度字段 + 经验字段 ):
DROP TABLE IF EXISTS bj59_yp_dws_jiale.dws_sale_daycount;
CREATE TABLE bj59_yp_dws_jiale.dws_sale_daycount(
--dt STRING,
province_id string COMMENT '省份id',
province_name string COMMENT '省份名称',
city_id string COMMENT '城市id',
city_name string COMMENT '城市name',
trade_area_id string COMMENT '商圈id',
trade_area_name string COMMENT '商圈名称',
store_id string COMMENT '店铺的id',
store_name string COMMENT '店铺名称',
brand_id string COMMENT '品牌id',
brand_name string COMMENT '品牌名称',
max_class_id string COMMENT '商品大类id',
max_class_name string COMMENT '大类名称',
mid_class_id string COMMENT '中类id',
mid_class_name string COMMENT '中类名称',
min_class_id string COMMENT '小类id',
min_class_name string COMMENT '小类名称',
-- 用于标记数据结果是按照那个维度来统计的一个经验字段
group_type string COMMENT '分组类型:store,trade_area,city,brand,min_class,mid_class,max_class, all',
-- =======日统计=======
-- 销售收入
sale_amt DECIMAL(38,2) COMMENT '销售收入',
-- 平台收入
plat_amt DECIMAL(38,2) COMMENT '平台收入',
-- 配送成交额
deliver_sale_amt DECIMAL(38,2) COMMENT '配送成交额',
-- 小程序成交额
mini_app_sale_amt DECIMAL(38,2) COMMENT '小程序成交额',
-- 安卓APP成交额
android_sale_amt DECIMAL(38,2) COMMENT '安卓APP成交额',
-- 苹果APP成交额
ios_sale_amt DECIMAL(38,2) COMMENT '苹果APP成交额',
-- PC商城成交额
pcweb_sale_amt DECIMAL(38,2) COMMENT 'PC商城成交额',
-- 成交单量
order_cnt BIGINT COMMENT '成交单量',
-- 参评单量
eva_order_cnt BIGINT COMMENT '参评单量comment=>cmt',
-- 差评单量
bad_eva_order_cnt BIGINT COMMENT '差评单量negtive-comment=>ncmt',
-- 配送成交单量
deliver_order_cnt BIGINT COMMENT '配送单量',
-- 退款单量
refund_order_cnt BIGINT COMMENT '退款单量',
-- 小程序成交单量
miniapp_order_cnt BIGINT COMMENT '小程序成交单量',
-- 安卓APP订单量
android_order_cnt BIGINT COMMENT '安卓APP订单量',
-- 苹果APP订单量
ios_order_cnt BIGINT COMMENT '苹果APP订单量',
-- PC商城成交单量
pcweb_order_cnt BIGINT COMMENT 'PC商城成交单量'
)
COMMENT '销售主题日统计宽表'
PARTITIONED BY(dt STRING)
ROW format delimited fields terminated BY '\t'
stored AS orc tblproperties ('orc.compress' = 'SNAPPY');
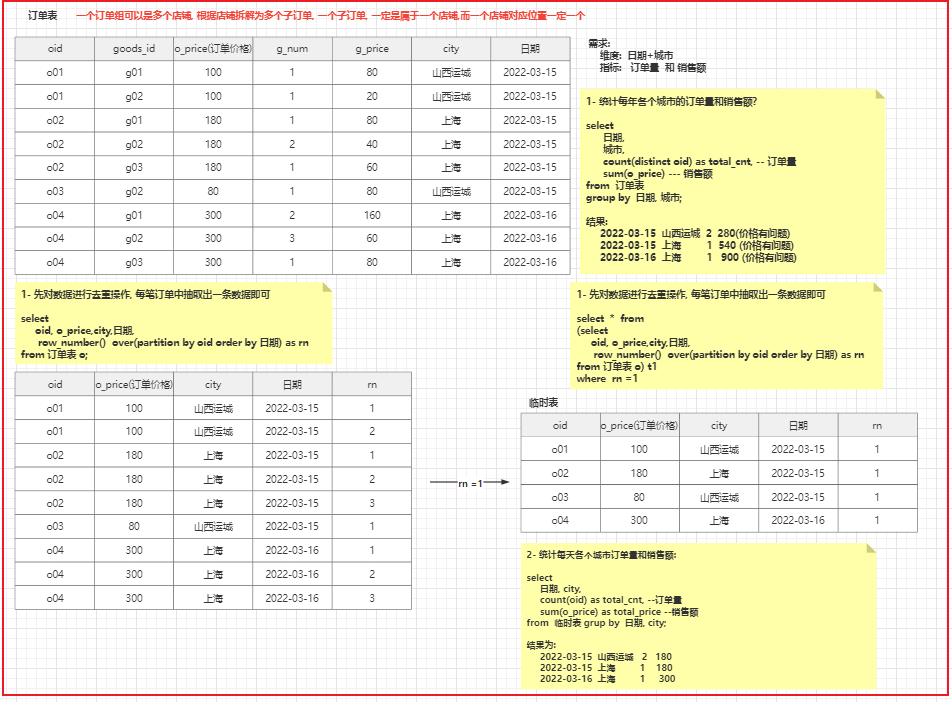
- 根据 日期 + 城市, 统计相关的指标:
SQL实现:
-- 开启动态分区支持:
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=10000;
set hive.exec.max.dynamic.partitions=100000;
set hive.exec.max.created.files=150000;
-- hive压缩
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
-- 写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
-- map join 优化操作
set hive.auto.convert.join=true;
set hive.auto.convert.join.noconditionaltask.size=20971520;
-- group by 数据倾斜的优化
-- set hive.map.aggr=true; -- 方案一
set hive.groupby.skewindata=true; -- 方案二
-- 日期 + 城市
-- 第一步: 先去重操作
with t1 as (
select
--维度字段:
o.dt,
s.province_id,
s.province_name,
s.city_id,
s.city_name,
-- 指标字段
o.order_id , -- 订单ID, 计算订单量相关指标
o.order_amount, -- 订单额, 计算订单销售收入相关指标
o.plat_fee, -- 平台分润
o.delivery_fee, -- 配送费用
-- 判断字段,
o.order_from, -- 渠道类型
o.evaluation_id, -- 评价ID, 用于判断是否参评
o.geval_scores, -- 综合评分
o.delievery_id, -- 配送ID, 用于判断是否配送
o.refund_id, -- 退款ID, 用于判断是否退款单
-- 去重操作处理逻辑:
row_number() over(partition by o.order_id) as rn
from bj59_yp_dwb_jiale.dwb_order_detail o
left join bj59_yp_dwb_jiale.dwb_shop_detail s on o.store_id = s.id
left join bj59_yp_dwb_jiale.dwb_goods_detail g on o.goods_id = g.id
-- 确保订单是支付状态
where o.is_pay = 1 and o.order_state not in(1,7)
)
insert overwrite table bj59_yp_dws_jiale.dws_sale_daycount partition(dt)
select
province_id,
province_name,
city_id,
city_name,
'-1' as trade_area_id,
'-1' as trade_area_name ,
'-1' as store_id ,
'-1' as store_name ,
'-1' as brand_id ,
'-1' as brand_name ,
'-1' as max_class_id ,
'-1' as max_class_name ,
'-1' as mid_class_id ,
'-1' as mid_class_name ,
'-1' as min_class_id ,
'-1' as min_class_name ,
'city' as group_type,
-- --------------以下为指标统计操作---------------------
-- coalesce:(字段1,字段2....): 用于返回第一个不为null的值
sum(coalesce(order_amount,0)) as sale_amt,
sum(coalesce(plat_fee,0)) as plat_amt, -- 平台收入
sum(coalesce(delivery_fee,0)) as deliver_sale_amt, -- 配送成交额
sum(
if(
order_from = 'miniapp',
coalesce(order_amount,0),
0
)
) as mini_app_sale_amt, -- 小程序成交额
sum(
if(
order_from = 'android',
coalesce(order_amount,0),
0
)
) as android_sale_amt, -- Android成交额
sum(
if(
order_from = 'ios',
coalesce(order_amount,0),
0
)
) as ios_sale_amt, -- IOS成交额
sum(
if(
order_from = 'pcweb',
coalesce(order_amount,0),
0
)
) as pcweb_sale_amt, -- pc商城成交额
count(order_id) as order_cnt , -- 成交单量
-- 参评单量: 订单被评价了, 就说明这个订单属于参评订单了, 需要进行统计
count(
if(
evaluation_id is not null ,
order_id,
NULL
)
) as eva_order_cnt, -- 参评单量
-- 差评单量: 必须评价, 而且呢, 评价分数比较低
count(
if(
evaluation_id is not null and geval_scores is not null and geval_scores <=6,
order_id,
NULL
)
) as bad_eva_order_cnt,
-- 配送成交单量: 订单必须是已经被配送的, 如果配送,属于配送单
count(
if(
delievery_id is not null,
order_id,
null
)
) as deliver_order_cnt, -- 配送成交单量
-- 退款单量: 如果说退款ID存在, 说明订单一定是退款单
count(
if(
refund_id is not null,
order_id,
null
)
) as refund_order_cnt,
count(
if(
order_from = 'miniapp',
order_id,
NULL
)
) as mini_app_order_cnt, -- 小程序订单量
count(
if(
order_from = 'android',
order_id,
NULL
)
) as android_order_cnt, -- Android订单量
count(
if(
order_from = 'ios',
order_id,
NULL
)
) as ios_order_cnt, -- IOS订单量
count(
if(
order_from = 'pcweb',
order_id,
NULL
)
) as pcweb_order_cnt, -- pc商城订单量
dt
from t1 where rn = 1
group by dt, province_id,province_name,city_id,city_name;
- 日期+ 城市 + 商圈 (与上一个类型)
```sql
— 开启动态分区支持:
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=10000;
set hive.exec.max.dynamic.partitions=100000; set hive.exec.max.created.files=150000;
— hive压缩 set hive.exec.compress.intermediate=true; set hive.exec.compress.output=true;
— 写入时压缩生效 set hive.exec.orc.compression.strategy=COMPRESSION;
— map join 优化操作 set hive.auto.convert.join=true; set hive.auto.convert.join.noconditionaltask.size=20971520;
— group by 数据倾斜的优化 — set hive.map.aggr=true; — 方案一 set hive.groupby.skewindata=true; — 方案二
— 日期 + 城市
— 第一步: 先去重操作 with t1 as ( select —维度字段: o.dt, s.province_id, s.province_name, s.city_id, s.city_name, s.trade_area_id, s.trade_area_name, — 指标字段 o.order_id , — 订单ID, 计算订单量相关指标 o.order_amount, — 订单额, 计算订单销售收入相关指标 o.plat_fee, — 平台分润 o.delivery_fee, — 配送费用
-- 判断字段,
o.order_from, -- 渠道类型
o.evaluation_id, -- 评价ID, 用于判断是否参评
o.geval_scores, -- 综合评分
o.delievery_id, -- 配送ID, 用于判断是否配送
o.refund_id, -- 退款ID, 用于判断是否退款单
-- 去重操作处理逻辑:
row_number() over(partition by o.order_id) as rn
from bj59_yp_dwb_jiale.dwb_order_detail o
left join bj59_yp_dwb_jiale.dwb_shop_detail s on o.store_id = s.id
left join bj59_yp_dwb_jiale.dwb_goods_detail g on o.goods_id = g.id
-- 确保订单是支付状态
where o.is_pay = 1 and o.order_state not in(1,7)
) insert into table bj59_yp_dws_jiale.dws_sale_daycount partition(dt) select province_id, province_name, city_id, city_name, trade_area_id, trade_area_name , ‘-1’ as store_id , ‘-1’ as store_name , ‘-1’ as brand_id , ‘-1’ as brand_name , ‘-1’ as max_class_id , ‘-1’ as max_class_name , ‘-1’ as mid_class_id , ‘-1’ as mid_class_name , ‘-1’ as min_class_id , ‘-1’ as min_class_name , ‘trade_area’ as group_type, — ———————以下为指标统计操作——————————- — coalesce:(字段1,字段2….): 用于返回第一个不为null的值 sum(coalesce(order_amount,0)) as sale_amt, sum(coalesce(plat_fee,0)) as plat_amt, — 平台收入 sum(coalesce(delivery_fee,0)) as deliver_sale_amt, — 配送成交额 sum( if( order_from = ‘miniapp’, coalesce(order_amount,0), 0 ) ) as mini_app_sale_amt, — 小程序成交额
sum(
if(
order_from = 'android',
coalesce(order_amount,0),
0
)
) as android_sale_amt, -- Android成交额
sum(
if(
order_from = 'ios',
coalesce(order_amount,0),
0
)
) as ios_sale_amt, -- IOS成交额
sum(
if(
order_from = 'pcweb',
coalesce(order_amount,0),
0
)
) as pcweb_sale_amt, -- pc商城成交额
count(order_id) as order_cnt , -- 成交单量
-- 参评单量: 订单被评价了, 就说明这个订单属于参评订单了, 需要进行统计
count(
if(
evaluation_id is not null ,
order_id,
NULL
)
) as eva_order_cnt, -- 参评单量
-- 差评单量: 必须评价, 而且呢, 评价分数比较低
count(
if(
evaluation_id is not null and geval_scores is not null and geval_scores <=6,
order_id,
NULL
)
) as bad_eva_order_cnt,
-- 配送成交单量: 订单必须是已经被配送的, 如果配送,属于配送单
count(
if(
delievery_id is not null,
order_id,
null
)
) as deliver_order_cnt, -- 配送成交单量
-- 退款单量: 如果说退款ID存在, 说明订单一定是退款单
count(
if(
refund_id is not null,
order_id,
null
)
) as refund_order_cnt,
count(
if(
order_from = 'miniapp',
order_id,
NULL
)
) as mini_app_order_cnt, -- 小程序订单量
count(
if(
order_from = 'android',
order_id,
NULL
)
) as android_order_cnt, -- Android订单量
count(
if(
order_from = 'ios',
order_id,
NULL
)
) as ios_order_cnt, -- IOS订单量
count(
if(
order_from = 'pcweb',
order_id,
NULL
)
) as pcweb_order_cnt, -- pc商城订单量
dt
from t1 where rn = 1 group by dt, province_id,province_name,city_id,city_name,trade_area_id,trade_area_name;
- 日期 + 品牌 : (需求思考, 处理逻辑是不一样的, 因为 一个订单中可以有多个品牌, 一个品牌可以有多个订单)
- 目前订单明细宽表存在问题: 一个子订单中 可能存在重复的数据信息
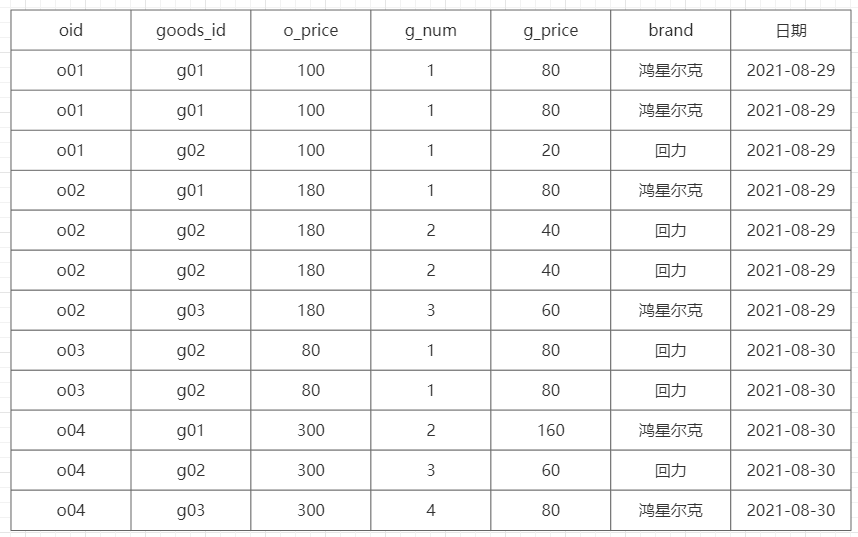<br />流程分析处理:<br />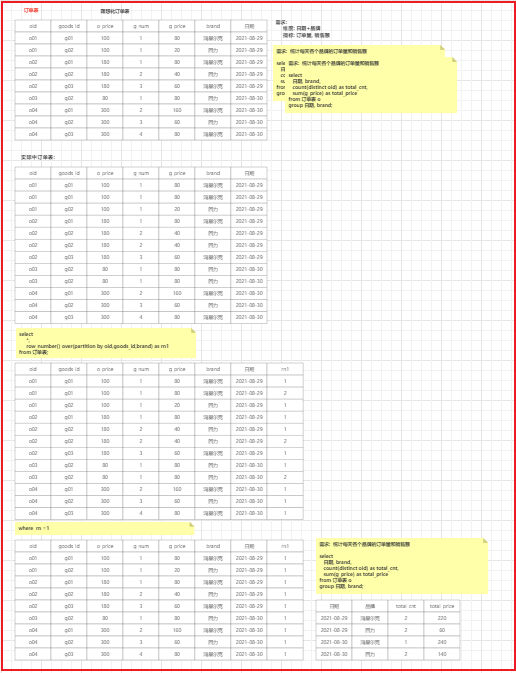
```sql
订单和品牌之间的关系: 一个订单下, 可以多个品牌的数据, 一个品牌也可以有多个订单数据, 之间的关系为 多对多
-- 开启动态分区支持:
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=10000;
set hive.exec.max.dynamic.partitions=100000;
set hive.exec.max.created.files=150000;
-- hive压缩
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
-- 写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
-- map join 优化操作
set hive.auto.convert.join=true;
set hive.auto.convert.join.noconditionaltask.size=20971520;
-- group by 数据倾斜的优化
set hive.map.aggr=true; -- 方案一
set hive.groupby.skewindata=false; -- 方案二
-- 第一步: 先去重操作
with t1 as (
select
--维度字段:
o.dt,
s.province_id,
s.province_name,
s.city_id,
s.city_name,
s.trade_area_id,
s.trade_area_name,
g.brand_id,
g.brand_name,
-- 指标字段
o.order_id , -- 订单ID, 计算订单量相关指标
o.order_amount, -- 订单额, 计算订单销售收入相关指标
o.plat_fee, -- 平台分润
o.delivery_fee, -- 配送费用
o.total_price, -- 商品的价格, 在计算 基于品牌 大类 中类 小类
-- 判断字段,
o.order_from, -- 渠道类型
o.evaluation_id, -- 评价ID, 用于判断是否参评
o.geval_scores, -- 综合评分
o.delievery_id, -- 配送ID, 用于判断是否配送
o.refund_id, -- 退款ID, 用于判断是否退款单
-- 去重操作处理逻辑:
row_number() over(partition by o.order_id) as rn, -- 计算 日期, 日期+城市 , 日期+城市+商圈, 日期+城市+商圈+店铺
row_number() over(partition by o.order_id, o.goods_id,g.brand_id) as rn1 -- 日期+品牌
from bj59_yp_dwb_jiale.dwb_order_detail o
left join bj59_yp_dwb_jiale.dwb_shop_detail s on o.store_id = s.id
left join bj59_yp_dwb_jiale.dwb_goods_detail g on o.goods_id = g.id
-- 确保订单是支付状态
where o.is_pay = 1 and o.order_state not in(1,7)
)
insert into table bj59_yp_dws_jiale.dws_sale_daycount partition(dt)
select
-- 书写维度信息字段:
'-1' as province_id,
'-1' as province_name,
'-1' as city_id,
'-1' as city_name,
'-1' as trade_area_id,
'-1' as trade_area_name ,
'-1' as store_id ,
'-1' as store_name ,
brand_id ,
brand_name ,
'-1' as max_class_id ,
'-1' as max_class_name ,
'-1' as mid_class_id ,
'-1' as mid_class_name ,
'-1' as min_class_id ,
'-1' as min_class_name ,
'brand' as group_type,
-- 指标计算操作
sum(coalesce(total_price,0)) as sale_amt, -- 销售收入
null as plat_amt, -- 平台收入(无法计算,因为都是基于订单, 而不是基于品牌)
null as deliver_sale_amt, -- 配送成交额(无法计算,因为都是基于订单, 而不是基于品牌)
sum(
if(
order_from = 'miniapp',
coalesce(total_price,0),
0
)
) as mini_app_sale_amt, -- 小程序成交额
sum(
if(
order_from = 'android',
coalesce(total_price,0),
0
)
) as android_sale_amt, -- Android成交额
sum(
if(
order_from = 'ios',
coalesce(total_price,0),
0
)
) as ios_sale_amt, -- IOS成交额
sum(
if(
order_from = 'pcweb',
coalesce(total_price,0),
0
)
) as pcweb_sale_amt, -- pc商城成交额
count(distinct order_id) as order_cnt , -- 成交单量
-- 参评单量: 订单被评价了, 就说明这个订单属于参评订单了, 需要进行统计
count( distinct
if(
evaluation_id is not null ,
order_id,
NULL
)
) as eva_order_cnt, -- 参评单量
-- 差评单量: 必须评价, 而且呢, 评价分数比较低
count( distinct
if(
evaluation_id is not null and geval_scores is not null and geval_scores <=6,
order_id,
NULL
)
) as bad_eva_order_cnt,
-- 配送成交单量: 订单必须是已经被配送的, 如果配送,属于配送单
count( distinct
if(
delievery_id is not null,
order_id,
null
)
) as deliver_order_cnt, -- 配送成交单量
-- 退款单量: 如果说退款ID存在, 说明订单一定是退款单
count( distinct
if(
refund_id is not null,
order_id,
null
)
) as refund_order_cnt,
count( distinct
if(
order_from = 'miniapp',
order_id,
NULL
)
) as mini_app_order_cnt, -- 小程序订单量
count( distinct
if(
order_from = 'android',
order_id,
NULL
)
) as android_order_cnt, -- Android订单量
count( distinct
if(
order_from = 'ios',
order_id,
NULL
)
) as ios_order_cnt, -- IOS订单量
count( distinct
if(
order_from = 'pcweb',
order_id,
NULL
)
) as pcweb_order_cnt, -- pc商城订单量
dt
from t1 where rn1 = 1
group by dt,brand_id,brand_name;
1.2 HIVE其他优化点
1- 关联优化器: 如果多个MR之间的操作的数据都是一样的, 同样shuffle操作也是一样的, 此时可以共享shuffle (建议常开)
一个SQL语句最终翻译为MR, 请问, 有没有可能出现翻译为多个MR的情况呢? 非常有可能的 每一个MR的中间都有可能会执行shuffle的操作, 而 shuffle其实比较消耗资源操作(内部存在多次IO操作) 开启关联优化器后, 如果多个MR中shuffle是一致的, 此时可以共享shuffle, 减少shuffle次数, 从而提升效率 配置项: set hive.optimize.correlation=true;2- HIVE并行执行 ```sql 2.1 并行编译: hive.driver.parallel.compilation 是否开启并行编译 hive.driver.parallel.compilation.global.limit 设置最大同时编译多少个会话的SQL
如果设置为0/负值, 表示无限制注意: 以上两个参数, 建议是直接在CM中开启, 并配置好即可
说明:
默认情况下, 如果HIVE有多个会话窗口, 而且多个窗口都在提交SQL , 此时HIVE默认只能对一个会话SQL进行编译, 其他会话的SQL需要等待, 这样的效率比较低
2.2 并行执行: 一个SQL语句在提交到HIVE之后, SQL有可能会被翻译为多个阶段, 在这个过程中, 有可能出现多个阶段互补干扰的情况, 这个时候, 可以安排多个阶段并行执行操作, 以此来提升效率 如何设置呢? 建议是在 会话中配置(压根无法在CM中配置) set hive.exec.parallel=true: 可以开启并发执行,默认为false。 set hive.exec.parallel.thread.number=16; 同一个sql允许的最大并行度,默认为8。
注意: 开启了此配置后, 并不代表所有SQL一定会并行的执行, 因为是否可以并行执行, 还取决于SQL中多个阶段之间是否有依赖, 只有在没有依赖的时候, 才可能并行执行(还有前提, 资源得够)
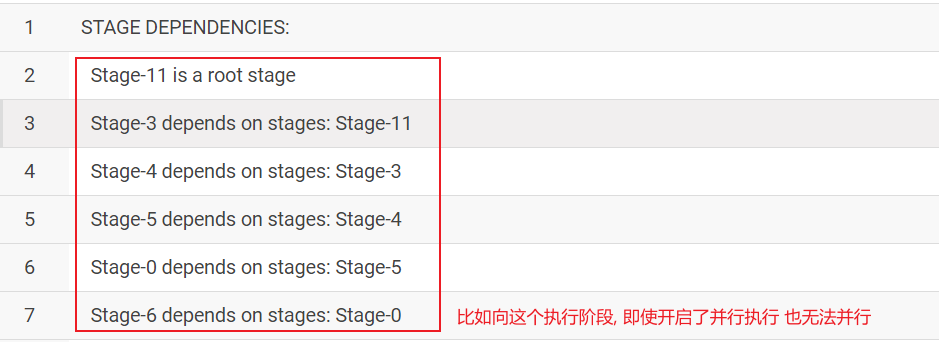
- 2.3 HIVE中小文件合并操作
```properties
HIVE: 在执行完成后, 输出的结果的文件尽量的少一些, 避免出现一些小文件过多问题, 此时可以通过设置让SQL在执行的时候输出的文件尽可能少
hive.merge.mapfiles : 是否开启map端的小文件合并的操作 (指的MR程序只有map 没有reduce的操作)
hive.merge.mapredfiles : 是否开启reduce端的小文件合并的操作
hive.merge.size.per.task : 设置文件的大小(合并后的文件的最大值,默认为: 256M)
hive.merge.smallfiles.avgsize : 当输出文件的平均大小小于此设置值时候, 启动一个独立的MR任务进行文件合并操作, 默认值为 16M
说明: 以上参数配置, 直接在CM上进行配置即可
例如:
比如一个MR输出 10个文件
1M 10M 50M 2M 3M 30M 10M 5M 6M 20M
请问, 是否会进行文件合并操作吗?
取决于hive.merge.smallfiles.avgsize值, 默认为16M, 意味输出的多个文件平均大小小于等于16M的时候, 就会触发合并
计算后, 平均大小为 13.7M 那么就会触发合并操作
思考: 是将所有的文件合并为一个文件吗? 还是怎么处理呢?
取决于 hive.merge.size.per.task 参数设置, 如果这个参数设置为 128M, 意味着合并文件最大为128M
128M , 9M
- 2.4 矢量化查询(批量化) ```properties 配置: 建议会话中常开 set hive.vectorized.execution.enabled=true; set hive.vectorized.execution.reduce.enabled = true;
说明:
一旦开启了矢量化查询的操作后, HIVE执行引擎在读取数据的时候, 就会采用批量化读取工作, 一次性读取 多条数据进行统一的处理操作, 从而减少读取的次数(减少磁盘IO次数), 从而提升效率
注意: 要求表的存储格式必须为ORC
- 2.5 读取零拷贝
```properties
在读取数据时候, 能少读一些, 尽量少读一些(没用的数据尽量不读)
配置: 建议在会话中常开
set hive.exec.orc.zerocopy=true;
注意: 表的存储格式必须为ORC
例如:
假设有一个A表, 表中 a b c三个字段
select a,b from A where a ='xxx'; c字段在整个SQL中都没有使用, 在读取数据时候, 我们就不读取c列数据
2- Presto相关内容
2.1 Presto 基本介绍
Presto是一个大数据旗下的分布式SQL查询引擎, Presto可以独立提供计算分析操作, 不需要依赖于其他的计算引擎, 而HIVE仅仅是一个工具, 最终计算是依赖于MR或者其他的执行引擎
Presto可以对接多种数据源, 可以从不同的数据源中读取数据进行分析处理, 一条presto查询可以将多个数据源进行合并, 可以跨越多个不同的组织进行分析
Presto是完全基于内存的计算引擎, 这也导致Presto不能对海量大量的数据进行统计分析操作, 数据集一般 在 GB ~ PB左右(集群数量越多, 资源越多, 可以计算的数据量越高)
性能对比图表: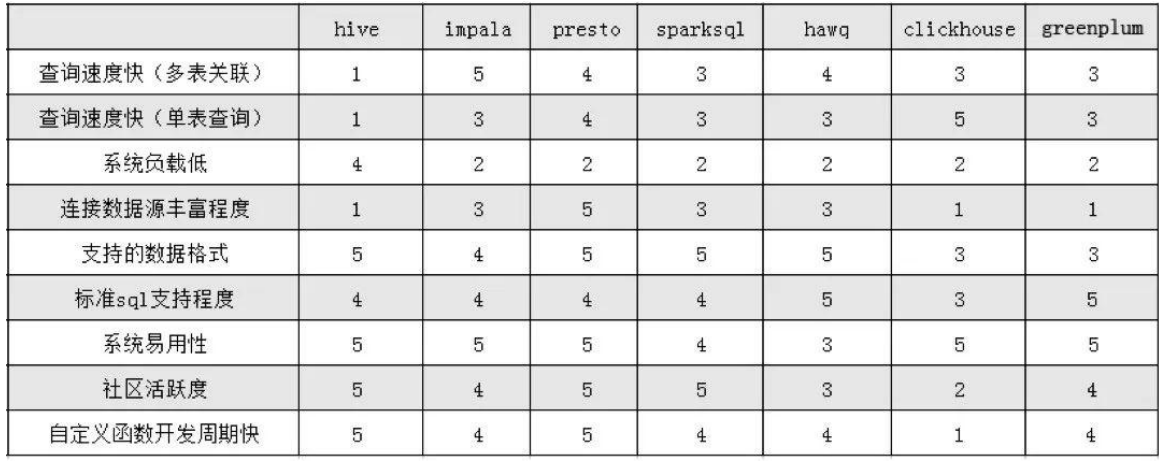
应用场景:
1) 适用于对数据源统一查询 (多数据源场景)
2) 适用于 GB TB 快速的数据查询操作, 数据量越大, 资源占用越高
不适用场景:
1) 多张数据量比较大的表Join操作
2) 不适合进行清洗 转换 维度退化的相关操作, 主要应用在数据分析上
2.2 Presto的集群安装操作
参考 <
2.3 使用DBeaver连接Presto
演示连接云平台的presto:
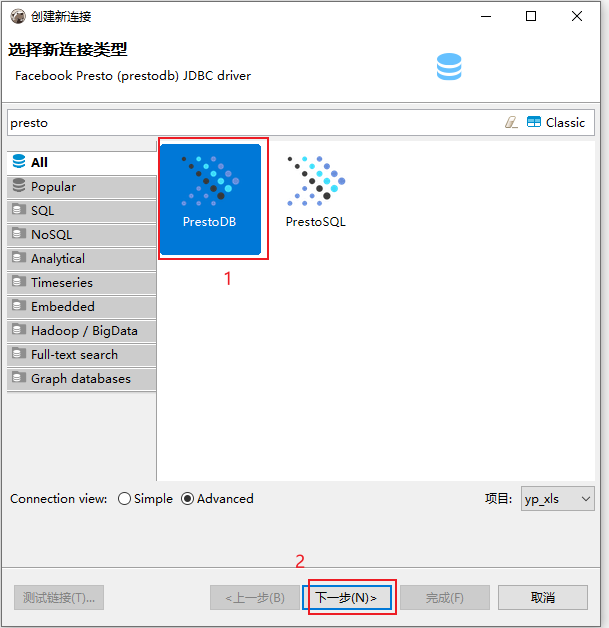
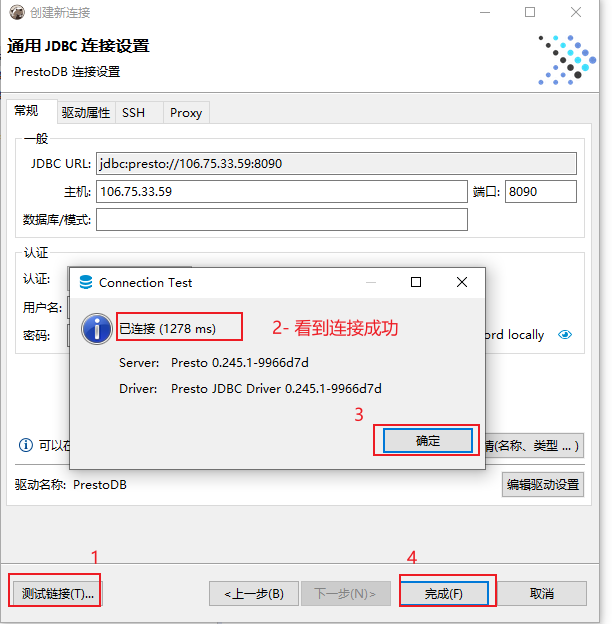
此处连接云端环境, 如果连接本地, 将ip地址更改为 192.168.88.80 即可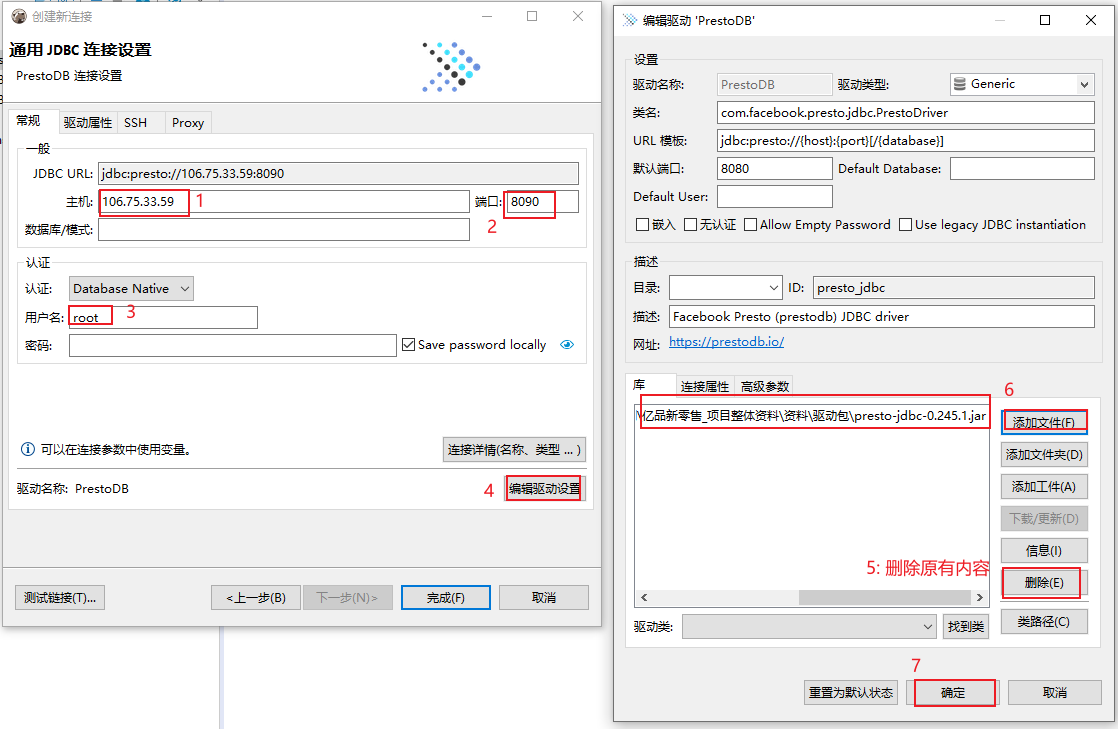
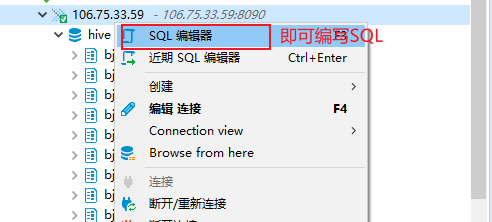

若有收获,就点个赞吧
0 人点赞
