day04_新零售课程笔记
今日内容:
-- 店铺表DROP TABLE if exists yp_ods.t_store;CREATE TABLE yp_ods.t_store (`id` string COMMENT '主键',`user_id` string,`store_avatar` string COMMENT '店铺头像',`address_info` string COMMENT '店铺详细地址',`name` string COMMENT '店铺名称',`store_phone` string COMMENT '联系电话',`province_id` INT COMMENT '店铺所在省份ID',`city_id` INT COMMENT '店铺所在城市ID',`area_id` INT COMMENT '店铺所在县ID',`mb_title_img` string COMMENT '手机店铺 页头背景图',`store_description` string COMMENT '店铺描述',`notice` string COMMENT '店铺公告',`is_pay_bond` TINYINT COMMENT '是否有交过保证金 1:是0:否',`trade_area_id` string COMMENT '归属商圈ID',`delivery_method` TINYINT COMMENT '配送方式 1 :自提 ;3 :自提加配送均可; 2 : 商家配送',`origin_price` DECIMAL,`free_price` DECIMAL,`store_type` INT COMMENT '店铺类型 22天街网店 23实体店 24直营店铺 33会员专区店',`store_label` string COMMENT '店铺logo',`search_key` string COMMENT '店铺搜索关键字',`end_time` string COMMENT '营业结束时间',`start_time` string COMMENT '营业开始时间',`operating_status` TINYINT COMMENT '营业状态 0 :未营业 ;1 :正在营业',`create_user` string,`create_time` string,`update_user` string,`update_time` string,`is_valid` TINYINT COMMENT '0关闭,1开启,3店铺申请中',`state` string COMMENT '可使用的支付类型:MONEY金钱支付;CASHCOUPON现金券支付',`idCard` string COMMENT '身份证',`deposit_amount` DECIMAL(11,2) COMMENT '商圈认购费用总额',`delivery_config_id` string COMMENT '配送配置表关联ID',`aip_user_id` string COMMENT '通联支付标识ID',`search_name` string COMMENT '模糊搜索名称字段:名称_+真实名称',`automatic_order` TINYINT COMMENT '是否开启自动接单功能 1:是 0 :否',`is_primary` TINYINT COMMENT '是否是总店 1: 是 2: 不是',`parent_store_id` string COMMENT '父级店铺的id,只有当is_primary类型为2时有效')comment '店铺表'partitioned by (dt string)row format delimited fields terminated by '\t' stored as orc tblproperties ('orc.compress'='ZLIB');
导入数据:
/usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \--connect 'jdbc:mysql://192.168.88.80:3306/yipin?enabledTLSProtocols=TLSv1.2&useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \--username root \--password 123456 \--query "select *, '2022-04-26' as dt from t_store where 1=1 and \$CONDITIONS" \--hcatalog-database yp_ods \--hcatalog-table t_store \-m 1
1. ODS层增量数据采集操作
1.1 模拟一份增量数据操作
此操作在实际生产环境中是不存在的, 因为 实际生产环境中, 本身每天就是有增量数据
-- 日期表(全量覆盖的方式):-- 新增一条数据INSERT INTO yipin.`t_date` VALUES ('20310101','2031-01-01','20301201','2031','2031年','01','01月','1','Q1','203101','52','203052','01','203101','3','星期三','01','01','4','3','01','001','20301225','20301201','10000000','20300101','20310101','20310131','1','上半年','S04','冬季','否','H01','元旦','F01','元旦','','','2021-12-20 14:20:57.401');-- 订单评价表(仅新增同步):INSERT INTO yipin.`t_goods_evaluation` VALUES ('10001','430eff5a55d911e998ec7cd30ad32e2e','7b09b44e5b6d11e998ec7cd30ad32e2e','dd190411306814f41f',10,10,10,1,'430eff5a55d911e998ec7cd30ad32e2e','2022-04-27 09:42:02',NULL,NULL,1);-- 店铺表(新增及更新同步):update yipin.`t_store` set name='北京传智教育科技股份有限公司' , update_time = '2022-04-27 05:50:55' where id = '0afb5daf777d11e998ec7cd30ad32e2e';INSERT INTO yipin.`t_store` VALUES ('10010','02554155777c11e998ec7cd30ad32e2e',NULL,NULL,'黑马程序员',NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,'0af148be777d11e998ec7cd30ad32e2e',NULL,NULL,NULL,24,NULL,NULL,'22:00','08:00',0,'02554155777c11e998ec7cd30ad32e2e','2022-04-27 05:50:55',NULL,NULL,3,'MONEY',NULL,NULL,'0afaf8ad777d11e998ec7cd30ad32e2e',NULL,'名称_**亿隆电子科技开发有限公司',0,1,NULL);
1.2 完成增量数据采集操作
- 1- 思考: 如何从这些表中获取到需要增量更新的数据呢?
- 全量覆盖的表操作: 日期表 ```sql — 日期表(全量覆盖): 如果更新的频次以天基准, 对于全量覆盖的表来说, 每天都是将之前的所有的数据全部都删除, 然后重新导入即可 — 思考: 是否可以通过sqoop直接进行全量覆盖呢? 表的存储格式为ORC , 导入数据需要使用hcatalog方式, hcatalog是否支持覆盖导入呢? 不行的, 仅支持追加
— 如何解决呢? 先将表清空了, 然后执行导入操作
— 对于 hive的表, 是无法对数据直接进行处理, 也就是无法修改数据, 或者删除数据, 一般建议将表先删除, 然后重新建表即可
drop table if exists yp_ods.t_date; CREATE TABLE if not exists yp_ods.t_date ( dim_date_id string COMMENT ‘日期’, date_code string COMMENT ‘日期编码’, lunar_calendar string COMMENT ‘农历’, year_code string COMMENT ‘年code’, year_name string COMMENT ‘年名称’, month_code string COMMENT ‘月份编码’, month_name string COMMENT ‘月份名称’, quanter_code string COMMENT ‘季度编码’, quanter_name string COMMENT ‘季度名称’, year_month string COMMENT ‘年月’, year_week_code string COMMENT ‘一年中第几周’, year_week_name string COMMENT ‘一年中第几周名称’, year_week_code_cn string COMMENT ‘一年中第几周(中国)’, year_week_name_cn string COMMENT ‘一年中第几周名称(中国’, week_day_code string COMMENT ‘周几code’, week_day_name string COMMENT ‘周几名称’, day_week string COMMENT ‘周’, day_week_cn string COMMENT ‘周(中国)’, day_week_num string COMMENT ‘一周第几天’, day_week_num_cn string COMMENT ‘一周第几天(中国)’, day_month_num string COMMENT ‘一月第几天’, day_year_num string COMMENT ‘一年第几天’, date_id_wow string COMMENT ‘与本周环比的上周日期’, date_id_mom string COMMENT ‘与本月环比的上月日期’, date_id_wyw string COMMENT ‘与本周同比的上年日期’, date_id_mym string COMMENT ‘与本月同比的上年日期’, first_date_id_month string COMMENT ‘本月第一天日期’, last_date_id_month string COMMENT ‘本月最后一天日期’, half_year_code string COMMENT ‘半年code’, half_year_name string COMMENT ‘半年名称’, season_code string COMMENT ‘季节编码’, season_name string COMMENT ‘季节名称’, is_weekend string COMMENT ‘是否周末(周六和周日)’, official_holiday_code string COMMENT ‘法定节假日编码’, official_holiday_name string COMMENT ‘法定节假日’, festival_code string COMMENT ‘节日编码’, festival_name string COMMENT ‘节日’, custom_festival_code string COMMENT ‘自定义节日编码’, custom_festival_name string COMMENT ‘自定义节日’, update_time string COMMENT ‘更新时间’ ) COMMENT ‘时间维度表’ row format delimited fields terminated by ‘\t’ stored as orc tblproperties (‘orc.compress’ = ‘ZLIB’);
— 基于 sqoop 完成 全量的数据采集操作: sqoop import \ —connect jdbc:mysql://hadoop01:3306/yipin \ —username root \ —password 123456 \ —query ‘select * from t_date where 1 = 1 and $CONDITIONS’ \ —hcatalog-database ‘yp_ods’ \ —hcatalog-table ‘t_date’ \ —fields-terminated-by ‘\t’ \ -m 1
- 仅新增同步方式:```sql-- 订单评价表(仅新增同步): 表只有新增的操作, 没有更新的操作, 对于这种同步方式的表, 我们只需要每天将其新增的数据导入到对应的分区即可-- 如何获取上一天的新增数据呢?select *, '2022-04-27' as dt from yipin.`t_goods_evaluation` where create_time BETWEEN '2022-04-27 00:00:00' and '2022-04-27 23:59:59';-- 基于 sqoop完成导入:sqoop import \--connect jdbc:mysql://hadoop01:3306/yipin \--username root \--password 123456 \--query "select *, '2022-04-27' as dt from t_goods_evaluation where create_time BETWEEN '2022-04-27 00:00:00' and '2022-04-27 23:59:59' and \$CONDITIONS" \--hcatalog-database 'yp_ods' \--hcatalog-table 't_goods_evaluation' \--fields-terminated-by '\t' \-m 1
- 新增和更新的同步方式: ```sql — 店铺表(新增及更新同步): 每天进行增量数据同步的时候, 需要将上一天的新增的数据和更新的数据放置到对应的分区即可
— 思考: 如果获取到上一天的新增和更新的数据呢? select *, ‘2022-04-27’ as dt from yipin.t_store where create_time BETWEEN ‘2022-04-27 00:00:00’ and ‘2022-04-27 23:59:59’ OR update_time BETWEEN ‘2022-04-27 00:00:00’ and ‘2022-04-27 23:59:59’;
— 基于 sqoop完成数据导入操作
sqoop import \ —connect jdbc:mysql://hadoop01:3306/yipin \ —username root \ —password 123456 \ —query “select *, ‘2022-04-27’ as dt from t_store where create_time BETWEEN ‘2022-04-27 00:00:00’ and ‘2022-04-27 23:59:59’ OR update_time BETWEEN ‘2022-04-27 00:00:00’ and ‘2022-04-27 23:59:59’ and \$CONDITIONS” \ —hcatalog-database ‘yp_ods’ \ —hcatalog-table ‘t_store’ \ —fields-terminated-by ‘\t’ \ -m 1
> 目前, 书写的这些sqoop的脚本, 是比较死板的, 原因: 当中日期本应该是一个变量, 随着时间的推移, 每天都应该自动指向上一天的日期数据, 但是目前都是写死了, 每天都需要手动的修改, 这种方式, 并不是我们想要的吧.....> 如何解决这个问题呢? 希望除了能够自动获取上一天的日期, 还能支持根据指定的日期导入相关的数据> 基于 SHELL脚本来实现, 后续将shell脚本通过oozie完成自动化调度操作```properties1- 思考: 在shell执行的时候, 是否支持读取到外部传递的参数? 完全支持的2- 如何通过shell读取上一天的日期呢?获取当前日期: date2022年 04月 28日 星期四 10:23:06 CST获取上一天: date -d '-1 day'2022年 04月 27日 星期三 10:24:05 CST获取上一个小时: date -d '-1 hour'2022年 04月 28日 星期四 09:24:39 CST获取上一周: date -d '-1 week'2022年 04月 21日 星期四 10:25:01 CST3- 如何让日期数据按照特定的格式输出呢? date -d '-1 day' +'%Y-%m-%d %H:%M:%S'2022-04-27 10:27:344- 如果外部传递了参数, shell内部如何接收呢?$# : 获取当前外部一共传递了多少个参数$N : N 表示数据, 获取第一个参数5- 在编写一个shell脚本, 默认第一行书写 #!/bin/bash 用于标识这个是shell脚本, 采用bash解释器运行一个shell脚本方式: sh 脚本单独一个# 表示是注释关键词: wait 表示串行执行(默认就是)6- 如果外部传递了参数, 按照指定的参数日期进行数据采集, 如果没有传递, 使用上一天的日期即可#!/bin/bash# 注意: [] 内部两端都要有空格if [ $# == 1 ]then# 等号两端不允许出现空格dateStr=$1else# 飘号(`)(esc下面的那个键): 表示内部内容, 会先执行dateStr=`date -d '-1 day' +'%Y-%m-%d'`fi# ${变量} : 用于获取变量的值echo ${dateStr}# 在shell中 在双引号里面是支持 特殊符号操作 , 如果是单引号, 表示原样输出7- 如何在shell脚本中, 执行hive的SQL呢?hive -e -S 'SQL语句'-S: 表示静默执行, 避免输出太多的日志数据
编写shell脚本, 完成增量脚本实现:
1- 在hadoop01的家目录下执行操作:cd ~vim yp_ods_incr.sh输入 i 进入编辑模式:添加以下内容:#!/bin/bash# 1- env pathHIVE_HOME=/usr/bin/hive# 2- Tranif [ $# == 1 ]thendateStr=$1elsedateStr=`date -d '-1 day' +'%Y-%m-%d'`fiecho ${dateStr}# 3- HIVE delete tableecho '---------------HIVE DELETE START---------------'${HIVE_HOME} -S -e "drop table if exists yp_ods.t_date;CREATE TABLE if not exists yp_ods.t_date (dim_date_id string COMMENT '日期',date_code string COMMENT '日期编码',lunar_calendar string COMMENT '农历',year_code string COMMENT '年code',year_name string COMMENT '年名称',month_code string COMMENT '月份编码',month_name string COMMENT '月份名称',quanter_code string COMMENT '季度编码',quanter_name string COMMENT '季度名称',year_month string COMMENT '年月',year_week_code string COMMENT '一年中第几周',year_week_name string COMMENT '一年中第几周名称',year_week_code_cn string COMMENT '一年中第几周(中国)',year_week_name_cn string COMMENT '一年中第几周名称(中国',week_day_code string COMMENT '周几code',week_day_name string COMMENT '周几名称',day_week string COMMENT '周',day_week_cn string COMMENT '周(中国)',day_week_num string COMMENT '一周第几天',day_week_num_cn string COMMENT '一周第几天(中国)',day_month_num string COMMENT '一月第几天',day_year_num string COMMENT '一年第几天',date_id_wow string COMMENT '与本周环比的上周日期',date_id_mom string COMMENT '与本月环比的上月日期',date_id_wyw string COMMENT '与本周同比的上年日期',date_id_mym string COMMENT '与本月同比的上年日期',first_date_id_month string COMMENT '本月第一天日期',last_date_id_month string COMMENT '本月最后一天日期',half_year_code string COMMENT '半年code',half_year_name string COMMENT '半年名称',season_code string COMMENT '季节编码',season_name string COMMENT '季节名称',is_weekend string COMMENT '是否周末(周六和周日)',official_holiday_code string COMMENT '法定节假日编码',official_holiday_name string COMMENT '法定节假日',festival_code string COMMENT '节日编码',festival_name string COMMENT '节日',custom_festival_code string COMMENT '自定义节日编码',custom_festival_name string COMMENT '自定义节日',update_time string COMMENT '更新时间')COMMENT '时间维度表'row format delimited fields terminated by '\t' stored as orc tblproperties ('orc.compress' = 'ZLIB');"echo '---------------HIVE DELETE SUCCESS---------------'# 4- SQOOP IMPORTecho '---------------SQOOP IMPORT START---------------'SQOOP_HOME=/usr/bin/sqoop# PUBLIC PATHurl='jdbc:mysql://hadoop01:3306/yipin'username='root'password='123456'${SQOOP_HOME} import \--connect ${url} \--username ${username} \--password ${password} \--query 'select * from t_date where 1 = 1 and $CONDITIONS' \--hcatalog-database 'yp_ods' \--hcatalog-table 't_date' \--fields-terminated-by '\t' \-m 1wait${SQOOP_HOME} import \--connect ${url} \--username ${username} \--password ${password} \--query "select *, '${dateStr}' as dt from t_goods_evaluation where create_time BETWEEN '${dateStr} 00:00:00' and '${dateStr} 23:59:59' and \$CONDITIONS" \--hcatalog-database 'yp_ods' \--hcatalog-table 't_goods_evaluation' \--fields-terminated-by '\t' \-m 1wait${SQOOP_HOME} import \--connect ${url} \--username ${username} \--password ${password} \--query "select *, '${dateStr}' as dt from t_store where create_time BETWEEN '${dateStr} 00:00:00' and '${dateStr} 23:59:59' OR update_time BETWEEN '${dateStr} 00:00:00' and '${dateStr} 23:59:59' and \$CONDITIONS" \--hcatalog-database 'yp_ods' \--hcatalog-table 't_store' \--fields-terminated-by '\t' \-m 1echo '---------------SQOOP IMPORT SUCCESS---------------'
执行shell脚本, 执行完成后, 进行校验操作:
- 全量覆盖表, 主要是校验所有的数据是否和数据源表是否一致 (可以看数据量, 以及映射的数据内容)
数据源: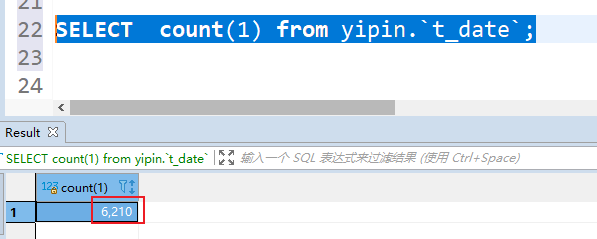
hive中对应表: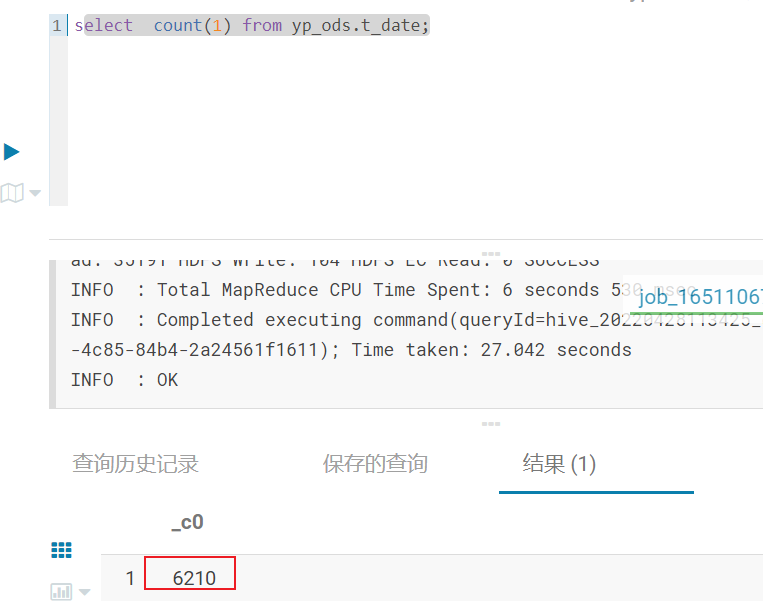
- 仅新增的表和 新增及更新表: 可以通过查看是否有这个分区的数据
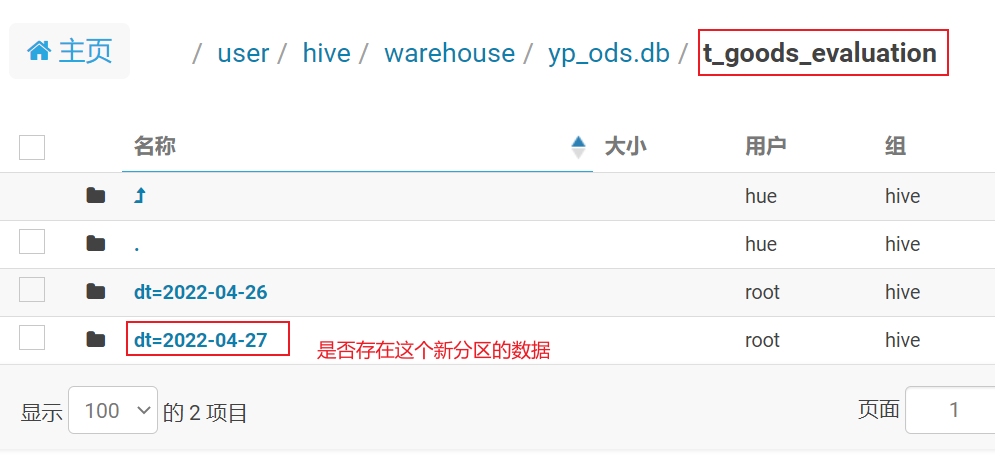
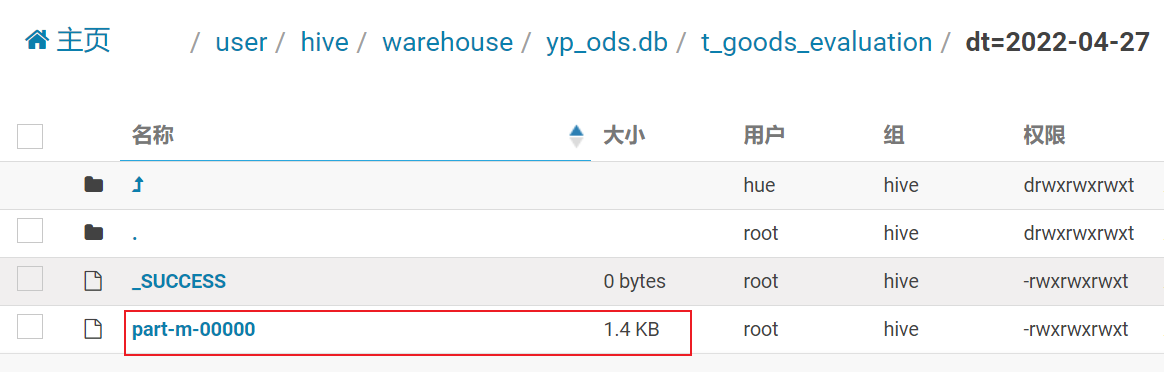
说明: 有可能是没有的, 比如说, 正好上一天没有任何的新增数据, 此时什么都没有
SQL校验: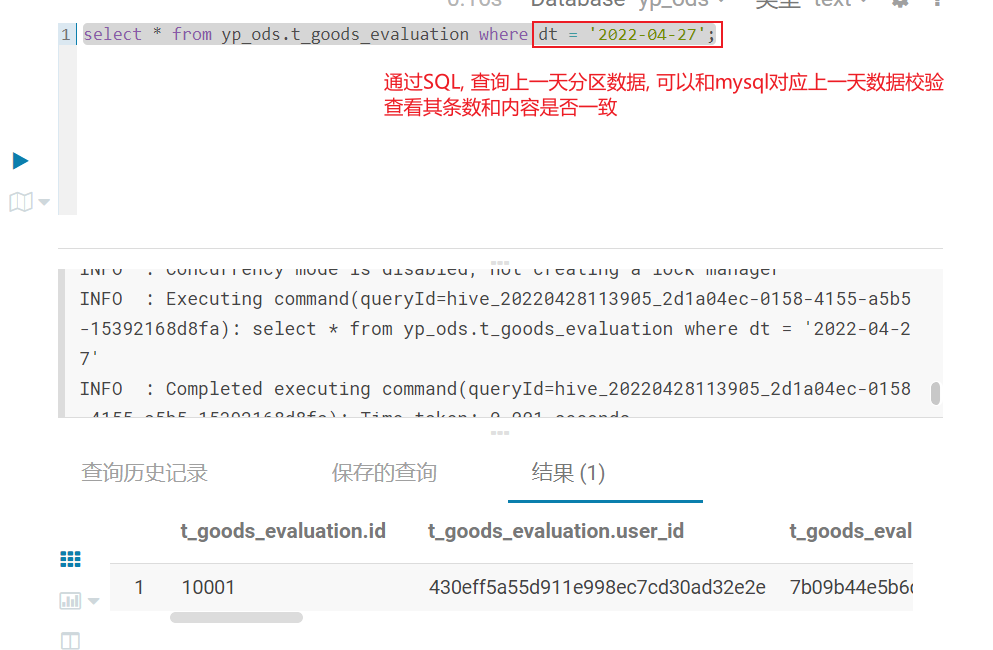
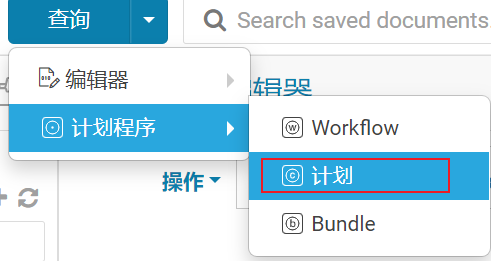
目前脚本确实写好了, 但是呢, 还是需要每天上去跑一下才可以, 而且这个执行操作, 必须是凌晨, 或者深夜执行(因为这个操作比较影响业务端资源), 显然不太合适, 此时需要让程序能够定时的周期性的运行操作, 所以需要使用oozie完成定时调度操作
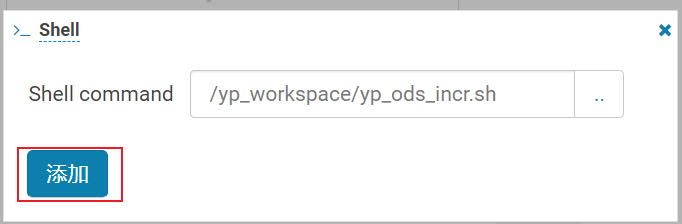
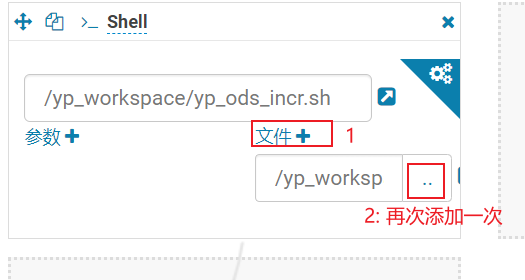
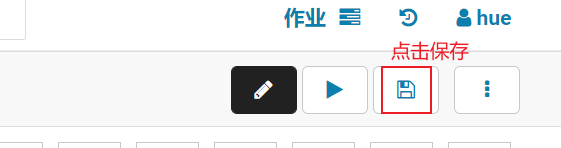
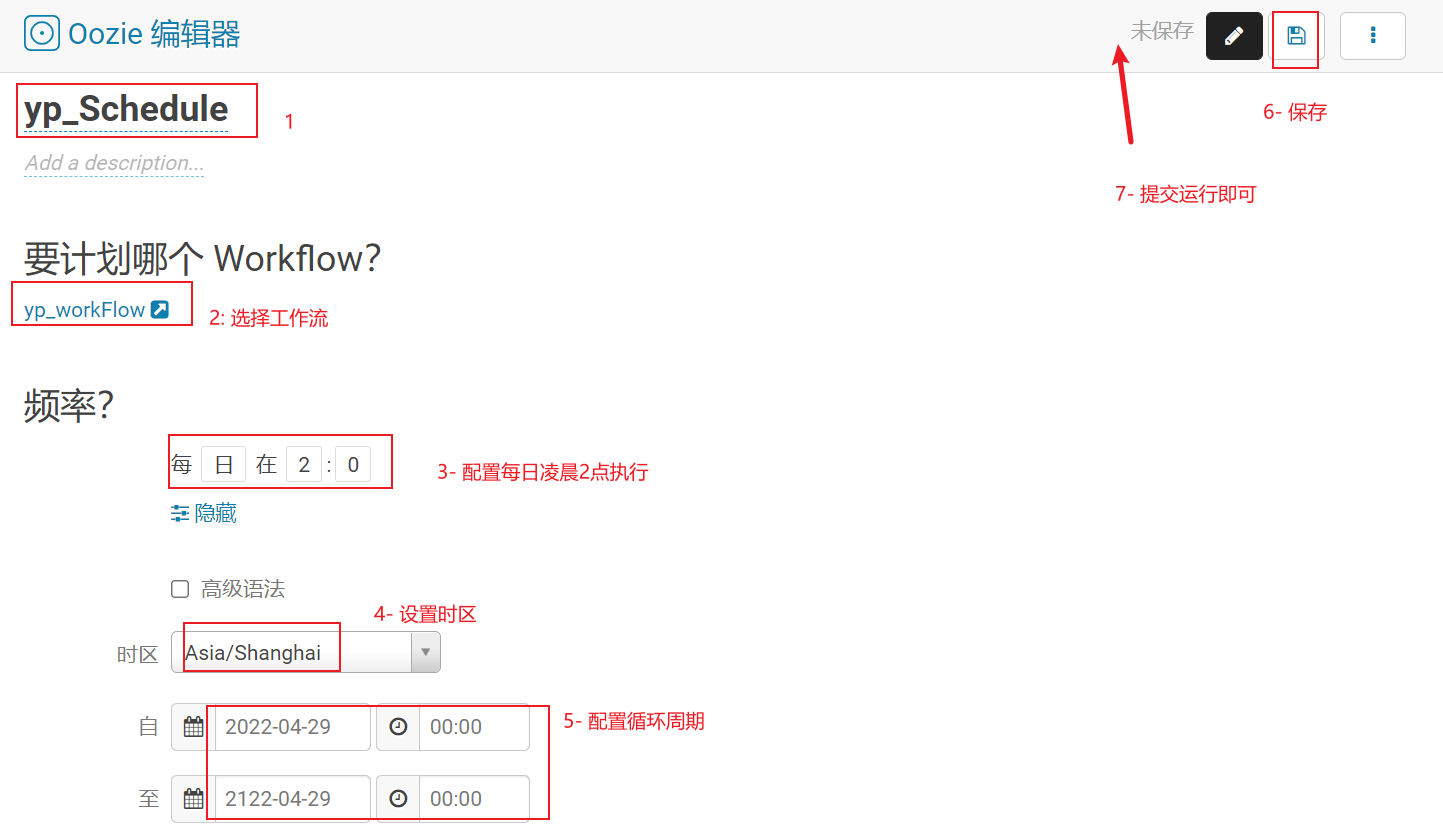
1- 配置工作流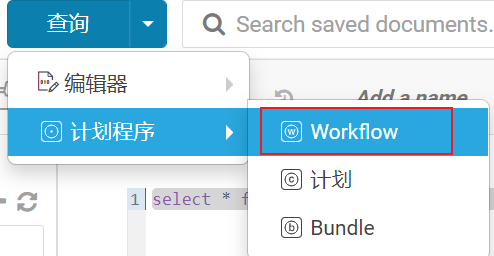
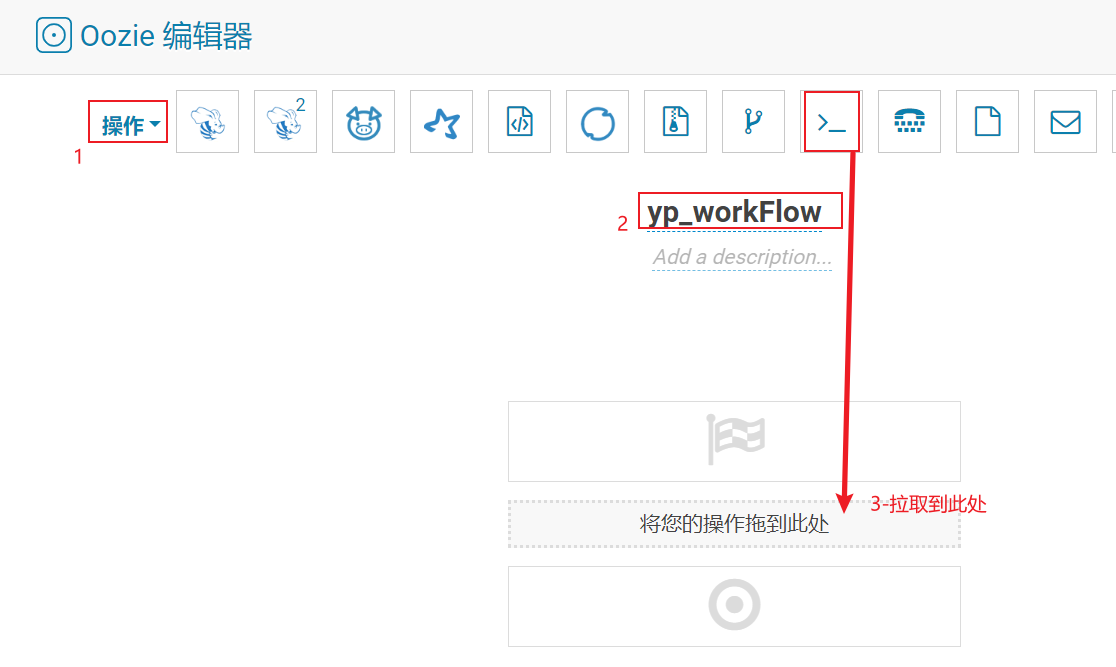
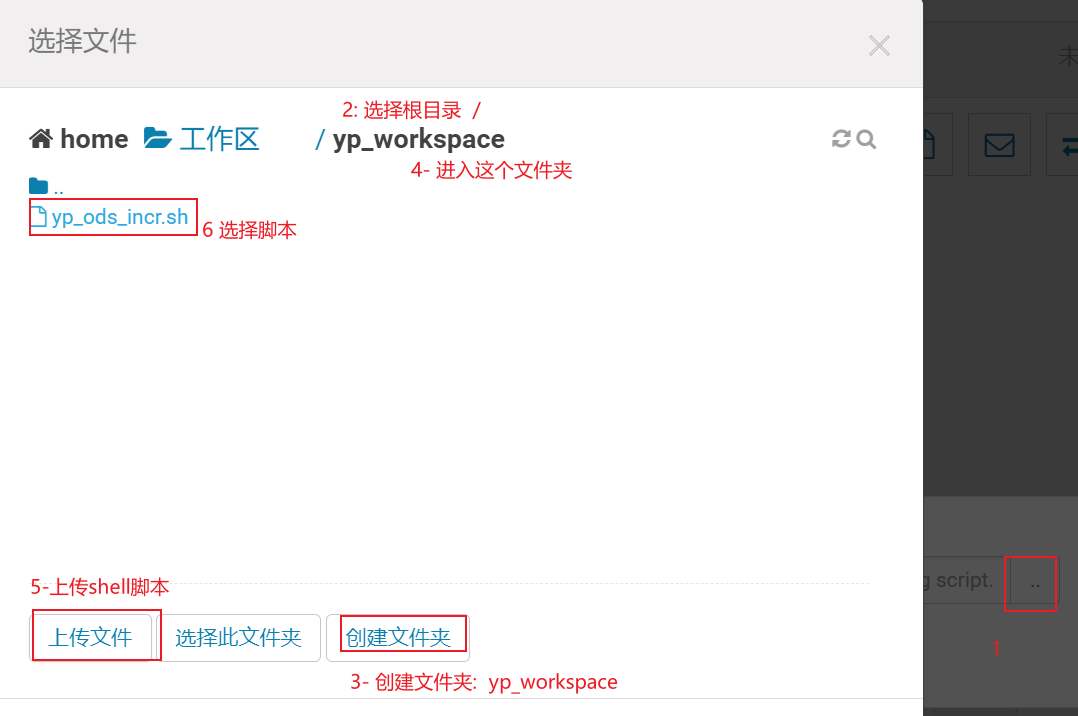
2. 分桶表相关内容
2.1 分桶表基本介绍
分桶表:
- 分文件的, 在创建表的时候, 指定分桶字段, 并设置分多少个桶, 在添加数据的时候, hive会根据设置分桶字段, 将数据划分到N个桶(文件)中, 默认情况采用HASH分桶方案 , 分多少个桶, 取决于建表的时候, 设置分桶数量, 分了多少个桶最终翻译的MR也就会运行多少个reduce程序(HIVE的分桶本质上就是MR的分区操作)
如何构建一个分桶表呢?
create table 表名(字段 类型,....)clustered by(分桶字段) [sorted by (字段 [asc | desc])] into N buckets --- 定义分桶表核心语句row format......
如何向桶表添加数据 ```properties 思考: 是否可以通过 load data 方式添加数据呢? 不行的 注意: 如果使用 apache 版本的HIVE, 默认情况下, 是可以通过 load data 方式来加载数据. 只不过没有分桶的效果
但是对于 CDH版本中, 是不允许通过 load data 方式来加载的: 在CDH中默认开启了一个参数, 禁止采用load data方式向桶表添加数据: set hive.strict.checks.bucketing = true;
如果 现有一个文本文件数据, 需要加载到分桶表,如何解决呢? 第一步: 基于桶表创建一张临时表, 此表和桶表保持相同字段, 唯一区别, 当前这个表不是一个桶表 第二步: 将数据先加载到这个临时表中 第三步: 基于临时表, 使用 insert into|overwrite + select 将数据添加到桶表
注意: sqoop不支持桶表数据导入操作
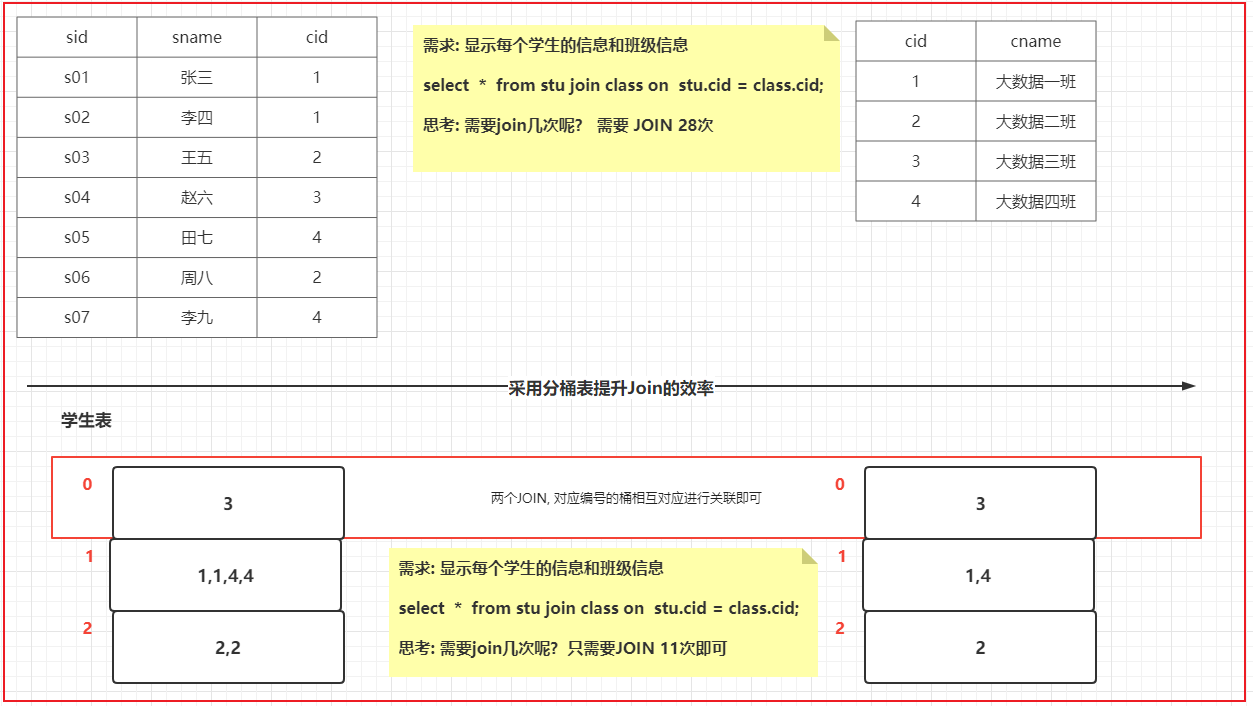
- 桶表有什么用呢?```properties1) 进行数据采样工作1.1) 当表的数据量比较庞大的时候, 在编写SQL语句后, 需要首先测试 SQL是否可以正常的执行, 需要在表中执行查询操作, 由于表数据量比较庞大, 在测试一条SQL的时候整个运行的时间比较久, 为了提升测试效率, 可以整个表抽样出一部分的数据, 进行测试1.2) 校验数据的可行性(质量校验)1.3) 进行统计分析的时候, 并不需要统计出具体的指标, 可能统计的都是一些相对性指标, 比如说一些比率(合格率)问题, 此时可以通过采样处理2) 提升查询的效率(更主要是提升JOIN的效率)可以减少JOIN次数, 从而提升效率注意:在生产环境中, 何时使用桶表, 主要看是否需要应用上述作用
2.2 数据采样
- 如何实现数据采样的工作 ```properties 采样函数: tablesample(bucket x out of y [on column])
使用位置: 紧紧跟在表名的后面, 如果表名有别名, 必须放置别名的前面
说明: x: 从第几个桶开始进行采样 y: 抽样比例 column: 分桶的字段, 可以省略
注意: x 不能大于 y y 必须是表的分桶数量的倍数或者因子
案例: 1) 假设 A表有10个桶, 请分析, 下面的采样函数, 会将那些桶抽取出来呢? tablesample(bucket 2 out of 5 on xxx)
会抽取出几个桶数据呢? 总桶数 / 抽样比例 = 分桶数量 2个桶抽取那几个桶呢? (x + y)2, 7
2) 假设 A 表有20个桶, 请分析, 下面的抽样函数, 会将那些桶抽取出来呢? tablesample(bucket 4 out of 4 on xxx)
会抽取出几个桶数据呢? 总桶数 / 抽样比例 = 分桶数量 5个桶抽取那几个桶呢?4 , 8,12,16,20tablesample(bucket 8 out of 40 on xxx)会抽取出几个桶数据呢? 总桶数 / 抽样比例 = 分桶数量 二分之一个桶抽取那几个桶呢?8号桶二分之一
大多数情况下, 都是因子, 取某几个桶的操作
<a name="5772be65"></a>### 2.3 执行计划用户提交HiveSQL查询后,Hive会把查询语句转换为MapReduce作业。Hive会自动完成整个执行过程,一般情况下,我们并不用知道内部是如何运行的。 <br /> 执行计划可以告诉我们查询过程的关键信息,**用来帮助我们判定优化措施是否已经生效**。<br />语法:```sqlEXPLAIN [EXTENDED] query简单来说:explain sql语句
- 类似的一个执行计划
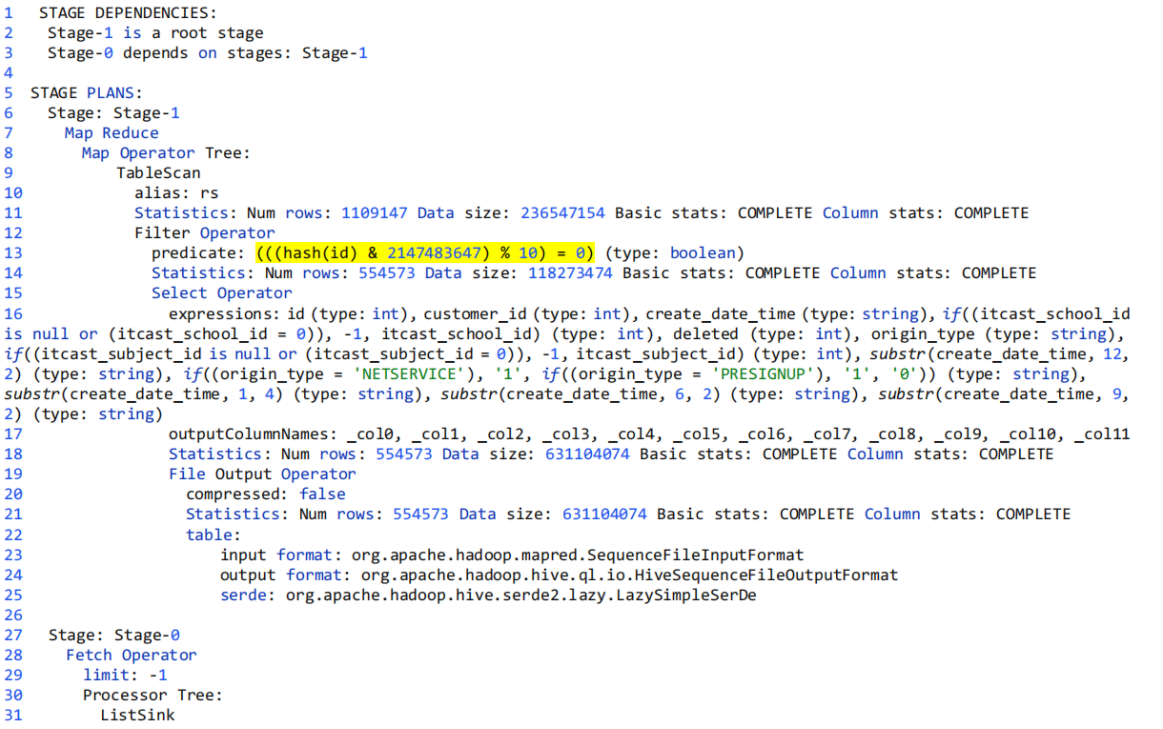
1. stage依赖(STAGE DEPENDENCIES)
(1) 这部分展示本次查询分为两个stage:Stage-1,Stage-0.
(2) 一般Stage-0是最终给查询用户展示数据用的,如LIMITE操作就会在这部分。
(3) Stage-1是mr程序的执行阶段。
1 STAGE DEPENDENCIES:
2 Stage-1 is a root stage
3 Stage-0 depends on stages: Stage-1
2. stage详细执行计划(STAGE PLANS)
(1) 包含了整个查询所有Stage的大部分处理过程。
(2) 特定优化是否生效,主要通过此部分内容查看。
3. 名次解释
TableScan:查看表
alias: emp:所需要的表
Statistics: Num rows: 2 Data size: 820 Basic stats: COMPLETE Column stats: NONE:这张表 的基本统计信息:行数、大小等;
expressions: empno (type: int), ename (type: string), job (type: string), mgr (type: int), hiredate (type: string), sal (type: double), comm (type: double), deptno (type: int):表中需要输出 的字段及类型
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7:输出的的字段编 号
compressed: true:输出是否压缩;
input format: org.apache.hadoop.mapred.SequenceFileInputFormat:文件输入调用的Java 类,显示以文本Text格式输入;
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat:文件输出调 用的java类,显示以文本Text格式输出;
3- 将ODS层某个表进行分桶重建演示
3.1 ODS层对订单表进行重建操作
-- 订单表
DROP TABLE if exists yp_ods.t_shop_order;
CREATE TABLE yp_ods.t_shop_order
(
id string COMMENT '根据一定规则生成的订单编号',
order_num string COMMENT '订单序号',
buyer_id string COMMENT '买家的userId',
store_id string COMMENT '店铺的id',
order_from TINYINT COMMENT '是来自于app还是小程序,或者pc 1.安卓; 2.ios; 3.小程序H5 ; 4.PC',
order_state INT COMMENT '订单状态:1.已下单; 2.已付款, 3. 已确认 ;4.配送; 5.已完成; 6.退款;7.已取消',
create_date string COMMENT '下单时间',
finnshed_time timestamp COMMENT '订单完成时间,当配送员点击确认送达时,进行更新订单完成时间,后期需要根据订单完成时间,进行自动收货以及自动评价',
is_settlement TINYINT COMMENT '是否结算;0.待结算订单; 1.已结算订单;',
is_delete TINYINT COMMENT '订单评价的状态:0.未删除; 1.已删除;(默认0)',
evaluation_state TINYINT COMMENT '订单评价的状态:0.未评价; 1.已评价;(默认0)',
way string COMMENT '取货方式:SELF自提;SHOP店铺负责配送',
is_stock_up INT COMMENT '是否需要备货 0:不需要 1:需要 2:平台确认备货 3:已完成备货 4平台已经将货物送至店铺 ',
create_user string,
create_time string,
update_user string,
update_time string,
is_valid TINYINT COMMENT '是否有效 0: false; 1: true; 订单是否有效的标志'
)
comment '订单表'
partitioned by (dt string)
clustered by(id) sorted by (id) into 5 buckets
row format delimited fields terminated by '\t'
stored as orc tblproperties ('orc.compress' = 'ZLIB');
3.2 将数据导入到ODS层
1- 创建一张订单表的临时表(一定不能是桶表)
CREATE TABLE yp_ods.t_shop_order_temp ( id string COMMENT '根据一定规则生成的订单编号', order_num string COMMENT '订单序号', buyer_id string COMMENT '买家的userId', store_id string COMMENT '店铺的id', order_from TINYINT COMMENT '是来自于app还是小程序,或者pc 1.安卓; 2.ios; 3.小程序H5 ; 4.PC', order_state INT COMMENT '订单状态:1.已下单; 2.已付款, 3. 已确认 ;4.配送; 5.已完成; 6.退款;7.已取消', create_date string COMMENT '下单时间', finnshed_time timestamp COMMENT '订单完成时间,当配送员点击确认送达时,进行更新订单完成时间,后期需要根据订单完成时间,进行自动收货以及自动评价', is_settlement TINYINT COMMENT '是否结算;0.待结算订单; 1.已结算订单;', is_delete TINYINT COMMENT '订单评价的状态:0.未删除; 1.已删除;(默认0)', evaluation_state TINYINT COMMENT '订单评价的状态:0.未评价; 1.已评价;(默认0)', way string COMMENT '取货方式:SELF自提;SHOP店铺负责配送', is_stock_up INT COMMENT '是否需要备货 0:不需要 1:需要 2:平台确认备货 3:已完成备货 4平台已经将货物送至店铺 ', create_user string, create_time string, update_user string, update_time string, is_valid TINYINT COMMENT '是否有效 0: false; 1: true; 订单是否有效的标志' ) comment '订单表' partitioned by (dt string) row format delimited fields terminated by '\t' stored as orc tblproperties ('orc.compress' = 'ZLIB');2- 通过sqoop将数据导入到临时表中
# 订单表 sqoop import \ --connect jdbc:mysql://hadoop01:3306/yipin \ --username root \ --password 123456 \ --query 'select *, "2022-04-26" as dt from t_shop_order where create_time <= "2022-04-26 23:59:59" OR update_time <= "2022-04-26 23:59:59" and $CONDITIONS' \ --hcatalog-database 'yp_ods' \ --hcatalog-table 't_shop_order_temp' \ --fields-terminated-by '\t' \ -m 13- 从临时表将数据灌入到桶表中 ```sql — 开启动态分区支持: SET hive.exec.dynamic.partition=true; — 开启动态分区支持, 默认为true SET hive.exec.dynamic.partition.mode=nonstrict; — 开启非严格模式 set hive.exec.max.dynamic.partitions.pernode=10000; — 最大一个节点能够生成多少个分区 set hive.exec.max.dynamic.partitions=100000; — 最大支持多少个动态分区 set hive.exec.max.created.files=150000; — 最多一次性可以创建多少个文件
— hive压缩 set hive.exec.compress.intermediate=true; — 中间结果的压缩 默认为true set hive.exec.compress.output=true;
— 写入时压缩生效 set hive.exec.orc.compression.strategy=COMPRESSION; —分桶 set hive.enforce.bucketing=true; — 开启桶表支持 (默认为true) set hive.enforce.sorting=true; — 开启分桶强制排序, 根据sort by 指定字段排序
insert overwrite table yp_ods.t_shop_order partition(dt) select
- from yp_ods.t_shop_order_temp;
注意: set 设置 仅在当前会话有效
演示: 采样操作, 比如说, 要采样第三个桶
```sql
explain
select
*
from yp_ods.t_shop_order tablesample(bucket 3 out of 5);
执行计划
# 描述 共计有二个阶段: stage -1 和 stage -0 其中 -0阶段依赖于 -1阶段, 先执行 -1阶段
1 STAGE DEPENDENCIES:
2 Stage-1 is a root stage
3 Stage-0 depends on stages: Stage-1
4
# 各个节点详细描述
5 STAGE PLANS:
6 Stage: Stage-1
7 Map Reduce
8 Map Operator Tree:
9 TableScan
# 读取 t_shop_order这个表
10 alias: t_shop_order
# 数量信息: 共有 3155条消息 总数据大小 4044436
11 Statistics: Num rows: 3155 Data size: 4044436 Basic stats: COMPLETE Column stats: PARTIAL
# 描述过滤信息
12 Filter Operator
# (((hash(id) & 2147483647) % 5) = 2) : 对 id 进行 hash取模 对 5取模 余数为 2 表示第三个桶
13 predicate: (((hash(id) & 2147483647) % 5) = 2) (type: boolean)
14 Statistics: Num rows: 1577 Data size: 290168 Basic stats: COMPLETE Column stats: PARTIAL
15 Select Operator
16 expressions: id (type: string), order_num (type: string), buyer_id (type: string), store_id (type: string), order_from (type: tinyint), order_state (type: int), create_date (type: string), finnshed_time (type: timestamp), is_settlement (type: tinyint), is_delete (type: tinyint), evaluation_state (type: tinyint), way (type: string), is_stock_up (type: int), create_user (type: string), create_time (type: string), update_user (type: string), update_time (type: string), is_valid (type: tinyint), dt (type: string)
17 outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7, _col8, _col9, _col10, _col11, _col12, _col13, _col14, _col15, _col16, _col17, _col18
18 Statistics: Num rows: 1577 Data size: 290168 Basic stats: COMPLETE Column stats: PARTIAL
19 File Output Operator
20 compressed: true
21 Statistics: Num rows: 1577 Data size: 290168 Basic stats: COMPLETE Column stats: PARTIAL
22 table:
23 input format: org.apache.hadoop.mapred.SequenceFileInputFormat
24 output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
25 serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
26
27 Stage: Stage-0
28 Fetch Operator
29 limit: -1
30 Processor Tree:
31 ListSink
4. DWD层相关操作
DWD层作用:
DWD层 和 ODS层保持相同粒度, 从ODS层将数据抽取出来, 对数据进行清洗转换的操作, 将清洗转换后的数据灌入到DWD层中
从DWD层开始, 将整体迁移到云环境来处理
云环境的HUE地址:
http://106.75.33.59:8888/hue/
用户名: bj_class59
密码: bj_class59
- 1- 构建DWD层的库 ```sql create database if not exists bj59_yp_dwd_jiale ;
库名格式要求(务必按照此格式构建): bj59yp_dwd姓名
说明: 关于在DWD层, 一般主要做那些清洗和转换的操作呢?
```properties
关于当前项目的DWD层构建:
1) 由于粒度是一致的, 所以DWD层表数量以及表的结构基本上ODS层是一致的
2) 在DWD层建表的时候, 将压缩方案 从原有zlib 更改为 snappy, 便于后续读取操作
3) 对于同步方式为新增及更新的表, 由于需要在DWD层中对历史数据进行拉链处理操作, 所以在DWD层进行建表的时候, 会新建两个字段: start_date(拉链开始时间) 和 end_date(拉链的结束时间) 其中 会将 start_date作为分区字段
一般在实际生产环境中 一般需要清洗转换那些操作呢?
1- 去除无用空值, 缺少值
2- 去重
3- 过滤掉一些以及标记为删除的数据
4- 发现一个字段中如果涵盖了多个字段信息, 一般需要将其转换为 多个字段来分别处理
比如说: 日期, ODS层中日期值可能为 2022-01-01 14:25:30 包含 年 月 日 小时 分钟 秒
可以将其拆解为 年字段, 月字段, 日字段, 小时字段, 季度字段...
5- 原有数据可能是通过数字来表示一种行为, 可能需要将其转换为具体的内容
比如说: 数据中用 1表示男性 0 表示女性 直接将其转换为 男 和 女
或者 将具体内容, 转换为数字
6- 维度退化操作, 将多个相关的表合并为一个表(此种一般需要JOIN大量的表来处理)
注意: 一般此操作会独立处理, 不会和清洗转换放置在一块, 除非非常简单
7- JSOIN数据的拉平操作:
比如说: 一个字段为 content字段, 字段里面数据格式 "{'name':'张三','address':'北京'}"
此时需要将其拉宽拉平, 形成两个新的字段: content_name , content_address
目前, 在我们项目中, 基本上不去处理任何的转换操作, 主要原因是因为当前这份数据, 本身就是一些测试数据, 里面将大量的敏感数据给脱敏了, 导致一旦进行清洗处理, 可能什么数据都不剩下了
4.1 完成各个表的构建操作
说明:
需要对表划分那些是事实表, 那些是维度表, 以及那些表需要进行拉链
- 事实表:

- 维度表

建表操作:
- 事实表建表语句
- 维度表
4.2 完成各个表的数据导入操作
4.3 拉链表实现流程分析
4.4 拉链表的实现操作

若有收获,就点个赞吧
0 人点赞
