技巧一:理解指针或引用的含义
技巧二:警惕指针丢失和内存泄漏
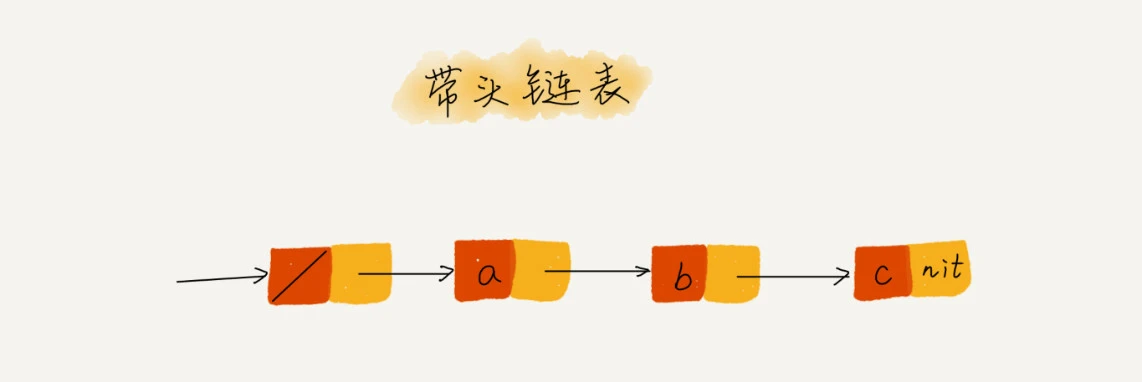
技巧三:利用哨兵简化实现难度
哨兵结点是不存储数据的。因为哨兵结点一直存在,所以插入第一个结点和插入其他结点,删除最后一个结点和删除其他结点,都可以统一为相同的代码实现逻辑了。
优化前:
// 在数组a中,查找key,返回key所在的位置// 其中,n表示数组a的长度int find(char* a, int n, char key) {// 边界条件处理,如果a为空,或者n<=0,说明数组中没有数据,就不用while循环比较了if(a == null || n <= 0) {return -1;}int i = 0;// 这里有两个比较操作:i<n和a[i]==key.while (i < n) {if (a[i] == key) {return i;}++i;}return -1;}
优化后:
- 实际上不要这么写, 可读性差
- 优化掉了
while (i < n)
// 在数组a中,查找key,返回key所在的位置// 其中,n表示数组a的长度// 我举2个例子,你可以拿例子走一下代码// a = {4, 2, 3, 5, 9, 6} n=6 key = 7// a = {4, 2, 3, 5, 9, 6} n=6 key = 6int find(char* a, int n, char key) {if(a == null || n <= 0) {return -1;}// 这里因为要将a[n-1]的值替换成key,所以要特殊处理这个值if (a[n-1] == key) {return n-1;}// 把a[n-1]的值临时保存在变量tmp中,以便之后恢复。tmp=6。// 之所以这样做的目的是:希望find()代码不要改变a数组中的内容char tmp = a[n-1];// 把key的值放到a[n-1]中,此时a = {4, 2, 3, 5, 9, 7}a[n-1] = key;int i = 0;// while 循环比起代码一,少了i<n这个比较操作while (a[i] != key) {++i;}// 恢复a[n-1]原来的值,此时a= {4, 2, 3, 5, 9, 6}a[n-1] = tmp;if (i == n-1) {// 如果i == n-1说明,在0...n-2之间都没有key,所以返回-1return -1;} else {// 否则,返回i,就是等于key值的元素的下标return i;}}
技巧四:重点留意边界条件处理
- 如果链表为空时,代码是否能正常工作?
- 如果链表只包含一个结点时,代码是否能正常工作?
- 如果链表只包含两个结点时,代码是否能正常工作?
- 代码逻辑在处理头结点和尾结点的时候,是否能正常工作?
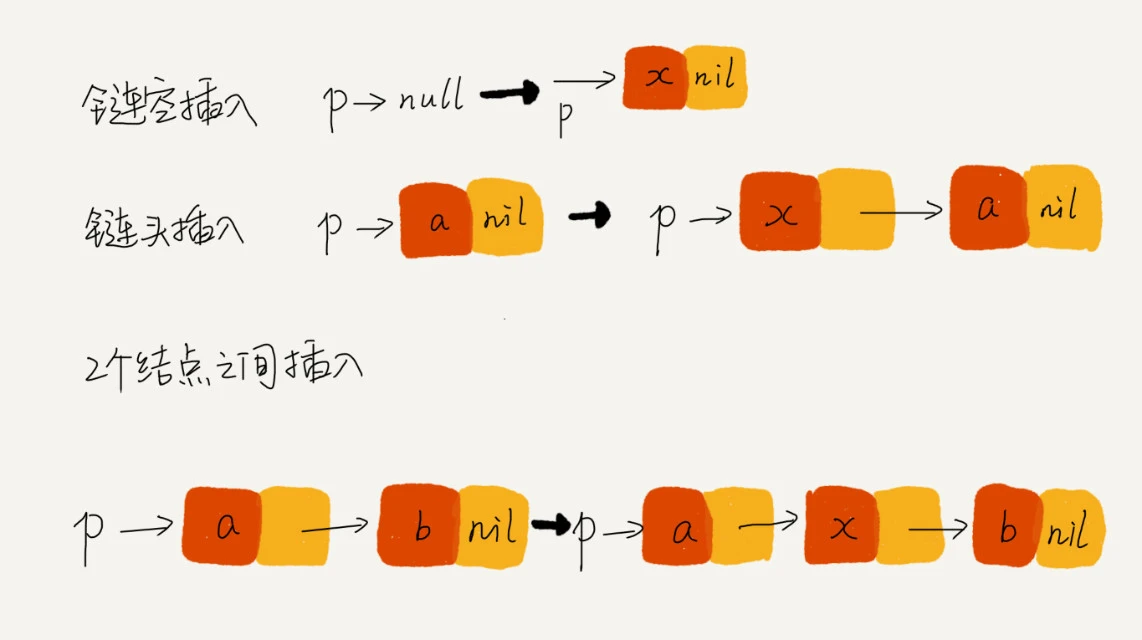
技巧五:举例画图,辅助思考
技巧六:多写多练,没有捷径
精选了 5 个常见的链表操作
- 单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第 n 个结点
- 求链表的中间结点

若有收获,就点个赞吧
0 人点赞
