canal简介
Canal 是用 Java 开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。 目前。Canal 主要支持了 MySQL 的 Binlog 解析,解析完成后才利用 Canal Client 来处理获得 的相关数据。(数据库同步需要阿里的 Otter 中间件,基于 Canal)。
binlog简介
MySQL 的二进制日志可以说 MySQL 最重要的日志了,它记录了所有的 DDL 和 DML(除 了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL 的二进 制日志是事务安全型的。
一般来说开启二进制日志大概会有 1%的性能损耗。二进制有两个最重要的使用场景:
其一:MySQL Replication 在 Master 端开启 Binlog,Master 把它的二进制日志传递给 Slaves 来达到 Master-Slave 数据一致的目的。
其二:自然就是数据恢复了,通过使用 MySQL Binlog 工具来使恢复数据。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有 的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的 DDL 和 DML(除了数据查询语句)语句事件。
binlog分类
MySQL Binlog 的格式有三种,分别是 STATEMENT,MIXED,ROW。在配置文件中可以选择配 置 binlog_format= statement|mixed|row。
三种格式的区别:
1)statement:语句级,binlog 会记录每次一执行写操作的语句。相对 row 模式节省空 间,但是可能产生不一致性,比如“update tt set create_date=now()”,如果用 binlog 日志 进行恢复,由于执行时间不同可能产生的数据就不同。 优点:节省空间。 缺点:有可能造成数据不一致。
2)row:行级, binlog 会记录每次操作后每行记录的变化。 优点:保持数据的绝对一致性。因为不管 sql 是什么,引用了什么函数,他只记录 执行后的效果。 缺点:占用较大空间。
3)mixed:statement 的升级版,一定程度上解决了,因为一些情况而造成的 statement 模式不一致问题,默认还是 statement,在某些情况下譬如:当函数中包含 UUID() 时;包含 AUTO_INCREMENT 字段的表被更新时;执行 INSERT DELAYED 语句时;用 UDF 时;会按照 ROW 的方式进行处理 优点:节省空间,同时兼顾了一定的一致性。 缺点:还有些极个别情况依旧会造成不一致,另外 statement 和 mixed 对于需要对 binlog 的监控的情况都不方便。
综合上面对比,Canal 想做监控分析,选择 row 格式比较合适。
工作原理
mysql主从复制原理
1)Master 主库将改变记录,写到二进制日志(Binary Log)中;
2)Slave 从库向 MySQL Master 发送 dump 协议,将 Master 主库的 binary log events 拷贝 到它的中继日志(relay log);
3)Slave 从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库。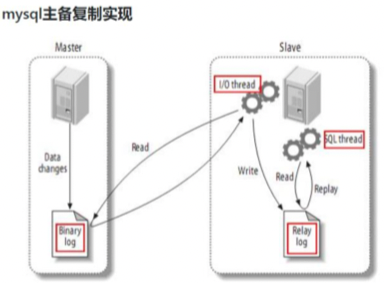
Canal 的工作原理
很简单,就是把自己伪装成 Slave,假装从 Master 复制数据
使用场景
- 原始场景:
阿里 Otter 中间件的一部分 Otter 是阿里用于进行异地数据库之间的同步框架,Canal 是其中一部分。
- 常见场景 : 更新缓存

3)常见场景 2:抓取业务表的新增变化数据,用于制作实时统计
整体架构

而在消息的存储设计中,Canal使用了RingBuffer,架构如下图:
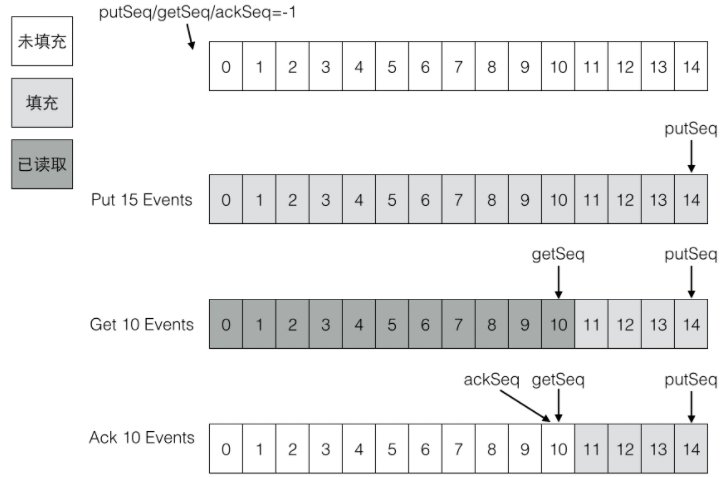
可以看到,现在Canal是在内存中来缓存消息的,并不会对数据进行持久化,而且缓存空间大小肯定是固定的,所以就会存在一直不提交确认ACK,导致内存缓存被占满的情况
canal数据结构
message有多个sql, 里面是Entry集合
一个Entry对应一个sql命令
这个sql的表名是TableName
EntryType是这个sql的类型, ddl和dml之类的
RowDATA 行数据
RowDataList, 一个sql会影响多行数据, update还有更新前和更新后的数据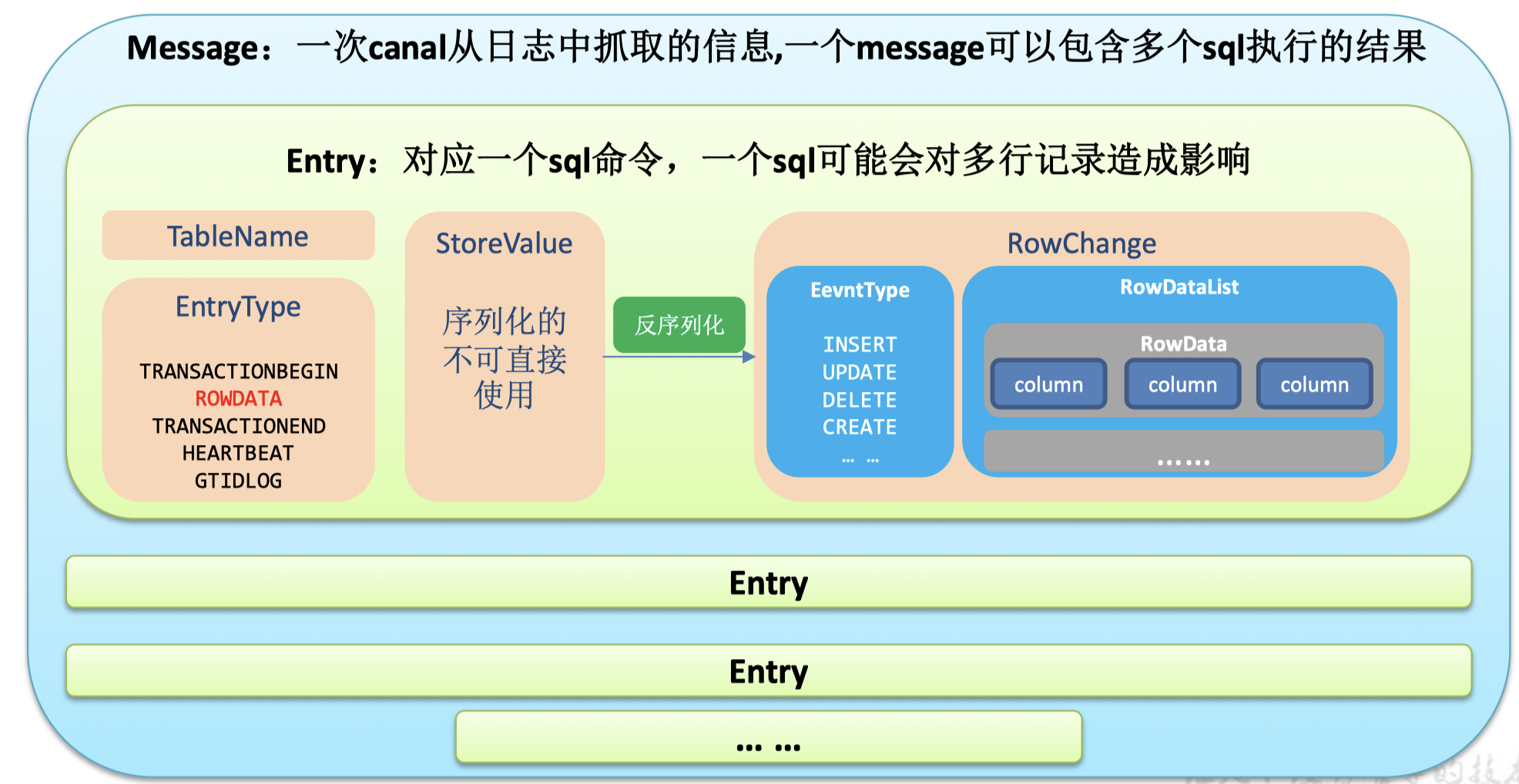

若有收获,就点个赞吧
0 人点赞
