redo log
WAL 预写日志技术
所有的数据库都有这个技术
这个技术解决什么问题?为啥要这个技术
当我们直接把数据写到磁盘上的时候, 这个数据是不同行不同的列, 在磁盘上是不同的区域.
比如
update T set c=c+1 where id>2;
那会让磁头先寻找位置, 然后更改数据, 中间产生大量的随机io, 很慢!
可不可以写把这次改动先记录下来, 然后异步的刷到磁盘上面, 可以的, 就是WAL, 把随机io改为顺序io
那数据写记录下来, 没真正的写到数据对应的磁盘那个区域, 那我读数据怎么读取呢?
数据从磁盘读取的时候, 会和WAL里面的数据进行merge的
两阶段提交
讲组复制之前必须要了解双1机制
比如一个update语句在mysql内部持久化的流程是这样的
update T set c=c+1 where id=2;
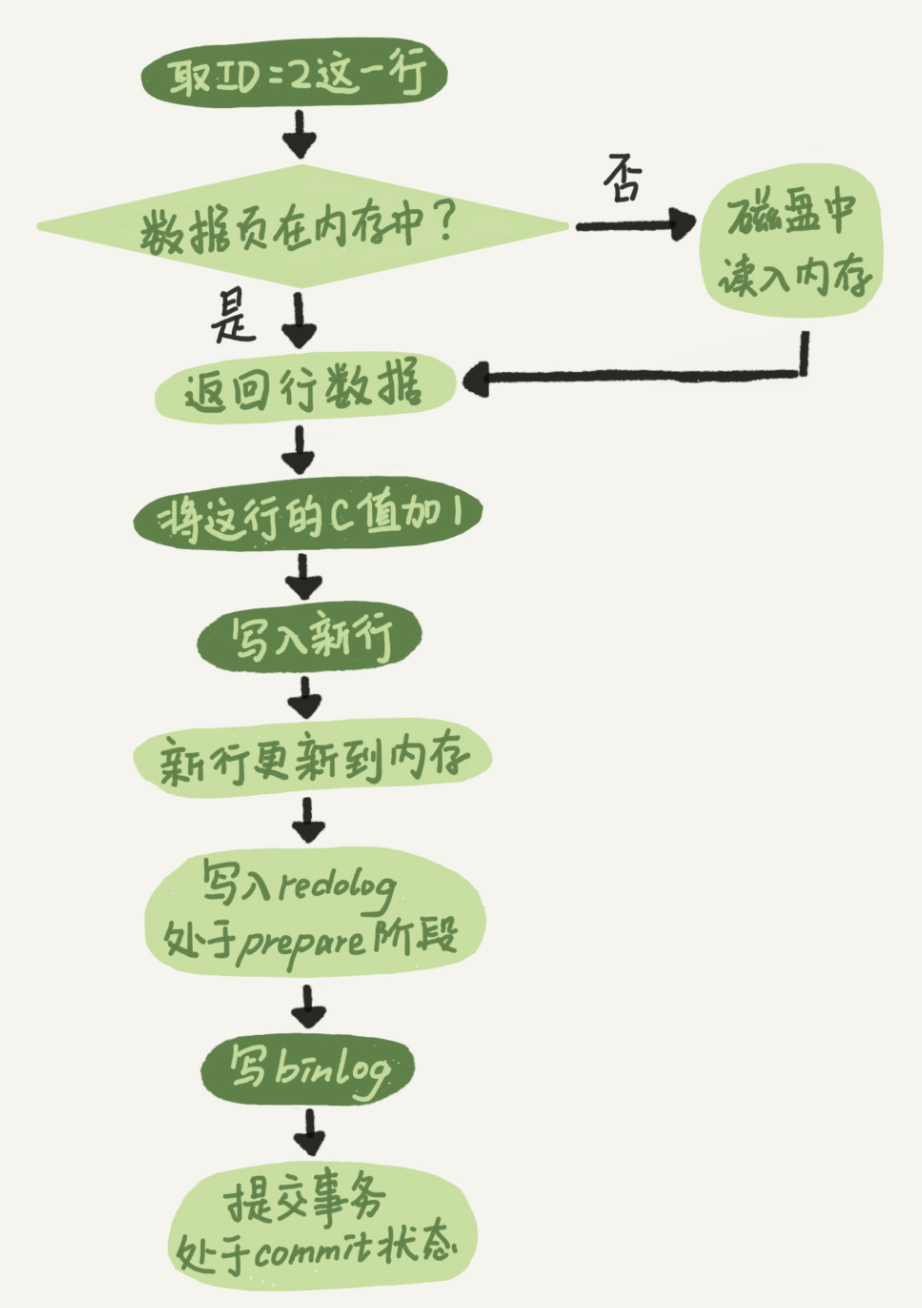
执行器和 InnoDB 引擎在执行这个简单的 update 语句时的内部流程:
- 执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
数据在写入binlog之前要写入redo log, 为啥要redo log这个. 能不能去掉他, 直接写入binlog?
不行, 为啥不行
- 当mysql异常崩溃的时候, 只有binlog无法恢复, 因为binlog代表的是一个语句, 这个语句的更新设计多行, 多列, 在磁盘上是多个块. 当mysql在写磁盘某一个块的时候崩溃了, 需要redo log去恢复, binlog只是记录的sql不知道mysql写数据块写哪里了.
- 数据持久化到磁盘, 需要redo log帮忙提升性能, 把随机io改为顺序io
那这个redo log这么好, 我可不可以不要binlog, 只要redo log?
不行,
- redo log没有归档的功能
- 只有innodb有
- 版本不一样的redo log差异很大
- redolog大小有限制, 超过就刷盘了.
那这个两阶段为啥要这个顺序?可不可以先写redo log再写binlog?
- 先写redo log再写binlog的问题
假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。由于我们前面说过的,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。然后会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。 因为主库上的binlog恢复的数据应该和主库上的现有数据保持一致
- 先写binlog再写redo log
如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。所以,在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
mysql之前的复制方式
mysql的binlog 一条条记录着sql/row/mixed
这些信息, mysql5.6之前是单线程的一条条的在从库回放, 那能不能异步 并行的回放?
协调者把不同的sql发给不同的线程处理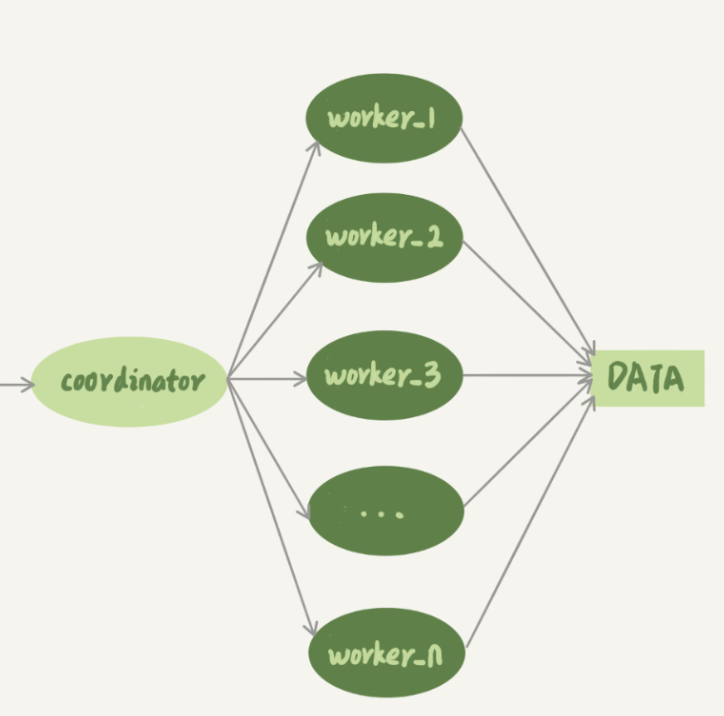
如果随意的异步并行把sql分给多线程, 会出现这样的问题
# 主库是这样的binlog (假设是sql格式, 方便理解)1. update T set c=c+1 where id>2;2. update T set c=3 where id>10;# 从库, 多线程回放线程1: 正在执行一堆任务, 此时这个sql进入了队列: update T set c=c+1 where id>2;线程2: 正在执行一堆任务, 此时这个sql进入了队列: update T set c=3 where id>10;
如果从库上线程2的执行比线程1快, 那sql的顺序就反了, 业务的正确性就受到了影响
那么单线程会导致什么问题?
mysql的从库大大落后主库, 导致主从延迟过大, 如果主从延迟过大的话, 从库的实际作用几乎没有了.
比如: 很多数据要求的延迟大概就是几秒或者2分钟, 再慢就查主库了.
如何提升mysql复制的能力?
基于组的并行复制, 组提交的并行复制
组的复制方式
- 能够在同一组里提交的事务,一定不会修改同一行;
- 主库上可以并行执行的事务,备库上也一定是可以并行执行的。
具体的实现是:
- 在一组里面一起提交的事务,有一个相同的 commit_id,下一组就是 commit_id+1;
- commit_id 直接写到 binlog 里面;
- 传到备库应用的时候,相同 commit_id 的事务分发到多个 worker 执行;
- 这一组全部执行完成后,coordinator 再去取下一批。
这个策略,目标是模拟主库的并行模式
但是,这个策略有一个问题,它并没有实现“真正的模拟主库并发度”这个目标。在主库上,一组事务在 commit 的时候,下一组事务是同时处于“执行中”状态的。
这个方案很容易被大事务拖后腿, 这段时间,只有一个 worker 线程在工作,是对资源的浪费。
利用mysql的两阶段提交实现这个
能够到达 redo log prepare 阶段,就表示事务已经通过锁冲突的检验了
MySQL 5.7 并行复制策略的思想是:
- 同时处于 prepare 状态的事务,在备库执行时是可以并行的;
- 处于 prepare 状态的事务,与处于 commit 状态的事务之间,在备库执行时也是可以并行的
binlog 的组提交的时候,有两个参数:
- binlog_group_commit_sync_delay 参数,表示延迟多少微秒后才调用 fsync
- binlog_group_commit_sync_no_delay_count 参数,表示累积多少次以后才调用 fsync
这两个参数是用于故意拉长 binlog 从 write 到 fsync 的时间,以此减少 binlog 的写盘次数。在 MySQL 5.7 的并行复制策略里,它们可以用来制造更多的“同时处于 prepare 阶段的事务”。这样就增加了备库复制的并行度
这两个参数,既可以“故意”让主库提交得慢些,又可以让备库执行得快些
双1机制
sync binlog和redo log的参数配置
那么组提交了, 那把binlog和redo log刷盘是不是也可以做成组提交强刷磁盘?
刷盘有哪些参数
- 写pagecache等os刷盘
- 写pagecache, 每秒刷1次盘
- 不写pagecache, 强刷磁盘
有了组提交, 强刷磁盘性能就不那么差了, 因为是批量写, 而且redo和binlog都是顺序io写
附录
mysql存储
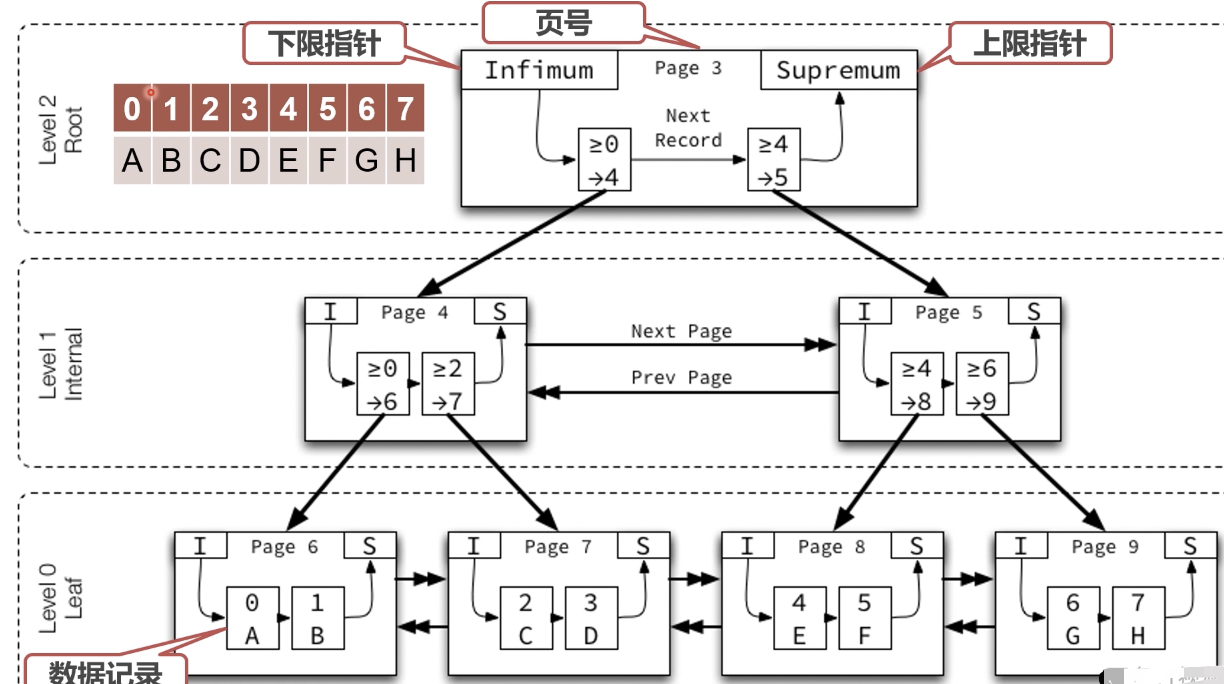
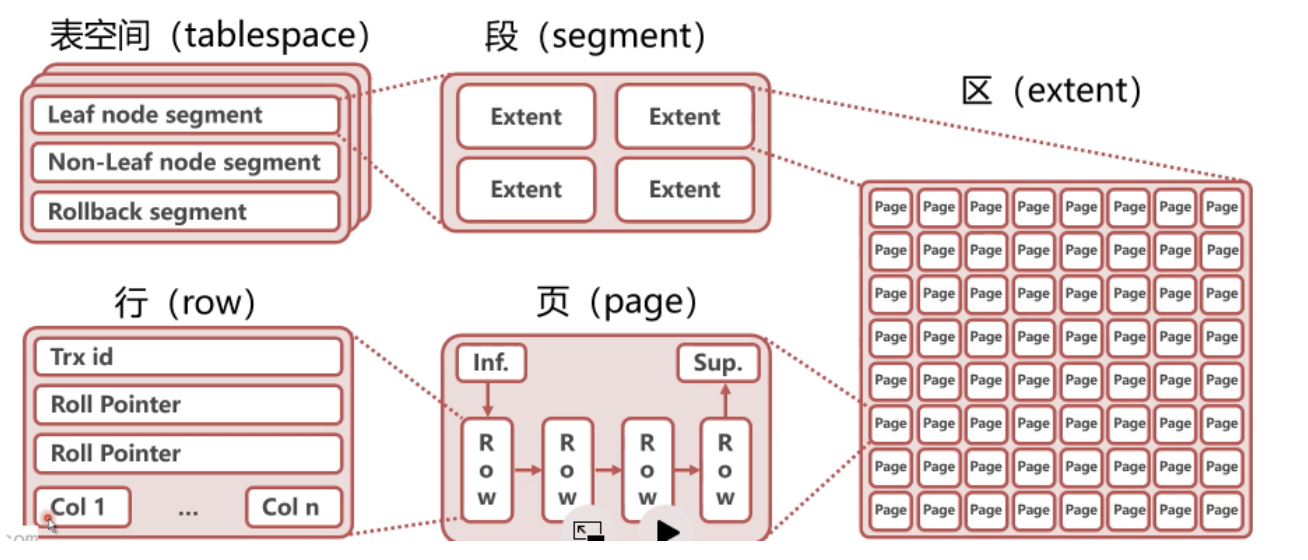
表空间是.ibd文件
page就是B+树上的page
Trx id是事务id, 表示是那个事务更新的
Coln是行数据
段
数据段: B+树的叶子节点
索引段: B+树的非叶子节点
innodb中, 段由innodb自己管理的

若有收获,就点个赞吧
0 人点赞
